COVID-19 확산의 분석
Contents
- 개요 및 기존 분석들
- 분석 방향성
- 분석
- 결과 및 의의
- 이후 방향성
- 참고
개요 및 기존 분석들
COVID-19 사태는 현재 인류에 큰 피해를 주고 있으며, 앞으로 얼마나 더 지속될지 모르고, 후에 유사한 전염병이 다시 나타났을 때, 좀 더 유연하고 의미있는 해결책과 대비책이 존재하면 좋을 것이라고 생각했습니다. 또한 코로나와 같은 사회 경제에 직접적으로 영향을 주게 되는 경우, 어떤 패턴이 존재하고 변화하는지를 알아보는 과정이 흥미로울 것 같아서 분석을 진행해보게 되었습니다.
먼저, 기존의 분석에 대한 소개입니다. COVID-19 데이터에 대한 분석의 경우, 개인부터 기업에서 정부까지 다양한 지원을 받으며 이루어지고 있습니다. 따라서 여러가지 방식의 분석이 존재하고, 데이터 분석가들이 분석한 자료들이 다량 존재합니다.
유사한 바이러스가 과거에 확산되었던 것에 관한 논문을 데이터 삼아 딥러닝으로 COVID-19에 의미가 있는 부분을 찾아내는 연구도 진행되었고, 데이터 분석 및 머신러닝 대회를 다루는 kaggle, dacon 같은 사이트 에서는 COVID-19과 연관된 대회들이 계속 진행되고 있습니다.
기존에 진행된 연구를 살펴보면 장단점들이 공존합니다. 우선 장점으로는 사용한 데이터들이 깔끔합니다. 데이터의 중요성이 높을뿐더러, 개인이 구하기 힘든 데이터들이 많이 존재합니다. 하지만 단점으로는 사용한 데이터 기간이 한정적입니다. 시시각각 변화하는 데이터에 대한 즉각적이고 확실한 분석을 진행할 수가 없다는 단점이 있습니다
분석 방향성
분석을 진행한 방향에 대해서 먼저 소개를 하겠습니다
시작은 먼저 많은 분석들 처럼 코로나 사태의 확산에 대한 분석으로 시작했습니다. 확진자 수, 사망자 수 그리고 회복한 환자 수 데이터를 이용해 나라별 차이와 인구수를 바탕으로 한 차이를 비교해 보았습니다.
나라별로 코로나 사태 확산 추세를 분류하여, 어떤 추세들이 나타나고 분류별로 어떤 특징들이 존재하는지, 특정 유형들이 나타나는 이유에 대해 분석을 해보았습니다.
그 후 여러가지 수치 요인들을 이용해서 과연 코로나와 관계가 있는지, 있다면 어떤 관계가 있는지 확인해 보았습니다.
마지막으로 한국 코로나에 대한 데이터 분석을 진행했습니다. 주식 데이터를 이용해 종목별로 특이한 점이나 코로나와 연관성이 존재하는지 연구해보았고, 시장 매출 데이터 변화의 분석을 통해서, 또 어떤 매출 변화의 유형들이 존재하고, 그런 유형들이 나타나는 종목들에 대한 분석과 그 이유에 대해 알아보는 순서로 분석을 진행하였습니다.
분석
원하는 날짜에 데이터를 받아올 수 있게하기 위해, 웹 크롤링을 사용했습니다. 위키백과에서 코로나 최신 확산 현황을 받아올 수 있었습니다.
