Reverse Engineering of Generative Models
Introduction
이번 글에서는 페이스북 AI Research가 작성한 Reverse Engineering of Generative Models: Inferring Model Hyperparameters from Generated Images 논문을 소개하고자 합니다. 이 논문은 최근 딥러닝 기술의 발달로 딥페이크가 악용되고 있는 상황에서, 딥페이크를 추적하는 기술이 어떤 것이 있나 조사하는 과정에서 알게 되었습니다. 본 논문은 딥페이크 판별과 더불어 딥페이크 이미지를 생성한 모델의 property까지 추론한다는 점에서 다른 딥페이크 탐지 기술과 차별화됩니다. 또한 AI 모델의 연구 진행 과정이 잘 보이는 것 같아서 소개하게 되었습니다. 작성된 내용은 논문과 저자들 중 일부가 페이스북 기술 블로그에 작성한 글을 위주로 작성되었습니다. 개인적으로 분석한 내용이라, 논문과 다르거나 잘못 작성했을 수 있다는 점은 양해 부탁드립니다.
용어정리
내용에 들어가기 앞서, 본 논문에서 사용하는 용어들을 정리하고자 합니다.
Deepfake detection
- 임의의 딥페이크 이미지가 어떤 딥페이크 생성 모델로 생성되었는지를 판단하는 것
Image attribution
- 임의의 딥페이크 이미지가 어떤 모델에 의해 생성되었는지를 판단하는 것
- 이미 아는 모델로 생성된 딥페이크 이미지도 있지만, 알지 못하는 모델로 생성된 딥페이크 이미지도 있음

Model parsing
- 딥페이크 이미지가 그것을 생성한 모델에 대해서 어떠한 정보를 알려주는지를 판단하는 것
- 각각의 생성 모델은 그것이 생성한 딥페이크에 자신의 imprint(각인)을 남긴다는 사실을 이용

개요
최근 딥페이크 기술은 쉽게 구분하지 힘들고 믿을만할 정도로 발전했습니다. 딥페이크를 탐지하는 것은 여전히 어려운 과제임에도, 대규모로 악의적인 의도를 가지고 만들어지는 딥페이크는 큰 문제를 야기할 수 있으며, 실제로도 딥페이크가 영화, 홍보 등에서 정당하지 못하게 사용된 선례도 많이 발생했습니다.
