Flash와 FTL
안녕하세요?
오늘은 flash와, flash에서 사용되는 기법인 FTL에 대한 간단한 글을 써보았습니다.
Flash의 특성
Flash(플래시 메모리)는 전기적으로 데이터를 저장하는 저장장치들을 일컫는 말입니다.
요즘 사용되는 대부분의 기계에는 flash가 들어갑니다. 대부분의 컴퓨터나 노트북에는 SSD가 들어가고, 데이터를 간편하게 휴대하기 위해 사용하는 USB나 스마트폰에 내장되어있는 저장장치도 대부분 flash입니다.
Flash는 Random read 속도가 빠르고, 전력 소모도 적고, 충격에도 강한 등의 많은 장점을 가지고 있어 널리 사용됩니다.
이런 flash에 데이터를 저장할 때, 공통적으로 몇 가지 특별한 속성을 가집니다.
이 때문에 flash에 데이터를 저장할 때에는 여러 흥미로운 문제들이 생겨나게 됩니다.
먼저 Flash는 page와 block이라는 저장 단위를 가집니다. Page는 flash의 최소 저장 단위이며, 4KB 정도의 크기를 갖습니다. Page들이 모이면 block이 되는데, 대략 128~256KB 정도의 크기를 가집니다.
또, flash에 데이터를 저장하기 위해서 flash는 다음과 같은 주요 3가지 operation을 지원합니다.
-
Read (page 단위): 한 page에 적혀있는 데이터를 읽습니다. 소요 시간은 수 십 us 정도입니다.
-
Erase (block 단위): 한 block의 비트를 모두 1로 바꿉니다. Erase가 완료된 block 내 page는 아래의 Program operation을 진행할 수 있습니다. 소요 시간은 수 ms 정도입니다.
-
Program (page 단위): Erase가 완료된 page의 특정 비트들을 1에서 0으로 바꿉니다. (즉, 데이터를 쓰는 것입니다). 소요 시간은 수 백 us 정도입니다.
흥미로운 점은, flash에 Program operation, 즉 쓰기를 하기 위해서는 Erase operation을 먼저 해주어야 하는데, Erase operation은 block 단위로 수행되며, 수행 속도가 굉장히 느립니다. (Read와 비교하면 거의 100배의 시간이 소요됩니다) 이 때문에 Flash에 데이터를 막 저장한다면, 엄청난 성능 저하를 일으키게 됩니다.
한 가지 예시를 통해 살펴보겠습니다.
편의를 위해 block size = 8byte, page size = 1byte라고 가정해보겠습니다. (실제로 block 하나에는 page가 64개 정도 들어갑니다)
현재 Flash의 한 block에 ABCDEFGH라는 데이터가 저장되어 있다고 가정해봅시다.
이 때, 데이터가 약간 수정되어 IBCDEFGH로 바뀌었다고 가정해봅시다.
단 한 page가 바뀌었음에도 이를 바꾸기 위해서는 (i) 나머지 7개의 page를 읽고, (ii) Block에 Erase operation을 진행하고, (iii) 8개의 page를 써주어야 합니다. 그야말로 엄청나게 비효율적인 방법입니다.
속도 뿐만이 아니라 이러한 방법은 Flash의 수명 또한 엄청나게 단축시킵니다. 총 가동시간과 수명이 비례하는 HDD와 달리, Flash는 P/E cycle(Program/Erase)이 수명에 영향을 미칩니다. 즉, 총 Program과 Erase 연산을 진행할 수 있는 횟수가 한정되어 있습니다.
P/E cycle은 flash에 따라 차이가 있으나, 10만 회~100만 회 정도를 갖습니다.
따라서 위 방식처럼 하나의 data가 수정될 때마다 erase를 해준다면, flash의 수명 또한 굉장히 짧아지게 될 것입니다.
위 문제를 해결하기 위하여 고안된 것이 FTL(Flash Translation Layer)입니다.
FTL
FTL은 Flash Translation Layer의 약자입니다. FTL은 logical address를 physical address로 변환해주는 역할을 합니다.
즉, 어떠한 logical address에 data를 write하라는 request가 왔을 때 이 데이터를 실제로 어디에 write할지 정한 뒤, 해당 physical address에 데이터를 write합니다. 나중에 해당 logical address에 대한 read request가 오면, 어떤 physical address에 데이터를 기록했는지 기억해서 해당 phyical address에서 data를 read한 뒤 반환합니다.
FTL이 존재할 경우, 데이터 저장이 훨씬 유연해지게 됩니다. 아까의 예시를 다시 살펴보도록 하겠습니다.
한 block에 ABCDEFGH가 적혀져 있을 때, 이를 IBCDEFGH로 바꾸기 위해서는 총 7번의 Read, 1번의 Erase, 8번의 Program operation이 필요했습니다.
