키보드 음성 키로거
1. Introduction
최근에 참가한 PBCTF 2021에서 Ghost Writers라는 이름의 문제를 보다가 굉장히 흥미로운 주제를 알게 되어 소개해드립니다. 특히 음성 인식과 머신 러닝에 관심이 많은 분이라면 좋은 연구 주제가 될 수 있다고 생각합니다.
트위치나 아프리카와 같은 플랫폼에서 여러 스트리머의 방송을 보다보면 마이크를 꺼두지 않는 한 방송 중에 기계식 키보드의 타이핑 소리가 그대로 송출이 되는 경우가 거의 대다수입니다. 이 타이핑 소리로부터 무언가 의미있는 정보를 얻기는 어려울 것 같지만, 혹시 지금 주변에 기계식 키보드가 있다면 여러 키를 눌러보았을 때 의외로 소리에 차이가 나는 경우를 쉽게 관찰할 수 있습니다. 대표적으로 스페이스 바와 그냥 q와 같은 버튼을 누를 때에는 확실히 소리의 크기에 차이가 있습니다. 그렇기 때문에 타이핑 소리를 아주 잘 분석하면 키보드 소리로부터 스트리머가 입력한 데이터가 무엇인지를 알아내는게 아예 불가능하지는 않겠다는 생각을 할 수 있습니다. 더군다나 방송의 특성상 게임 내의 채팅 혹은 메모장에 작성한 글과 같이 화면으로 송출되고 있는 곳에 무언가 작성을 한다면 타이핑 소리와 입력한 데이터를 매칭시킬 수 있는 경우도 많습니다. 그렇기 때문에 공격자의 입장에서 스트리머가 타이핑한 데이터를 파악해 계정의 비밀번호, 사적인 대화 내용등을 알아낼 수 있게 되는 경우가 충분히 발생할 수 있습니다. 꼭 스트리밍이 아니더라도 Zoom, VoIP와 같은 서비스에서도 비슷한 일이 발생할 수 있습니다.
물론 당연히 이러한 연구 방향을 해당 문제의 출제자가 처음 생각해낸건 아니고 Keyboard acoustic emanations, D. Asonov et al., Don’t Skype & Type!: Acoustic Eavesdropping in Voice-Over-IP, A. Compagno et al. 등의 선행 연구가 있습니다. 먼저 비교적 최신 논문인 Don't Skype & Type!: Acoustic Eavesdropping in Voice-Over-IP, A. Compagno et al.의 내용을 아주 간략하게 리뷰해보겠습니다.
2. Don’t Skype & Type!: Acoustic Eavesdropping in Voice-Over-IP, A. Compagno et al.
해당 논문에서는 공격자가 victim의 키보드 입력 소리를 VoIP 프로그램인 스카이프나 구글 등을 통해 전달받을 수 있는 상황을 가정합니다. 키보드에서 키를 누를 때와 뗄 때 음성 신호에는 2번의 pick이 발생하게 됩니다.
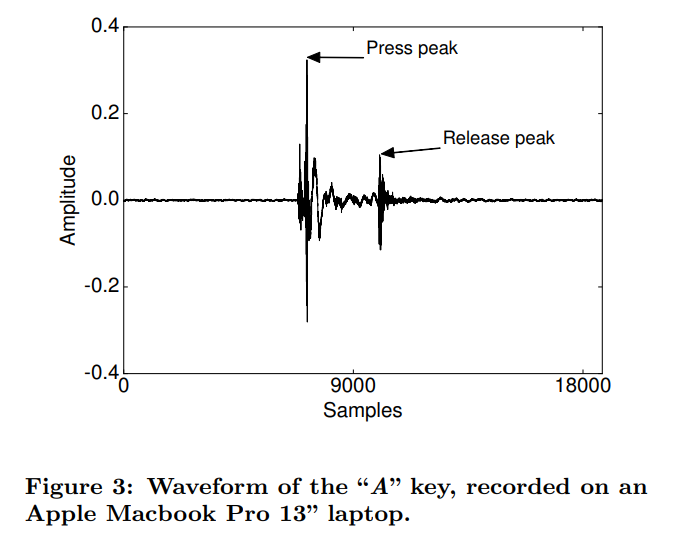
논문에서는 이를 토대로 키보드의 입력을 감지할 수 있게 음성 신호를 normalize한 후 10ms 정도의 작은 단위로 구간을 쪼개어 해당 구간의 에너지가 일정 threshold를 넘겼는지 확인합니다. 이 때 FFT의 계수를 더하는 방법이 쓰입니다. 만약 threshold를 넘겼을 경우 해당 구간에 키 입력이 있었다고 가정하고, 대략 100ms 구간을 잘라내어 해당 파형을 키 입력이 녹음된 파형으로 생각합니다.
