WAVENET: A GENERATIVE MODEL FOR RAW AUDIO
소개
2016년 구글 딥마인드에서 오디오 생성 모델인 wavenet에 관한 논문을 공개했습니다.
이 당시 대부분의 TTS 모델은 녹음된 음성 데이터를 쪼개고 조합해서 음성을 생성하는 방식인 Concatenative TTS를 기반으로 구현되었습니다. 이 방식은 기본적으로 많은 양의 데이터를 필요로 했고, 화자나 톤을 바꾸는 등의 변형을 할 때마다 새로운 데이터가 필요했습니다. 이에 따른 대안으로 통계적인 방법으로 음성을 생성하는 parametric TTS 방식이 주목받았지만 Concatenative TTS에 비해서 생성된 음성이 덜 자연스러웠습니다.
wavenet은 기존의 방식과 다르게 오디오의 파형을 직접 모델링하여 훨씬 자연스러운 음성를 생성하는데 성공했고, 컨디션 모델링을 통해서 다양한 음성을 생성할 수 있었습니다. 또한, wavenet은 음악 생성을 포함한 다양한 오디오 생성 분야에도 응용될 수 있음을 보여주었습니다.
WaveNet
wavenet은 오디오 파형 데이터를 직접 사용해서 새로운 파형을 모델링합니다. 파형 $x={x_1, …, x_T}$는 조건부 확률을 이용하여 다음과 같이 나타냅니다.
| $p(x)=\prod_{t=1}^T p(x_t | x_1, …, x_{t-1})$ |
즉, 각 샘플 $x_i$의 확률 분포는 미래의 샘플 $x_{i+1}, x_{i+2}, …, x_T$에 의존하지 않고 오직 이전 샘플에만 의존해서 결정됩니다.
Dilated causal convolutions
wavenet에서는 아래 그림과 같이 오직 과거의 파형 정보만 접근할 수 있도록 causal convolutional layer를 여러겹 쌓았습니다. 실제 구현할 때는 단순히 이전 층의 결과를 쉬프팅하면서 1d convolutional layer를 쌓으면 됩니다.
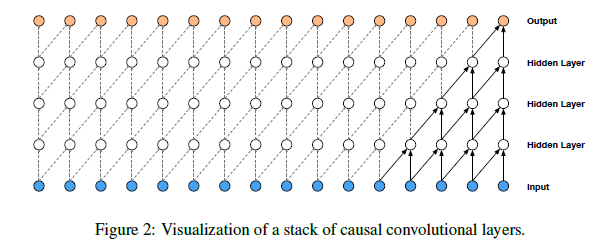
학습 시에는 ground truth를 모두 알고 있기 때문에 모든 스탭에 대한 예측을 동시에 진행할 수 있습니다(teacher forcing). 음성을 생성할 때는 예측을 한 스탭씩 진행하게 되고 매 스탭마다 결과 값은 다음 스탭의 입력 값으로 주어지게 됩니다.
이런식으로 긴 시계열을 다룰 때 RNN을 사용하지 않고 causal convolutional layer를 사용하면 모델을 빠르게 학습할 수 있습니다. 하지만, 동일한 dilation의 convolutional layer를 쌓으면 receptive field를 넓히기 위해서 많은 층이 필요하다는 단점이 있습니다. 예를 들어, 위 그림에서는 4개의 층을 쌓았지만 receptive field가 $5(=\text{#layers}+\text{filter length}-1)$ 밖에 되지 않습니다.
이 문제를 해결하기 위해 wavenet은 일정 스탭(dilation)을 건너뛰면서 filter를 적용하는 dilated convolution을 사용합니다. dilated convolution은 적은 층 수의 layer로도 receptive field를 효과적으로 넓힐 수 있게 만듭니다. 예를 들어서 아래 그림은 dilation이 각각 1, 2, 4, 8인 dilated causal convolution layer를 차례로 쌓은 모습을 나타냅니다. 이 때, receptive field는 16이 됩니다.

논문에서는 dilation을 일정 제한까지 두 배씩 증가시키고 이를 반복(1, 2, 4, …, 512, 1, 2, 4, …, 512, 1, 2, 4, …, 512)하며 층을 쌓아 올렸습니다. 이렇게 함으로써 층 수에 대해 지수스케일로 receptive field을 늘리고 모델의 표현력을 증가시켰습니다.
Softmax distributions
논문에서 conditional distribution을 모델링할 때 softmax distibution을 사용했습니다. 일반적으로 오디오는 16-bit 정수 값으로 저장하기 때문에 그대로 사용하면 스탭마다 총 65536개의 확률을 다뤄야 합니다. 이 수를 줄이기 위해서 오디오 데이터에 $\mu$-law companding을 적용해서 256개 중 하나의 값으로 양자화시켜 사용했습니다.
$\mu$-law companding:
| $f(x_t)=\text{sign}(x_t){\ln(1+\mu | x_t | ) \over \ln(1+\mu)}$ |
이러한 non-linear한 양자화 방식이 linear한 양자화 방식보다 더 좋은 성능을 보였다고 합니다.
Gated activation units
Wavenet은 PixelCNN에서 사용된 gated activation unit을 사용합니다.
Gated activation unit:
$z=\tanh(W_{f,k}x)\odot\sigma(W_{g,k}x)$
여기서 각 연산과 변수의 의미는 다음과 같습니다.
