Pix2Pix 이미지 변환 모델 소개 및 구현
소개
“Image-to-Image Translation with Conditional Adversarial Nets”은 CVPR 2017에 accept된 논문입니다. 이 논문은 이미지의 도메인간 변화를 다루는 문제인 image to image translation을 처음으로 정의했습니다. 이 변환에는 흑백 사진을 컬러화 시키는 것, 윤곽이 주어졌을 때 물체를 그리는 것 등이 포함됩니다. 이전까지는 각각의 변환 문제마다 다른 모델을 사용했었는데 해당 논문에서는 자신들의 Pix2Pix 모델이 대부분의 변환 문제를 잘 해결함을 보여주었습니다.
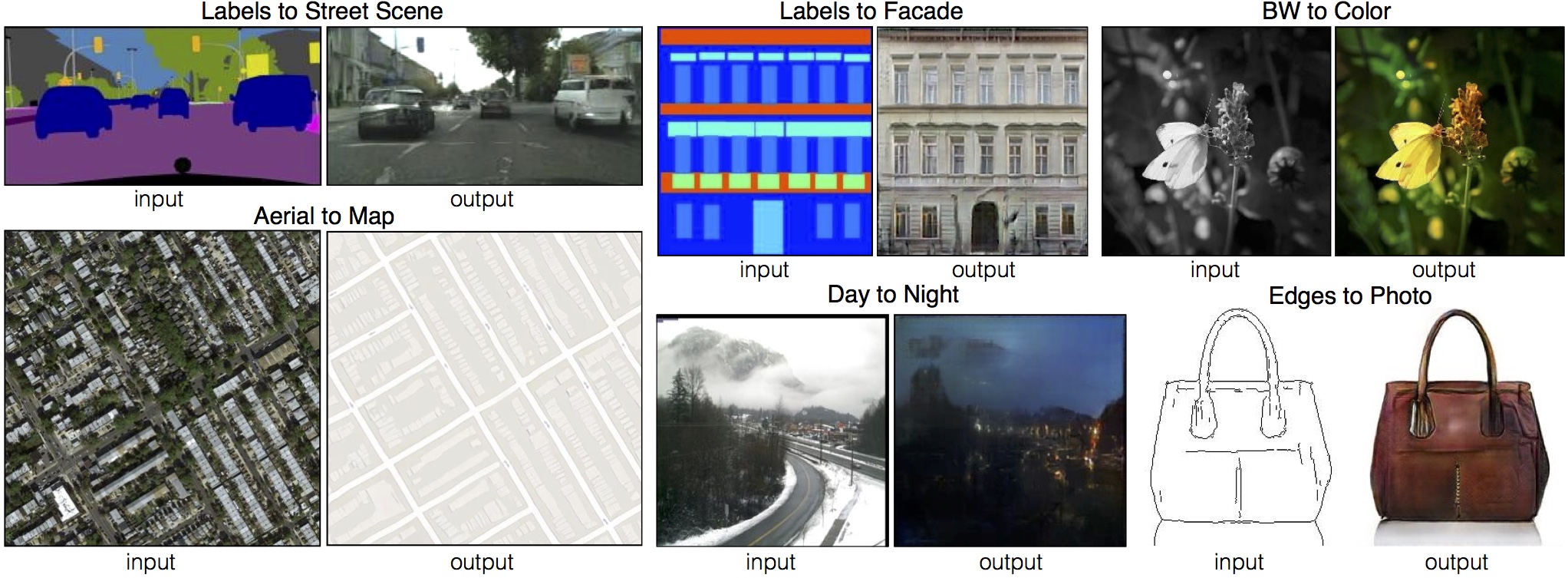
이미지 변환 예시 (출처: https://phillipi.github.io/pix2pix/)
이미 수많은 이미지 처리 문제는 convolutional neural nets(CNNs)를 사용해서 해결하고 있습니다. 하지만, 여전히 CNNs를 학습할 때 효과적인 loss를 설계하는 것은 어려운 일입니다. 예를 들어, 간단히 CNN을 타겟과 예측 결과 사이 유클리디언 거리를 줄이는 방향으로 학습하면 모델은 흐릿한 이미지를 출력하게 됩니다.