https://en.wikipedia.org/wiki/Template:COVID-19_pandemic_data
COVID_WIKI = "https://en.wikipedia.org/wiki/Template:COVID-19_pandemic_data"
with urllib.request.urlopen(COVID_WIKI) as response:
html = response.read()
soup = BeautifulSoup(html, 'html.parser')
table = soup.find("table",{'id':'thetable'})
lines = table.find_all("tr")
line_num = 0
names = []
cases = []
deaths = []
recov = []
for i in lines:
line_num += 1
if line_num == 2:
data = i.find_all("th")
data_num = 0
for j in data:
data_num+=1
if data_num > 1:
num_data = j.get_text()
clean = re.sub(r'\[[^)]*\]', '', num_data)
clean = clean.rstrip("\n")
print(clean)
if data_num == 2:
names.append(clean)
elif data_num == 3:
cases.append(int(clean.replace(",","")))
elif data_num == 4:
deaths.append(int(clean.replace(",","")))
elif data_num == 5:
recov.append(int(clean.replace(",","")))
break
elif line_num > 2:
tt = i.find_all("th")
pp_num = 0
for k in tt:
pp_num += 1
if pp_num > 1:
num_data = k.get_text()
clean = re.sub(r'\[[^)]*\]', '', num_data)
clean = clean.rstrip("\n")
names.append(clean)
print(clean)
data = i.find_all("td")
data_num = 0
for j in data:
num_data = j.get_text()
clean = re.sub(r'\[[^)]*\]', '', num_data)
clean = clean.rstrip("\n")
print(clean)
data_num += 1
if data_num == 1:
if clean == "No data" or clean == "?":
cases.append(0)
else:
cases.append(int(clean.replace(",","")))
elif data_num == 2:
if clean == "No data" or clean == "?":
deaths.append(0)
else:
deaths.append(int(clean.replace(",","")))
elif data_num == 3:
if clean == "No data" or clean == "?":
recov.append(0)
else:
recov.append(int(clean.replace(",","")))
break
if names[len(names)-1] == "Tanzania":
break
확진자수, 사망자수, 회복한 환자수에 대한 나라별 데이터를 그래프로 나타낸 결과를 먼저 확인했습니다. 미국, 인도, 브라질이 세 부분에서 모두 top 3에 해당했으며, 확진자수가 많은 나라가 이에 비례해서 사망자수와 회복환자수도 많은 것으로 나타났습니다.
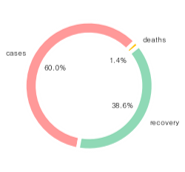
전 세계의 코로나로 인한 사망률은 1.4%에 해당했으며, 이전의 다른 전염병과 비교했을 때 높은 사망률은 아니지만 발전된 의학과 과학을 고려하면 이번 COVID-19은 낮지 않은 사망률을 보였습니다.
인구수 대비 데이터를 이용하기 위해, 웹크롤링으로 나라별 인구수 데이터를 받아왔습니다.
https://www.worldometers.info/world-population/population-by-country/
POPULATION = "https://www.worldometers.info/world-population/population-by-country/"
req = Request(POPULATION, headers={'User-Agent': 'Mozilla/5.0'})
webpage = urlopen(req).read()
soup = BeautifulSoup(webpage, 'html.parser')
table = soup.find("table",{'id':'example2'})
tbody = table.find("tbody")
trs = tbody.find_all("tr")
names1 = []
pop = []
for h in trs:
tds = h.find_all("td")
td_num = 0
for i in tds:
td_num += 1
if td_num == 2:
num_data = i.get_text()
clean = re.sub(r'\[[^)]*\]', '', num_data)
clean = clean.rstrip("\n")
names1.append(clean)
elif td_num == 3:
num_data = i.get_text()
clean = re.sub(r'\[[^)]*\]', '', num_data)
clean = clean.rstrip("\n")
pop.append(int(clean.replace(",","")))
break
np.zeros(len(names))
names_1 = []
cases_1 = []
deaths_1 = []
recov_1 = []
pop_1 = []
cnt = 0
mcount = 0
for i in names:
tnc = 0
for j in names1:
if j == i:
mcount += 1
flag = True
names_1.append(i)
cases_1.append(cases[cnt])
deaths_1.append(deaths[cnt])
recov_1.append(recov[cnt])
pop_1.append(pop[tnc])
break
tnc+=1
cnt+=1
c_per_p = []
d_per_p = []
r_per_p = []
for i in range(len(pop_1)):
c_per_p.append(cases_1[i] / pop_1[i])
d_per_p.append(deaths_1[i] / pop_1[i])
r_per_p.append(recov_1[i] / pop_1[i])
위의 세가지 데이터를 인구수를 기준으로 나누어본 결과, 위와 결과가 많이 상이해졌고, 해당하는 나라별 특징을 찾기 어려웠습니다. 따라서, 지역(대륙별)별 분류 또는 코로나와 관련된 여러가지 요인을 가지는 데이터를 사용하고자 하였고 이는 아래의 사이트에서 daily update를 해주고 있어서 사용하게 되었습니다.
