Network Architecture Search
Intro
기존에는 효율적인 딥러닝 모델을 찾기 위해 수많은 실험을 반복하고 경험적으로 최적의 파라미터를 찾아야 했습니다. 최근에는 이러한 과정을 딥러닝으로 해결하려는 연구가 이루어지고 있는데, 이러한 분야를 AutoML이라고 합니다. 즉, 딥러닝으로 딥러닝 모델을 찾는 것이라 할 수 있습니다. 이 글에서는 대표적인 AutoML 방법인 NAS(Network Architecture Search)와 NASNet에 대해 소개하려고 합니다.
NAS
먼저 소개할 논문은 2017년 ICLR에 발표된 논문 “Neural Architecture Search with Reinforcement Learning”입니다. NAS라고 알려진 이 논문은 강화학습을 이용한 뉴럴네트워크 구조 탐색 방법에 대해 소개하는데, 아래에서 설명할 NASNet이나 다른 AutoML 연구들에 아이디어를 제공한 논문이기도 합니다.
NAS는 두 가지 종류의 네트워크를 자동으로 생성하는 방법을 제안합니다. 하나는 image classification을 위한 convolutional neural network이고, 다른 하나는 NLP 등에 범용적으로 사용되는 recurrent cell입니다. 여기서는 CNN의 생성에 대해서만 살펴보겠습니다.
Generate Model Descriptions with a Controller RNN
NAS의 기본적인 아이디어는 단순합니다. RNN으로 구성된 controller를 이용해 child network를 만들고, 특정 데이터셋 (ex. CIFAR-10)에 대해 validation accuracy가 수렴할 때까지 child network를 학습시킵니다. 그러면 수렴한 validation accuracy를 reward로 설정하여 reward의 기댓값을 높이는 방향으로 policy gradient를 이용해 controller를 학습하게 됩니다.
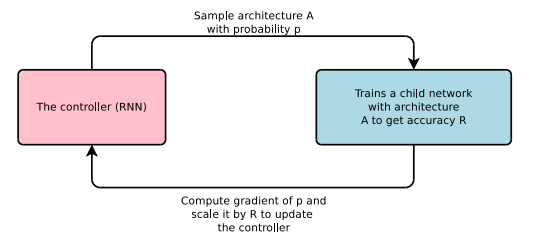
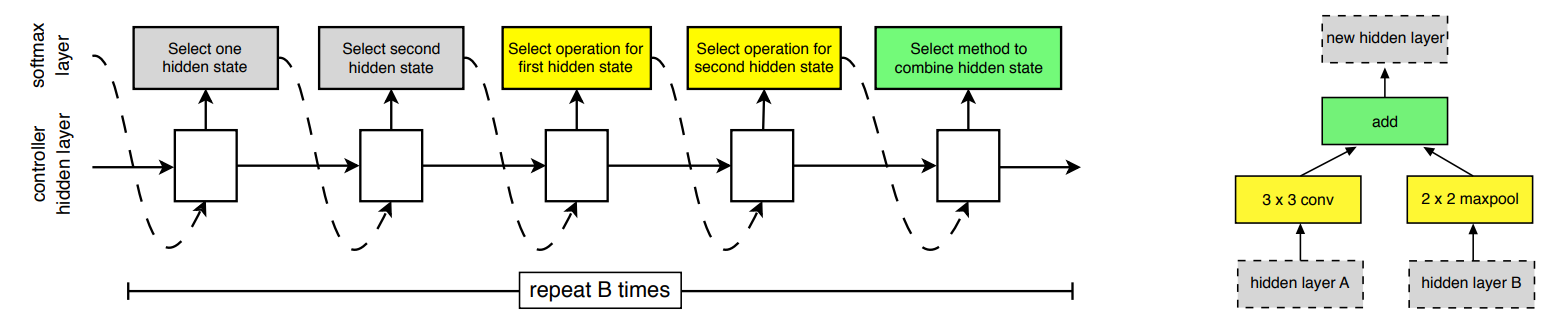
Controller는 필터의 개수와 크기, stride 등 하나의 convolutional layer를 표현하는 hyperparameter들을 결정합니다. 구체적으로는 다음의 리스트에서 각각 옵션을 하나씩 선택하게 됩니다.
