문제 출제를 위한 플랫폼 - Polygon 사용하기
Polygon , Codeforces , problem-solving , competitive-programming , programming-contest , setter
Polygon이란?
Polygon이란 Codeforces에서 제공하는 Competitive Programming Contest를 위한 문제 출제를 위한 플랫폼입니다. 출제를 위해 필요한 과정 - 데이터 제작, 검증, 솔루션 검증 등에 굉장히 유용한 기능들이 많으며 그 과정을 다른 사람과 공유하며 협업할 수도 있습니다.
폴리곤에서의 작업은 각 문제 단위로 동작합니다. 문제를 등록하는 방법부터 완성된 문제를 패키지로 다운받는 방법까지, 필요한 기능들을 간략히 확인하고 언제 어떤 메뉴를 사용해야 하는지 문제 출제 단계에 따라 익혀봅시다. 아, 그 전에 회원가입은 다들 하셔야겠죠?
문제 등록하기
폴리곤에 로그인하면 아래와 같은 화면을 볼 수 있습니다.

폴리곤의 이런저런 기능들을 사용하기 위해서는 먼저 문제를 등록해야 합니다. ‘New Problem’을 눌러 문제의 이름을 지정한 뒤 ‘create’ 버튼을 누르면 메인 화면에 해당 문제를 위한 세션이 생성된 것을 볼 수 있습니다. ‘Start’를 눌러 문제를 관리해봅시다.

문제 세션 내부를 보면 이런저런 메뉴가 많습니다. 각 메뉴를 처음부터 다 알 필요는 없습니다. 우선은 간략히 어떤 역할인지만 인지한 후 단계단계마다 필요한 메뉴에 대해서 조금 더 자세히 알아봅시다.
- General Info: 문제에 대한 설명과 적용할 메모리/시간 제한, 파일입출력 등의 설정을 위한 메뉴입니다.
- Statement: 문제 본문과 입력/출력에 대한 설명, 예제 등 모든 디스크립션을 관리하는 메뉴입니다. 한국어/영어 등 언어별로 관리할 수 있습니다.
- Files: 문제 출제를 위해 사용되는 모든 소스 파일(Data Generator/Validator, Checker 등)을 관리하는 메뉴입니다.
- Checker: 문제의 채점 방식을 관리하는 메뉴입니다. 여러
- Validator: 등록된 데이터가 valid한지 검사하는 프로그램을 관리하는 메뉴입니다.
- Tests: 문제의 테스트 데이터를 관리하는 메뉴입니다.
- Stresses: 정답 솔루션과 틀린 솔루션, 데이터 생성기를 등록하면 두 코드가 다른 답을 출력하는 데이터를 생성해주는 메뉴입니다.
- Solution files: 문제의 솔루션 코드를 관리하는 메뉴입니다.
- Invocation: 솔루션과 테스트 데이터를 선택하면 선택한 솔루션이 테스트 데이터에 대해 어떤 결과가 나오는지, 지정한 상태(Accepted, WA, TLE …)와 일치하는지를 검사할 수 있습니다.
- Issues: 문제 관련 수정 건의나 해야할 일 등을 메모처럼 관리하는 메뉴입니다.
- Packages: 위 메뉴들에서 관리한 모든 상태를 묶어 다운로드 받을 수 있습니다.
- Manage access: 문제를 다른 사람과 공유하거나 공동으로 작업할 때 권한을 관리할 수 있습니다.
아래의 내용에서 General Info, Statement, Issues, Manage access는 따로 다루지 않습니다. General Info는 워낙 메뉴가 간단하고, Statement를 위한 문법을 익히기 어렵다면 다른 대체 플랫폼(구글 드라이브, GitHub)을 통해 관리한다는 선택지도 있습니다. Issues, Manage access의 경우 직관적이라 사용이 어렵지 않습니다. 다른 사람과 문제를 공유하거나 공동으로 작업하고 싶다면 Manage access 메뉴에서 유저를 추가하여 권한을 설정할 수 있습니다.