https://ourworldindata.org/coronavirus-source-data
먼저 추세에 대한 분석을 진행하였습니다. 랜덤 비트마스크를 사용해 5개의 나라에 대해 확진자수의 누적분포와 일별분포를 그래프로 찍어보았고, 여러번의 시행을 통해 불규칙한 경우를 포함해 총 4가지 정도의 추세 형태를 확인할 수 있었습니다.
bit_mask = np.zeros(len(loc_list))
nums = []
for i in range(5):
nums.append(randint(0,216-i))
for i in range(5):
for j in range(i):
if nums[j] < nums[i]:
nums[i] += 1
bit_mask[nums[i]] = 1
i = 0
for wname in loc_list:
if bit_mask[i] == 1:
ndf = data.loc[data['location'] == wname]
fig = plt.figure(figsize=(10,3))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax1.title.set_text(wname+' Cumulative cases')
ax1.plot(ndf['total_cases'])
ax2.title.set_text(wname+' new cases')
ax2.plot(ndf['new_cases'])
plt.show()
i+=1
-
일별 확산이 증가(또는 거의 유지) 하는 형태

-
초기 확산이 빠르게 이루어지고 그 후 잠잠한 형태
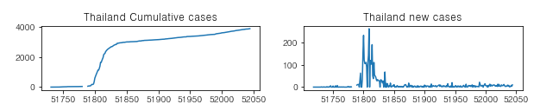
-
특정 날짜를 기준으로 급격한 확산이 이루어지는 형태

위에서 발견된 추세의 다양성을 바탕으로 추세 그래프를 클러스터링 하는 것이 의미 있다고 판단하여, 나라의 일별 데이터를 모두 사용하여 클러스터링을 진행했습니다. min-max scaling을 진행한 후에 필요한 행을 뽑아내고 불필요한 row와 결측값을 포함한 부분은 사용하지 않았습니다.
mydata = data[['location','date','new_cases']]
loc_list = mydata['location'].unique()
# print(len(loc_list))
pp = []
for i in range(217):
if i == 0:
line = ['name']
start_date = date(2019, 12, 31)
end_date = date(2020, 11, 21)
delta = timedelta(days=1)
count = 0
while start_date <= end_date:
line.append(start_date.strftime("%Y-%m-%d"))
start_date += delta
pp.append(line)
else:
line = []
for j in range(328):
line.append('0')
pp.append(line)
qnt = 0
for loc in loc_list:
qnt+=1
aa = mydata[mydata['location'] == loc]
temp = aa['new_cases'].copy()
temp = temp.transform(lambda x:(x-x.min())/(x.max()-x.min()))
aa['new_cases'] = temp
#display(aa)
##break
aa['date'] = pd.to_datetime(aa['date'])
pp[qnt][0] = aa.iloc[0,0]
tnt = 1
for i in range(len(aa)):
bb = aa.iloc[i,1].strftime('%Y-%m-%d')
while True:
if pp[0][tnt] == bb[:10]:
break
tnt+=1
pp[qnt][tnt] = aa.iloc[i,2]
X = np.array(pp)
X.shape
mypd = pd.DataFrame(pp[1:],columns=pp[0])
두 가지 클러스터링 기법(KMEANS, HIERARCHICAL)을 사용했는데, 결과가 거의 동일해 Kmeans 클러스터링을 보여드리겠습니다. Kmeans 클러스터링을 하기위해 먼저 elbow method를 이용해 적합한 k를 선택하였습니다.
def elbow(X):
sse = []
for i in range(1, 20):
km = KMeans(n_clusters=i, init = 'k-means++', random_state = 0)
km.fit(X)
sse.append(km.inertia_)
plt.plot(range(1,20), sse, marker = 'o')
plt.xlabel('clusters')
plt.ylabel('sse')
plt.show()
elbow(mypd)
model = KMeans(n_clusters=5,algorithm='auto')
model.fit(mypd)
predict = pd.DataFrame(model.predict(mypd))
predict.columns=['predict']
bit_mask = []
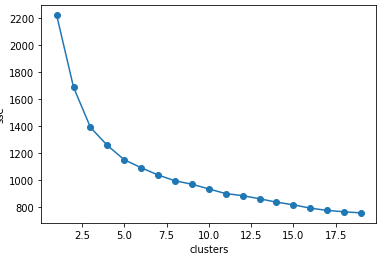
적합한 k(=5)를 찾아 Kmeans 클러스터링을 진행했고 아래는 그 결과입니다. 보이다시피 클러스터별로 확실한 차이가 나타났습니다.