파형을 추출한 후 해당 파형이 실제 어떤 키에 대응되는지를 판별할 때에는 여러 휴리스틱이 동원됩니다. 일단 Feature를 MFCC(Mel-Frequency Cepstral Coefficients), FFT coefficients, cepstral coefficients 등의 여러 음성 분석 기법으로 추출한 후 Logistic Regression을 수행합니다. 이러한 기법들을 통해 최종적으로 대략 92% 내외의 정확도로 키보드의 입력을 알아낼 수 있었습니다.
구현 코드는 여기서 확인해볼 수 있습니다.
논문에서 제시한 방법에서는 만약 100ms 구간 내에 다른 키 입력이 발생할 경우 제대로 분석이 이루어지지 않을 수가 있습니다. 하지만 구간의 길이를 꼭 100ms으로 두지 않더라도 30ms 이상으로 두면 그럭저럭 합리적인 수준의 결과가 나온다는 것이 설명되어 있습니다. 1분에 600타를 친다고 가정하면 타이핑당 간격이 100ms이니 30ms 정도면 충분히 합리적인 수치로 생각이 듭니다. 또한 키보드 소리만 녹음되지 않고 다른 음성과 함께 녹음이 되는 경우, 키보드 소리가 다른 음성의 데시벨보다 높을 경우에는 성능에 큰 변화가 없었지만 다른 음성의 데시벨이 키보드 소리보다 높을 경우에는 점차 성능의 저하가 발생했고 특히 20dB 이상 높을 경우에는 랜덤으로 키를 고르는 것과 동일한 성능을 내었습니다.
또한 이 공격으로부터 방어를 할 수 있는 방법으로 키 입력이 감지될 때 마다 키 입력 소리와 관련이 있는 특정 주파수대역의 값에 조그만 변화를 줘서 듣는 입장에서 크게 어색하지 않으면서도 파형의 유사성을 낮추는 방법을 제안했습니다. 이 방법을 통해 정확도를 92%에서 20% 이하로 낮출 수 있었습니다.
3. Keytap
2018년에 공개된 Keytap이라는 프로그램이 있습니다. 해당 툴 또한 Acoustic Eavesdropping을 도와주는 툴이고 제작자에 따르면 Don't Skype & Type!: Acoustic Eavesdropping in Voice-Over-IP, A. Compagno et al. 논문을 어느 정도 참고하긴 했지만 구현 아이디어는 스스로 떠올린 부분이 많다고 소개하고 있습니다. 이 프로그램의 경우 WebAssembly 구현체가 존재하기 때문에 직접 실행을 해볼 수 있다는 장점이 있습니다. 실행은 이 곳에서 해볼 수 있습니다.
이 프로그램 또한 휴리스틱을 이용하고 있습니다. Press peak을 토대로 75ms-100ms 정도의 구간을 자르고 음성 분석 기법으로 얻어낸 파형간의 유사도를 알아냅니다. 여기까지는 Don't Skype & Type! 논문과 크게 다를게 없는 방향인데 Keytap2라는 프로그램에서 제공하는 기능이 상당히 재밌습니다. Keytap2는 사전 학습이 아예 없는 상황을 가정합니다. 키보드 소리는 녹음이 되었지만 실제 무엇을 입력했는지는 아예 알지 못하는 상황을 생각해보면, 유사도로 키 분류를 완벽하게 했다는 가정하에 풀어야 하는 문제의 상황이 마치 고전 암호에서의 substitution cipher를 해결하는 상황과 동일합니다(참고).
그런데 Keytap에서는 키 분류를 완벽하게 할 수 있다기보다는 i번째 키 입력과 j번째 키 입력의 유사도가 0.79이다와 같은 방식으로 분류가 이루어집니다. 그렇기 때문에 Keytap2에서는 이 유사도 정보를 감안해서 입력받은 메시지를 짐작하고 이후 substitution cipher를 해결하는 방법을 사용하는데, 메시지를 고정해두는 대신 두 과정을 병합해서 substitution cipher를 해결할 때 유사도를 고려해 일부 글자를 수정할 수 있다면 더 좋겠지만 일단 그 부분은 보류가 되어있는 상황입니다. 논문처럼 성능 분석을 엄격하게 진행하지는 않았지만 시연 영상을 보면 꽤 잘 동작함을 확인할 수 있습니다.