대회에 사용할 문제를 한 곳에 담아두고 싶다면
하나의 대회를 위해 여러 개의 문제를 출제할 때가 있습니다. 이럴 때는 메인 메뉴에서 ‘New Contest’를 눌러 새로운 콘테스트를 생성하여 여러 문제를 해당 콘테스트에 묶어둘 수 있습니다. 콘테스트를 만들었다면 ‘View Contests’에서 원하는 콘테스트에 ‘Enter’를 누르면 관리메뉴를 볼 수 있습니다.
Contest Problems의 우측에 ‘add problems?’라는 메뉴를 볼 수 있습니다. 해당 메뉴를 클릭하면 자신에게 권한이 있는 문제들을 해당 콘테스트에 추가할 수 있습니다. 콘테스트의 협업자를 추가하는 것은 우측 메뉴 중 ‘Contest Developers’에서 관리할 수 있습니다. 각 문제의 오너가 위에서 설명한 Manage access 메뉴를 통해 각 협업자에게 권한을 주면 협업자도 자유롭게 해당 문제 세션을 사용하고 편집할 수 있습니다.
우리를 위해 준비된 “testlib.h”
이후의 과정을 설명하기 전에 먼저 알아둘 파일이 있습니다. 바로 폴리곤에서 각종 검증을 위해 사용하는 C++ 헤더파일인 “testlib.h”입니다. 이 헤더에는 Data Generator를 작성할 때 유용한 랜덤 난수 생성기, Input Validator를 작성할 때 유용한 버퍼 리더, Validator와 Checker에서 사용되는 상태에 따른 verdict 함수 등이 구현되어 있습니다.
보다 자세한 내용 및 예제는 Testlib GitHub에서 확인할 수 있으며 유저가 따로 해당 함수를 만들어 사용하는 것보다 플랫폼과의 호환성이나 안정성 면에서 뛰어나고 별도의 숙련 없이 위에서 설명한 기능들을 손쉽게 사용할 수 있으니 아래에서 설명할 Generator / Validator / Checker 등을 작성할 때 꼭 활용해봅시다. 아래에서 각 소스코드를 작성할 때 주로 사용되는 함수에 대한 예제를 살펴볼테니 필요할 때 조금씩 찾아봐도 충분합니다.
+) “testlib.h”는 소스코드 내부에서 사용하는 난수가 상황에 따라 변하는 것을 막기 위해 srand()와 rand() 함수의 사용이 불가능합니다. 또한 기존의 함수들을 오버로딩하기 때문에 충돌을 피하기 위해 가장 먼저 include 해야 합니다.
데이터 제작하기
문제를 출제할 때 가장 시간을 쓰는 단계는 아무래도 데이터 제작입니다. 단순한 랜덤 데이터는 의도하지 않은 풀이를 손쉽게 통과시킬 수 있으며, 이를 방지하려면 많은 노력과 다양한 형태의 데이터를 제작해야합니다. ‘Tests’에서는 문제에 사용되는 입력데이터를 관리할 수 있습니다.
