Introduction To Retroactivity
Table Of Contents
Introduction
안녕하세요, Aeren입니다!
Persistent data structure는 어떤 data structure의 여러 상태를 저장하면서 임의의 상태로부터의 연산을 통해 도달한 새로운 상태를 관리할 수 있게 합니다. 이렇게 만들어진 상태들의 관계는 tree 구조룰 이루게 되죠. 이번 글에서 소개할 내용은 이와 대비되는 개념인 retroactive data structure입니다. Retroactive data structure에서 각 상태들의 관계는 line graph형태로 고정되있습니다. 그리고 어떤 상태가 연산을 통해 변화했다면, 이후의 모든 상태들도 마치 과거에 그러한 연산이 존재했던 것처럼 변화합니다. 비유를 들자면, 공상과학 소설에서 시간여행이란 주제를 다루는 두 유형과 비슷합니다. 하나는, 등장인물이 과거로 돌아가 어떠한 행동을 취했을 때 그 지점으로부터 또 하나의 parallel universe가 생긴다는 전제이고 (= persistency), 다른 하나는 오직 하나의 시간축 위에서 그 행동에 의해 현재 모습이 완전히 바뀌는 것이죠 (= retroactivity).
이 글은 다음 글을 바탕으로 작성되었습니다.
Preliminaries
Operations
일반적으로, data structure는 상태를 바꾸는 연산인 “update”와, 현재 상태에 대한 어떤 정보를 묻는 연산인 “query”를 통해 상호작용 합니다. 시간 $t_1<…<t_m$에 대하여, $U=[u_{t_1},…,u_{t_m}]$를 data structure에 적용될 update들의 집합이라고 표기하겠습니다. (일반성을 잃지 않고, 임의의 시간에는 오직 하나의 update만 존재한다고 가정하겠습니다.) 또한, data structure의 원래 연산들을 소문자로 시작하도록 표기하고, retroactivity 관련 연산들을 대문자로 시작하도록 표기하겠습니다.
Partial Retroactivity
어떤 data structure가 partially retroactive하다는 것은, 현재 상태에서의 update와 query뿐만 아니라, 과거 update의 insertion 및 deletion을 추가로 지원하는 것을 의미합니다. 즉, 다음 연산들을 추가로 지원하는 것입니다.
- $\mathrm{Insert}(t,u)$: 시간 $t$에서 $U$에 update $u$를 삽입합니다. ($u$가 시간 $t$에 삽입되는 유일한 연산이라고 가정합니다.)
- $\mathrm{Delete}(t)$: 시간 $t$에서 $U$의 update $u$를 삭제합니다. (시간 $t$에 연산이 존재한다고 가정합니다.)
Full Retroactivity
어떤 data structure가 fully retroactive하다는 것은, 과거 update의 insertion / deletion뿐만 아니라, 과거의 상태를 묻는 query연산도 지원하는 것입니다. 즉, 다음 연산들을 추가로 지원하는 것입니다.
- $\mathrm{Insert}(t,u)$: 시간 $t$에서 $U$에 update $u$를 삽입합니다. ($u$가 시간 $t$에 삽입되는 유일한 연산이라고 가정합니다.)
- $\mathrm{Delete}(t)$: 시간 $t$에서 $U$의 update $u$를 삭제합니다. (시간 $t$에 연산이 존재한다고 가정합니다.)
- $\mathrm{Query}(t,q)$: 시간 $t$에서 data structure의 상태를 묻는 query $q$를 답합니다.
앞으로 모든 retroactivity관련 연산들은 valid한 것들만 주어진다고 가정하겠습니다. (즉, $\mathrm{Insert}$는 시간 $t$에 다른 연산이 존재하지 않을 때만 주어지고, $\mathrm{Delete}$는 시간 $t$에 어떤 연산이 존재할 때만 주어지며, data structure 자체 혹은 이후의 update / query가 invalidated되는 연산은 주어지지 않는다고 가정합니다.)
Runtime
Retroactive data structure의 runtime을 표현할 때, 다음 변수들을 사용하겠습니다.
- $n$: 임의의 시간에 $U$에 존재할 수 있는 update들의 갯수의 최댓값
- $m$: 시간축 위의 retroactive update의 갯수
- $r$: 주어진 시간 이후의 retroactive update의 갯수R
General Retroactivity
먼저 내재된 data structure의 형태에 의존하지 않고 retroactivity를 다루겠습니다.