mp = mypd['predict'].max()
print(mp)
for to in range(mp+1):
zeroc = mypd[mypd['predict'] == to]
cnt = 0
ccc = 0
plt.figure(figsize=(30, 15))
plt.subplot(mp+1,1,to+1)
for i in zeroc['name'].unique():
oo = zeroc[zeroc['name'] == i]
cnt= oo.index[0]
oo = oo.drop(['name'],axis = 1)
oo = oo.drop(['predict'],axis = 1)
oo = oo.drop(['hcluster'],axis = 1)
line = []
for j in oo.columns:
if oo.loc[cnt,j] == '0':
line.append(0)
else:
line.append(oo.loc[cnt,j])
plt.plot(np.arange(len(line)),line)
plt.show()
for to in range(mp+1):
print(len(mypd[mypd['predict'] == to]))
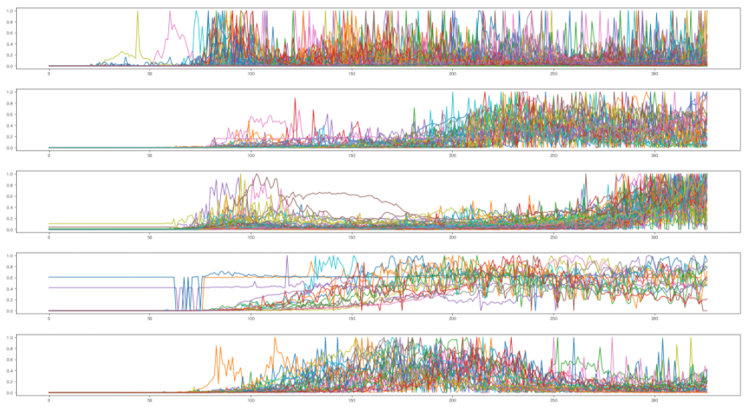
첫 번째 클러스터의 경우 특정 시점에 확산이 급격히 일어나는 나라들이, 두 번째는 초기에 잠잠했다가 후반부에 있어서 확산이 발생한 나라들이, 세 번째 클러스터의 경우 확산의 정도가 시간이 지남에 따라 증가하는 형태의 나라들이, 네 번째 클러스터의 경우 불규칙 형태의 나라들이 그리고 마지막 클러스터에는 한 시점에 확산이 빠르게 진행되었다가 잠잠해진 형태들이 포함됬습니다.
지도상에 나라별 및 인구수 별 확진자 수를 색으로 표현한 결과는 아래와 같았습니다.
fig = px.choropleth(ndf,
locations = names_1[0:],
color = c_per_p[0:],
locationmode = 'country names',
hover_name = names_1[0:],
color_continuous_scale = px.colors.sequential.Plasma)
fig.update_layout(
title='Confirmed Cases per Population In Each Country',
)
fig.show()
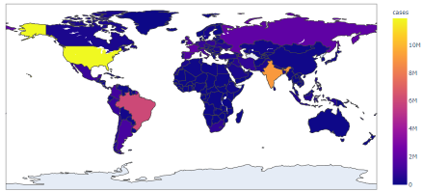
북반구 쪽에 같은 클러스터로 분류된 형태를 확인할 수 있었으며 적도 부근에 같은 클러스터로 분류된 형태가 보이긴 하지만 지역에 따라 확산 추세가 결정된다라고 확정 지을 수 있을 만한 의미있는 정보는 없었습니다.
ourworldindata 사이트에서 제공된 데이터에 여러가지 요인들이 존재했고, 인구 대비 확진자 수에 대한 항목과 상관관계가 크게 나타나는 요인이 있을까 하는 궁금증에 heatmap으로 표현했지만. 단순 수치형 데이터에서 변화와 관련된 상관관계가 크게 나타는 요인은 존재하지 않았습니다.
다음으로 한국의 데이터를 이용해서 분석을 시작했습니다. 한국 확산 추세의 경우 현재까지 3번의 급상승이 있었습니다.(현재 3번째 급상승 진행중) 즉 특정 날짜에 확산이 집중되는 형태의 확산 추세를 보여주고 있고 Kmeans clustering의 1번째 cluster에 속한 것을 확인할 수 있습니다.