하지만, 남는 block이 있다면 그냥 이 데이터를 다른 block에 적고, 해당 데이터를 어디에 적었는지 정보만 기록해놓으면 어떨까요?
이 경우 1번의 Program operation만 있으면 데이터의 저장을 완료할 수 있습니다. 대신 각 데이터를 저장할 때 어떤 physical address에 적었는지 정보를 적어주어야 합니다. 위 예시의 경우, 다음과 같은 형태를 띠게 됩니다. (저장되는 data의 logical address는 0~7이라고 가정합시다
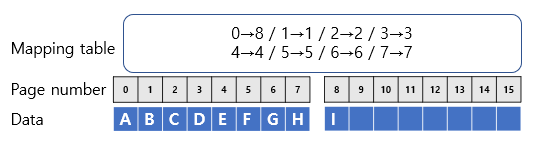
이렇게 각 logical page address마다 하나의 다른 physical page address에 mapping을 해주는 것을 page-level FTL이라고 부릅니다. 이런 저장 방식을 취한다면 flash의 operation을 굉장히 효율적으로 처리할 수 있습니다.
하지만 page-level FTL을 사용하면 발생하는 문제점들이 있습니다.
첫째는 사용되지 않는 데이터들이 남아있는 block들이 생겨나게 됩니다.
위 예시를 이어서 살펴봅시다. 이제 IBCDEFGH였던 데이터가 IBJKLMNO로 변했습니다. 이제 block에는 다음과 같이 데이터가 저장되어 있습니다.
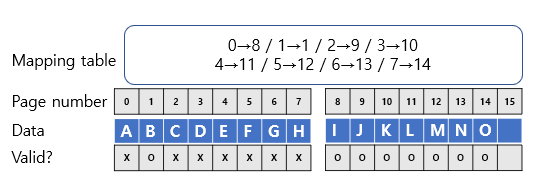
첫 번째 block을 보면, block 내의 8개의 page 중 단 1개만이 사용되고, 나머지 7개의 page는 무의미한(garbage) page입니다. 이런 식으로 사용되지 않는 page들이 늘어나면, 전체적인 space utilization이 안 좋아집니다.
이런 경우를 대비하여, FTL은 garbage가 많은 block을 찾아 적혀있는 데이터를 다른 곳에 옮겨적고, 해당 block을 Erase 시켜주는 작업을 진행해주어야 합니다. 이것을 Garbage Collection(GC)이라고 합니다. Garbage Collection을 할 때는, 당연하지만 일반적으로 valid한 page가 적은 block을 고를수록 좋습니다.
위 경우 Garbage Collection을 마친 결과는 다음 그림과 같습니다.
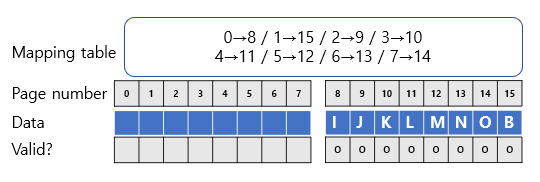
첫 block에 남아있던 유일한 데이터인 B를 마지막으로 옮기고, 그에 맞게 mapping table을 수정해주었습니다.
둘째는 조금 더 치명적인 문제입니다.
Mapping information을 저장하기 위해서는 추가적인 DRAM이 필요한데, 이를 위해 필요한 DRAM size가 생각보다 굉장히 큽니다.
하나의 page의 크기를 4KB, 그리고 mapping을 하는 데에 int형인 4byte가 필요하다고 가정해봅시다.
120GB SSD의 mapping information을 유지하는 데에는 총 120GB / 4KB * 4byte = 120MB의 DRAM이 필요합니다.
요즘은 1TB 크기의 SSD도 나오고 있는데, 만약 page-level FTL을 사용한다면 단순히 SSD 펌웨어를 위해서만 1GB의 DRAM을 필요로 하는 것이지요.
하지만 mapping table의 크기를 줄이는 것은 그리 쉽지 않습니다. 예컨대 page level mapping 대신, 각 block마다 mapping을 해주는 block level mapping을 사용한다면, block당 page의 갯수만큼의 비율의 메모리 사용량을 줄일 수 있습니다.
예를 들어 한 block 당 64개의 page가 있다면 mapping table의 크기도 1/64로 줄일 수 있습니다.
하지만, block level mapping을 사용한다면 맨 처음에 살펴보았던 예시인 block 내의 하나의 page만 수정되었을 때 전체 block에 대해 Erase operation을 진행해야 하는 문제점을 해결하지 못합니다. 따라서 성능이 저하된다는 문제점이 발생합니다.
좋은 성능을 내고, mapping table의 size도 작게 유지할 수 있는 FTL 알고리즘이 과연 있을까요? 이것은 굉장히 흥미로운 문제입니다.