- filter height in [1, 3, 5, 7]
- filter width in [1, 3, 5, 7]
- number of filters in [24, 36, 48, 64]
- strides in [1, 2, 3] (or 1)
위의 값들을 모두 결정하면 하나의 레이어가 만들어지고, 이를 $N$번 반복하면 $N$개의 서로 다른 레이어가 만들어집니다. Controller는 RNN으로 구성되어 매 선택의 순간마다 이전 선택의 결과에 영향을 받도록 했습니다.
그동안 image classification의 연구 결과들을 보면 GoogLeNet이나 ResNet과 같이 branching이나 skip connection을 적용한 네트워크의 성능이 우수했습니다. 따라서 NAS에서도 이러한 connection을 예측할 수 있도록 하기 위해 anchor point를 도입했습니다. Anchor point는 $i$번째 레이어가 $0$ ~ $i-1$번째 레이어들과 각각 연결될 확률을 계산하는 지점이라 할 수 있습니다. 아래 그림에서 convolutional layer의 파라미터를 결정하는 부분 뒤에 anchor point가 삽입된 것을 볼 수 있습니다.
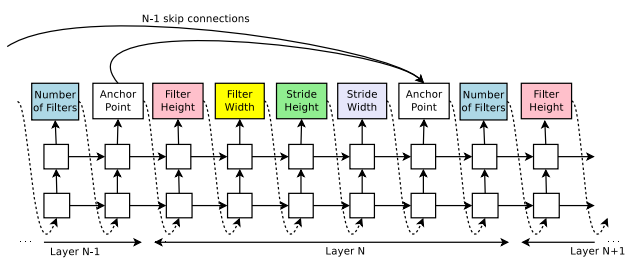
단, 이러한 방식의 connection을 도입하면 특정 확률에 따라 일부 레이어는 input이나 output 레이어가 전혀 없을 수도 있습니다. 이 문제를 해결하기 위해 input이 없는 레이어들은 초기 입력 이미지를 input으로 연결하고, output이 없는 레이어들은 기존의 최상단 레이어에 depth 방향으로 이어붙였습니다. 또한 dimension이 맞지 않는 경우에는 zero padding을 적용했습니다.
Training with REINFORCE
Controller의 학습은 RNN controller의 parameter vector인 $\theta_c$를 업데이트하는 것으로 생각할 수 있습니다. 수식으로 나타내면 다음의 식을 최대화하는 것으로 볼 수 있습니다.
\[J(\theta_c)=E_{P(a_{1:T};\theta_c)}[R]\]여기서 $T$는 controller가 예측해야 할 파라미터의 개수, $R$은 reward (child network로부터 얻은 validation accuracy), $a_{1:T}$는 action list (controller가 선택하는 hyperparameter들의 list)입니다. 즉, 우리가 원하는 것은 reward $R$의 기댓값을 최대화하는 최적의 policy (각 action의 확률)을 찾는 것입니다. 이를 위해 policy gradient를 이용하게 되는데, 구체적으로는 REINFORCE rule을 사용합니다.
\[\nabla_{\theta_c}J(\theta_c)=\sum_{n=1}^TE_{P(a_{1:T};\theta_c)}[\nabla_{\theta_c}logP(a_t|a_{(t-1):1};\theta_c)R]\]만약 $m$개의 sample을 하나의 batch로 한 번에 update하고자 하는 경우, 위 식을 다음과 같이 approximate할 수 있습니다.
\[\frac{1}{m}\sum_{k=1}^{m}\sum_{t=1}^{T}\nabla_{\theta_c}logP(a_t|a_{(t-1):1};\theta_c)R_k\]$R_k$는 $k$번째 child network로부터 얻은 validation accuracy입니다. 단, 위 식으로 학습을 할 경우 variance가 매우 커질 수 있기 때문에 baseline function을 도입한 다음의 식을 사용합니다.