이런 문제를 해결하기 위해 이미지 처리 문제에서는 Generative Adversarial Networks(GANs)를 많이 사용합니다. GANs는 생성 모델(generative model)과 판별 모델(discriminative model)을 경쟁적으로 학습합니다. 생성 모델은 판별 모델이 생성된 이미지와 실제 이미지를 구분하지 못 하도록 학습되고 판별 모델은 생성 모델이 생성한 이미지를 실제 이미지와 구분할 수 있도록 학습됩니다. 이러한 학습과정을 거치면 생성 모델은 실제와 유사한 이미지를 만들 수 있게 됩니다.
논문에서는 조건을 넣을 수 있는 conditional GANs(cGANs)을 사용했습니다. 이미지 변환을 할 때 생성 모델과 판별 모델에 조건으로 이미지를 넣어 학습하면 생성모델은 입력 이미지에 따르는 결과 이미지를 생성할 수 있게 됩니다.

이번 포스트에서는 Pix2Pix에 대해 알아보고 이를 구현해보겠습니다. 제 Pix2Pix 구현체는 여기에서 확인할 수 있고, 저자의 Pix2Pix 구현체 및 데모 버전은 여기에서 확인할 수 있습니다.
목표
$G, D$를 각각 생성 모델과 판별 모델이라 하고 $x, y, z$를 각각 입력 이미지, 출력 이미지, 노이즈라고 합시다. cGAN의 목표는 다음과 같이 정의되는 cGAN loss를 최소화하는 것입니다. 이 과정을 통해 $G$는 입력 이미지 $x$와 노이즈 $z$로부터 출력 이미지 $y$로의 맵핑을 배우게 됩니다.
\[\mathcal{L}_{cGAN}(G,D)=\mathbb{E}_{x,y}[\log D(x,y)]+\mathbb{E}_{x,z}[\log(1-D(x,G(x,z)))]\] \[G^\ast=\arg\min_G\max_D \mathcal{L}_{cGAN}(G,D)\]논문에서는 이러한 GAN loss와 더불어 L1, L2 distance같은 전통적인 loss를 추가로 사용했습니다. 이때 판별 모델의 목적 함수는 바뀌는 것이 없지만 생성 모델은 추가로 출력값과 타겟 이미지와의 거리를 좁히게 됩니다. 여기서 Pix2Pix는 흐려짐을 방지하기 위해 L2 대신에 L1 거리를 사용하였습니다.
\[\mathcal{L}_{L1}(G)=\mathbb{E}_{x,y,z}[||y-G(x,z)||_1]\]그러면 다음과 같이 생성 모델 $G^\ast$을 찾는 것이 최종 목표가 됩니다.
\[G^\ast=\arg\min_G\max_D \mathcal{L}_{cGAN}(G,D) + \lambda\mathcal{L}_{L1}(G)\]생성 모델에서 $z$가 없어도 $x$에서 $y$로의 맵핑을 학습할 수 있습니다. 하지만, 그러면 생성 모델은 주어진 입력 이미지에 대해 오직 하나의 결과 이미지를 출력하게 될 것입니다. 따라서 과거의 cGAN들은 가우시안 분포 노이즈 $z$를 $x$와 함께 생성 모델의 입력으로 주었습니다. 저자의 실험에서는 이러한 방식을 통해 주어진 노이즈가 무시되면서 학습되는 현상이 일어났는데 이를 효과적으로 해결할 방법을 찾을 수 없었다고 합니다. 그래서 Pix2Pix는 오직 dropout을 통해서만 노이즈를 주었고 이를 학습 시와 테스트 시 모두에 사용했습니다.