그 중 간단하게 생각할 수 있는 하나의 방법으로, Page-level FTL과 Block-level FTL을 섞어서 사용하는 Hybrid FTL이라는 기법이 있습니다.
이 FTL 기법에서는, 전체 block 중 일부를 log block으로 미리 할당하고, 나머지는 실제 데이터가 저장되는 data block으로 사용합니다. 새로운 데이터가 write될 때는 log block에다가 적어준 뒤, 더 이상 사용할 수 있는 log block이 존재하지 않을 경우 log block을 Erase해주면서 data block과 log block을 merge해줍니다.
Merge는 크게 3가지 종류로 나눌 수 있습니다.
첫째는 switch merge입니다. 만약 log block에 데이터가 우연하게도 같은 블럭이면서 순서대로 쓰였다면, data block과 log block을 단순하게 바꾸어주는 것으로써 merge를 완료할 수 있습니다.
둘째는 partial merge입니다. switch merge와 비슷하지만, 데이터가 완전히 쓰여있지 않았을 경우 나머지 데이터를 data block으로부터 옮긴 뒤, merge를 완료해줄 수 있습니다.
마지막으로 full merge입니다. 일반적으로 대부분의 경우는 full merge에 속하는데, 한 log block 내에 다양한 block number의 page들이 섞여있을 경우 log block 안에 있는 모든 data block들과 merge를 해주어야 합니다. Full merge는 굉장히 비용이 비싸며, 성능을 많이 하락시키는 주 원인입니다.
Hybrid Mapping은 log block에 대해서는 page-level mapping, data block에 대해서는 block-level mapping을 사용합니다. 때문에 성능을 크게 감소시키지 않으면서 필요한 mapping table의 size 또한 감소시킬 수 있는 좋은 방법입니다.
Wear leveling
위에서 Flash는 P/E cycle이 한정되어 있다고 말씀드린 것을 기억하시나요?
P/E cycle이 끝나면 flash의 수명도 끝나기 때문에, P/E cycle을 관리하는 것 또한 굉장히 중요하며 이 또한 FTL에서 그 역할을 맡고 있습니다. 이를 Wear Leveling이라고 합니다.
Wear leveling은 모든 블럭들의 P/E count를 최대한 균등하게 맞추어주는 것을 목표로 합니다.
균등하게 맞추어주는 이유는, 몇 개의 block에만 count가 편중될 경우 해당 block들의 수명이 빠르게 소모되어, 성능 하락이 오는 시기가 더 빨라지기 때문입니다.
Wear leveling을 위해 널리 사용되는 기법으로, Hot block과 Cold block을 구분하는 것이 있습니다.
Hot block의 경우 자주 수정되는 데이터가 저장되는 블럭입니다. 예를 들어 metadata들은 자주 변경이 되기 때문에, 이러한 데이터가 저장된 block은 hot block에 속합니다.
반면, Cold block은 자주 수정되지 않는 데이터가 저장되어 있는 block입니다. 예컨대 큰 파일을 한 번 저장해놓고 수정하지 않는다면, 이 데이터는 cold block에 속하게 됩니다.
문제는 cold block의 경우, 한 번 저장된 후 수정이 좀처럼 일어나지 않기 때문에 해당 data가 저장된 block은 Erase operation이 일어나지 않습니다. 결국, 다른 block들에서만 반복적으로 Program / Erase operation이 일어나면서 수명이 점점 줄어들게 됩니다. 이러한 현상이 지속되면 Hot block들은 수명이 빠르게 소모되어 결국 제 역할을 못하게 되고, cold block만 살아있게 됩니다.
이것을 어떻게 방지할 수 있을까요? 해답은 주기적으로 Cold block과 hot block의 데이터를 바꾸어주는 것입니다. 이렇게 할 경우 특정 block들에만 operation이 몰리는 것을 방지할 수 있습니다. 다만 바꾸는 데에 추가적인 비용이 들기 때문에 전체적인 성능은 약간 하락하게 됩니다.
마무리
FTL에 관한 내용은 흥미롭게 읽으셨나요?
저는 이 내용을 처음 배울 때, Flash가 가진 특이한 특성 때문에 data를 저장하는 과정에서도 고려할 것이 많고, 어떠한 알고리즘을 사용하느냐에 따라 성능이 크게 갈린다는 점이 아주 흥미로웠습니다.
여러분도 여러분만의 알고리즘을 구상하여, 자신만의 FTL을 한 번 만들어보시는 것은 어떨까요?
지금까지 읽어주셔서 감사하며, 틀린 내용이나 질문이 있으시다면 sslktong@dgist.ac.kr로 연락주시기 바랍니다.
감사합니다.
아래는 글을 쓸 때 참고한 문서들입니다.
Operating Systems: Three Easy Pieces Chapter 44. Flash-based SSDs