가장 먼저 생각할 수 있는 방법은 retroactive update가 시간 $t$에 주어질 때 마다, $t$이후의 모든 연산을 rollback한 뒤 연산을 수행하고 다시 이후의 연산들을 복구하는 것입니다. Formal하게 표현하면 다음과 같습니다.
THEOREM
연산들을 $O(T(n))$에 수행하는 data structure가 주어질 때, 같은 연산들을 $O(T(n))$에 수행하고, retroactive한 연산들을 $O(r \cdot T(n))$에 수행하는 retroactive data structure가 존재한다.
물론 이 방법은 두말할 것도 없이 매우 비효율적입니다. 여기서 retroactive한 연산에서 $r$에 대한 의존도를 줄일수는 없을까요? 아쉽게도 다음 정리에 의해 일반적으로는 불가능합니다.
THEOREM
연산들을 $O(1)$시간에 수행하지만 partially retroactive한 연산들은 $\Omega(r)$의 시간을 (amortized여부에 상관 없이)필요로 하는 data structure가 존재한다.
PROOF
제시할 자료구조는 두 변수 $X$와 $Y$를 저장합니다. 초기에는 두 변수 모두 $0$을 저장합니다. 그리고 $X$에 상수 $c$를 더하는 연산 $\mathrm{addX}(c)$, $Y$에 상수 $c$를 더하는 연산 $\mathrm{addY}(c)$, 그리고 $X$와 $Y$를 곱한 값을 $Y$에 저장하는 연산 $\mathrm{mulXY}()$, 마지막으로 $Y$의 값을 반환하는 쿼리연산 $\mathrm{printY}()$를 지원합니다. 각 연산은 자명하게 $O(1)$시간 안에 수행가능합니다.
이제 다음 $m=2n+1$개의 연산들을 생각해봅시다.
$[\mathrm{addY}(a _ n) , \mathrm{mulXY}() , \mathrm{addY}(a _ {n-1}) , \mathrm{mulXY}() , \cdots , \mathrm{mulXY}() , \mathrm{addY}(a _ 0)]$
이후 연산열의 제일 첫부분에 $\mathrm{addX}(x)$를 retroactive하게 삽입하면, $Y$에는 최종적으로 $ a _ 0 + a _ 1 x + \cdots + a _ n x ^ n $이 저장됩니다. Degree $d$인 polynomial의 evaluation에는 최소 $O(d)$의 시간이 필요하기에, 결국 $\mathrm{Insert}(m-r, \mathrm{addX(x)})$ 이후 $\mathrm{PrintY}()$를 호출하는데에 적어도 $O(r)$시간이 필요합니다.
$\blacksquare$
하지만, partially retroactive한 data structure를 갖고 있다면, 약간의 cost를 지불함으로서 fully retroactive한 data structure로 전환할 수 있습니다.
THEOREM
$T(m)$시간에 retroactive update를 수행하고 $Q(m)$시간에 query를 수행하는 partially retroactive data structure가 주어질 때, $O(\sqrt{m} \cdot T(m))$시간에 같은 retroactive update를 수행하고 $O(\sqrt{m} \cdot T(m)+Q(m))$시간에 retroactive query를 수행하는 fully retroactive data structure가 존재한다.
PROOF
$\sqrt{m}$개의 체크포인트 $t _ 1 , \cdots , t _ { \sqrt { m } }$를 처음과 끝, 그리고 연속된 체크포인트 사이에 최대 $3 / 2\sqrt{m}$개의 연산이 들어있도록 놓겠습니다. 그리고 $\sqrt{m}$개의 partially retroactive data structure $D _ 1, \cdots , D _ {\sqrt{m}}$를 $D _ i$가 $t _ i$이전의 모든 update를 포함하도록 놓겠습니다.
- Retroactive update가 시간 $t$에 주어지면, $t < t _ i$인 최소의 $t _ i$를 찾은 후, 모든 $D _ i, \cdots, D _ \sqrt{m}$을 update해줍니다. 이 때 총 시간복잡도는 $O(\sqrt{m} \cdot T(m))$입니다.