네트워크 구조
이제 생성 모델과 판별 모델의 구조를 살펴보겠습니다. 두 모델은 convolution-BatchNorm-Relu 형태의 모듈로 한 레이어를 구성하였습니다.
생성 모델
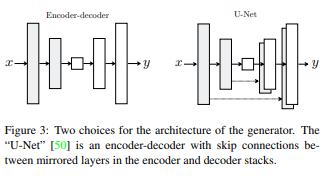
저자는 이미지 변환에서 입력 이미지와 출력 이미지 사이의 표면의 형태는 다르지만 구조 정보를 그대로 가져가야 하는 경우를 고려해서 모델을 설계했다고 합니다. 생성 모델은 U-Net처럼 가운데 병목이 있는 형태로 설계 되었는데 이러한 구조는 low-level의 정보를 전달하기에 좋은 구조라고 합니다. 예를 들어, 이미지 채색 문제의 경우 입력과 출력 사이에서 중요한 엣지 정보를 공유하게 됩니다.
특별한 점은 병목 지역을 통한 정보 전달을 피할 수단으로 skip connection을 추가했다는 것입니다. 총 레이어 수를 $n$이라고 할 때 $i$번째 레이어와 $n-i$번째 레이어를 이어서 skip connection을 추가했습니다.
판별 모델
이미 생성 모델에서 $L1$ distance로 low-frequency에서의 정확함을 요구했으므로 판별 모델은 high-frequency 구조만을 모델링해도 충분하다고 보았습니다. 그리고 high-frequency를 모델링할 때, 지역 이미지만을 고려해도 충분하다고 여겼습니다. 그래서 판별 모델은 $N \times N$개의 작은 구역의 이미지 각각을 판별하고 각 결과의 평균을 구하게 됩니다.
$N$이 작아도 전체 크기의 이미지를 통째로 입력받아서 판별하는 것보다 좋은 결과를 내놓았다고 합니다. 또한, 이 방식은 적은 파라메터를 사용하고, 빠르게 판별할 수 있고, 매우 큰 이미지에도 적용할 수 있다는 장점이 있습니다.
논문 실험 및 결과
저자는 photo generation, semantic segmentation, colorization 등을 비롯해 다양한 비전 테스크를 수행했습니다.

논문에는 다음과 같이 흥미로운 결과들이 많이 있었습니다.



하지만 일반적이지 않은 입력이 들어오거나 sparse한 이미지가 입력으로 들어왔을 때 이상한 이미지가 나오거나 뿌옇게 되는 경우도 있었습니다.

구현
Pix2Pix 코드를 보면서 원래 모델보다 조금 간단화된 버젼을 구현해보았습니다. 전체 코드나 저자의 코드를 직접 보고 싶으면 위의 링크를 참조하세요.
생성 모델
생성 모델은 UNet의 skip connection 블럭을 가지고 쉽게 구현할 수 있습니다. skip connection 블럭은 가장 바깥쪽, 가장 안쪽, 그 사이에 있는 것 총 세 종류를 고려해서 구현해야 합니다. 이 중에서 가장 안쪽을 제외한 나머지 두 개는 skip connection으로 인해 입력 채널을 두 배로 해야 하는 점에 유의합시다.
참고로 모델에서는 batch norm과 instance norm 중 선택해서 사용할 수 있게 되어 있습니다. 만약 batch norm을 사용한다면 batch norm 안에 bias 항이 있으므로 그 전 컨볼루션의 bias를 사용할 필요가 없게 됩니다.