\[\frac{1}{m}\sum_{k=1}^{m}\sum_{t=1}^{T}\nabla_{\theta_c}logP(a_t|a_{(t-1):1};\theta_c)(R_k-b)\]Results
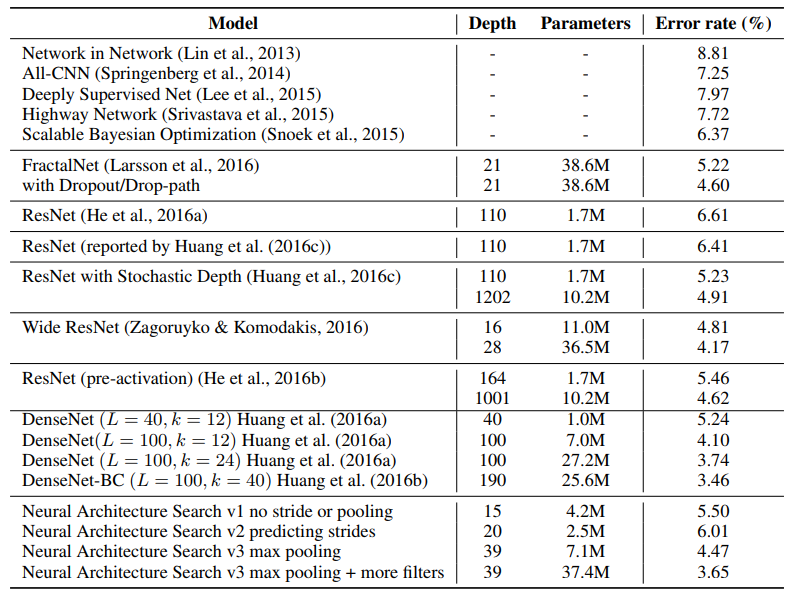
연구진들은 NAS의 성능을 측정하기 위해 CIFAR-10으로 학습을 진행했습니다. 무려 800개의 GPU로 약 한 달간 학습을 수행했고, 그 결과 기존에 성능이 좋았던 다른 모델들과 비슷한 수준의 성능을 보였습니다.
NASNet
기존 NAS 방법의 가장 큰 단점은 학습 시간이 매우 오래 걸린다는 것이었습니다. CIFAR-10은 작은 데이터셋임에도 불구하고 무려 한 달간 학습을 수행해야 겨우 기존의 모델들과 비슷한 성능을 내는 정도였고, 이렇게 해서 얻은 모델은 다른 데이터셋에 적용하기 어렵다는 단점도 있었습니다.
2018년 CVPR에 발표된 논문 “Learning Transferable Architectures for Scalable Image Recognition” 에서는 기존 NAS의 단점을 보완하는 방법을 제시합니다. 학습 시간도 7일 정도로 짧아졌고, state-of-the-art 수준의 모델을 찾는 데 성공했습니다. 무엇보다도, CIFAR-10으로 학습한 모델에 약간의 변형을 거쳐 ImageNet을 비롯한 다른 데이터셋에 적용시켰을 때 상당히 우수한 성능을 보였습니다. 연구진들은 이 모델을 NASNet이라고 명명했습니다.