- Retroactive query가 시간 $t$에 주어지면, $t < t _ i$인 최소의 $t _ i$를 찾은 후, $D _ i$를 $t$로 rollback해준 후 query를 수행하고 다시 $t _ i$로 복구시킵니다. 연속된 체크포인트 사이에 최대 $3/2\sqrt{m}$개의 연산이 들어있기 때문에 총 시간복잡도는 $O(\sqrt{m} \cdot T(m) + Q(m))$입니다.
$\blacksquare$
Specific Retroactivity
앞에서 보았듯이, 내재된 data structure의 형태에 의존하지 않고 retroactivity를 다루는 데에는 한계가 있습니다. 따라서 queue, deque, union-find, priority queue 총 4가지 abstract data type들에 대한 효율적인 retroactive counterpart들을 소개한 후 이 글을 마치도록 하겠습니다.
앞으로, $U$ (update들의 집합)는 time에 의해 정렬된 doubly link list형태로 저장하겠습니다. 그리고 retroactive한 연산이 주어질 때, $U$에 삽입될 위치가 같이 주어진다고 가정하겠습니다. (만약 주어지지 않는다면, update들을 binary search tree에 저장함으로서 $O(\log m)$시간에 위치를 얻어내는 것이 가능합니다.)
Queue
Queue는 다음 연산들을 지원하는 abstract data type입니다.
- updates
- $\mathrm{enqueue}(x)$: $x$를 queue에 삽입합니다.
- $\mathrm{dequeue}()$: 가장 먼저 삽입된 원소를 제거합니다. (queue가 비어있지 않다고 가정합니다.)
- queries
- $\mathrm{front}()$: 가장 먼저 삽입된 원소를 return합니다. (queue가 비어있지 않다고 가정합니다.)
- $\mathrm{back}()$: 가장 늦게 삽입된 원소를 return합니다. (queue가 비어있지 않다고 가정합니다.)
THEOREM
모든 연산을 $O(1)$에 수행하는 partially retroactive queue data structure가 존재한다.
PROOF
$\mathrm{enqueue}$ 연산들을 시간으로 정렬된 상태로 doubly linked list $L$에 저장합니다. 그리고 다음 $\mathrm{front}()$연산에서 return될 원소를 가르키는 포인터 $F$와 다음 $\mathrm{back}()$연산에서 return될 원소를 가르키는 포인터 $B$를 추적합니다.
- $\mathrm{Insert}(t, \mathrm{enqueue}(x))$연산이 들어오는 경우, $L$에 연산을 삽입합니다. 이 때, 삽입된 연산이 $L$의 맨 앞쪽에 위치한다면, $F$를 이전 원소로 옮겨줍니다. 또한, 삽입된 연산이 $L$의 맨 뒷쪽에 위치한다면, $B$를 다음 원소로 옮겨줍니다.
- $\mathrm{Insert}(t, \mathrm{dequeue}())$연산이 들어오는 경우, $F$를 다음 원소로 옮겨줍니다.
- $\mathrm{Delete}(t)$연산이 들어오는 경우,
- 만약 $t$의 연산이 $\mathrm{enqueue}(x)$라면, $L$에서 삭제해주고, $t$가 $F$가 가르키는 연산의 시간보다 빠르다면, $F$를 다음 원소로 옮겨줍니다.
- 그리고 만약 $t$의 연산이 $\mathrm{dequeue}()$라면, $F$를 이전 원소로 옮겨줍니다.
- $\mathrm{Query}(t, \mathrm{front}())$연산이 들어오는 경우, $F$가 가르키는 연산의 원소를 return합니다.
- $\mathrm{Query}(t, \mathrm{back}())$연산이 들어오는 경우, $B$가 가르키는 연산의 원소를 return합니다.
위 모든 과정은 $O(1)$시간에 처리할 수 있습니다.
$\blacksquare$
THEOREM
모든 retroactive한 연산을 $O(\log m)$에 수행하고 현재 시간에 관한 연산을 $O(1)$에 수행하는 fully retroactive queue data structure가 존재한다.