4. Deep Learning Approach
우선 필자는 음성 처리에 대해 거의 아는 바가 없고, 딥러닝(을 포함한 AI)와 관련된 과목을 이번 학기에 처음으로 수강해서 개/고양이 분류하는 모델을 불과 한 달 전쯤에 작성해본 AI 뉴비입니다. 이 점을 감안해서 이번 단원의 글을 읽어주시면 감사하겠습니다.
앞서 살펴본 Don't Skype & Type! 논문에서의 구현체와 Keytap 모두 분석을 위해 휴리스틱을 사용하고 있습니다. 그런데 음성 데이터의 유사도 분석은 휴리스틱 대신 RNN을 사용해서 충분히 효과적으로 할 수 있습니다. LSTM, RNN등의 내용은 AI를 아는 입장에서는 너무 간단하기 때문에 당연히 알고 있을 내용이고, 모르는 입장에서는 이해가 사실상 불가능하기 때문에 설명을 생략합니다.
threshold를 통해 키 입력을 감지하는 로직 또한 개선이 가능하겠지만 해당 로직은 굳이 인공지능을 쓰지 않더라도 충분히 강력한 것으로 보이니 그대로 두고, 키 입력이 녹음된 75-100ms의 구간을 잘라낸 후 해당 구간이 어떤 소리에 대응되는지를 분류하는 문제는 video classification 문제와 비슷한 맥락에서 해결이 가능하다고 생각이 듭니다. 그렇기 때문에 타이핑 소리와 입력한 데이터를 매칭시킬 수 있어 충분한 학습 데이터를 확보해뒀다고 가정했을 경우 상당히 높은 수준의 정확도를 낼 수 있다고 전망됩니다.
5. 결론
이번 글에서는 키보드 음성 키로거의 가능성과 더불어 Don't Skype & Type! 논문, Keytap과 같은 구현체를 소개했습니다. 또 AI를 아주 얕게 배워서 현재 더닝 크루거 곡선의 최상단에 위치하고 있기 때문에 그런 생각을 하는 것일수도 있지만, RNN을 통해 기존의 구현체를 충분히 개선할 여지가 있다고 생각이 듭니다. 도저히 여유가 나지 않아 일단 미루고 있는데 다음에 여유가 된다면 꼭 구현을 해보려고 합니다.
한편으로 키보드 음성 키로거는 상당히 파급력이 있는 공격이라고 생각합니다. 특히 기계식 키보드의 경우 소리가 크게 두드러지는데 이 소리가 송출되어도 크게 의미있는 정보가 될 수 있다는 생각을 하기는 쉽지 않습니다. 그러나 소개한 여러 결과들에서 볼 수 있듯 해당 소리로부터 충분히 입력한 데이터가 무엇인지를 알아낼 수 있습니다. 특히 대중에게 다소 개인적인 영역이 노출되기 쉽고 인기가 많아 이른바 사생팬으로부터 프라이버시 위협을 늘 받고 있는 스트리머의 경우 이 문제로 인해 패스워드를 비롯한 여러 개인 정보의 유출로 인한 피해를 받을 수 있습니다.
이 공격이 널리 알려져 플랫폼 차원이나 개인이 소프트웨어적인 방어 대책을 세운다면 Don't Skype & Type! 논문에서 제시된 랜덤 노이즈 추가는 공격자가 AI 기반의 분석을 시도할 경우 비교적 간단하게 파훼가 가능할 것으로 보입니다. 그렇다면 방어자는 공격자의 분류 모델에 대해 Adversarial Attack을 수행하는 방향으로 방어를 할 수 있습니다.
이 공격이 정말 저의 예상대로 대중화가 될 수 있는지는 장담할 수 없지만 개인 차원에서는 방송을 송출할 때 기계식 키보드를 사용하지 않는다거나, 마이크를 키보드로부터 최대한 멀리 두어서 키보드 소리가 다른 소리에 묻힐 수 있도록 하는 조치를 취할 수 있다고 생각합니다. 주변에 아는 스트리머가 있다면 이 글의 내용을 전달하는 것도 나쁘지 않아보입니다.