이에 따라 페이스북 AI Research에서는 Michigan State University (MSU)와 협력해서 Deepfake detection과 Image attribution에 관해서 연구를 진행했습니다. 본 연구는 생성 모델로 생성된 이미지 뿐만 아니라 그것을 생성하는 생성 모델까지를 대상으로 하는 Reverse engineering이라고 할 수 있습니다. 이는 딥페이크 이미지 자체가 생성 모델에 대한 유일한 단서라는 점에서 현실 세계에 바로 적용 가능하다는 장점이 있습니다.
Reverse engineering
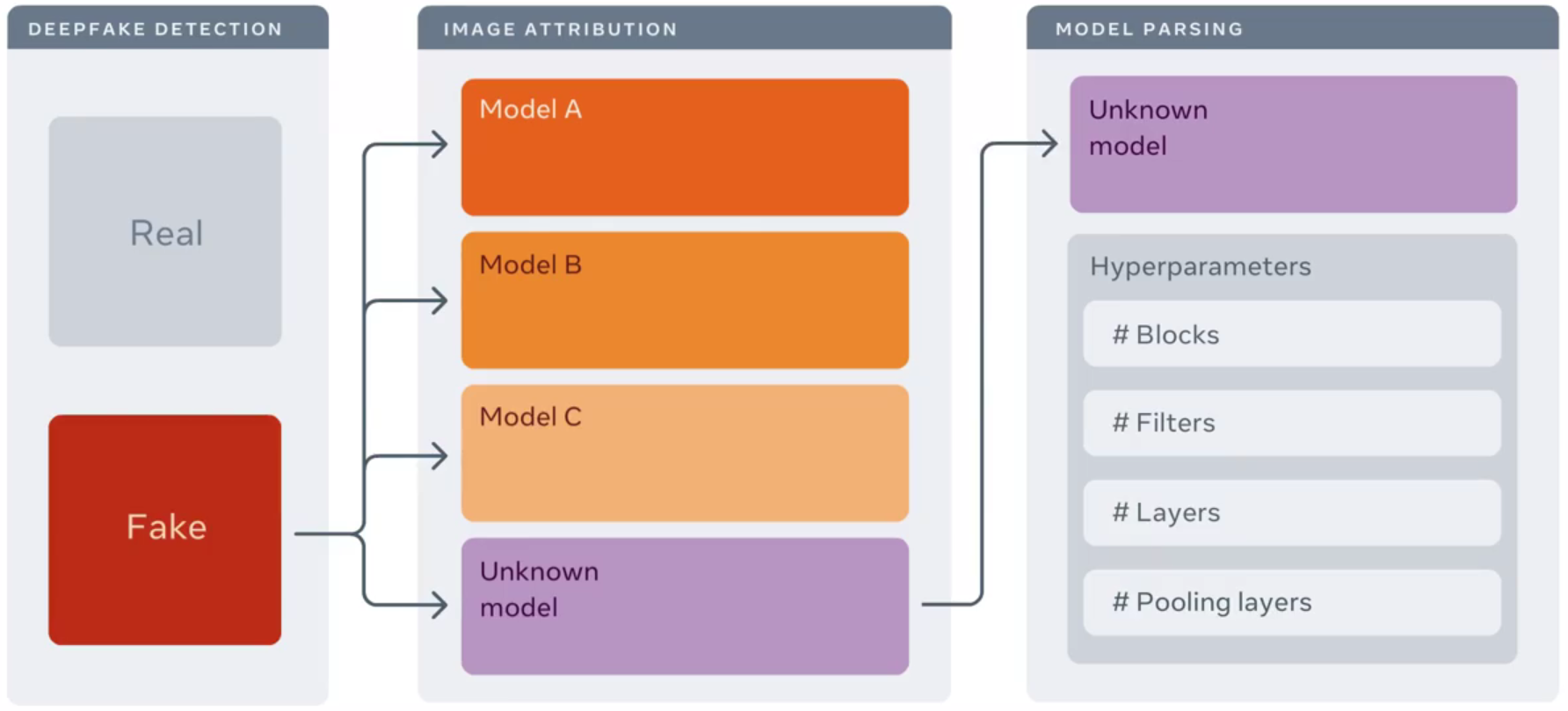
본 논문에서는 앞서 여러 번 언급한 것처럼, Deepfake detection에서 더 나아가, 이미 아는 모델이든 모르는 모델이든 어떤 모델에서 해당 딥페이크 이미지가 만들어졌는지 감별하는 Image attribution까지를 목표로 하고 있습니다. 하지만 학습 단계에 존재하는 한정된 모델 뿐만 아니라, 학습 데이터에 없는 알려지지 않은 모델까지 Image attribution을 확장하는 것은 더욱 어려운 문제입니다. 저자들은 학습 데이터에 포함된 모델에 관한 Image attribution을 Close-set image attribution이라고 부르며, 이를 넘어 알려지지 않은 모델에 관한 Open-set image attribution을 위해 reverse engineering 접근을 사용하였다고 합니다.
저는 잘 몰랐지만 ML 분야에서 reverse engineering 접근을 적용하는 것이 새로운 시도는 아니라고 합니다. 이전에 임의의 모델을 Black box로 여기고, 그것의 (input, output) 쌍을 통해서 해당 모델의 정보를 찾는 시도들이 있었다고 합니다. (input, output) 쌍 뿐만 아니라, 모델 추론 중에서 CPU나 메모리와 같은 Hardware 정보 또한 사용 가능합니다.
본 논문에서 사용하는 reverse engineering 접근은 구체적으로 딥페이크 이미지를 근거로 그를 생성한 생성 모델의 고유한 pattern, property를 추론하는 것입니다. 나아가 pattern들 사이의 유사성을 분석함으로써 대규모로 발생한 이미지들이 어떤 하나의 출처를 추론할 수도 있습니다.