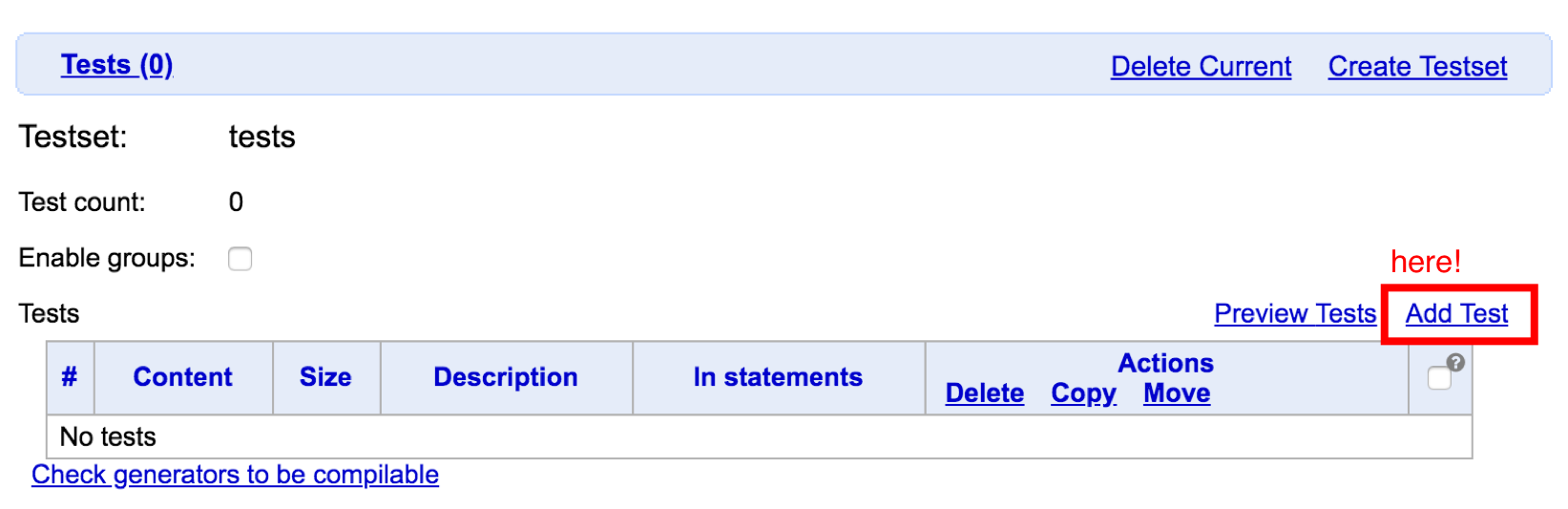
테스트 데이터는 여러 그룹으로 나누어 관리할 수 있습니다. Create Testset을 하면 새로운 테스트셋을 만들 수 있고, 의미나 데이터 범위에 따라 소속 테스트셋을 나누어 데이터를 등록하는 것은 나중에 Invocation 등의 검증 과정에서 큰 도움이 됩니다.
데이터 제너레이터로 생성하지 않고 직접 만든 테스트 데이터의 경우 ‘Add Test’ 버튼을 통해 여러 파일을 한 번에 등록할 수 있습니다. 여기까지는 일반적이지만 조금 생소한 것은 위 메뉴의 밑에 있는 스크립트 창일 것입니다.
#include "testlib.h"
using namespace std;
int main(int argc, char* argv[]){
registerGen(argc, argv, 1);
int l = atoi(argv[1]);
int r = atoi(argv[2]);
int N = rnd.next(l, r);
int M = rnd.next(1, N);
printf("%d %d\n", N, M);
return 0;
}
“testlib.h”를 이용하여 다음과 같은 데이터 제너레이터를 작성해봅시다. 위 코드는 두 개의 인자 l, r을 받아 [l, r] 정수 N과 [1, N] 정수 M을 랜덤하게 선택해 입력 데이터를 만듭니다. 이때 registerGen() 함수는 입력받은 인자를 프로그램 내에서 사용하기 위해 호출해주셔야 합니다. 이 소스코드를 ‘Files’ 메뉴로 가서 Source Files에 “data_gen.cpp”라는 이름으로 추가해줍시다.
파일 등록이 완료되었다면 아래는 등록된 생성기를 이용해 l = 1000, r = 2000인 입력 데이터 파일을 생성하는 스크립트 예제입니다.
