강화학습 핵심 개념 정리 (1)
강화학습 핵심 개념 정리 (1)
Reinforcement Learning Key Concepts
이 시리즈의 목표는 강화학습을 잘 모르는 사람이 해당 분야의 전반적인 흐름을 파악하고 이 글을 토대로 세부적인 내용을 찾아볼 수 있게 하는 것입니다. 이번 글에서는 여러가지 주요 용어를 살펴보고, 다음 글에서는 Q learning 과 Policy Gradient 에 대해서 살펴보겠습니다.
문제 정의
강화학습에서 다루는 문제가 어떤 것인지부터 살펴봅시다.
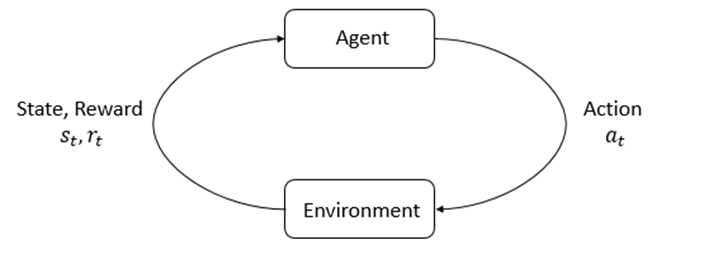
주변 상태에 따라 어떤 행동을 할지 판단을 내리는 주체인 에이전트가 있고, 에이전트가 속한 환경이 있습니다. 에이전트가 행동을 하면 그에 따라 상태가 바뀌게 되고, 보상을 받을 수도 있습니다. 강화학습의 목표는 주어진 환경에서 보상을 최대한 많이 받을 수 있는 에이전트를 학습하는 것입니다.
이제 위의 내용을 정확한 용어로 정의해보겠습니다.
-
상태(State)는 현재 시점에서 상황이 어떤지 나타내는 값의 집합입니다. 가능한 모든 상태의 집합을 state space라고 부르고, $ S $ 로 적습니다. 특정 시각 $ t $ 에서의 상태값은 $ s_t $ 로 적습니다.
-
행동(Action)은 우리가 취할 수 있는 선택지를 일컫는 말입니다. 가능한 모든 행동의 집합을 action space라고 부르고, $ A $ 로 적습니다. 특정 시각 $ t $ 에서 상태 $ s_t $ 를 본 뒤 취했던 행동은 $ a_t $ 로 적습니다.
-
에이전트가 어떤 행동을 했을 때 따라오는 이득을 보상(Reward) 이라고 합니다. 말 그대로 보상이기 때문에 높을수록 좋습니다. 보상값에 -1을 곱해서 비용(Cost)이라고 부르기도 하고, 이 경우는 낮을수록 좋습니다.
주의할 점은 보상이 현재 상태, 행동에 대해서만 평가하는 즉각적인 값이라는 것입니다. 장기적으로 가장 좋은 결과를 얻을 수 있는 행동을 고르기 위해선 현재 보상이 제일 높은 행동이 아니라 누적 보상이 제일 높은 행동을 골라야 합니다. 누적 보상의 개념은 아래 “가치 함수” 부분에서 좀 더 자세히 다루겠습니다.
같은 알고리즘이더라도 보상 함수를 어떻게 정의하느냐에 따라 성능이 달라질 수 있습니다. 각 경우에서 보상을 어떻게 할당할지 결정하는 것을 reward shaping 이라고 부릅니다.
상태 $ s_t $ 에서 행동 $ a_t $ 를 취해 상태가 $ s_{t+1} $ 로 바뀌면서 얻은 보상은 $ r_t $ 라고 하고1, 이를 나타내는 함수를 $ R: S \times A \times S \rightarrow \mathbb{R} $ 로 나타냅니다.
-
주어진 문제 상황에서 행동하는 주체를 에이전트(Agent)라고 부릅니다. 게임에서는 플레이어가 조작하는 캐릭터, 또는 조작하는 플레이어 본인이 에이전트가 될 것입니다.