PROOF
Order statistic tree $T _ e$와 $T _ d$를 유지합니다. $T _ e$는 모든 $\mathrm{enqueue}$연산들을, 그리고 $T _ d$는 모든 $\mathrm{dequeue}$연산들을 시간으로 정렬된 상태로 저장합니다. 각 retroactive update들에 대해 $T _ e$와 $T _ d$를 $O(\log m)$에 update하는 과정은 자명합니다. 연산 $\mathrm{Query}(t, \mathrm{front}())$가 주어지면, $T _ d$를 이용해 시간 $t$이전에 존재하는 $\mathrm{dequeue}$연산의 갯수 $k$를 구한 후, $T _ e$에서 $k+1$번째 원소를 찾아 return합니다. 그리고 연산 $\mathrm{Query}(t,\mathrm{back}())$가 주어지면, $T _ e$에 존재하는 $t$이전의 가장 늦은 시간에 존재하는 원소를 찾아 출력합니다. 또한, partially retroactive queue와 비슷하게 front pointer $F$와 back pointer $B$를 추적해주면, 현재 시간에 대한 query는 $O(1)$에 답할 수 있습니다.
$\blacksquare$
Deque
Deque(doubly-ended queue)는 다음 연산들을 지원하는 abstract data type입니다.
- updates
- $\mathrm{pushfront}(x)$: $x$를 deque의 앞쪽에 삽입합니다.
- $\mathrm{popfront}()$: deque의 가장 앞쪽 원소를 제거합니다.
- $\mathrm{pushback}(x)$: $x$를 deque의 뒤쪽에 삽입합니다.
- $\mathrm{popback}()$: deque의 가장 뒤쪽 원소를 제거합니다.
- queries
- $\mathrm{front}()$: 맨 앞쪽 원소를 return합니다. (deque가 비어있지 않다고 가정합니다.)
- $\mathrm{back}()$: 맨 뒤쪽 원소를 return합니다. (deque가 비어있지 않다고 가정합니다.)
THEOREM
모든 retroactive한 연산을 $O(\log m)$에 수행하고 현재 시간에 관한 연산을 $O(1)$에 수행하는 fully retroactive deque data structure가 존재한다.
PROOF
일반적인 deque의 구현은 다음과 같습니다. 변수 $L=1$과 $R=0$, 그리고 array $A$를 준비합니다.
- $\mathrm{pushfront}(x)$연산이 들어오면 $L$을 감소시키고 $A[L]=x$으로 update시킵니다.
- $\mathrm{popfront}()$연산이 들어오면 $L$을 증가시킵니다.
- $\mathrm{pushback}(x)$연산이 들어오면 $R$을 증가시키고 $A[R]=x$으로 update시킵니다.
- $\mathrm{popback}()$연산이 들어오면 $R$을 감소시킵니다.
같은 아이디어로 retroactive deque를 구현할 수 있습니다. Segment sum, 그리고 segment minimum / maximum prefix / suffix를 지원하는 balanced binary search tree $U _ F$와 $U _ B$을 준비합니다. 여기서 $U_F$는 $\mathrm{pushfront}$와 $\mathrm{popfront}$들을 $t$로 정렬된 상태이며 각각 가중치 1과 -1을 갖습니다. 이제 시간 $t$에서 $L$값은 $U _ F$의 $t$이하의 key를 갖는 부분의 가중치의 합이 됩니다. 이제 $A[L]$값은, 마지막으로 index가 $L$이 됬던 위치를 root에서 타고내려오면서 찾아줌으로서 알아낼 수 있습니다. $U _ B$도 마찬가지입니다. 위 연산들은 모두 $O(\log m)$에 수행가능합니다.
$\blacksquare$
Union-Find
Union-find는 서로다른 원소들의 집합 $S$에서 equivalence relation에 대한 다음 연산들을 지원 하는 abstract data type입니다.
- updates
- $\mathrm{create}(x)$: $x$를 $S$에 삽입합니다. 이 때, $x$의 equivalence class는 $\lbrace x \rbrace$입니다.
- $\mathrm{union}(x,y)$: $x$와 $y$의 equivalence class를 합칩니다. ($x$와 $y$가 equivalent하지 않다고 가정합니다.)
- queries
- $\mathrm{find}(x)$: $x$의 equivalence class의 representative를 return합니다.
각 equivalence class의 representative는 매 연산 이후 바뀔 수 있기 때문에, $\mathrm{find}(x)$연산의 용도는 임의의 두 원소의 equivalence를 판별하는 것으로 한정됩니다. 따라서, $\mathrm{find}(x)$를 다음의 연산으로 대체하겠습니다.
- $\mathrm{sameset}(x,y)$: $x$와 $y$가 equivalent한지의 여부를 return합니다.