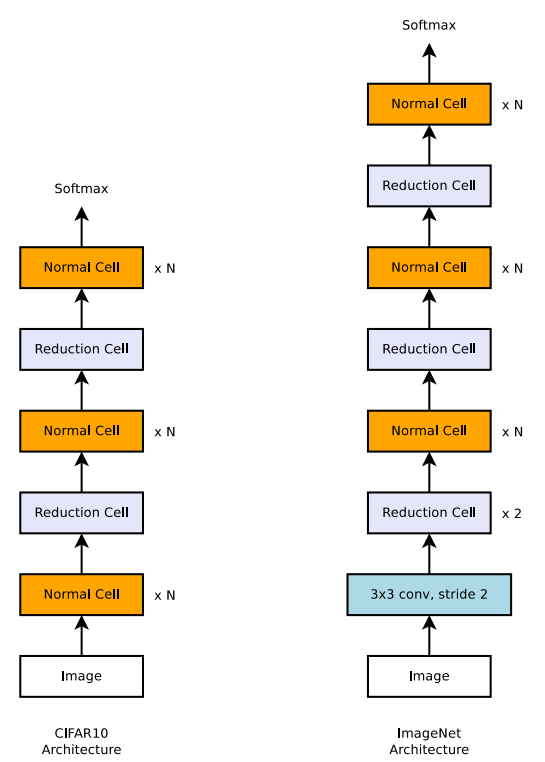
NASNet의 핵심적인 아이디어는 기존 NAS 방법을 유지하되, 새로운 search space를 찾는 것입니다. 기존 NAS는 사실상 모든 레이어마다 서로 다른 hyperparameter들을 예측하여 네트워크를 구성했지만, NASNet은 Normal Cell과 Reduction Cell이라는 두 작은 단위의 구조만을 예측한 후 두 cell을 반복적으로 쌓아올려 네트워크를 구성했습니다. 따라서 기존 NAS에 비해 search space가 작아져 학습에 걸리는 시간 또한 줄어들게 됩니다.
Convolutional Cells
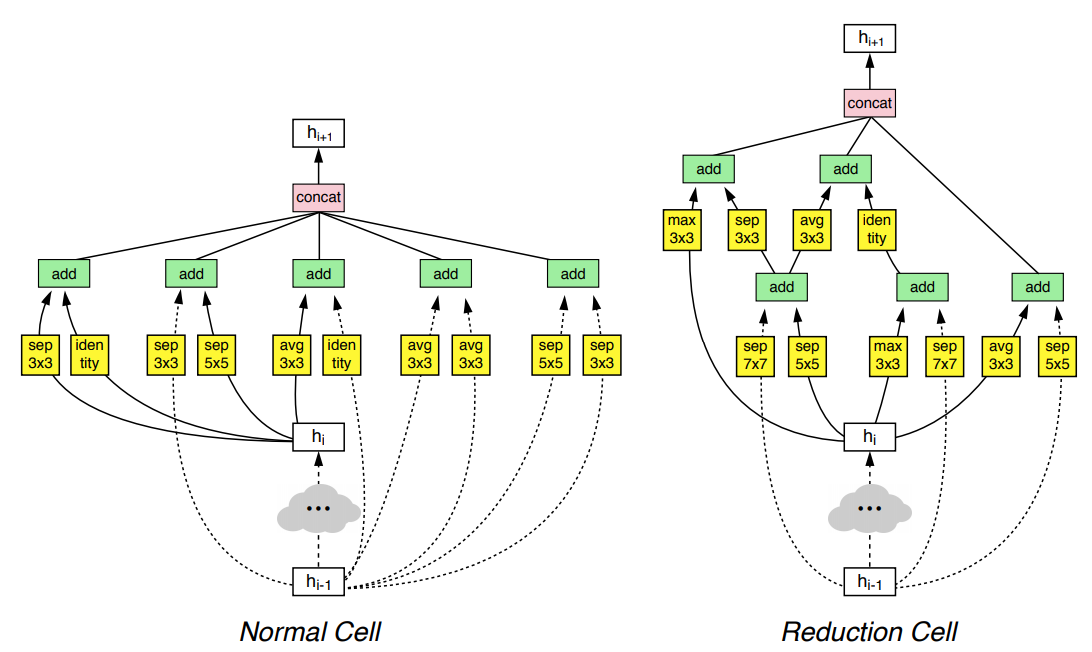
NASNet은 앞서 언급했듯이 Normal Cell과 Reduction Cell이라는 단위로 이루어집니다. Normal Cell은 input과 output의 dimension이 같은 convolutional cell이고, Reductoin Cell은 output의 dimension이 input의 절반이 되는 convolutional cell입니다.