에이전트가 판단하는 방식을 정책(Policy)이라고 부르는데, 에이전트와 혼용하는 경우가 많습니다. 정책을 수학적으로 나타내면 상태에 따른 행동의 조건부 확률, 즉 P(action|state)가 됩니다. 보통 현재 상태가 s일 때 확률분포 자체는 $ \pi ( \cdot | s)$ 로 나타내고, 특정 행동 a가 뽑힐 확률은 $ \pi(a|s) $ 로 나타냅니다. 또 현재 학습중인 정책(target policy)은 $ \pi $ 로 쓰고 과거에 데이터를 수집할 때 취했던 정책(behavior poilcy)은 $ \mu $ 로 쓰는 것이 관례입니다. 정책 중 가장 좋은 것을 optimal policy라고 부르고 $ \pi^* $ 로 나타냅니다.
추가적으로 한번에 하나의 에이전트가 아니라 여러 에이전트를 동시에 다루는 문제는 Multi-Agent 세팅이라고 부릅니다.
-
환경(Environment)은 문제 세팅 그 자체를 의미합니다. 게임에서는 에이전트가 취할 수 있는 행동, 그에 따른 보상 등 게임 자체의 모든 규칙이 환경이 됩니다. 즉 $ S, A, R $ 등은 모두 환경의 구성 요소가 됩니다. 플레이어가 조작할 수 있는 부분은 에이전트, 그 외의 모든 정해진 것들은 환경이라고 생각하면 됩니다.
강화학습의 중요한 가정 중 하나는 환경이 Markov property를 가진다는 것입니다. 이는 현재 상태만 참조하면 항상 필요한 모든 정보를 알 수 있다는 뜻입니다. 수학적으로 나타내면 $ s_{t+1} $ 와 $r_t $ 는 $ s_t, a_t$ 만의 함수라는 것이고, 그보다 과거의 상태/행동 $ s_i|{i<t} $ 와 $ a_i |{i < t} $ 에서 얻을 수 있는 필요한 정보는 이미 $ s_t $ 에 담겨 있어야 하므로 알 필요가 없다는 것입니다. 예를 들어 게임 상태를 스크린샷으로 정의하는 경우 테트리스는 모든 정보가 현재 화면의 스크린샷에 담겨 있기 때문에 Markov property를 만족하는 환경이지만, 배틀그라운드의 경우 현재 화면 스크린샷 하나만으로는 (과거에 봐서 알고 있는) 자신 기준 뒤쪽에 떨어져 있는 아이템 정보는 알 수 없기 때문에 Markov property를 만족하지 못하게 됩니다.

Deep Reinforcement Learning에서는 이런 경우 RNN 등을 추가해 과거 상태를 요약하는 벡터를 만들어 근사적으로 해결합니다. 즉 RNN의 internal context vector가 state space에 추가되는 것입니다.
-
초기상태(initial state)는 에이전트가 처음으로 환경과 상호작용할 때의 상태를 뜻합니다. 게임으로 치면 시작화면입니다. 가능한 초기상태는 여러 개일 수 있고, 그를 나타내는 확률분포가 있을 수도 있습니다.
-
종료상태(terminal state)는 도달할 경우 더 이상의 행동이 불가능한 상태를 뜻합니다. 게임으로 치면 게임오버 또는 클리어 했을 때가 됩니다.
-
에피소드(Episode)는 initial state부터 terminal state까지 에이전트가 거친 (상태, 행동, 보상)의 sequence를 의미합니다. Rollout이나 Trajectory라고 부르기도 합니다.
여담으로, 행동이 다음 상태에 영향을 끼치지 않는 경우는 Contextual Bandit, 거기에다 상태가 하나뿐인 경우는 Multi-Armed Bandit 문제라고 부르며 추천 시스템 등에서 주로 다루게 됩니다.
Terms
이제 강화학습 분야에서 자주 쓰이는 용어와 개념을 살펴보겠습니다.