가장 처음으로 분석에 사용해 본 것은 주식데이터 입니다. 코로나 전과 후로 주식이 치솟은 기업이 있는가 하면 하락세를 보이는 기업도 존재합니다. 이와 관련해서 과연 COVID-19의 확산과 주식 시장이 관련이 있을가? 하는 궁금증에서 분석을 시작해 보았습니다. 주식 데이터 역시 실시간으로 데이터가 추가되므로, 네이버 금융 사이트를 사용해서 등록된 일별 데이터를 받아왔습니다. 이 데이터와 한국 코로나 관련 데이터를 비교해보았습니다
minmax scaling을 진행한 후에 325일치의 데이터와 2300개의 종목에 대해 한국에서 COVID-19으로 인한 일별 확진자 데이터와의 피어슨 상관계수 값을 계산했습니다. 혹시 관계가 선형에서 벗어날 수 있어, 스피어만 상관계수도 이용했지만, 결과는 거의 동일했습니다. 2300개의 종목 중 68개의 종목이 걸러졌고, 68개의 종목에 대해서 K means clustering을 진행했습니다.
상관계수값 계산
cnt = 0
bitmask = np.zeros(len(code_df))
for i in code_df['name']:
df = holy(i)
hello = pd.merge(sk,df,on = "date",how = "left")
mdf = hello[['new_cases','close']]
temp = mdf['new_cases'].copy()
temp = temp.transform(lambda x:(x-x.min())/(x.max()-x.min()))
mdf['new_cases'] = temp
temp = mdf['close'].copy()
temp = temp.transform(lambda x:(x-x.min())/(x.max()-x.min()))
mdf['close'] = temp
corr = mdf.corr()
gap = corr['new_cases']['close']
print(gap)
if gap > 0.4 or gap < -0.4:
bitmask[cnt] = 1
cnt+=1
결과는 스택이 적은 클러스터들이 많았고 대부분이 하나에 모여있어서, 제대로 된 분류가 이루어지지 않았습니다. 따라서 각 법인들이 다루고 있는 업종들을 각각 모두 조사해보았습니다. 그 결과 해당하는 종목들의 업종이 9개 정도로 매우 편향되어 있는 것을 확인할 수 있었습니다

보시다시피 건축, 의료 , 반도체, 서비스, 디스플레이, 보안, 부품, 기술, 금융, 생활관련 종목들로 이루어져있었습니다
다음으로 분석에 사용한 데이터는 업종 별 결재 데이터를 이용한 업종과 코로나의 연관성 분석을 진행했습니다.
https://dacon.io/competitions/official/235618/overview/
위의 데이콘 대회에서 코로나 이후 업종 별 결재 데이터를 구할 수 있었고 데이터의 기간이 그리 길지는 않았습니다. 데이터에는 행정동 코드와, 업종, 날짜, 매출 건수로 이루어진 card data가 있었고, 행정동 코드와, 시/도/군을 나타내는 region data가 있었습니다. 행정동 코드를 사용하여 이 두 데이터를 merge 하였습니다. minmax scaling을 진행하고, 그 후 불필요하거나, nan값이 많은 행과 열을 제거한 후 사용했습니다. 클러스터링 기법은 Kmeans clustering을 사용했습니다.
st_list = card['업종'].unique()
cnt = 0
pp = []
for i in st_list:
#print(i)
aa = card[card['업종'] == i]
bb = aa.groupby('날짜').sum()['매출건수']
bb = bb.reset_index()
temp = bb['매출건수'].copy()
temp = temp.transform(lambda x:(x-x.min())/(x.max()-x.min()))
bb['매출건수'] = temp
line = []
line.append(i)
for j in bb['매출건수']:
line.append(j)
if len(line) == 155:
line.append(0)
if len(line) == 156:
pp.append(line)
cnt+=1
print(str(cnt) + "/" + str(len(st_list)))
mypd = pd.DataFrame(pp[1:],columns=np.arange(156))
mypd.index = mypd[0]
mypd = mypd.drop([0],axis = 1)
역시 elbow method 를 이용해 적합한 k를 찾고 클러스터링을 진행했습니다.