하나의 convolutional cell은 다시 $B$개의 Block으로 구성됩니다. 각 Block은 두 개의 hidden state를 입력으로 받아 각각 특정 operation을 적용한 후, 특정 method에 따라 두 결과를 combine하여 새로운 hidden state를 만듭니다. 좀 더 쉽게 말하자면 두 개의 레이어를 입력으로 선택하여 어떤 연산을 수행한 후 하나의 출력 레이어를 만드는 것입니다. 즉, 2개의 hidden state, 2개의 operation, 1개의 combine method로 총 5가지의 hyperparameter가 하나의 Block을 정의하게 되고, 이를 RNN Controller로 예측하는 것입니다.
선택 가능한 hidden state(입력)은 $h_i$ , $h_{i-1}$, 또는 현재 cell에서 이전에 생성된 Block의 output입니다. $h_i$와 $h_{i-1}$은 이전 두 cell의 output에 해당합니다. 기존 NAS와 달리 skip connection이 가능한 레이어의 범위를 제한한 것도 search space를 줄이는 데 기여했다고 볼 수 있습니다.
선택 가능한 operation의 종류는 다음과 같습니다.
- identity
- 1x3 then 3x1, 1x7 then 7x1 convolution
- 3x3 dilated convolution
- 3x3 average pooling
- 3x3, 5x5, 7x7 max pooling
- 1x1, 3x3 convolution
- 3x3, 5x5, 7x7 depthwise-separable convolution
combine method로는 element-wise addition과 concatenation 중 하나를 선택하게 됩니다.
이 과정을 $B$번 반복하면 서로 다른 $B$개의 Block이 생성됩니다. 마지막으로 현재 cell 내에서 사용되지 않은 (다른 block의 input으로 연결되지 않은) hidden state들을 depth 방향으로 이어붙여 cell의 output으로 설정합니다. 우리가 생성해야 하는 cell은 Normal Cell과 Reduction Cell의 두 가지이므로, 2 x $B$ 개의 Block을 만들어서 앞의 $B$개는 Normal Cell에 사용하고, 뒤의 $B$개는 Reduction Cell에 사용합니다.