Model parsing flow
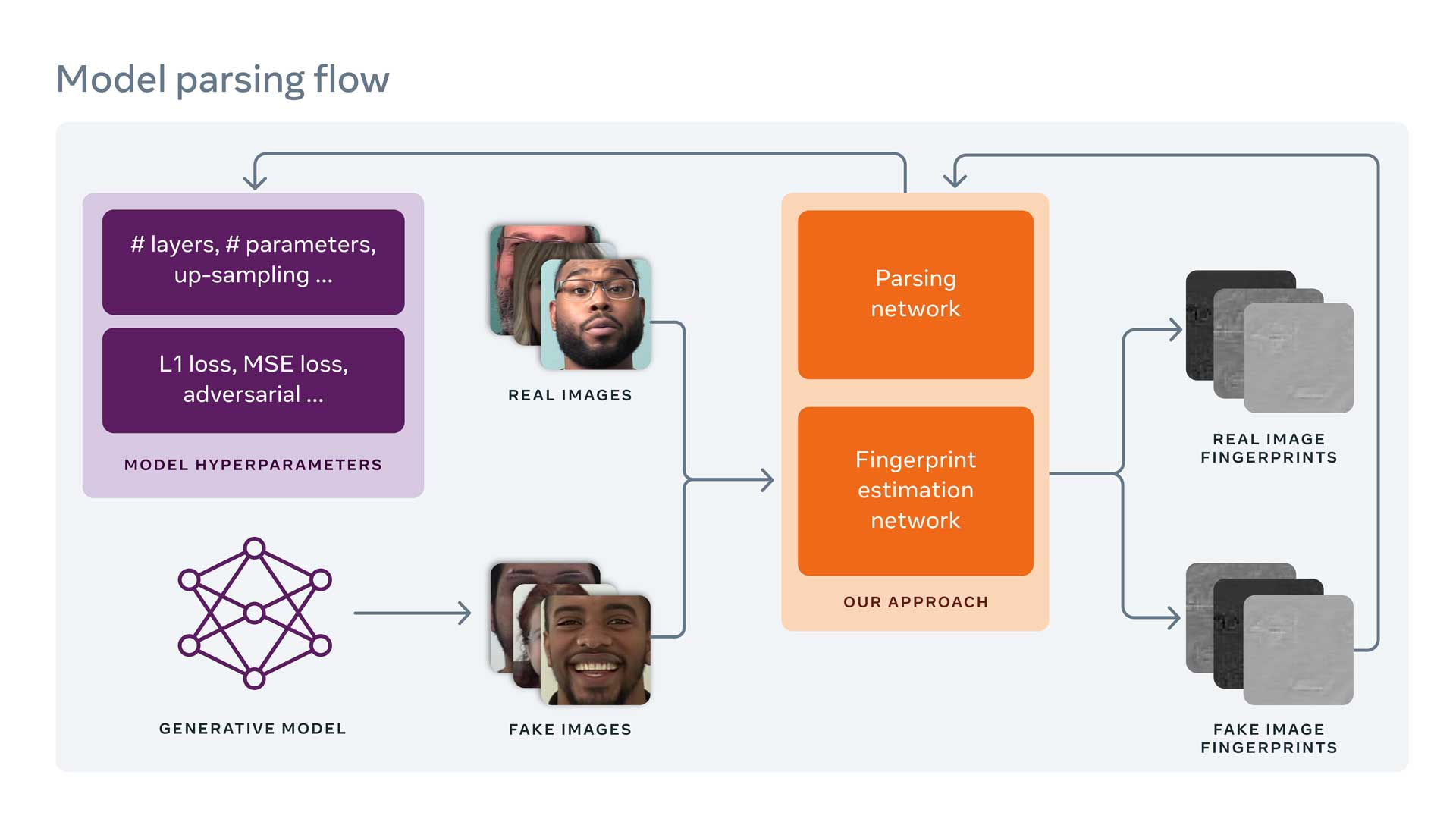
연구진은 생성 모델에 의해 남겨진 fingerprint에 대한 detail을 추정하기 위해서 Fingerprint Estimation Network (FEN)를 이용하는 것으로 연구를 시작했습니다. Device fingerprint는 특정한 장치에 의해 생산된 각 이미지에 남겨진, 탐지하기는 힘들지만 장치의 고유한 pattern입니다. Device fingerprint는 생성 과정에서의 imperfection에 의해 남겨지게 됩니다. 이러한 Device fingerprint와 유사하게, 본 연구에서는 이미지를 생성한 생성 모델을 식별하기 위해 해당 생성 모델이 남기는 고유한 pattern인 Image fingerprint를 근거로 사용합니다.
