Object Detection
Object Detection
Computer Vision(컴퓨터 비전)이란 컴퓨터 공학의 관점에서, 인간의 시각 시스템이 할 수 있는 작업을 구현하고 이를 자동화하는 방법을 다루는 학문입니다. 이를 위해 이미지 및 비디오에 대한 수집, 처리, 분석을 진행하기 위해 필요한 여러가지 주제들에 대한 연구가 이루어지고 있습니다.
Object Detection(객체 감지)란 컴퓨터 비전의 하위 분야 중 하나로 전체 디지털 이미지 및 비디오 내에서 유의미한 특정 객체를 감지하는 작업을 합니다. 이러한 object detection은 Image retrieval(이미지 검색), Image annotation(이미지 주석), Face detection(얼굴 인식), Video Tracking(비디오 추적) 등 다양한 분야의 문제를 해결하기 위해 사용됩니다.
자율 주행 자동차에서, 차량 주변에 있는 비디오를 인식하여 자동으로 비디오 이미지 내에 차량이 있는지 혹은 사람이 있는지 등을 분석하여 주변 객체들에 대한 위치, 이동 정보를 주는 것(video tracking)이나, 휴대폰 보정 카메라 어플에서 얼굴을 감지하여 해당 부분의 이미지 보정을 적용하는 것(face detection), 포털 사이트의 이미지 검색을 이용할 때, 사진을 업로드하면 해당 사진 내에 존재하는 객체들을 자동으로 인식하여 이와 비슷한 유형의 이미지를 찾아주는 것(image annotation & retrieval) 등이 object detection을 통해 이루어지는 작업들입니다.
비슷한 주제로는 Image Classification(이미지 분류)이 있습니다. object detection의 경우, 한 사진 내에 우리가 object로 분류한 객체들에 대해, 어느 위치에(localization) 어떤 종류의 object가 있는지(classification)에 대한 정보를 주는 것입니다. 이에 반해 image classification은 하나의 사진 자체를 특정 개체로 분류하는 일을 합니다.

위 사진에서 확인할 수 있듯, object detection은 image classification보다 더 큰 범주를 가진다고 볼 수 있습니다.
Methods
object detection은 크게 두 가지 방식으로 구분할 수 있습니다. 바로 neural network를 베이스로 하는 neural approach methods, 베이스로 하지 않는 non-neural approach methods가 있습니다. 이 중 non-neural approach methods는 deep learning based detection methods의 고안 이전에 진행되었던 방식으로, classification을 위한 feature들을 해당 방법들을 통해 구한 다음, feature들을 사용한 classification 기술(e.g. SVM)을 사용하여 detection을 진행합니다.
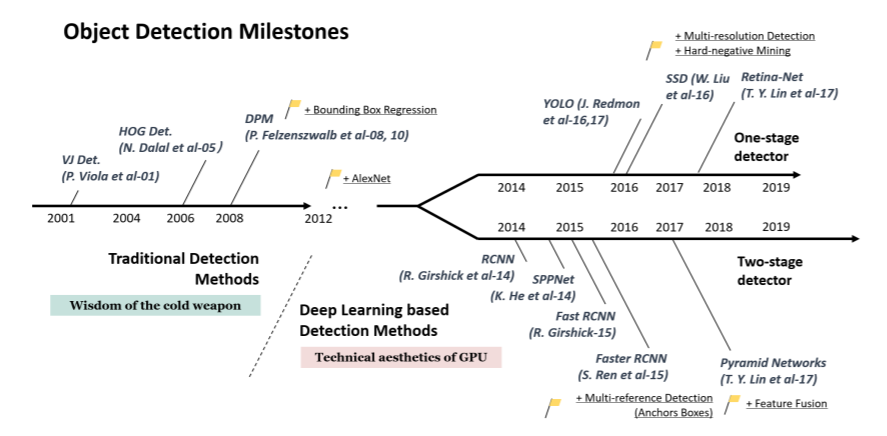
최근에는 non-neural approch method가 neural approach method의 성능을 따라오지 못하는 점으로 인해, neural approach method를 발전시키는 방법으로의 연구가 활발히 이루어지고 있습니다.
neural approach method의 경우, CNN, YOLO, Retina-Net, FCOS 등 여러가지 방법들이 고안되었습니다.
Detector Stage
앞서 이야기한 것과 같이, object detection은 두 가지로 구성되어 있습니다. 첫 번째는 object 자체가 존재하는 위치를 찾아내는 localization이며, 두 번째는 해당 local에 존재하는 object가 무엇인지 확인하는 classification입니다. object detector에서 localization과 classification이 진행되는 순서에 따라서 1-Stage detector와 2-Stage detector로 나뉩니다.
현재 모델들은 localization 과정에서 ‘object가 있을법한 위치’를 찾아내는 알고리즘으로 Regional Proposal을 사용하고 있습니다.