가치 함수
위에서 언급했던 것과 같이 보상은 단기적인 이득만 나타내기 때문에, 각 행동이 얼마나 가치 있는지 판단하기 위해서는 누적 보상 값을 예측할 수 있어야 합니다2. 이를 수학적으로 정의한 것이 가치함수입니다.
먼저 t번째 시각 이후의 누적 보상을 나타내는 $ G_t $ 를 정의하겠습니다.
\[G_t \stackrel{def}{=} r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + ... = \sum_{i=t}^T \gamma ^{i-t}r_i = r_t + \gamma G_{t+1}\]여기서 $T$ 는 종료 시점의 시각이고, $ \gamma $ 는 discount factor 입니다. 0에서 1사이의 값을 취하게 되고, 0에 가까울수록 미래에 받을 수 있는 보상보다 지금 당장 얻을 수 있는 보상에 더 가중치를 주게 되고, 1에 가까울수록 즉각적인 보상과 미래에 받을 수 있는 보상을 동등하게 취급합니다. 직관적으로는 같은 돈을 벌 수 있다면 나중에 받는 것보다 지금 당장 받는게 이득이라는 사실을 반영한 것으로 볼 수 있고, 보통 0.99에 가까운 값으로 설정합니다. 또한 $ \gamma $ 는 여러 알고리즘의 수렴성 증명에도 사용됩니다.
이제 state에 대한 value function을 살펴보겠습니다. 주어진 상태 $ s $ 에서 행동 $ a $ 를 취했을 때 보상 $ r $ 를 받으면서 새로운 상태는 $ s’ $ 일 확률을 $ p(s’, r |s, a) $ , $ (s’, r) $ 의 분포를 $ p(\cdot|s, a)$ 로 적으면 value function은 아래와 같이 정의됩니다.
\[V_\pi(s) \stackrel{def}{=} E_\pi[G_t |S_t=s]\]즉 상태 $ s $ 에서 출발해 정책 $ \pi $를 따라 행동할 경우 얻을 수 있는 누적보상 $ G_t $ 의 기댓값을 그 상태 $ s $ 의 가치 함수로 정의합니다. 또한 가치 함수는 아래의 성질을 만족합니다.
\[E_\pi[G_t |S_t=s] \\ = E_{a\sim\pi(\cdot|s)}E_{s', r_t\sim p(\cdot|s,a)}[r_t + \gamma G_{t+1}] \\ = \sum_a \pi(a|s)\sum_{s', r_t}p(s',r_t|s, a) [r_t + \gamma v_\pi(s')]\]위와 같이 가치 함수를 재귀적으로 나타낼 수도 있습니다. 이 식을 value function에 대한 벨만 방정식(Bellman equation)이라고 합니다. 주어진 policy $ \pi $ 에 대해 벨만 방정식을 만족시키는 함수는 $ v_\pi $ 가 유일합니다. 즉 $ \pi $ 를 알 때 대응되는 value function을 찾고 싶다면 벨만 방정식을 만족시키는 함수를 찾으면 됩니다.
마찬가지 방식으로 (state, action) pair에 대한 가치 함수를 정의할 수도 있습니다. 보통 해당 함수를 Q function 이라고 부릅니다.
\[Q_\pi(s, a) \stackrel{def}{=} E_\pi[G_t |S_t=s, A_t=a]\]이 경우 함수값은 주어진 상태 $ s $ 에서 행동 $ a $ 를 한 후 얻을 수 있는 누적 보상의 기댓값이 됩니다. 마찬가지로 $ Q_\pi $ 는 아래 벨만 방정식의 유일한 해입니다.
\[Q(s,a)=E_{s',r\sim p(\cdot|s, a)}[r+\gamma E_{a' \sim\pi}[Q(s', a')]]\]$ V_\pi $ 와 $ Q_\pi$ 의 정의로부터 아래 성질도 성립합니다.
\[V_\pi(s) = E_{a\sim\pi(\cdot|s)}[Q_\pi(s,a)]\]마지막으로 optimal policy에 대한 가치 함수와 Q 함수를 정의하겠습니다. 여러 policy 중 누적 보상의 기댓값이 가장 큰 policy를 optimal policy라고 부르는데, 이를 만족하면 가치 함수 또한 모든 $ s $ 에 대해 가장 커지게 됩니다 3.