class UNetGenerator(nn.Module):
def __init__(self, image_channels=3, inner_channels=64, n_layers=8, dropout=0.5, norm_layer=nn.InstanceNorm2d):
super().__init__()
assert n_layers >= 5
block = UNetSkipConnectionBlock(inner_channels*8, inner_channels*8, 'innermost', norm_layer=norm_layer)
for _ in range(n_layers-5):
block = UNetSkipConnectionBlock(inner_channels*8, inner_channels*8, 'middle', block, dropout, norm_layer=norm_layer)
block = UNetSkipConnectionBlock(inner_channels*4, inner_channels*8, 'middle', block, dropout, norm_layer=norm_layer)
block = UNetSkipConnectionBlock(inner_channels*2, inner_channels*4, 'middle', block, dropout, norm_layer=norm_layer)
block = UNetSkipConnectionBlock(inner_channels, inner_channels*2, 'middle', block, dropout, norm_layer=norm_layer)
self.model = UNetSkipConnectionBlock(image_channels, inner_channels, 'outermost', block)
def forward(self, x):
return self.model(x)
class UNetSkipConnectionBlock(nn.Module):
def __init__(self,
outer_channels,
inner_channels,
module_type,
submodule=None,
dropout=0.5,
norm_layer=nn.InstanceNorm2d
):
super().__init__()
if module_type not in ['innermost', 'outermost', 'middle']:
raise Exception('no such module type')
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
down_conv = nn.Conv2d(outer_channels, inner_channels, kernel_size=4, stride=2, padding=1, bias=use_bias)
down_relu = nn.LeakyReLU(0.2, True)
down_norm = norm_layer(inner_channels)
up_relu = nn.ReLU(True)
up_norm = norm_layer(outer_channels)
self.outermost = module_type == 'outermost'
if module_type == 'innermost':
up_conv = nn.ConvTranspose2d(inner_channels, outer_channels, kernel_size=4, stride=2, padding=1, bias=use_bias)
modules = [down_relu, down_conv, up_relu, up_conv, up_norm]
elif module_type == 'outermost':
up_conv = nn.ConvTranspose2d(inner_channels*2, outer_channels, kernel_size=4, stride=2, padding=1)
modules = [down_conv, submodule, up_relu, up_conv, nn.Tanh()]
else:
up_conv = nn.ConvTranspose2d(inner_channels*2, outer_channels, kernel_size=4, stride=2, padding=1, bias=use_bias)
modules = [down_relu, down_conv, down_norm, submodule, up_relu, up_conv, up_norm, nn.Dropout(dropout)]
self. model = nn.Sequential(*modules)
def forward(self, x):
if self.outermost:
return self.model(x)
return torch.cat([x, self.model(x)], 1)
판별 모델
판별 모델은 생성 모델에 비해 간단하게 구현되어 있습니다. convolution-norm-relu 모듈을 쌓게 되면서 채널 수는 증가하고 width, heigh는 감소하게 됩니다. 앞에서 설명한 바와 같이 판별 모델의 출력 값의 사이즈는 $N \times N$ 형태가 됩니다.
class NLayerDiscriminator(nn.Module):
def __init__(self,
input_channels=6,
inner_channels=64,
n_layers=3,
norm_layer=nn.InstanceNorm2d
):
super().__init__()
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
modules = [nn.Conv2d(input_channels, inner_channels, kernel_size=4, stride=2, padding=1), nn.LeakyReLU(0.2, True)]
for i in range(n_layers-1):
modules += [
nn.Conv2d(inner_channels*min(2**i, 8), inner_channels*min(2**(i+1), 8), kernel_size=4, stride=2, padding=1, bias=use_bias),
norm_layer(inner_channels*min(2**(i+1), 8)),
nn.LeakyReLU(0.2, True)
]
modules += [
nn.Conv2d(inner_channels * min(2 ** (n_layers-1), 8), inner_channels * min(2 ** n_layers, 8), kernel_size=4, stride=1,
padding=1, bias=use_bias),
norm_layer(inner_channels * min(2 ** n_layers, 8)),
nn.LeakyReLU(0.2, True),
nn.Conv2d(inner_channels * min(2 ** n_layers, 8), 1, kernel_size=4, stride=1, padding=1)
]
self.model = nn.Sequential(*modules)
def forward(self, x):
return self.model(x)