def elbow(X):
sse = []
for i in range(1, 20):
km = KMeans(n_clusters=i, init = 'k-means++', random_state = 0)
km.fit(X)
sse.append(km.inertia_)
plt.plot(range(1,20), sse, marker = 'o')
plt.xlabel('clusters')
plt.ylabel('sse')
plt.show()
elbow(mypd)
model = KMeans(n_clusters=5,algorithm='auto')
model.fit(mypd)
predict = pd.DataFrame(model.predict(mypd))
predict.columns=['predict']
predict.index = mypd.index
bit_mask = []
mypd['predict'] = predict['predict']
mypd['name']=mypd.index
이제 클러스터링 결과를 line plot으로 각 클러스터마다 찍어보았습니다.
mp = 5
to = 0
for i in range(len(kk)):
plt.figure(figsize = (30,15))
plt.subplot(mp+1,1,to+1)
for j in range(len(kk[i])):
oo = mypd[mypd['name'] == kk[i][j]].copy()
oo = oo.drop(['predict'],axis = 1)
oo = oo.drop(['name'], axis = 1)
cnt = 0
line = []
for ll in oo.columns:
if oo.loc[kk[i][j],ll] == '0':
line.append(0)
else:
line.append(oo.loc[kk[i][j],ll])
plt.plot(np.arange(len(line)),line)
plt.show()
to+=1
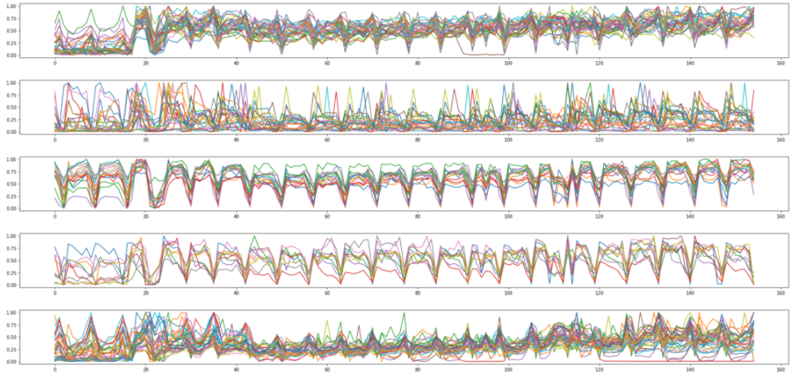