*: convolution 연산
$\odot$: element-wise 곱셈
$\sigma(\cdot)$: 시그모이드 함수
$W$: 학습 가능한 convolution filter
$f$: filter
$g$: gate
$k$: layer의 번호
매 층마다 입력 값이 주어지면 filter와 gate에 대한 convolution을 각각 구한 뒤 element-wise 곱을 구합니다.
Residual and skip connections
Wavenet은 학습시 수렴 속도를 높이고 깊은 모델을 만들기 위해서 매 층마다 residual, skip connection을 사용합니다. wavenet의 전체 구조는 다음과 같습니다.
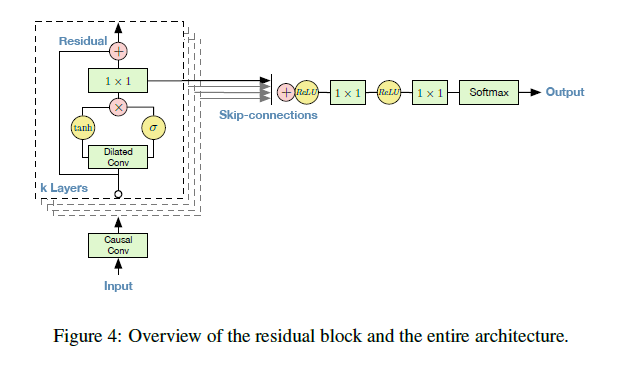
논문에서는 residual, skip connection를 어떻게 구현했는지 자세히 묘사하지는 않았습니다. 그림으로 봐서는 gated activation unit을 적용한 뒤 residual에 대한 1x1 convoltion과 skip connection에 대한 1x1 convolution을 따로 구했을 것으로 보입니다.
Conditional WaveNets
| Wavenet은 조건 $h$가 주어졌을 때의 조건부 확률인 $p(x | h)$를 다음과 같이 모델링할 수 있습니다. |
| $p(x | h)=\prod_{t=1}^T p(x_t | x_1, …, x_{t-1}, h)$ |
이렇게 모델에 조건을 추가함으로써 wavenet은 특별한 성질을 가진 오디오를 생성할 수 있습니다. 예를 들어서, 여러 명의 화자에 대한 음성 데이터가 주어졌다면 화자에 대한 정보를 조건으로 설정하여 각 화자에 대한 음성을 생성할 수 있게 만들 수 있습니다. TTS의 경우에는 텍스트에 대한 정보가 필요하기 때문에 이를 조건으로 설정해서 모델을 학습하면 됩니다.
wavenet의 조건을 설정하는 방식에는 전역적인 방법(global conditioning)과 지역적인 방법(local condioning)이 있습니다. 이름에서 유추할 수 있듯이, 전역적인 방법을 사용하면 주어진 조건 정보가 모든 스탭에 동일한 영향을 주게 됩니다(ex. 화자에 대한 정보). 이 때 앞에서 설명한 activation function이 다음과 같이 변하게 됩니다.
$z=\tanh(W_{f,k}x+V_{f,k}^T h)\odot\sigma(W_{g,k}x+V_{g,k}^T h)$
여기서 $V$는 학습가능한 linear projection을 나타냅니다.
지역적인 방법은 조건이 시계열 $h_t$로 주어졌을 때 사용할 수 있습니다(ex. TTS 모델에서 linguistic features). $h_t$를 activation function에 적용하기 위해서 $h_t$의 타입 스탭 수를 오디오의 타임 스탭 수와 똑같게 맞춰줘야 합니다. 이를 위해 transposed convolution을 사용하거나 단순히 각 스탭을 복제해서 맞춰줄 수 있습니다. 스탭 수를 맞춰준 조건 정보를 $y=f(h)$라고 할 때 activation function은 다음과 같이 변하게 됩니다.
$z=\tanh(W_{f,k}x+V_{f,k}y)\odot\sigma(W_{g,k}x+V_{g,k}y)$
여기서 $V_{f,k}*y$는 1x1 convoltion을 나타냅니다.
예제
딥마인드 블로그에서 wavenet으로 생성한 음성, 음악을 들을 수 있습니다.
(https://deepmind.com/blog/article/wavenet-generative-model-raw-audio)
구현
pytorch로 spectrogram conditional wavenet을 구현해보았습니다.
(전체 코드: https://github.com/choyi0521/wavenet-pytorch)
데이터 셋으로 LJspeech을 사용했고, log mel spectrogram을 구한 뒤 타임 스탭 수를 맞춰주어서 조건으로 사용했습니다. 아래는 local conditioning을 하는 wavenet 모델의 forward 함수 코드입니다.
def forward(self, x, cond):
x = self.input_conv(x)
skip = torch.zeros((x.shape[0], self.hidden_channels, x.shape[2]),
dtype=torch.float,
device=self.device)
for i, dilation in enumerate(self.dilations):
padded_x = self.pad[i](x)
padded_cond = self.pad[i](cond)
fx = self.filter_convs[i](padded_x)
gx = self.gate_convs[i](padded_x)
fc = self.cond_filter_convs[i](padded_cond)
gc = self.cond_gate_convs[i](padded_cond)
z = torch.tanh(fx+fc)*torch.sigmoid(gx+gc)
skip += self.skip_convs[i](z)
x += self.residual_convs[i](z)
y = self.relu(skip)
y = self.output_conv1(y)
y = self.relu(y)
y = self.output_conv2(y)
return y
참고문헌
- Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu. WaveNet: A Generative Model for Raw Audio. 2016.
- https://deepmind.com/blog/article/wavenet-generative-model-raw-audio