THEOREM
모든 연산을 $O(\log m)$에 수행하는 fully retroactive union-sameset data structure가 존재한다.
PROOF
$S$의 각 원소에 대응되는 vertex들을 생성해주고, 각 $\mathrm{union}(x,y)$마다 $x$와 $y$를 잇는 edge를 생성해주면, forest $F$가 얻어지고, $\mathrm{sameset}(x,y)$는 $x$와 $y$가 $F$에서 같은 component에 속하는지 판별하는 연산이 됩니다. 이는 link-cut tree를 이용해 $O(\log m)$에 처리할 수 있습니다. Retroactive한 연산을 위해서, 각 edge에 관련 $\mathrm{union}$연산의 $t$값을 저장합니다. 이제 $\mathrm{Query}(t,\mathrm{sameset}(x,y))$는 ($x$와 $y$가 같은 component에 속할 경우) $x$와 $y$의 경로상의 값의 최댓값이 $t$ 이하인지의 여부와 같아집니다. 이 연산 역시 link-cut tree로 $O(\log m)$에 처리할 수 있습니다.
$\blacksquare$
Priority-Queue
Priority-queue는 다음 연산들을 지원하는 abstract data type입니다.
- updates
- $\mathrm{push}(x)$: $x$를 priority queue에 삽입합니다.
- $\mathrm{pop}()$: priority queue에서 가장 작은 원소를 제거합니다.
- queries
- $\mathrm{top}()$: priority queue에서 가장 작은 원소를 return합니다.
이전까지 보았던 data type에 비해 까다로운 점이라면 하나의 update로 인해 이후의 많은 원소들의 lifetime이 바뀔 수 있다는 것입니다.
일반성을 잃지 않고, priority-queue안의 모든 원소는 pairwise-distinct하다고 가정하겠습니다. 또한 $t _ x$를 $x$의 insertion time, $d _ x$를 $x$의 deletion time, $Q _ t$를 시간 $t$에서 priority-queue의 원소들의 집합, $Q _ \mathrm{now}$를 현재 priority-queue의 원소들의 집합, $I _ {\ge t}$를 시간 $t$ 이후에 삽입된 원소들의 집합, 그리고 $D _ {\ge t}$를 시간 $t$ 이후에 삭제된 원소들의 집합이라 놓겠습니다.
이제 연산들을 그래프로 표현해보겠습니다. 가로축을 시간, 세로축을 key로 표현하고 각 item $x$는 $(t _ x, x)$와 $(d _ x, x)$를 잇는 가로선분과 $(d _ x, x)$와 $(d _ x, 0)$을 잇는 세로선분으로 표현하겠습니다.
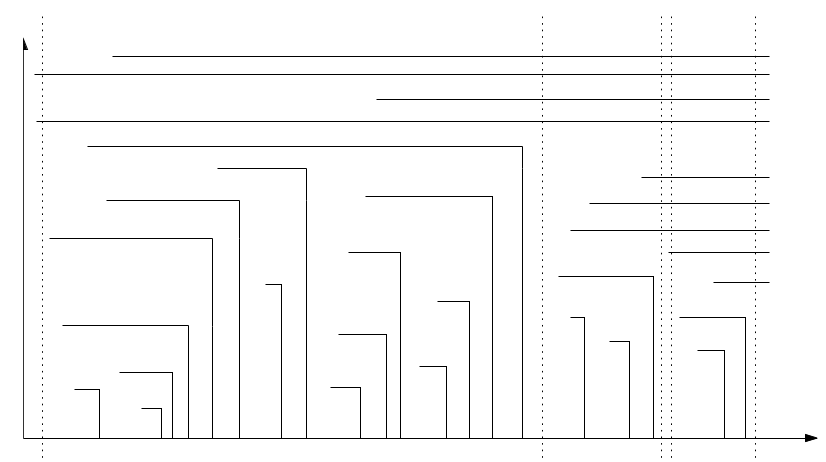
$\mathrm{Insert}(t,\mathrm{push}(x))$연산 이후, 단조증가하는 rectilinear한 계단 형태의 update가 이루어집니다.