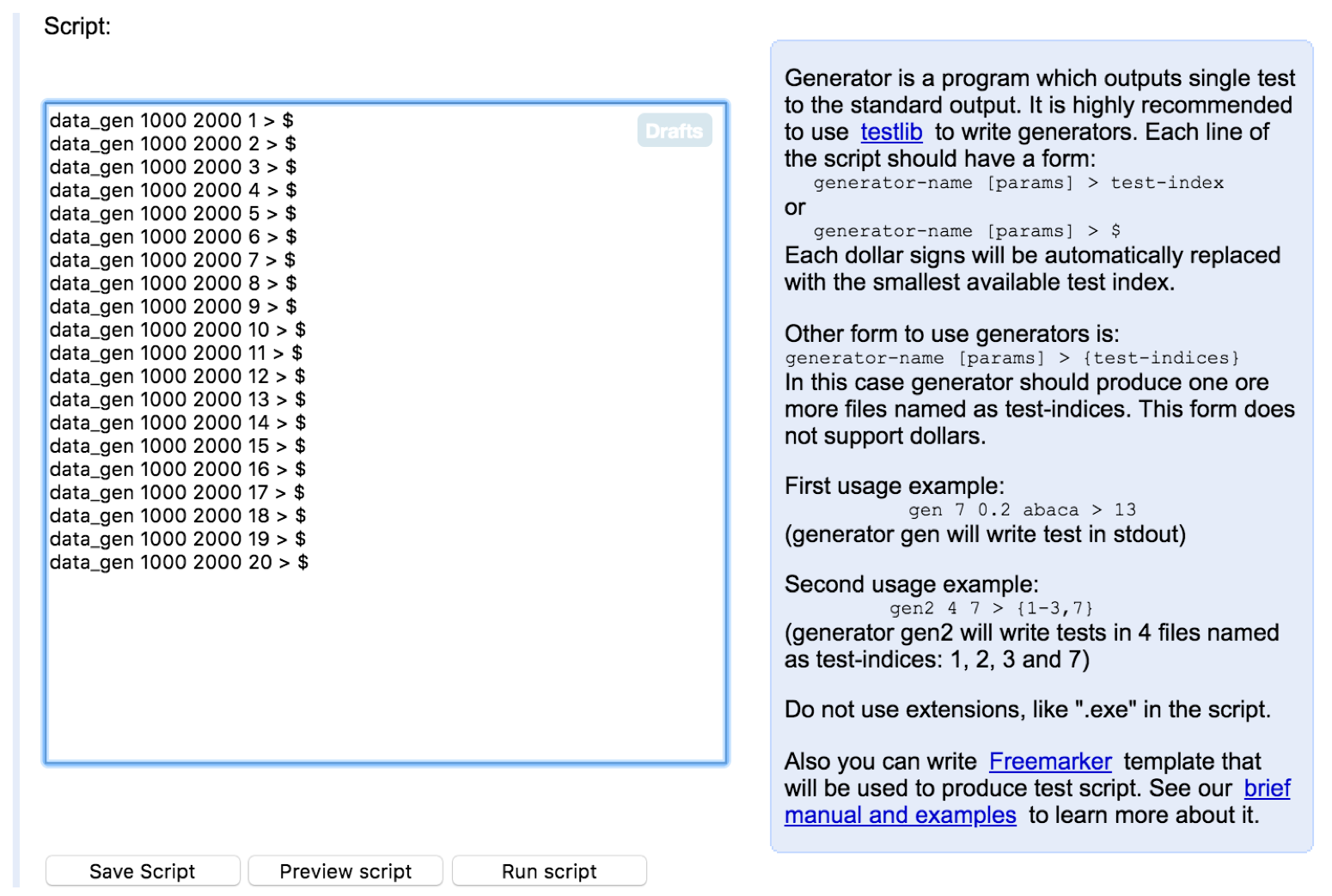
“data_gen”은 내가 등록해 둔 생성기 중 어떤 이름의 파일을 생성기로 사용할 것인지, 뒤의 두 숫자는 해당 생성기에서 입력으로 받는 인자값을 의미합니다. 여러개의 생성기를 만들었다면 혼용해서 사용도 가능합니다. 이때 가장 뒤의 1 ~ 20번 부터의 숫자는 20개의 같은 인자를 받은 생성기가 서로 다른 난수를 생성하기 위해 구분되는 추가 시드를 입력해준 것입니다. 만약 해당 값을 주지 않거나 같은 값으로 준다면 “testlib.h”에 의해 스크립트는 같은 데이터를 생성하게 됩니다.