\[V^*(s) = \underset{\pi}{max}\space V_\pi(s) = \underset{\pi}{max} \space E_\pi[G_t |S_t=s]\] \[Q^*(s,a)=\underset{\pi}{max}\space Q_\pi(s,a) = \underset{\pi}{max} \space E_\pi[G_t |S_t=s, A_t=a]\]결국 optimal policy는 모든 가능한 policy에 대해서 그때그때 가장 좋은 policy에 따라 행동하는 것과 동일하다고 볼 수 있습니다. 그리고 아래 성질이 성립합니다.
\[V^*(s) = \max_a Q^*(s, a)\]Monte Carlo, Temporal Difference, Bootstrapping
위에서 정의한 가치 함수를 실제로 구하는 방법엔 크게 Monte Carlo 계열과 Temporal Difference (이하 TD) 계열이 있습니다.
먼저 몬테카를로(Monte Carlo) 방식에 대해 알아보겠습니다. 위에서 살펴본 것처럼 $ V_\pi(s) $ 는 $ E_\pi[G_t |S_t=s] $ 와 동일한데, 이를 샘플링을 통해서 구해 $ V_\pi(s)$ 가 해당 값과 가까워지게 학습하는 방식을 통틀어서 몬테카를로 방법이라고 합니다. 즉 $ \pi $ 를 이미 알고 있을 때 에피소드의 처음부터 끝까지 $ \pi $ 를 따라 행동한 후, 수집한 데이터를 바탕으로 각 $ s_t $ 에 대응되는 누적 보상 $ G_t $ 를 구해서 $ V_\pi(s_t) $ 가 target value $ G_t $ 와 가까워지게 업데이트 하는 것을 반복하는 것입니다.
몬테카를로 방식은 직관적으로 이해하기 쉽지만 여러 단점이 있습니다. 먼저 이번 에피소드에서 $ G_t $ 를 구하기 위해선 종료 상태까지 방문해야 하므로 학습을 진행하기 위해선 에피소드가 끝나기를 기다려야 합니다. 만약 게임이 매우 길어진다면 학습을 자주 할 수 없게 되고, 마인크래프트 등 에피소드에 끝이라는 개념이 없고 계속 진행되는 문제 세팅의 경우 학습 대상을 정의하기 애매해집니다. 또한 종료 상태에 이르기 까지 선택 분기가 굉장히 많기 때문에 $ G_t $ 값의 variance도 커지게 됩니다.
반면 Temporal Difference 계열 알고리즘은 $ V $ 를 학습할 때 $ V $를 사용합니다. 이는 벨만 방정식 $V_\pi(s) = E_{a\sim\pi(\cdot|s)}E_{s’, r_t\sim p(\cdot|s,a)}[r_t + \gamma V_\pi(s’)]$ 의 우변을 target value로 삼아 $ V_\pi $ 를 업데이트한다는 뜻입니다. 즉 추정값을 사용해 이번 target value를 찾게 됩니다. $ r + \gamma V_\pi(s’) $ 를 TD target 이라고 부르고, TD target과 현재 $ V_\pi(s) $ 값의 차이를 TD Error라고 부릅니다.
TD 계열과 같이 추정값을 사용해서 추정값을 업데이트하는 방법을 통틀어 Bootstrapping 이라고 합니다. 이는 target value를 계산할 때 추정값이 필요하지 않은 Sampling 과 대비할 때 많이 사용하는 용어입니다.
Model-based, Model-free
딥러닝에서 모델이라는 단어는 뉴럴넷 구조 내지는 그 뉴럴넷이 표현하는 함수를 가리킵니다. ResNet 모델을 학습시킨다, 이 데이터에 적합한 모델은 BERT다 와 같이 사용합니다.