2-Stage Detector
2-stage detector의 경우, regional proposal과 classification이 순차적으로 이루어지는 모델입니다. Regional Proposal 과정이 먼저 이루어지며, 이 과정에서 image 내에 object가 있을 법한 영역인 RoI(Region of Interest)를 찾아냅니다. 이러한 영역들을 발견하고 나면 그 이후에 RoI들에 대하여 object classification을 진행하게 됩니다.
대표적으로 CNN 계열 모델(R-CNN, Faster R-CNN, DenseNet)들이 해당됩니다. RoI를 먼저 찾아내고나서 classification을 순차적으로 진행하게 되므로, 비교적 느리다는 단점이 있지만, RoI를 먼저 찾아내기 때문에 classification 과정에서의 noise가 적어 정확도는 비교적 높다는 장점이 있습니다.
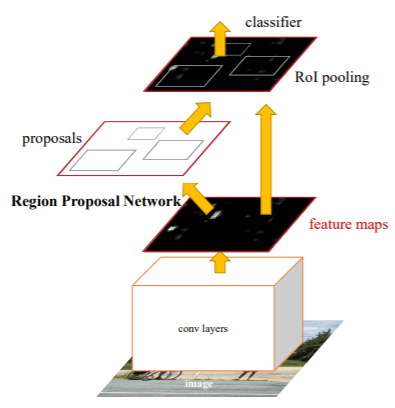
1-Stage Detector
1-stage detector의 경우, regional proposal과 classification이 동시에 이루어지는 모델입니다. Regional Proposal 과정과 classification 과정이 동시에 진행된다는 차이점이 존재합니다. RoI를 추출하지 않고, image 전체에 대해 clssification을 수행 하게됩니다. 예를 들어, 1-stage detector의 대표주자인 YOLO의 경우, 전체 이미지를 특정 크기의 grid로 분할하여 object의 중심이 cell에 존재할 경우 해당 cell이 object detection을 진행하는 방식으로 classification을 진행하여 바로 Bounding Box(BBox, object가 존재하는 image 내 사각형)를 예측하게 됩니다.
대표적으로 YOLO, SSD, RetinaNet 들이 해당됩니다. regional proposal과 classification이 동시에 이루어지기 때문에 비교적 빠르다는 장점이 있으나, 특정 object 하나만 담고 있는 RoI에 비해, 여러 noise와 object가 들어있는 image에서 수행하기 때문에 평균적으로 정확도는 더 낮다는 단점이 있습니다.
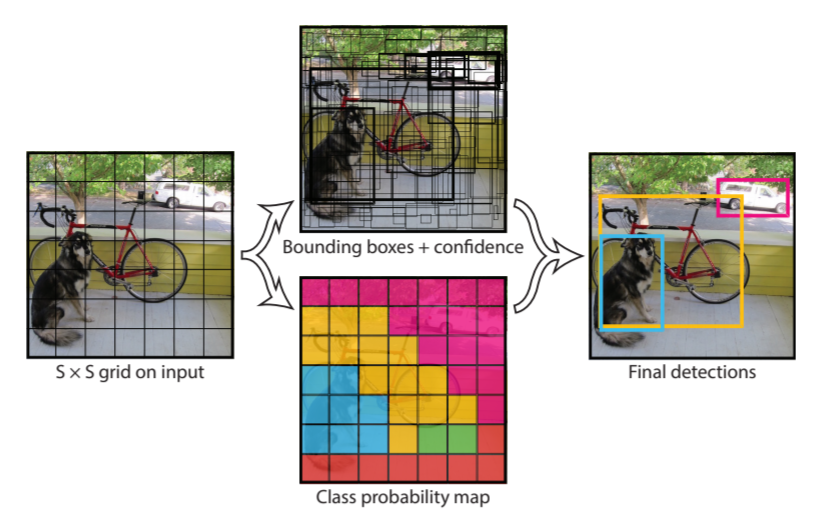
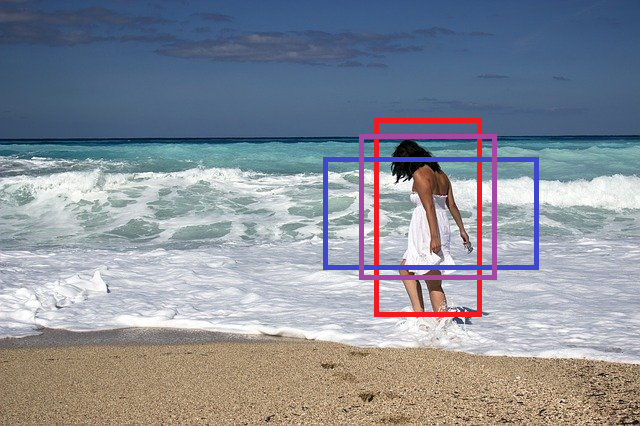
Anchor
object detection 문제에서, object에 대한 classification을 진행할 때에, object가 존재할 영역을 예측하여 해당 위치에 bounding box를 object의 midpoint에 그리게 됩니다. 이 때, 우리는 한 region 내에 하나의 object에 대해서는 하나의 object에 대해서만 detect가 가능합니다. 또한 우리가 검출하고자 하는 object 자체의 box 모양이 정사각형 이외의 특이한 모양으로 존재하는 등의 경우가 존재할 수 있습니다(e.g. 사람은 세로로 긴 모양). 이러한 때에 검출하고자하는 한 grid 내에 여러 objects가 존재하거나, 혹은 한 object가 여러 grid에 존재하는 문제가 발생합니다. 이러한 경우들을 해결하기 위해 여러 모양의 bounding box를 anchor라고 부릅니다. 이러한 anchor들을 그린 이후, 해당 anchor들 중, object가 존재하는 ‘겹치는 영역의 넓이(IOU, object detector의 평가를 설명할 때에 진행할 예정입니다)’을 기준으로 가장 큰 anchor를 선별하여 학습에 진행합니다.