스크립트 기능을 활용하면 굳이 로컬에서 데이터를 생성하지 않아도 플랫폼을 이용해 손쉽게 입력 데이터를 만들 수 있습니다. 단, 스크립트를 사용할 때 하나의 데이터 생성을 위한 최대 시간이 정해져 있는데 데이터 생성기의 시간복잡도가 높아 해당 시간을 넘기게 된다면 이는 로컬이나 다른 서버를 이용해 직접 파일을 생성해야 합니다.
데이터 검증하기
입력 데이터를 생성했다면 이제 이 입력 데이터가 디스크립션에서 설정한 조건에 맞는지 검증하는 과정이 필요합니다. 물론 데이터 생성기에 자신이 있고 문제가 없을 거라 확신한다면 필수적인 단계는 아닙니다. 하지만 문제를 출제하는 과정에서 돌다리를 두드려보는 것은 몇 번이어도 낭비가 아닙니다.
#include "testlib.h"
using namespace std;
int main(int argc, char* argv[]) {
registerValidation(argc, argv);
int N = inf.readInt(1000, 2000, "N");
inf.readSpace();
int M = inf.readInt(1, N, "M");
inf.readEoln();
ensuref(0 < N && 0 < M, "N M must be positive.")
ensuref(N != M, "N M must be different.")
inf.readEof();
}
위는 이전에 만든 “data_gen”으로 생성된 입력 파일을 읽고, 데이터의 형식에 문제가 없으며 N과 M이 양수인 서로 다른 숫자인지 검증하기 위한 Validator입니다. 물론 “date_gen”에서 M의 범위는 [1, N]이었으므로 ‘ensuref()’ 함수에 있는 조건은 True일 수도, False일 수도 있습니다. 만약 모든 데이터가 다행히도 해당 조건을 만족한다면 검증 과정에 문제없이 동작하겠지만 위 조건에 맞지 않는 데이터가 있을 경우 함께 기재한 verdict message로 어떤 조건에서 데이터가 맞지 않는지 확인할 수 있습니다.
이 밸리데이터를 제너레이터와 마찬가지로 ‘Files’ 메뉴의 Source Files에 추가해줍시다. 이후 ‘Validator’ 메뉴에서 해당 파일을 골라 밸리데이터로 지정해줍시다. 원하신다면 아래의 Validator Tests 메뉴를 통해 입력한 데이터에 대해 밸리데이터가 잘 동작하는지 확인할 수 있습니다.
솔루션 업로드 및 검증
입력 데이터 작업이 완료되었다면 이제 메인 솔루션 코드를 업로드할 차례입니다. ‘Solution files’메뉴를 보면 ‘Add Solutions’ 버튼을 통해 솔루션 코드를 등록할 수 있습니다. 솔루션을 추가한 후 해당 솔루션의 Type을 변경하실 수 있는데 이는 해당 솔루션에 기대하는 결과를 지정해주시면 됩니다. 정답을 비교할 메인 솔루션 코드에 Main Solution Code를 지정해주시고 다른 정답 코드들에는 Correct를 지정해주세요. 다른 오답 / 시간초과 / 런타임에러 등의 결과가 기대되는 코드에는 그에 맞는 타입을 지정해주시면 됩니다. 아래의 Solutions tags를 이용하시면 각 테스트셋별로 원하는 결과를 지정할 수도 있습니다.