그런데 강화학습에서 모델은 다른 의미를 가집니다. 딥러닝에서 어떤 함수에 대한 가정4 을 모델이라고 부르지만 강화학습에서는 환경에 대한 가정을 모델이라고 부릅니다. 예를 들어서 바둑 같은 경우 (x, y) 위치에 검은 돌을 두는 행동 을 환경에 적용하면 그에 따라 얻게 되는 새로운 상태는 기존 바둑판에서 (x, y) 위치에 검은 돌이 추가된 상태 가 될 것입니다. 이런 식으로 환경이 어떻게 동작할지 기존 지식을 활용하거나 학습해서 사용하는 방식을 model-based 알고리즘이라고 부르고, 환경을 블랙박스로 다루는 방식을 model-free 알고리즘이라고 합니다.
Model-based 알고리즘은 기존 지식을 활용하는만큼 적은 양의 데이터로 효율적인 학습을 할 수 있다는 장점이 있고, Model-free 알고리즘은 환경에 대한 모델을 세우기 어려운 경우에도 사용할 수 있고 여러 도메인에 동일한 방법을 적용할 수 있다는 장점이 있습니다. 이때까지는 model-free 알고리즘이 인기가 많았지만 데이터 효율성 측면이나 safety가 중요한 경우 model-based 알고리즘을 사용하는 추세로 보입니다. Model-based 알고리즘의 대표적인 예시로 알파고가 있고, Model-free 알고리즘의 대표적인 예시로는 DQN이 있습니다.
이 글에서는 “모델” 이라고 적으면 딥러닝에서의 모델을 뜻하고, 강화학습에서의 모델을 지칭할 땐 model-free, model-based 등과 같이 영어로 적도록 하겠습니다.
On-policy, Off-policy, Importance Sampling
비전이나 NLP 같은 도메인과는 다르게, 강화학습에서 학습에 쓰이는 데이터는 외부에서 미리 준비해둔 데이터가 아니라 학습 대상인 모델이 과거에 경험한(생성한) 데이터입니다. 그런데 사용하는 강화학습 알고리즘의 특성에 따라 현재 모델로 생성한 데이터만 학습에 사용할 수도 있고, 과거의 모델로 생성한 데이터도 학습에 사용할 수도 있습니다. 전자의 알고리즘을 on-policy, 후자의 알고리즘을 off-policy라고 부릅니다.
이러한 차이가 발생하는 이유는 다음과 같습니다. 대부분의 강화학습 알고리즘에서는 모델 파라미터(=뉴럴넷 파라미터)를 업데이트하기 위한 식에 $ E_{a \sim \pi(\cdot|s)} [f(s, a)] $ 꼴이 들어가는 경우가 많습니다. 여기서 $a \sim \pi(\cdot|s) $ 는 주어진 state $ s $ 에서 $ \pi $ 를 따라 action을 샘플링한다는 것을 뜻하고 $ f $ 는 $ s $ 와 $ a $ 에 관련된 임의의 함수가 됩니다. 즉 $ \pi $ 에서 샘플링한 데이터로 특정 함수를 계산하는 경우가 많습니다. 그런데 알고리즘의 수학적 특성에 따라 action을 샘플링하는 분포가 현재 업데이트 대상인 policy와 같아야 하는 경우가 있고, 달라도 되는 경우가 있기 때문에 on-policy와 off-policy가 나눠지게 됩니다.
그런데 왜 알고리즘이 on-policy인지 off-policy인지가 왜 중요할까요? off-policy와 비교했을 때 on-policy는 큰 단점이 있습니다. 데이터 효율성이 떨어진다는 점입니다. 현재 시점 t에서 파라미터가 $ \theta_{(t)} $ 라고 둡시다. on-policy 알고리즘의 경우 파라미터를 업데이트하기 위해선 $ \pi_{\theta_{(t)}}$ 로부터 데이터를 샘플링해야 합니다. 이렇게 샘플링한 데이터를 $ D_t $ 라고 부릅시다. 이제 업데이트된 policy $ \pi_{\theta_{(t+1)}} $가 있을텐데, 이 파라미터를 업데이트할 땐 $ D_t$ 를 사용할 수 없고 $ D_{t+1} \sim \pi_{\theta_{(t+1)}}$ 를 새로 샘플링해야 합니다. 즉 policy를 한번 업데이트할 때마다 과거 데이터를 전부 버리고 새로 모아야 하는 것입니다. 데이터를 수집하는 비용이 많이 들 때도 문제가 될 것이고, 분산 학습 환경이라면 동기화 과정이 추가로 필요해져 역시 문제가 됩니다.