매출의 경우 timeseries(시계열) 데이터였고, 5개 클러스터 모두에서 주기적인 데이터 형태를 보여주었습니다. 따라서 단순히 이 그래프만을 보고 클러스터의 특징을 알아보기에는 어려움이 있었기 때문에 STL decomposition을 사용해 계절성 데이터와, 추세 데이터 그리고 residual(오차) 데이터로 나누어 주는 기법을 이용하였습니다.
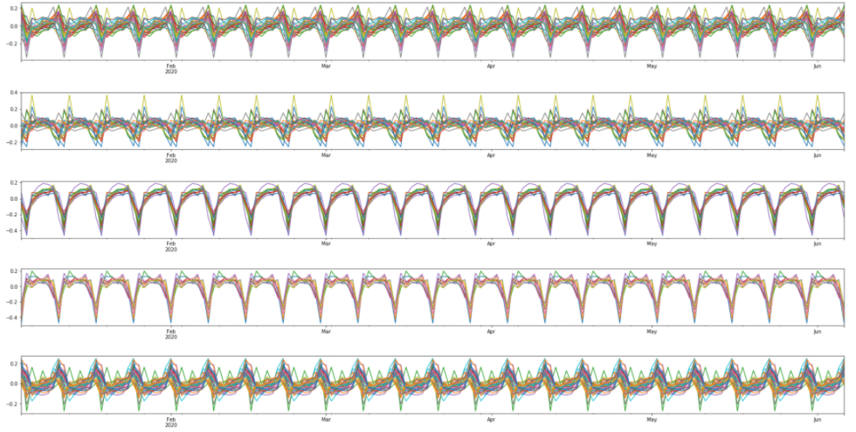
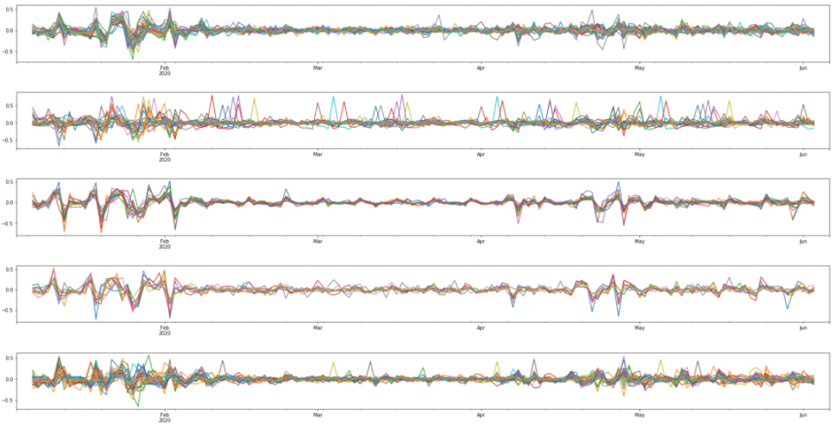
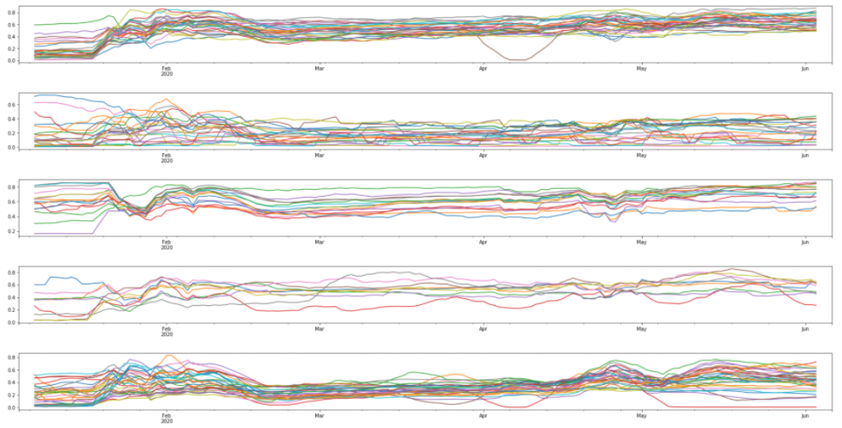
Trend(추세) plot을 보겠습니다.(마지막 5개 그래프입니다) 한국의 경우 6월 14일(데이터의 날짜 max값)까지 한 번의 급격한 확산이 있었습니다.
첫번째 클러스터의 경우 코로나 발병 이후 매출이 하락했다가, 빠르게 회복된 모습을 보이고, 두번째 클러스터의 경우 약간의 하락세는 있지만 코로나와 별다른 관계가 없어보입니다. 세번째 클러스터의 경우 코로나가 급격한 확산을 보인 시점을 기점으로 매출이 급격히 하락했다가 빠르게 매출이 회복되었으며, 네번째 클러스터의 경우 별다른 의미를 찾기 어려웠고, 다섯번째 클러스터의 경우 코로나의 급격한 확산 시점을 기준으로 매출이 하락했다가, 매출이 느리게 회복된 모습을 보여주고 있습니다. 그렇다면 각 클러스터에 해당하는 업종들을 살펴보겠습니다.

두 번째 클러스터의 경우 초기에 약간의 하락세는 있지만 코로나와 별다른 관계가 없었습니다 해당하는 업종의 경우 학원, 인터넷 쇼핑 등 필요할 때 꼭 찾는 업종들로 초기 하락 이후 변동이 없었습니다.
세 번째 클러스터의 경우 급격한 확산 시점을 기점으로 매출이 하락했다가 매우 빠르게 매출이 회복되었는데 해당하는 업종에 음식점이 많았습니다. 확산이 급격하게 이루어졌을 때, 정부 지침 등으로 매출이 하락했다가, 회복된 모습을 보여주었습니다.
네 번째 클러스터의 경우 별다른 의미를 찾기 어려웠는데 해당하는 업종 또한 특별한 관계가 존재하지 않았습니다.
첫 번째 클러스터의 경우 코로나 발병 이후 급격히 낮은 매출을 보이다가 빠르게 매출이 회복되었고, 다섯 번째 클러스터의 경우 그 시점을 기준으로 매출이 하락했다가, 느리게 회복된 모습을 보여주었습니다.