이제 업로드한 솔루션들이 등록된 입력 데이터들에 대해 올바른 출력을 하는지를 검증할 시간입니다. 이를 위해 ‘Checker’ 메뉴에서 메인 솔루션 코드의 출력과 다른 솔루션 코드의 출력을 어떻게 비교할 것인지 체커를 설정할 수 있습니다.
폴리곤에서는 여러 체커를 제공하는데, 메인 솔루션의 아웃풋과 유저의 아웃풋이 동일한지를 비교하는 체커가 기본으로 되어있습니다. 만약 다중 솔루션을 위한 스페셜저지가 필요하다면 소스코드를 작성하여 등록하면 이를 일반 체커 대신 채점기로 사용할 수 있습니다.
아래는 N과 M이 주어질 때 N * M과 같은 곱을 가지지만 N, M과는 다른 두 양의 정수 A, B를 출력하는 문제의 스페셜저지 예제입니다.
#include "testlib.h"
using namespace std;
int main(int argc, char* argv[]){
registerTestlibCmd(argc, argv);
int N = inf.readInt();
inf.readSpace();
int M = inf.readInt();
inf.readEoln();
int A = ouf.readInt();
ouf.readSpace();
int B = ouf.readInt();
ouf.readEoln();
if(A < 0 || B < 0)
quitf(_wa, "Invalid answer range: output must be positive");
if((long long)N * M != (long long)A * B)
quitf(_wa, "Wrong Answer: A * B not equals to N * M");
quitf(_ok, "Correct!");
}
데이터 등록, 솔루션 등록, 체커 등록을 모두 마쳤다면 이제 우리는 각 솔루션이 주어진 입력 데이터에 대해 올바른 답을 생성하는지 검증해 볼 수 있습니다. ‘Invocations’ 메뉴에서 ‘Want to run solutions?’를 클릭하면 내가 원하는 솔루션을 원하는 테스트 데이터에 대해 실행해 볼 수 있습니다. ‘Run’을 누르면 각 솔루션 코드의 각 데이터에 대한 결과를 받아볼 수 있으며, Accepted가 아닌 다른 상태의 경우 그 원인을 볼 수 있습니다. 입력 데이터가 밸리데이터를 통과하지 못했거나, 체커의 어느 부분에서 올바르지 않은 상태가 검출되었는지 등 지금까지 등록한 파일들을 바탕으로 데이터 혹은 솔루션에 문제가 없는지를 검증할 수 있습니다.