Importance Sampling을 이용하면 이 문제를 해결할 수 있습니다.
\[E_{a \sim \pi(\cdot|s)}[f(s,a)] = \sum_{ a}[\pi(a|s)f(s, a)] \\ = \sum_{a}[\mu(a|s)\frac{\pi(a|s)}{\mu(a|s)}f(s, a)] = E_{a \sim \mu(\cdot|s)}[\frac{\pi(a|s)}{\mu(a|s)}f(s, a)]\]위와 같이 식을 전개하면 $ \pi $ 에 대한 기댓값을 $ \mu $ 에 대한 기댓값으로 나타낼 수 있습니다. 이로써 과거 policy $ \mu $에서 샘플링한 action을 $ \pi $ 를 업데이트하는데 사용할 수 있게 됩니다. 바뀐 수식을 보면 $\pi(a|s)$ 와 $ \mu(a|s) $ 를 명시적으로 계산할 수 있어야 하는데, 다행히 대부분의 강화학습 세팅에서 우리는 policy를 계산할 수 있으므로 이 부분이 문제가 되지는 않습니다.
문제가 되는 것은 $ \mu(a|s) $ 가 분모에 있다는 점입니다. $ \pi(a|s) $ 와 $ \mu(a|s)$ 둘 다 확률값이기 때문에 [0, 1] 사이의 값을 가지게 되므로, $ \frac{\pi(a|s)}{\mu(a|s)} $ 의 값 자체가 매우 커질 수 있을뿐더러 variance도 커지게 됩니다. 그래서 해당 항의 범위에 제약을 걸거나 variance를 줄이는 것도 강화학습 알고리즘의 주요 관심사 중 하나입니다.
참고 자료
모르는 용어나 개념이 있을 때
- http://incompleteideas.net/book/RLbook2018.pdf
Policy Gradient 계열 알고리즘이 궁금할 때
- https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html
강화학습 관련 핵심 논문이 궁금할 때
- https://spinningup.openai.com/en/latest/spinningup/keypapers.html
- 논문을 읽을 땐 해당 논문의 openreview도 같이 읽어보면 도움이 될 때가 많습니다!
각주
-
$s_t$ 에서 $s_{t+1} $ 로 넘어갈 때 얻은 보상을 $r_{t+1} $ 라고 적는 경우도 있기 때문에 논문/책을 읽기 전에 어떤 표기를 따르는지 확인하는게 좋습니다. ↩
-
물론 어떤 state에서 특정 action을 취했을 때 얻을 수 있는 보상 r 도 우리가 미리 알 수는 없습니다. 다만 policy를 만들기 위해 여러가지 값을 예측하는 함수를 학습시킬 것인데, 예측 대상을 정할 때 보상보다는 누적 보상이 더 적합하다는 의미입니다. ↩
-
Optimal policy $ \pi^* $ 의 경우 모든 $ s $ 에 대해 다른 policy $ \pi $ 보다 더 큰 가치 함수 값을 가지게 됩니다. 만약 $ \pi^(s) < \pi(s)$ 인 $ \pi$ 가 있다면, 상태 $ s $ 에 방문했을 때만 $ \pi $ 를 따르고 다른 상태에서는 $ \pi^ $ 를 따르게 하는 방식으로 더 좋은 policy를 찾을 수 있게 되어 모순입니다. ↩
-
e.g. 이미지에 개가 있는지 판별하는 함수는 convolution layer와 fc layer를 쌓은 꼴로 나타낼 수 있을 것이다 ↩