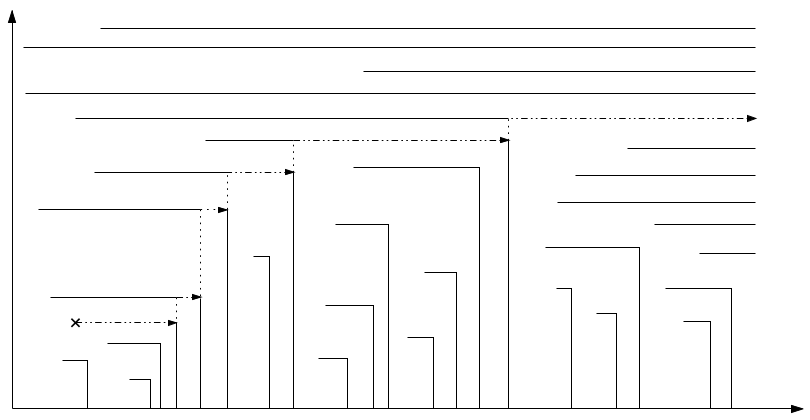
여기서 착안하여 다음 lemma를 얻어낼 수 있습니다.
LEMMA
$\mathrm{Insert}(t,\mathrm{push}(x))$연산 이후, $Q _ \mathrm{now}$에는 $\max(x, \max _ {x’ \in D _ {\ge t} }x’)$이 삽입된다.
시간 $t$에 $\mathrm{pop}()$연산이 있을 때, $\mathrm{Delete}(t)$는 pop될 원소를 재삽입하는 것과 동치이므로, 아래 lemma도 자연스럽게 얻어집니다.
LEMMA
시간 $t$에 $\mathrm{pop}()$연산이 있을 때, $\mathrm{Delete}(t)$연산 이후, $Q _ \mathrm{now}$에는 $\max _ {x’ \in D _ {\ge t}}x’$이 삽입된다.
하지만 $D _ {\ge t}$들은 한번의 연산으로 인해 여러 $t$에 대하여 바뀔 수 있기 때문에 직접 유지하는것은 매우 힘듭니다. 시간 $t$가 $Q _ t \subseteq Q _ \mathrm{now}$를 만족할 때, 시간 $t$에 bridge가 있다고 표현합시다. 맨 처음 figure에서 bridge는 세로로된 점선으로 표시되었습니다. 여기서 각 bridge사이의 구간에서, delete된 최대 원소는 같은 구간에서 delete된 원소들 중에서 가장 늦게 삭제됨에 주목하면, 다음 lemma가 얻어집니다.
LEMMA
$t’$를 $t$ 이전의 마지막 bridge라고 할 때, $\max _ {x’ \in D _ {\ge t}} x’ = \max _ {x’ \in I _ {\ge t’} - Q _ \mathrm{now}} x’$이 성립한다.
이제 $\mathrm{Insert}(t,\mathrm{pop}())$가 주어진다고 합시다. 다음 figure에서처럼, $\mathrm{push}$연산이 삽입될 때와 비슷하게 rectilinear한 계단 형태의 update가 이루어집니다.
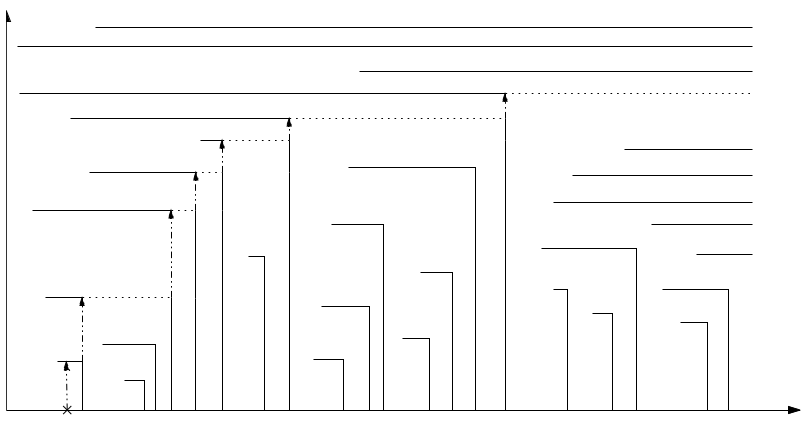
최종적으로 $Q _ \mathrm{now}$에서는 다음 bridge에 존재하는 원소들 중 최소원소가 삭제됩니다. 즉, 다음 lemma가 성립합니다.