완성된 문제 내려받기
여기까지 수행했을 때 우리는 문제 세션의 오른쪽에서 아래 세션 요약과 같이 어떤 체커 / 밸리데이터 등이 있고 테스트셋은 각 몇 개가 있는지 등을 알 수 있습니다.
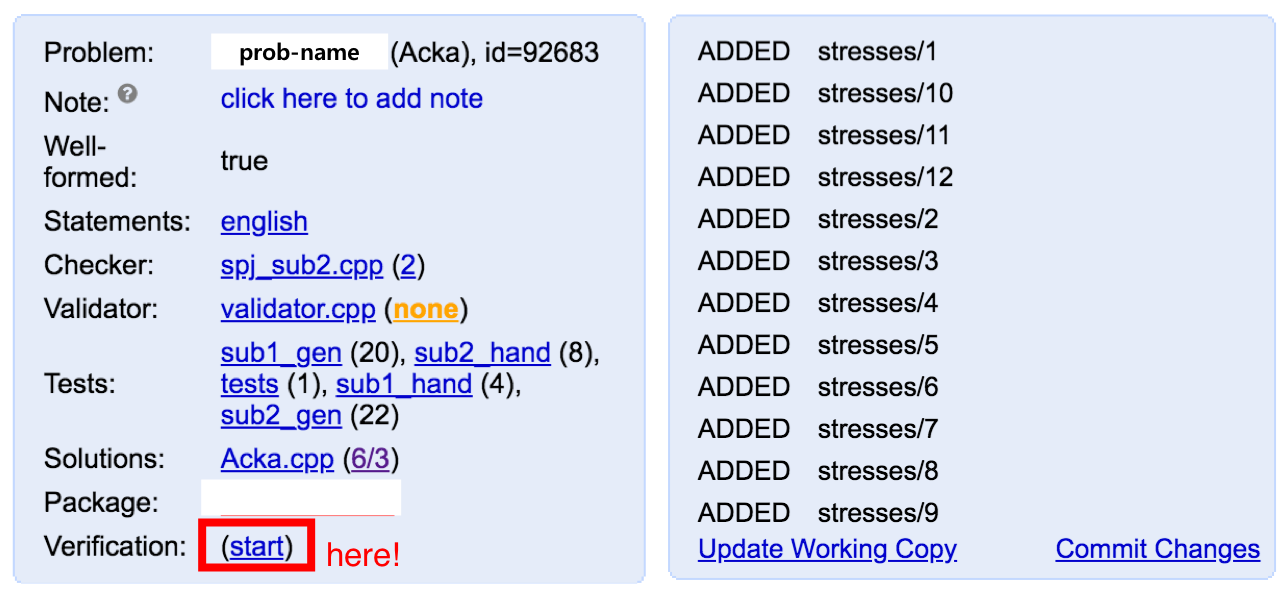
세션 요약 내용 중 Statements와 Validator는 필수 항목이 아니기 때문에 비어있을 수 있습니다. Package는 아직 생성한 적이 없다면 None으로 되어 있을텐데 이 세 가지 항목의 빨간색 None은 그대로 둬도 문제를 완성할 수 있습니다.
데이터와 솔루션이 더 이상 문제없이 동작한다는 자신이 들면 아래 ‘Verification’의 ‘start’ 버튼을 누릅시다. 기다리다 보면 ‘start’ 버튼이 있던 자리가 ‘fail’로 변합니다. 만약 ‘fail’이라는 결과를 받았다면 지금까지 작업한 내용 중 invalid한 내용이 있는 것이므로 이를 수정하고 다시 시도하시면 됩니다. invalid한 내용이라는 것은 데이터가 밸리데이터를 통과하지 못하거나, 각 솔루션의 지정된 타입과 실제 실행결과가 다르거나 spj에서 _fail 상태를 만나거나 등이 있습니다.
결과로 ‘ok’를 받았다면 등록한 모든 내용에 대해 valid하다는 것이며 이제 ‘Packages’ 메뉴에 가셔서 문제를 통째로 다운받을 수 있습니다. 다운받을 패키지는 필요한 내용에 따라 다르며, Linux 패키지를 다운받으면 별도의 스크립트를 거치지 않아도 테스트셋별로 입력/출력 데이터를 받을 수 있습니다. 이때 확장자가 없는 쪽이 입력 파일, 같은 번호의 .a 확장자를 가진 쪽이 해당 입력 파일의 메인 솔루션 출력 파일입니다.
또한 폴리곤의 장점 중 하나는 각 세션의 동작이 Git과 유사하다는 것입니다. ‘start’를 통해 문제 세션을 열고 작업을 하게 되면 위 추가 작업 내역처럼 내가 한 추가/수정/삭제 등의 작업 내역이 로그로 남는데 이때 지금 상태를 기록하고 싶다면 ‘Commit Changes’를 눌러 버젼을 기록할 수 있습니다. 또한 작업 중에 다른 사람이 새로운 버젼을 올렸다면 ‘Update Working Copy’를 통해 해당 버젼의 내용을 지금 작업 내용을 보존하며 합칠 수 있습니다. Git의 ‘commit’ & ‘push’ / ‘pull’과 비슷한 기능이라고 생각하면 편합니다. 문제 목록에서 Discard를 눌러 현재 작업 내용을 드랍하는 것도 가능합니다.