anchor를 사용하게 되면 grid를 사용할 때에, 물체의 위치에 따라서 detection 성능이 달라지는 현상을 완화할 수 있습니다.
Faster R-CNN 이후, 1-Stage Detector와 2-Stage Detector 모두 anchor를 사용하는 anchor-based detection들로 구현되었으나, 현재에는 anchor를 사용하지 않는 경우의 장점이 이야기되어 anchor-free detection들도 연구되고 있습니다.
Data Set
AI model의 성능을 평가하기 위해서, 혹은 모델을 학습시킬 때에 최대한 모델의 성능을 향상시키기 위한 용도로, AI task 분야에서는 모델을 개발하는 것 뿐만 아니라, 좋은 데이터 셋 또한 연구되고 있습니다. 이러한 이유로, 각각의 task들에 대해서 모델을 training 혹은 validation하기 위한 대표적인 dataset들이 존재합니다.
object detection의 경우 COCO, PASCAL 등의 데이터 셋 등이 모델의 평가를 위해 대표적으로 사용되고 있고, 여러 논문들의 대표적인 model experiment & validation에 사용되고 있습니다.

모델을 training하는 과정에서, 영향을 줄 수 있는 것은 다양한 요인들이 있습니다. 그리고 그러한 요인 중 하나가 바로 dataset입니다.
dataset에 모델의 training에 부정적인 영향을 줄 수 있는 이유는 다양하게 존재합니다(크기, 편향 등).
이 중, 특별히 object detection의 경우 다음 요소들이 모델링을 위한 중요한 요소로 고려됩니다.
Quality
object detection의 경우, 다른 training dataset과는 다르게, 추가로 image에 대한 데이터 뿐만 아니라, 모델이 labeling 과정에서 실제 object로 분리되는 영역을 확인하며, 그 object에 annotation을 진행하는 과정에서 좋은 annotation을 진행할 수 있는 학습 데이터 셋이 되어야합니다. 이러한 이유로 인해 데이터를 통해 학습한 모델의 annotation quality가 데이터 셋을 만드는 과정에서 굉장히 중요하게 여겨지며, 이 과정에서 annotation을 진행할 때의 ambiguity를 줄이는 방향으로 이루어져야합니다.
Generalize
object detection의 경우, 모델이 object annotation을 진행할, object가 존재하는 위치를 잘 정의해야하기 때문에 localization에 굉장히 민감합니다. 이를 위해 데이터 셋을 만드는 과정에서, 모델이 학습을 거치고 난 이후에 localizing을 올바르게 할 수 있도록 좋은 데이터를 만들어야합니다.
이러한 이유들로 인해, 실제로 object detection dataset을 만드는 것 또한 굉장히 중요한 문제로 이야기가 되고, 실제로 이에 대한 연구가 진행되고 있습니다.
2019년도에는 Object365와 같은 annotation quality와 generalize를 향상시켜 object detection을 위한 모델들로 학습을 진행했을 때에, 성능이 향상되는 새로운 pre-train dataset으로 발표되기도 하였습니다.
How to check best model
object detection을 비롯한 AI tasks들에 대한 trend를 확인하면, 현재 특정 분야에서 굉장히 좋은 성능을 내거나, 혹은 특별한 dataset에 대해 state-of-the-art인 model을 사용하는 것이 실제 model implementation 과정에서 좋은 결과를 낼 가능성이 높습니다. 이를 위해 현재 어떤 모델이 좋은지에 대해 여러 dataset에 대해 확인할 수 있는 사이트를 사용하면 좋습니다.
해당 사이트에서는 각각의 task와 dataset에 대해 현재까지 개발된 모델의 성능을 확인할 수 있습니다.
(예를 들어, Pascal VOC dataset에 대해 현재 SOTA를 달성하고 있는 model은 EfficientNet 모델임을 확인할 수 있습니다)
참고 문헌
‘Object Detection in 20 Years: A Survey’
‘Objects365: A Large-Scale, High-Quality Dataset for Object Detection’
‘Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks’