GNN을 이용한 컴파일러 기원 문제 해결 방법
1. Introduction
프로그래머가 작성한 코드는 컴파일 과정을 거쳐 기계가 해석 가능한 코드로 변환됩니다. 이 때 동일한 소스 코드임에도 불구하고 컴파일러의 종류에 따라 최종 결과물인 실행 파일에는 차이가 있을 수 있습니다. 하지만 일반적으로 실행 파일로부터 컴파일러의 종류와 버전, 최적화 옵션 등을 알아맞추는 것은 다소 난이도가 있는 작업이고 특히 디버깅 심볼을 포함한 여러 메타 데이터가 제거된 실행 파일에서는 파일에 포함된 문자열 등을 활용할 수 없이 오로지 데이터 영역의 값만을 통해 컴파일러를 유추해야 합니다. 한편, 실행 파일로부터 컴파일러의 정보를 알아내는 것은 악성 코드 분석, 디지털 포렌식 등에서 유용하게 쓰일 수 있습니다. 예를 들어 애플의 XcodeGhost[O6]와 같이 컴파일러 자체에 백도어가 발견된 경우, 앱스토어에 등록된 여러 어플리케이션 중에서 해당 컴파일러로 컴파일된 어플리케이션을 분류할 수 있다면 적절한 후속 조치를 취하는데에 도움이 될 수 있습니다. 또한 비슷한 분석은 프로그램의 저자 판별(Authorship Attribution) 문제에서도 활용될 수 있습니다.
이번 글에서는 기존의 컴파일러 기원(Compiler provenance) 문제에 대한 접근법 [RMZ10] [RMZ11] [BMB21]에서 착안하여 GNN(Graph Neural Network)를 이용해 주어진 실행 파일이 GCC, Clang, ICC중 어떤 것으로 컴파일된 것인지를 알아맞추는 방법을 고안하고 성능을 확인해본 일련의 과정을 소개해드리려고 합니다. 컴파일러 기원 문제나 GNN 등에 대해 지식이 없더라도 관련 내용에 대한 설명이 포함되어 있으니 큰 무리 없이 글을 이해할 수 있을 것으로 보입니다.
2. Related work
Rosenblum 등은 컴파일러를 구분지을 수 있는 여러 idiom feature들을 수집해 이를 바탕으로 주어진 프로그램의 컴파일러 기원을 알아맞추는 방법을 제안해 175개의 소스 코드로부터 컴파일된 프로그램에서 0.999의 정확도로 컴파일러의 종류를, 0.918의 정확도로 컴파일러의 버전을 맞출 수 있었습니다 [RMZ10] [RMZ11]. 이 방법을 통해 Ji 등은 컴파일러 기원 문제를 명령 단위의 feature와 CFG로부터 구해지는 그래프 단위의 feature를 결합해 Function Call Graph(FCG) 그래프에서 특성을 분류하는 문제로 생각해 Graph Neural Networks(GNN)을 사용하는 방법을 제안해 6,000개가 넘는 실행 파일에서 0.995의 정확도로 컴파일러의 종류를, 0.990의 정확도로 최적화 관련 옵션을 맞출 수 있었습니다 [JCH21]. Benoit 등은 CFG에서 RET, CALL, JMP, JCC와 같은 명령만 남긴 Forgetting CFG에서 Graph Neural Network(GNN)을 사용하는 방법을 제안해 36,272개의 소스 코드로부터 컴파일된 프로그램에서 0.9944의 정확도로 컴파일러의 종류를, 대략 0.7598의 정확도로 최적화 관련 옵션을 맞출 수 있었습니다 [BMB21].
3. Background
Graph Neural Networks
Graph Neural Networks (GNN) [ZCH+20]은 그림 혹은 영상과 같이 n차원 선형 공간에서 표현 가능한 데이터에 대한 처리가 가능하게끔 하는 Convolutional Neural Networks(CNN) [LBBH98]을 그래프 데이터에 대해서도 사용할 수 있게 확장한 신경망입니다. GNN을 통해 정점 단위(Node-level)의 계산, 간선 단위(Edge-level)의 계산, 그래프 단위(Graph-level)의 계산을 수행할 수 있습니다. 이 글에서는 주어진 컴파일러 기원 문제를 CFG에 대한 그래프 분류(Graph classification) 문제로 환원해서 해결할 예정입니다.
Control Flow Graph 복원
Control Flow Graph는 프로그램이 실행 중에 횡단할 수 있는 모든 경로를 나타낸 그래프입니다. 아래와 같은 코드를 생각해봅시다.
x = int(input())
if x == 0:
print("x = 0")
else:
print("x != 0")
아래의 코드는 사용자로부터 입력 받은 수의 값이 0인지 아닌지에 따라 분기가 발생합니다. 이 코드에 대한 CFG를 그려보면 아래와 같습니다.
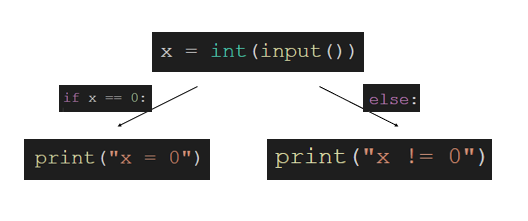
디버깅 정보가 스트립된 실행 파일에서 이와 같은 Control Flow Graph(CFG)를 복원하는건 정적 분석의 정확성을 높이기 위해 반드시 필요한 작업입니다. CFG를 복원하기 위해서는 우선 주어진 실행 파일에서 코드 영역과 데이터 영역을 구분해야 하고, 이후 코드 영역의 어셈블리 코드를 보며 JMP 명령을 찾아서 직접 호출(Direct call)을 처리합니다. 또한 switch문과 같은 문법으로 인해 발생할 수 있는 간접적 호출(Indrect call) 또한 처리를 해야 하고, 이 간접적 호출에 대한 처리가 CFG 복원의 큰 어려움으로 작용합니다.
다행히 CFG 복원 단계에서 간접적 호출을 처리하기 위한 여러 방법들이 제안된 바 있습니다 [CVE01] [KRVV04] [XSS09]. Shoshitaishvili 등은 이 방법들을 기반으로 해 현실적인 시간 안에 실제 실행 파일의 CFG를 복원할 수 있는 기능이 포함된 실행 파일 분석 프레임워크 angr를 만들었습니다 [SWS+16].Jung 등은 자체적으로 만든 효율적인 IR을 기반으로 하는 실행 파일 분석 프레임워크 B2R2를 만들었습니다 [JKH+19]. Di 등은 QEMU와 LLVM을 기반으로 한 실행 파일 분석 프레임 워크 REV.NG를 만들고 기존의 다른 도구들과 성능을 비교했습니다 [DFPA17]. x86-64 환경에서 GCC과 Clang으로 컴파일된 프로그램에 대해 함수를 각 분석 도구가 얼마나 정확하게 구분짓나 확인할 때 BAP는 Clang 기준 60\% 및 GCC 기준 83\%, IDA Pro와 angr는 94\%, REV.NG는 98\% 정도의 정확도를 가짐을 확인할 수 있었습니다. BAP는 정확도가 다른 도구들에 비해 많이 낮고 IDA Pro는 상용 소프트웨어이기 때문에 고려를 하지 않았습니다. angr와 REV.NG를 비교할 때 2017년 비교 당시의 성능은 REV.NG가 더 우수하나 angr가 REV.NG보다 더 긴 기간 동안 많은 분석가들에게 선택을 받아 사용되어 왔기 때문에 신뢰성이 더 높고, REV.NG와 비교할 때 10배 정도 더 많은 커밋으로 꾸준하게 관리되고 있으며, 결정적으로 angr는 CFG를 NetworkX 모듈의 그래프로 돌려주어 후처리를 편하게 진행할 수 있다는 장점이 있습니다. 이러한 점들을 고려해 이번 글에서는 angr를 이용해 CFG를 복원했습니다.
4. Design
저는 기존의 연구를 참고해 주어진 그래프로부터 CFG를 복원하고 CFG에서 Graph Neural Network(GNN)을 이용해 분류를 진행했습니다. 이 때 아래와 같은 사항들을 고려할 수 있습니다.
데이터 셋
각 컴파일러 별로 15개씩 제공된 binutils 실행 파일과 IOCCC(International Obfuscated C Code Contest, 국제 난독화 C 코드 대회)의 최근 수상 작품 14개에 대해 GCC 9.3.0, ICC 2021.4.0 20210910, Clang version 10.0.0-4ubuntu1에서 O0, O1, O2, O3 옵션으로 컴파일해서 각 컴파일러별로 56개의 실행파일을 확보한 후 이를 데이터 셋으로 활용했습니다. binutils 실행 파일은 알파벳 순으로 첫 9개의 실행 파일을 평가에 이용하고 뒤 6개의 실행 파일을 학습에 이용했습니다. IOCCC 실행 파일은 2019년 수상 작품 8개로 만들어낸 32개의 실행 파일을 평가에 이용하고 2020년 수상 작품 6개로 만들어낸 24개의 실행 파일을 학습에 이용했습니다. 학습에 이용한 실행 파일들은 디버깅 정보를 strip하지 않아 CFG의 정확성을 높일 수 있도록 했지만 평가에 이용한 실행 파일들은 strip --strip-all 명령을 이용해 디버깅 정보를 제거했습니다. binutils 실행 파일은 크기가 39KB인 elfedit 파일을 제외하고 나머지가 모두 크기 1.2MB 이상의 파일이었던 반면 IOCCC 실행 파일은 대부분의 파일이 10-50KB 범위에 있고 가장 크기가 큰 2020carlini 파일도 303KB인 정도의 작은 크기를 가지고 있었습니다.
GNN 학습 시 컴파일 옵션 고려 여부
컴파일러 기원 문제를 해결하는 이전의 연구들에서는 컴파일러 종류뿐만 아니라 O2, O3 등의 컴파일 옵션까지 맞추는 방법을 제시한 경우도 있었습니다 [RMZ11] [DFPA17] [BMB21]. 이번 글에서 다루는 문제는 컴파일러의 종류를 맞추는 것으로 범위가 제한되어 있지만 라벨링을 꼭 컴파일러의 종류로만 한정지을 필요가 없고 컴파일 옵션까지 라벨링을 해서 학습을 할 수도 있습니다다. 만약 GCC의 O2로 컴파일된 프로그램 A, ICC의 O2로 컴파일된 프로그램 B, GCC의 O3으로 컴파일된 프로그램 C에 대해 A와 C의 유사도가 A와 B의 유사도가 더 높다면 컴파일 옵션까지 라벨링을 해서 학습하는 것이 정확도 향상에 더 도움을 줄 것으로 예상할 수 있습니다. 그러나 학습 후 혼동 행렬(Confusion matrix)를 확인해보면 같은 컴파일러 종류에서 플래그가 다른 경우 혼동이 발생하지만 다른 컴파일러 종류에서는 혼동이 거의 발생하지 않기 때문에 컴파일 옵션은 별도로 라벨링을 하지 않고 학습을 진행했습니다 [BMB21].
CFG 복원
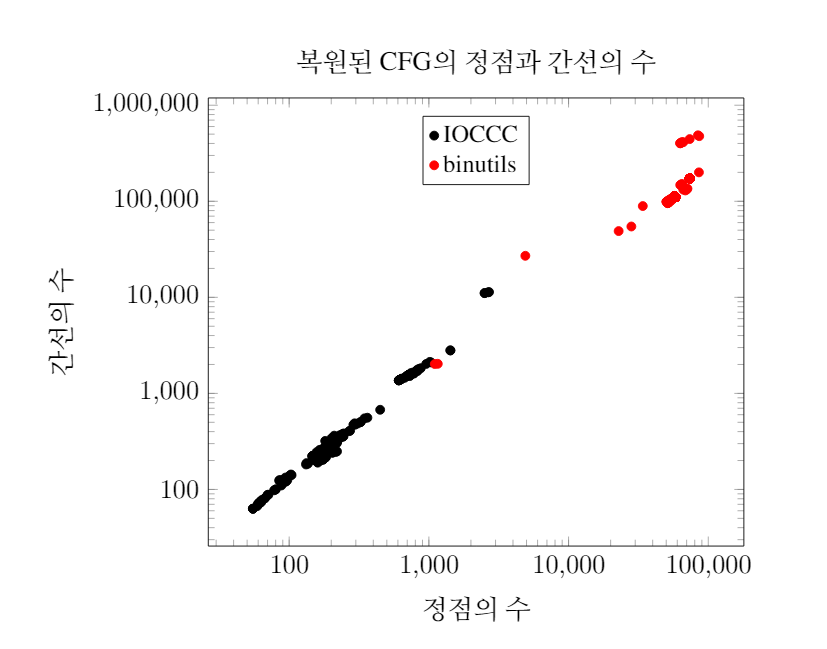
실행 파일 분석 프레임워크 angr를 이용해 주어진 실행 파일에 대한 CFG를 복원했습니다. binutils 실행 파일과 IOCCC 실행 파일 각각에 대한 정점과 간선의 수는 아래와 같습니다. IOCCC 실행 파일은 대부분의 경우 정점의 수가 1000 이하인 반면 binutils 실행 파일은 대부분의 경우 정점의 수가 50000 이상임을 확인할 수 있습니다.
GNN 구조
각 정점의 특성(feature)은 새로운 블록으로의 분기가 이루어지는 가장 마지막 명령으로 정했습니다. 전체 실행파일에 대해 가장 마지막 명령은 call, je, jne, jno, movdqa, bswap 등 총 75개가 등장했습니다. 이를 one-hot encoding한 값을 GNN에서 각 정점의 특성으로 사용하여 입력 레이어(Input layer)의 크기는 75입니다. 이번 글에서 해결하고자 하는 문제는 세 종류의 컴파일러 중 정답을 알아맞추는 것이므로 출력 레이어(Output layer)의 크기는 3입니다. 히든 레이어(Hidden layer)는 크기를 400으로 정해 1개를 배치했습니다. 입력 레이어와 히든 레이어, 그리고 히든 레이어와 출력 레이어 사이에는 GCN(Graph Convolutional Network)를 배치했습니다. 활성화 함수는 relu이고 학습률(learning rate)은 0.001, epoch는 10, 손실 함수(loss function)는 cross entopy입니다.
부분 그래프
5만개가 넘는 정점을 가지고 있는 그래프를 그대로 입력에 넣을 경우 현실적인 시간 안에 계산이 불가능합니다. GNN를 큰 그래프에 대해서도 수행할 수 있게 시간 복잡도와 공간 복잡도를 줄이는 방법이 제안된 바 있습니다 [CLS+19]. 한편 컴파일러 기원 문제에서는 너비 우선 탐색(Breadth-First Search)를 이용해 그래프를 분리하는 아이디어가 제안되었습니다 [BMB21]. 이번 글에서는 Benoit등의 방법을 인용해 시작 정점을 임의로 선택하고 해당 시작 정점에서 너비 우선 탐색을 거쳐 크기가 최대 50인 부분 그래프들을 구해 해당 부분 그래프로 학습을 진행했습니다. 평가를 진행할 때에는 정점의 개수에 비례한 개수의 부분 그래프를 구한 후 해당 부분 그래프로부터 얻어낸 결과 벡터를 모두 더해 그 결과로부터 컴파일러 기원을 결정했습니다.
5. Evaluation
실험은 Windows 10 Pro 64-bits, Intel Core i7-10700F CPU @ 2.90GHz, 32.0GB RAM, NVIDIA GeForce RTX 3070 환경에서 진행되었습니다. CFG는 angr 9.0.10651, GNN은 파이썬 모듈 dgl 0.7.2, cuda 11.3.109, PyTorch 1.10.0+cu113을 이용해 구현했습니다.
CFG의 생성에는 총 30분이 소요되었습니다. 213개의 실행 파일로 만들어낸 CFG로부터 41,015개의 부분 그래프를 얻어 해당 부분 그래프들로 학습을 진행했습니다다. 한 epoch당 실행 시간은 3분 내외였습니다.
평가는 binutils 실행 파일과 ioccc 실행 파일로 나누어 진행했습니다. 27개의 binutils 실행 파일 전체에 대한 평가 실행 시간은 24분 내외였습니다. 또한 binutils 실행 파일은 단 1회의 학습만으로도 100\% 정확하게 컴파일러를 분류할 수 있었습니다. 96개의 ioccc 실행 파일 전체에 대한 평가 실행 시간은 8분 내외였습니다. ioccc 실행 파일에 대한 실험 결과는 아래와 같습니다.
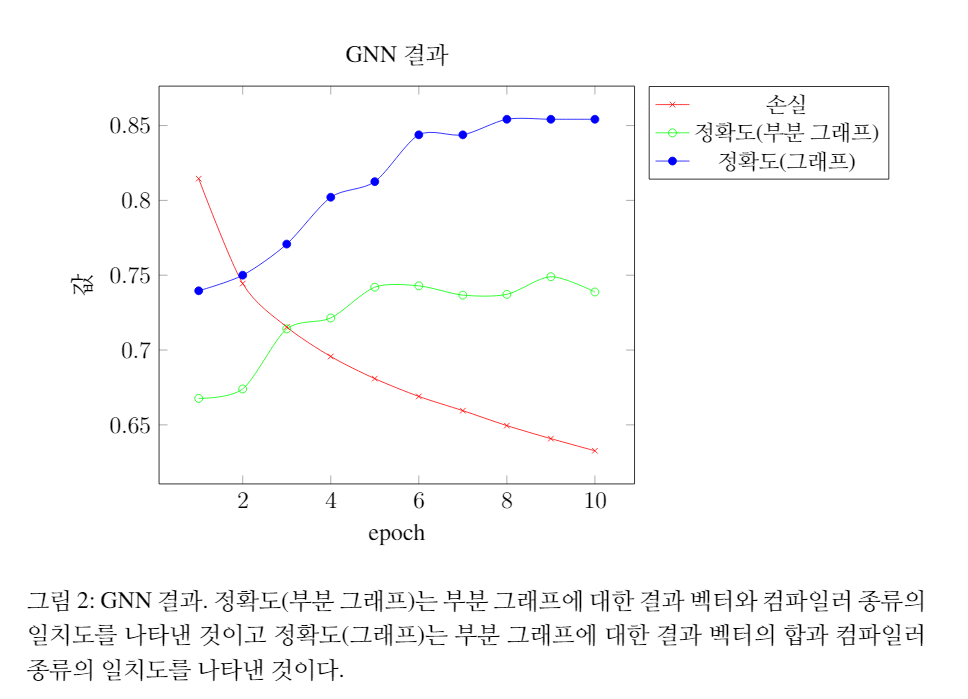
실험 결과 96개 중에서 82개에 대해 컴파일러를 올바르게 유추했습니다. 컴파일러를 다르게 유추한 14개의 경우 11개가 Clang이었고 3개가 ICC이었습니다. Clang에 대해 현재 모델의 정확도는 0.656으로 정확도가 각각 0.906, 1.000인 ICC, GCC에 비해 다소 낮은 정확도를 보여주었습니다.
6. Conclusion
이번 글에서는 컴파일러 기원 문제를 GNN으로 해결하는 방법을 알아보고 구현을 통해 결과를 확인했습니다. 실행파일이 비교적 큰 binutils 파일에 대해서는 1회의 학습만으로도 100\% 정확하게 컴파일러를 분류할 수 있었고 대부분의 파일이 50KB 미만인 ioccc 실행 파일에 대해서도 정확도 0.8542의 합리적인 결과를 얻을 수 있었습니다.
한편으로 (i) GNN에서 부분 그래프의 최대 크기, 학습률, 히든 레이어의 크기 등 여러 하이퍼 파라미터의 변경에 따른 결과의 변화, (ii) 최신의 GNN 논문에서 제안된, 정점이 많은 그래프에서도 학습을 진행할 수 있게 설계된 GNN 구조 도입, (iii) CFG 이외에도 컴파일러의 차이에 따른 파일 크기 혹은 함수의 수와 같은 다른 속성들을 포함한 기계 학습, (iv) 파일 크기가 50KB 이하로 작은 실행 파일에서 성능을 개선하기 위한 방법등을 고려할 경우 더 정확한 분류를 할 수 있을 것으로 보입니다.
또한 GCC, ICC에 비해 Clang의 정확도가 상당히 낮게 나온 이유를 알아내지 못했는데, 이 이유에 대해서도 탐구를 해보면 흥미로운 결과를 얻을 수 있을 것으로 보입니다.
구현에 사용된 코드는 리팩토링을 거친 후에 깃헙에 업로드할 계획인데 혹시 그 전에 코드가 필요하시면 admin [at] encrypted.gg로 문의 주시면 코드를 보내드릴 수 있습니다.
7. References
[BMB21] Tristan Benoit, Jean-Yves Marion, and S ́ebastien Bardin. Binary level toolchainprovenance identification with graph neural networks. In2021 IEEE InternationalConference on Software Analysis, Evolution and Reengineering (SANER), pages131–141. IEEE, 2021.
[CLS+19] Wei-Lin Chiang, Xuanqing Liu, Si Si, Yang Li, Samy Bengio, and Cho-Jui Hsieh.Cluster-gcn: An efficient algorithm for training deep and large graph convolutionalnetworks. InProceedings of the 25th ACM SIGKDD International Conference onKnowledge Discovery & Data Mining, pages 257–266, 2019.
[CVE01] Cristina Cifuentes and Mike Van Emmerik. Recovery of jump table case statementsfrom binary code.Science of Computer Programming, 40(2-3):171–188, 2001.
[DFPA17] Alessandro Di Federico, Mathias Payer, and Giovanni Agosta. rev.ng: a unifiedbinary analysis framework to recover cfgs and function boundaries. InProceedingsof the 26th International Conference on Compiler Construction, pages 131–141,2017.
[JCH21] Yuede Ji, Lei Cui, and H Howie Huang. Vestige: Identifying binary code prove-nance for vulnerability detection. InInternational Conference on Applied Cryp-tography and Network Security, pages 287–310. Springer, 2021.
[JKH+19] Minkyu Jung, Soomin Kim, H Han, Jaeseung Choi, and S Kil Cha. B2r2: Buildingan efficient front-end for binary analysis. InProceedings of the NDSS Workshopon Binary Analysis Research, 2019.
[KRVV04] Christopher Kruegel, William Robertson, Fredrik Valeur, and Giovanni Vigna.Static disassembly of obfuscated binaries. InUSENIX security Symposium, vol-ume 13, pages 18–18, 2004.
[LBBH98] Yann LeCun, L ́eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-basedlearning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998.
[O6] Dick O’Brien. The apple threat landscape.Symantec report, 2016.
[RMZ10] Nathan E Rosenblum, Barton P Miller, and Xiaojin Zhu. Extracting compilerprovenance from program binaries. InProceedings of the 9th ACM SIGPLAN-7
SIGSOFT workshop on Program analysis for software tools and engineering,pages 21–28, 2010.
[RMZ11] Nathan Rosenblum, Barton P Miller, and Xiaojin Zhu. Recovering the toolchainprovenance of binary code. InProceedings of the 2011 International Symposiumon Software Testing and Analysis, pages 100–110, 2011.
[SWS+16] Yan Shoshitaishvili, Ruoyu Wang, Christopher Salls, Nick Stephens, Mario Polino,Andrew Dutcher, John Grosen, Siji Feng, Christophe Hauser, Christopher Kruegel,et al. Sok:(state of) the art of war: Offensive techniques in binary analysis. In2016IEEE Symposium on Security and Privacy (SP), pages 138–157. IEEE, 2016.
[XSS09] Liang Xu, Fangqi Sun, and Zhendong Su. Constructing precise control flow graphsfrom binaries.University of California, Davis, Tech. Rep, 2009.
[ZCH+20] Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu,Lifeng Wang, Changcheng Li, and Maosong Sun. Graph neural networks: A reviewof methods and applications.AI Open, 1:57–81, 2020.