이때 발생하는 하나의 문제는 현재 존재하는 생성 모델이 너무나 많고, 앞으로 더 많아질 것이라는 것입니다. 다시 말해서, ML 이전에는 이미지를 생성하기 위해 소수의 잘 알려진 도구들을 사용했습니다. 그래서 Image fingerprint를 통해 그를 생성한 도구를 추론하는 것이 비교적 쉬웠습니다. 하지만 ML 기반으로 이미지를 생성하는 도구들이 상당히 많이 나왔기 때문에 이러한 문제가 훨씬 어려워졌습니다.
이렇게 수많은 생성 모델이 존재한다는 한계를 극복하기 위해서, 연구진은 unsupervised training을 위한 제약 조건을 개선하기 위한 basis로 fingerprint의 속성을 사용했습니다. 다시 말해, fingerprint magnitude (크기), repetitive nature (반복적인 성질), frequency range (주파수 범위), symmetrical frequency response 등을 포함한 일반적인 fingerprint의 속성에 따라 서로 다른 제약 조건을 사용해서 fingerprint를 추정했습니다. 그런 다음, 생성된 fingerprint들이 요구된 속성을 가지도록함을 목적으로 서로 다른 제약 조건들을 FEN에 적용하기 위해 서로 다른 loss function을 사용했습니다. 한번 fingerprint가 생성되면, 그 fingerprint는 Model parsing을 위한 input으로 사용될 수 있습니다.
정리하자면, fingerprint의 속성들을 다양하게 파악하기 위해서 다양한 loss function을 사용해서 다양한 fingerprint를 만들었고, 그 (fingerprint, 그를 생성한 모델) 쌍을 model parsing의 학습 데이터 (input)으로 사용합니다.
Model parsing은 추정된 생성 모델의 fingerprint를 사용해서 네트워크의 layer 수, block의 수, 각 block에 사용된 연산의 type 등과 같은 모델의 속성을 의미하는 모델의 hyperparameter들을 예측하는 새로운 문제를 의미합니다. 모델이 생성하는 딥페이크 이미지의 type에 영향을 주는 hyperparameter의 예시 중에는 training loss function이 있습니다. 당연하지만, loss function이 모델이 어떻게 학습될지를 결정하기 때문입니다. 결론적으로 모델의 network architecture와 training loss function 종류는 그 모델의 weight에 영향을 줄 것이고, 따라서 그 모델이 이미지를 생성하는 데 영향을 줄 것입니다. 이는 곁으로 보기에는 같은 모델이지만, hyperparameter에 따라서 각 모델을 구분하는 reverse engineering 접근에 포괄되는 내용입니다.
본 논문에서는 이러한 model parsing approach를 통해서, 임의의 모델이 딥페이크 이미지를 생성하는 데 사용하는 network architecture와 그 모델의 training loss function을 예측합니다. 연구진은 학습을 쉽게하기 위해 network architecture 내부의 일부 continuous parameter를 normalize했고, 또한 loss function 종류를 classify하기위해 hierarchical learning을 수행했습니다. 생성 모델은 일반적으로 자신의 network architecture와 training loss function으로 서로 구분되기 때문에, 딥페이크 이미지와 같은 생성된 이미지와 hyperparameter space를 mapping하는 것이 딥페이크 이미지를 생성한 모델의 feature를 이해하는 데 큰 도움을 된다는 아이디어의 확장인 것 같습니다. 이러한 접근이 개인적으로 인상깊었던 점이 논문을 소개하게 된 이유 중 하나입니다.