LEMMA
$\mathrm{Insert}(t,\mathrm{pop}())$연산 이후, $t’$을 $t$ 이후의 최초의 bridge라고 할 때, $Q _ \mathrm{now}$로부터 $\min _ {x \in Q _ {t’}} x$이 삭제된다.
또한 시간 $t$에 $\mathrm{push}(x)$연산이 있을 때, $\mathrm{Delete}(t)$는 insert될 원소를 삭제하는 것과 동치이므로, 아래 lemma도 자연스럽게 얻어집니다.
LEMMA
시간 $t$에 $\mathrm{push}(x)$연산이 있을 때, $t’$을 $t$이후의 최초의 bridge라고 할 때, $\mathrm{Delete}(t)$연산 이후, $Q _ \mathrm{now}$로부터, $x \in Q _ \mathrm{now}$라면 $x$가 삭제되고, 아닐경우 $\min _ {x’ \in Q _ {t’}} x’$가 삭제된다.
위 lemma들을 종합하여, 다음 theorem이 얻어집니다.
THEOREM
모든 retroactive한 update들을 $O(\log m)$에 수행하고, 현재 시간에 대한 query들을 $O(1)$에 수행하는 retroactive priority-queue data structure가 존재한다.
PROOF
$Q _ t$를 추적하는 것이 매우 어렵기 때문에, 모든 연산은 $Q _ \mathrm{now}$와 update들에 대한 정보를 통해 $\max _ {x’ \in D _ {\ge t}} x’ = \max _ {x’ \in I _ {\ge t’} - Q _ \mathrm{now}} x’$와 $I _ {\le t’} \cap Q _ \mathrm{now}$를 이용하여 이루어질 것입니다. 제시할 자료구조는 모든 update들을 시간으로 정렬된 상태로 doubly linked list에 저장하고, $Q _ \mathrm{now}$를 balanced binary search tree에 저장합니다. 그리고 $Q _ \mathrm{now}$의 각 원소들은 그 원소를 생성한 insert연산으로의 doubly linked list의 pointer를 저장합니다. 이제 각 연산마다, 위 lemma들에 따라 $Q _ \mathrm{now}$가 update될 것입니다. 이 과정을 효율적으로 하기 위해서는 두가지 연산을 처리해야 합니다.
- $t$가 주어질 때, $t$ 이전의 마지막 bridge와 $t$ 이후의 최초의 bridge 탐색
- bridge $t’$이 주어질 때, $I _ {\ge t’} - Q _ \mathrm{now}$의 최대원소와 $I _ {\le t’} \cap Q _ \mathrm{now}$의 최소원소 탐색
만약 $x \in Q _ \mathrm{now}$에 대해 $\mathrm{push}(x)$에 가중치 0을 주고, $x \notin Q _ \mathrm{now}$에 대해 $\mathrm{push}(x)$에 가중치 1을 주며, $\mathrm{pop}()$에 가중치 -1을 주면, bridge는 prefix sum이 정확히 0인 지점이 됩니다. 그리고 이는 retroactive deque에서 썼던 방법과 동일하게 처리해 줄 수 있습니다. 또한, $\mathrm{push}$연산들을 또 하나의 balanced binary search tree에 저장하면서 각 노드에, subtree의 $Q _ \mathrm{now}$에 존재하지 않는 key중 최댓값을 추적해주면 $I _ {\ge t’} - Q _ \mathrm{now}$의 최대 원소를 $O(\log m)$에 구할 수 있고, 추가적으로 subtree의 $Q _ \mathrm{now}$에 존재하는 key중 최솟값을 추적해주면 $I _ {\le t’} \cap Q _ \mathrm{now}$의 최소 원소도 $O(\log m)$에 구할 수 있습니다. 매 연산마다 $Q _ \mathrm{now}$는 최대 하나의 원소가 바뀌기 때문에, 위 모든 과정은 $O(\log m)$안에 수행할 수 있습니다.
$\blacksquare$
Summary
| Abstract Data Type | Partially Retroactive | Fully Retroactive |
|---|---|---|
| Queue | $O(1)$ | $O(\log m)$ |
| Deque | $O(\log m)$ | $O(\log m)$ |
| Union-Find | $O(\log m)$ | $O(\log m)$ |
| Priority-Queue | $O(\log m)$ | $O(\sqrt{m} \cdot \log m)$ |