연구진들이 찾은 최적의 Normal Cell과 Reduction Cell은 다음과 같습니다.
Results
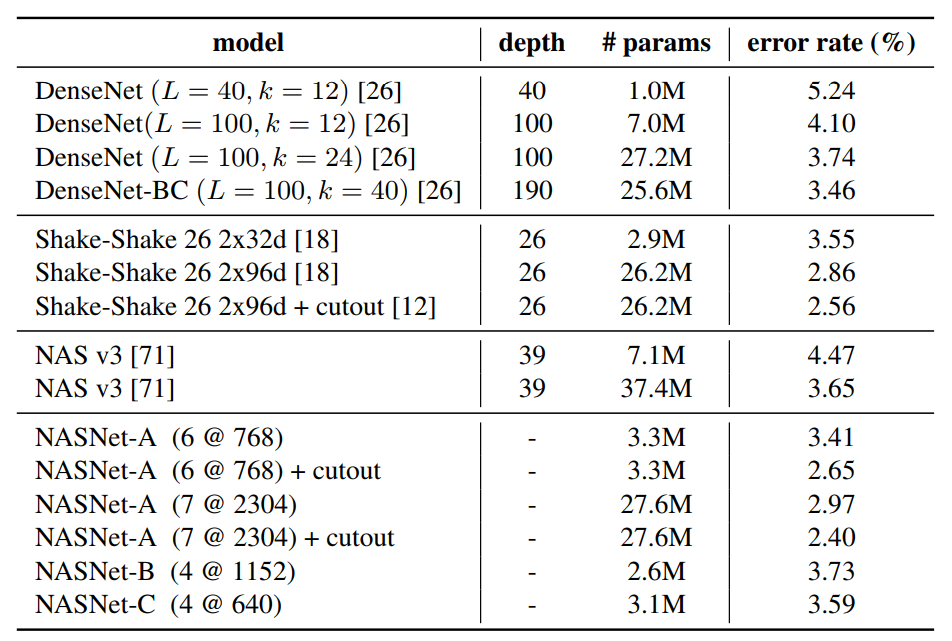
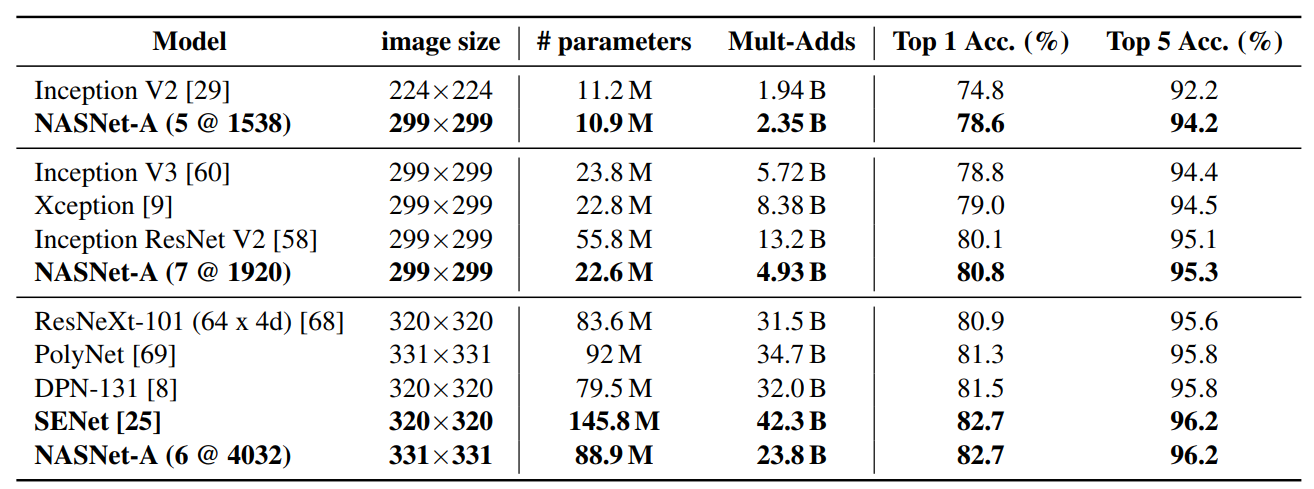
NASNet은 CIFAR-10과 ImageNet에서 state-of-the-art 수준의 성능을 보였습니다. ImageNet에 사용된 모델은 CIFAR-10으로 생성한 모델 하단에 2개의 Reduction Cell과 1개의 3x3 Conv layer만을 추가한 것으로, 매우 좋은 transferability를 확인할 수 있습니다. 특히 기존 state-of-the-art 모델이었던 SENet보다 파라미터 수는 훨씬 적으면서도 거의 동등한 정확도를 기록했습니다.
Conclusion
NASNet은 기존 NAS의 한계를 극복하면서 AutoML의 가능성을 보여주었습니다. NASNet 이후에도 학습 속도를 더 향상시킨 ENASNet (Efficient NASNet)이 등장했는데, 단일 GTX 1080 ti 만으로 하루도 안 걸려서 (16시간) 학습시킨 결과 기존 NAS와 비슷한 성능의 모델을 찾을 수 있었습니다. 그 외에도 성능을 개선한 PNASNet(Progressive NASNet), 모바일 플랫폼에 최적화된 MNASNet 등 NASNet의 후속 연구가 활발히 이루어지고 있습니다.
References
[1] Barret Zoph, Quoc. V. Le. Neural Architecture Search with Reinforcement Learning. In International Conference on Learning Representations, 2017.
[2] Barret Zoph, et al. Learning Transferable Architectures for Scalable Image Recognition. In Computer Vision and Pattern Recognition, 2018.