이 접근이 실제로 적용 가능한지를 테스트하기 위해서, MSU 연구진은 100개의 공개된 생성 모델로부터 생성된 100,000개의 가짜 이미지 셋을 사용했습니다. 각 생성 모델 당 1000개의 이미지를 사용한 셈입니다. 이때 사용된 각 생성 모델은 오픈 소스이며, 이미 생성된 이미지가 공개된 생성 모델에 대해서는 그 중에서 랜덤하게 1,000개의 이미지를 선택해서 사용했고 그렇지 않은 생성 모델에 대해서는 연구진에서 직접 1,00개의 이미지를 생성해서 사용했습니다. 테스트 이미지가 실제로는 알지 못하는 생성 모델에서 생성될 수 있다는 점을 고려하여, 연구팀은 서로 다른 분할된 데이터 셋을 사용하여 모델을 train하고 evaluate함으로써 cross-validation을 수행했습니다.
결과
Model parsing을 본 논문에서 처음 시도한 것이기 때문에, 비교를 위한 선행 연구가 존재하지 않았다고 합니다. 따라서 연구진은 ground-truth set의 각 hyperparameter를 랜덤하게 섞음으로써 baseline을 만들었고, 그를 random ground-truth라고 명명했습니다. 이러한 random ground-truth vector는 원래의 분포를 유지했고, 결과는 연구진의 접근이 random ground-truth baseline보다 훨씬 나은 성능을 보인다는 것을 보여주었습니다.
이러한 결과는 같은 길이와 분포를 가지는 random vector에 비해, 생성된 이미지와 의미있는 architecture hyperparameter의 embedding 공간 및 loss function types 사이에 훨씬 강하고 일반화된 상관관계가 있음을 나타냅니다.

위 결과 이미지에서 왼쪽은 100개의 생성 모델로부터 하나씩 생성된 100개의 이미지가 생성한 estimated fingerprint를 나타내고,오른쪽은 그에 관련된 frequency spectrum을 나타냅니다. 이를 통해 많은 frequency spectrum들이 뚜렷한 high-frequency signal들을 보여주며, 일부는 서로 유사한 signal 형태를 보인다는 사실을 알 수 있습니다.
Model parsing과 더불어, 본 연구에서 사용된 FEN은 deepfake detection과 image attribution에도 사용될 수 있습니다. 이 2개의 task를 위해서, 연구진은 estimated fingerprint를 입력으로 받아서 deepfake detection을 위한 binary classification이나 image attribution을 위한 multi-class classification을 수행하는 shallow network를 추가했습니다. 비록 fingerprint estimation이 deepfake detection과 image attribution task에 적합하게 조정된 것은 아님에도, 여전히 fingerprint estimation이 우수한 일반화 능력을 가지고 있음을 확인할 수 있었습니다.
딥페이크를 생성하는 데 사용된 원본 이미지 중 일부가 공개된 실제 사람의 얼굴 데이터였지만, MSU 연구진은 딥페이크를 생성하기 위해서 원본 이미지를 사용하기보다는 그 딥페이크를 대상으로 forensic-style analysis를 진행했는데, 이 방법은 딥페이크를 그것의 fingerprint로 분해하는 것을 포함하기 때문에, MSU 연구진은 그 모델이 fingerprint를 다시 원래의 이미지로 mapping할 수 있는지를 분석했습니다. 그 결과, mapping이 불가능하다는 사실을 확인했습니다. 이 결과는 fingerprint가 그에 해당하는 딥페이크의 내용보다는 그 딥페이크를 생성한 생성 모델이 남긴 흔적을 주로 포함한다는 것을 뜻한다는 점에서 가치가 있습니다.
본 연구에 사용된 모든 가짜 얼굴 이미지는 MSU 연구진에서 제작되었으며, reverse engineering process에 수행된 모든 실험은 모두 MSU에 의해 수행되었습니다.
결론
제가 관련 분야에 전문적인 지식이 있는 단계가 아니기 때문에, 논문의 모든 내용을 글에 담지는 못했고, 틀린 내용도 있을지도 모르겠습니다. 하지만 ML 분야의 연구가 어떤 방식으로 진행되는지를 파악하는 정도로도 저에게 큰 의미가 있었던 논문이었습니다. 자세한 내용과 코드는 아래 링크를 참고하시면 될 것 같습니다.