두 클러스터에 해당하는 업종을 통째로 보았을 때, 사람들이 많이 모이는 장소들이었고, 여가 생활 또는 자주 사용하게 되는 업종들이 이에 속하는 것을 확인했습니다 즉 코로나로 인해 사람들의 경각심이 하락에 적용된 것으로 보았고, 업종별로, 그 경각심의 정도가 약해짐에 따라 매출 회복이 이루어진 것으로 보입니다.
결과 정리 및 의의
-
결과 정리
확산의 경우 인구 밀집도와는 크게 관련이 없었습니다. 즉 전염병 유행시 사람들의 경각심에 따라 확산 속도에 있어서 큰 차이가 나타났습니다 사람들의 경각심이나 나라의 정책으로 인한 일시적인 확산 감소 효과는 확실히 있지만, 대부분의 나라에 있어서 효과가 오래가지 않았고, 오히려 특정 시점(사건)을 기점으로 확산이 증가했습니다.
한국 확산 추세 역시 대부분 나라에 해당하는 경우에 속했고, 최근의 확산 증가를 포함해 총 세 번의 시점이 있었습니다. 한국 증시 데이터와 코로나의 경우 상관관계를 통한 분석 결과 유의미한 관계를 보인 종목의 경우 매우 편향되어 있는 형태를 띄었습니다.
업종 별 결재데이터를 이용한 코로나와 관계 분석을 통해 업종 별로 코로나로 인한 매출 변화가 특정한 형태로 나타남을 확인했습니다. 그 형태와 종목관의 관련성이 존재했고, 코로나와의 연관성 또한 확인 가능했습니다
-
결론 및 의의
-
결론
코로나 확산에 가장 큰 영향을 준 것은 나라별 정책의 변화와, 사람들의 행동이었습니다. 이는 한국에서도 나타났으며, 코로나로 인해 특정 업종의 증시에도 변동이 있는 것을 확인할 수 있었습니다. 또한 업종 매출에 있어서 큰 변화가 있었고, 업종의 종류에 따라 타격의 정도와, 매출 회복에 있어서 차이가 나타나는 것을 확인할 수 있었습니다.
-
의의
확산이 잠시 미미하다고 안심하거나, 정책을 크게 완화시키는 것은 바람직하지 않습니다 코로나와 같이 전염성이 강한 질병의 경우, 사실상 확진자 수는 검사자와, 양성판정 즉 positive rate에 의해 결정되는 것이므로, 실제 확진 수를 정확히 판단할 수 없습니다 따라서 정책 완화와 경제적 균형에 있어서 적절한 조치를 취해야 할 것이며, 코로나로 인해 매출에 피해를 크게 입은 업종들과 그 회복이 상대적으로 느린 업종들에 대한 대비책이 마련되어야 할 것입니다.
-
이후 방향성
분석에 있어서 제한사항과 좀 아쉬웠던 점이 많았습니다.
먼저 나라별로 다른 조건과 사용하지 못한 요인으로 생기는 오차가 있었고, 단순히 수치로 이루어진 데이터만을 사용해 결과 또한 수치 or boolean값으로 나타나는 문제가 있었습니다. 또한 수치형 데이터에 결측 값 또는 이상치들이 많이 존재했고, 특정 나라에 대한 데이터가 통째로 이상치로 적용될 가능성 또한 있었습니다. 마지막으로 개인이 모을 수 있는 세부적인 데이터의 한계성이 가장 큰 제한점이었습니다.
이후 분석 방향성의 경우에 아래와 같이 설정했습니다. 데이터 수집에 있어서 더 많은 시간은 할애할 필요가 있다고 느꼈습니다. 수치형 데이터뿐 아니라, 소셜 미디어 관련 논문, 이전 전염병 사례와의 비교 등 여러 형태의 데이터를 이용한 분석이 진행되면 더 좋은 결과를 이끌어 낼 수 있을 것 같습니다.
참고
- 사용된 데이터
https://en.wikipedia.org/wiki/Template:COVID-19_pandemic_data
https://www.worldometers.info/world-population/population-by-country/
https://ourworldindata.org/coronavirus-source-data
https://dacon.io/competitions/official/235618/overview/
- 참고한 분석 들
https://www.kaggle.com/fedi1996/covid-19-analysis-visualization-and-comparaisons
https://www.kaggle.com/maksimeren/covid-19-literature-clustering
https://dacon.io/competitions/official/235618/codeshare/1448