안녕하세요. 오늘은 제가 예전에 HPX 라는 오픈소스에 구현했던 parallel partition 알고리즘에 대해 간단히 소개하고 설명하는 시간을 가져보도록 하겠습니다.
출처
먼저 이 포스팅에서 다루는 알고리즘/코드의 출처는 다음과 같습니다.
- HPX : https://github.com/STEllAR-GROUP/hpx
- 관련 MR : https://github.com/STEllAR-GROUP/hpx/pull/2778
- 소스코드 : https://github.com/STEllAR-GROUP/hpx/blob/master/hpx/parallel/algorithms/partition.hpp
소개
parallel partition 알고리즘은 여러 개의 연산 유닛 (쉽게 말하면 cpu) 들을 이용해서 partition 알고리즘을 수행하는 것을 말합니다.
이 포스팅에서는 독자가 partition 알고리즘에 대해서 이미 알고있다고 가정합니다. partition 알고리즘에 대한 설명은 cppreference 를 참고하시기 바랍니다.
알고리즘 설명
partition 알고리즘은 주어진 영역을 정해진 규칙을 만족하는지 아닌지에 따라 두 영역으로 분류하는 알고리즘입니다.
예를 들어, 짝수인지 여부에 대해 partition 알고리즘을 수행한다고 하면 결과는 다음과 같습니다.
적용 전 : 3 5 7 4 2 1 9 8 6
적용 후 : 6 8 2 4 * 7 1 9 5 3
즉, partition 알고리즘의 핵심은 다음과 같습니다.
- 두 영역을 구분할 수 있는 boundary 를 찾는다.
- 그 boundary 의 왼쪽에는 조건을 만족하는 원소들이, 오른쪽에는 조건을 만족하지 않는 원소들이 위치하게 된다.
자, 위의 핵심을 기억하면서 parallel partition 알고리즘을 살펴보도록 합시다.
결론적으로 parallel partition 알고리즘은 크게 4단계로 이루어집니다.
- 주어진 영역을 여러 개의 block 으로 쪼개서 병렬로 sub-partitioning 을 수행한다.
- 남은 block 들에 대해서 순차적으로 sub-partitioning 을 수행한다.
- 남은 block 들을 boundary 근처로 모아서 하나로 합친다.
- boundary 근처로 합쳐진 하나의 block 에 대해서 순차 partition 알고리즘을 적용한다.
1단계를 제외한 2~4 단계는 모두 순차적으로 수행됩니다.
그러면 1단계부터 살펴보도록 하겠습니다.
1단계. 병렬 sub-partitioning
처음에 들었던 예시를 다시 한번 봐봅시다.
적용 전 : 3 5 7 4 2 1 9 8 6
적용 후 : 6 8 2 4 * 7 1 9 5 3
위 예시에서도 볼 수 있듯이 partition 알고리즘은 unstable 한 특성이 있습니다. (stable partition 알고리즘도 물론 별도로 존재합니다.)
즉, 기존 원소들간의 순서를 지킬 필요없이 영역만 나누면 장땡입니다. 따라서 병렬 알고리즘을 구현하는게 매우 수월해지는데요. 주어진 영역을 여러 개의 block 으로 나눈뒤에 두 개의 block 끼리 짝을 지어서 partition 알고리즘을 수행하는 방식을 사용하려고 합니다. 일단, 순차적으로 이러한 알고리즘을 수행하는 것을 살펴보겠습니다.
3 5 7 4 2 1 9 8 6
위와 같이 원소들이 주어져있을 때, 3개의 원소씩 block 을 구성하여 partitioning 을 수행해보겠습니다.
^ 3 5 7 | 4 2 1 | ^ 9 8 6
맨 왼쪽과 맨 오른쪽에서 block 을 한 개씩 구성하면 위와 같습니다.
8 6 ^ 7 | ^ 4 2 1 | 9 3 5
자 이제 두 block 에 대해서 partition 알고리즘을 수행하면 위와 같이 변하게 되는데요.
맨 오른쪽 block 은 홀수만 존재하게 되었지만, 맨 왼쪽 block 은 여전히 ‘7’ 하나가 홀수인채로 남아있습니다. 맨 왼쪽 block 에 대해서도 partition 이 완전히 수행되려면 다시 오른쪽에서 block 을 하나 뽑아서 partition 을 마저 수행해야합니다.
그렇게 partition 을 마저 수행하고 나면 다음과 같이 변합니다.
8 6 4 | 7 ^ 2 1 | 9 3 5
자 여전히 2 1 이 partitioning 되지 못하고 남게 되었는데요. 이렇게 이러한 작업을 반복해서 수행하다 보면 하나의 block 이 남을 수가 있습니다. 이렇게 남은 block 을 앞으로 remaining block 이라고 부르겠습니다.
지금까지 간단하게 설명드린 알고리즘을 병렬로도 돌릴 수가 있습니다.
여러 개의 코어가 계속 왼쪽/오른쪽에서 block 을 뽑아가면서 partitioning 을 수행하면 됩니다.
HPX 에서의 코드를 살펴보면 다음과 같습니다.
// The function which performs sub-partitioning.
template <typename FwdIter, typename Pred, typename Proj>
static block<FwdIter>
partition_thread(block_manager<FwdIter>& block_manager,
Pred pred, Proj proj)
{
using hpx::util::invoke;
block<FwdIter> left_block, right_block;
left_block = block_manager.get_left_block();
right_block = block_manager.get_right_block();
while (true)
{
while ( (!left_block.empty() ||
!(left_block = block_manager.get_left_block()).empty()) &&
invoke(pred, invoke(proj, *left_block.first)))
{
++left_block.first;
}
while ( (!right_block.empty() ||
!(right_block = block_manager.get_right_block()).empty()) &&
!invoke(pred, invoke(proj, *right_block.first)))
{
++right_block.first;
}
if (left_block.empty())
return right_block;
if (right_block.empty())
return left_block;
std::iter_swap(left_block.first++, right_block.first++);
}
}
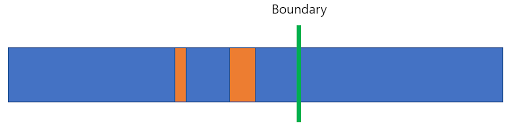
그렇게 1단계를 완료하고 나면, 다음과 같은 상태가 됩니다. (주황색은 remaining block 을 의미합니다.)
여기서 boundary 라는게 있는데 이게 매우 중요합니다. 왼쪽에서 뽑힌 block 을 “왼쪽 block”, 오른쪽에서 뽑힌 block 을 “오른쪽 block” 이라고 할 때, “왼쪽 block” 들과 “오른쪽 block” 들 사이의 경계가 생기게 됩니다. 이 경계를 boundary 라고 부르도록 하겠습니다. 여기서 주목해야할 특징은, boundary 왼쪽의 파란색 영역은 모두 주어진 조건을 만족하도록 partitioning 되어있고, 오른쪽의 파란색 영역은 모두 주어진 조건을 만족하지 않도록 partitioning 되어있다는 것입니다.
즉, 주황색영역 (remaining block) 을 제외하면 boundary 를 기준으로 partitioning 되어있는 상태가 됩니다. 결국 문제가 되는건 주황색 영역인데 이 영역들을 2~4 단계에서 partitioning 하게 됩니다.

2단계. remaining block 들에 대한 순차 sub-partitioning
1단계에서, 만약 N개의 코어로 병렬작업을 수행한다면 최대 N개의 remaining block 이 생길 수 있습니다. 이렇게 생긴 N개의 remaining block 들에 대해서 똑같이 sub partitioning 을 수행할 수 있는데 이게 바로 2단계입니다. 단, 2단계에서는 순차적으로 sub-partitioning 을 수행하는데요. boundary 왼쪽과 오른쪽에서 각각 block 을 한 개씩 뽑아나가며 알고리즘을 수행합니다. 결국 최후에는 boundary 를 기준으로 한쪽에만 block 이 남게되는데요. 그림으로 보면 다음과 같은 상태가 됩니다.
코드는 collapse_remaining_blocks() 함수를 참고하시길 바랍니다.
3단계. 남은 block 들을 boundary 근처로 모은다.
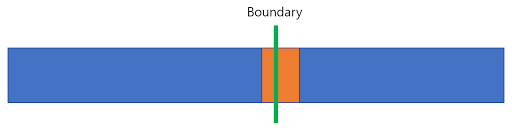
자, 이제 boundary 를 기준으로 한쪽에만 소수의 block 들이 partitioning 되지 않은 상태로 남아있습니다. partitioning 을 마저 완료하기 위해, 저 remaining block 들을 boundary 에 인접하도록 모아서 하나의 block 으로 합치고, 그것에 대해서 순차적인 일반 partition 알고리즘을 수행하려고 합니다.
일단, remaining block 들을 boundary 에 인접하도록 하나의 block 으로 합치면 다음과 같은 상태가 됩니다.

코드는 merge_remaining_blocks() 함수를 참고하시길 바랍니다.
4단계. 모아진 하나의 block 에 대해서 순차 partitioning 을 수행한다.
모아진 하나의 block 에 대해서 순차 partition 알고리즘을 적용하면 새로운 boundary 를 구할 수 있고, 이 boundary 가 마침내 주어진 영역을 주어진 조건에 따라 분리하는 최종 boundary 가 됩니다.
block size
parallel partition 알고리즘의 성능을 최적화하기 위해서는 적절한 block size 를 사용하는 것이 중요합니다.
만약 block size 가 너무 작다면, 1단계에서 block 을 자주 뽑아야 하므로 여기에서 overhead 가 많이 발생할 수 있습니다. (특히 block 을 뽑을 때 동기화 연산이 들어가므로 더더욱 그렇습니다.) 또한, block 을 자주 뽑게되면 cache miss 의 비율이 늘어나 성능상으로 악영향을 주게 됩니다.
그렇다고 block size 가 너무 크면, remaining block 의 사이즈가 커지게 되고 이에 따라 순차적으로 수행해야하는 알고리즘들이 오래걸리게 됩니다.
제가 HPX 에 parallel partition 을 구현할 때는 block size 를 바꿔가면서 성능테스트를 수행해보고 다른 논문의 실험결과도 참고하여 default block size 로서 20000 을 채택하게 되었습니다.
벤치마크
제가 parallel partition 을 구현하고나서 수행했던 벤치마크 결과입니다.
16 코어 (8 physical core) 환경에서 테스트했을 때, sequential version 에 비해 약 12배정도 빠른 것을 확인할 수 있었습니다.

마무리
이번 포스팅을 하기위해 오랜만에 옛날 코드를 뒤적거렸는데요. HPX 오픈소스를 한창 하던때가 17년 여름인데 벌써 2년이 다되간다는게,, 참 시간이 빠르네요. 그리고, 옛날 코드를 다시 보니 맘에 안드는 점들도 많이 보이고…ㅠㅠ
아무튼, 코너 케이스 처리와 iterator category 마다의 다른 구현을 확인하고 싶으신 분은 여기에서 전체 코드를 참고하시면 될 것 같습니다.
다음에 만나요~~