Image steganography based on deep learning
Introduction
최근 딥러닝을 사용하는 분야가 넓어짐에 따라, 보안에서는 딥러닝이 어떻게 사용되고 있는지 궁금해 관련 서베이 논문을 살펴보았습니다. 해당 논문에서는 아래와 같이 GAN이 적용되고 있는 여러 분야들을 제시하고 있습니다.

굉장히 다양한 분야가 있지만, 저는 이중에서도 Image steganography에 딥러닝이 어떻게 사용되는지에 대해 관심을 가지고 선행 연구들을 조사해보았는데, 이번 글에서는 Image steganography와 End-to-end Trained CNN Encode-Decoder Networks for Image Steganography에서 제안된 비교적 간단하지만 괜찮은 성능을 보이는 모델에 대해 살펴보려고 합니다.
Image steganography
Steganography는 임의의 데이터(cover)에 다른 데이터(payload)를 은폐하는 기술을 의미합니다. 위키백과에서는 cryptography와 비교하여, cryptography는 암호문이라는 것은 알지만 그에 담긴 정보를 모르게 하는 기술이라면, steganography는 암호문인 것 자체, 내부에 정보가 있다는 사실조차 모르게 하는 기술이라고 비교하고 있습니다.
Image steganography는 image에 정보를 은폐하는 기술입니다. 다른 사람이 보았을 때는 일반적인 이미지와 다를 바가 없지만, 그 속에는 숨겨진 정보가 포함되어 있습니다.
LSB based Image steganography
Imgae steganography 중에서 가장 기본적인 방법으로는 LSB, 즉 Least Significant Bit를 변환하여 정보를 저장하는 방식이 있습니다. 예를 들어 RGB color image에서 한 pixel의 R, G, B 정보가 각각 8bit로 이루어져 0~255의 값을 가질 때, LSB 하나를 변환하면 값이 0~1 밖에 차이가 나지 않습니다. 사람의 눈으로는 이 정도의 변화를 눈치채기 쉽지 않습니다. 직접 구현을 통해서 얼마나 차이가 나는지 살펴보겠습니다.
RGB color image에 같은 크기의 grayscale image를 은폐하려고 합니다. 그럼 R, G, B 총 24 bits에 8 bits의 정보를 은폐하는 것이므로, 33% 정도의 정보를 은폐하는 것입니다. 이를 보통 8 bpp라고 하는데, bpp는 bits per pixel이라는 뜻입니다. 저는 grayscale image의 각 pixel(8 bits)을 3 bits, 3 bits, 2 bits로 나누어서 각각 RGB color image의 R, G, B의 LSB를 대체하도록 구현했습니다. 코드는 아래와 같습니다.
from PIL import Image, ImageOps
import cv2
import numpy as np
def encode_pixel(dest, src, size):
distributed = (
src >> (size[1] + size[2]),
(src >> size[2]) & (2 ** size[1] - 1),
src & (2 ** size[2] - 1),
)
return (
(dest[0] & (255 - (2 ** size[0] - 1))) + distributed[0],
(dest[1] & (255 - (2 ** size[1] - 1))) + distributed[1],
(dest[2] & (255 - (2 ** size[2] - 1))) + distributed[2],
)
def decode_pixel(pixel, size):
filterd = (
pixel[0] & (2 ** size[0] - 1),
pixel[1] & (2 ** size[1] - 1),
pixel[2] & (2 ** size[2] - 1),
)
return (filterd[0] << (size[1] + size[2])) + (filterd[1] << size[2]) + filterd[2]
class LSB_RGB:
def __init__(self, size=(3, 3, 2)):
self.size = size
self.name = f"LSB_RGB-{size[0]}-{size[1]}-{size[2]}"
def encode(self, c, p):
e_c = Image.new("RGB", c.size)
for w in range(c.size[0]):
for h in range(c.size[1]):
c_pix = c.getpixel((w, h))
p_pix = p.getpixel((w, h))
encoded_pix = encode_pixel(c_pix, p_pix, self.size)
e_c.putpixel((w, h), encoded_pix)
return e_c
def decode(self, e_c):
d_p = Image.new("L", e_c.size)
for w in range(e_c.size[0]):
for h in range(e_c.size[1]):
pix = e_c.getpixel((w, h))
decoded = decode_pixel(pix, self.size)
d_p.putpixel((w, h), decoded)
return d_p
def test(self, p, d_p):
for w in range(p.size[0]):
for h in range(p.size[1]):
p1 = p.getpixel((w, h))
p2 = d_p.getpixel((w, h))
if p1 != p2:
return False
return True
def concat_images(images, size, shape=None):
# https://gist.github.com/njanakiev/1932e0a450df6d121c05069d5f7d7d6f#file-concat_images-py
width, height = size
images = [ImageOps.fit(image, size, Image.ANTIALIAS)
for image in images]
shape = shape if shape else (1, len(images))
image_size = (width * shape[1], height * shape[0])
image = Image.new('RGB', image_size)
for row in range(shape[0]):
for col in range(shape[1]):
offset = width * col, height * row
idx = row * shape[1] + col
image.paste(images[idx], offset)
return image
# main
c = Image.open("test1.jpg").resize((300, 200))
p = Image.open("test2.jpg").resize((300, 200)).convert("L")
model = LSB_RGB()
e = model.encode(c, p)
d = model.decode(e)
print(model.test(p, d)) # True
merged=concat_images((c, p, e, d), (300, 200))
display(merged)
코드를 실행했을 때 test() 함수에서 True가 나왔기 때문에 decode된 grayscale image는 원본과 완벽히 똑같은 image라는 것을 알 수 있습니다. 아래 그림은 왼쪽부터 차례로 원본 RGB color iamge(cover), 원본 grayscale image(payload), payload가 은폐된 encoded cover image, encoded cover image로부터 decode된 payload image입니다. 원본 cover image가 무엇인지 알고 보아도 encoded cover image가 어색해보이지는 않습니다.

이 방법을 사용하면 위와 같은 image 뿐만 아니라 어떠한 데이터든 payload로 사용할 수 있다는 장점이 있지만, 고전적이고 간단하기에 쉽게 탑지가 가능합니다. 최근에도 이 방법을 개선한 다양한 연구들이 제시되고 있습니다.
End-to-end Trained CNN Encode-Decoder Networks for Image Steganography
Overview
본 논문은 2017년에 arXiv에 제출된 논문으로, image steganography를 위한 autoencoder 구조를 제안합니다. 앞으로 본 논문에서 제안한 모델을 EDS라고 명명하도록 하겠습니다.
저자가 말하는 3가지 contribution은 아래와 같습니다.
- image steganography를 위한 deep learning based encoder-decoder 구조를 제안한다.
- encoder와 decoder를 동시에 학습시키는 end-to-end training을 위한 새로운 loss function을 설계했다.
- 다양한 dataset들에 대해서 성능 평가를 진행하였고, 높은 PSNR, SSIM을 달성했다.
실제로 저자는 CIFAR10, ImageNet, PASCAL-VOC12, LFW dataset에 대해서 성능 평가를 진행하였고, EDS는 color image에 grayscale image를 은폐할 때 아래와 같은 성능을 달성했습니다.
- 원본 cover image와 encoded cover image 간 평균 PSNR = 32.9 db
- 원본 cover image와 encoded cover image 간 평균 SSIM = 0.96
- 원본 payload image와 decoded payload image 간 평균 PSNR = 36.6 db
- 원본 payload image와 decoded payload image 간 평균 SSIM = 0.96
Architecture
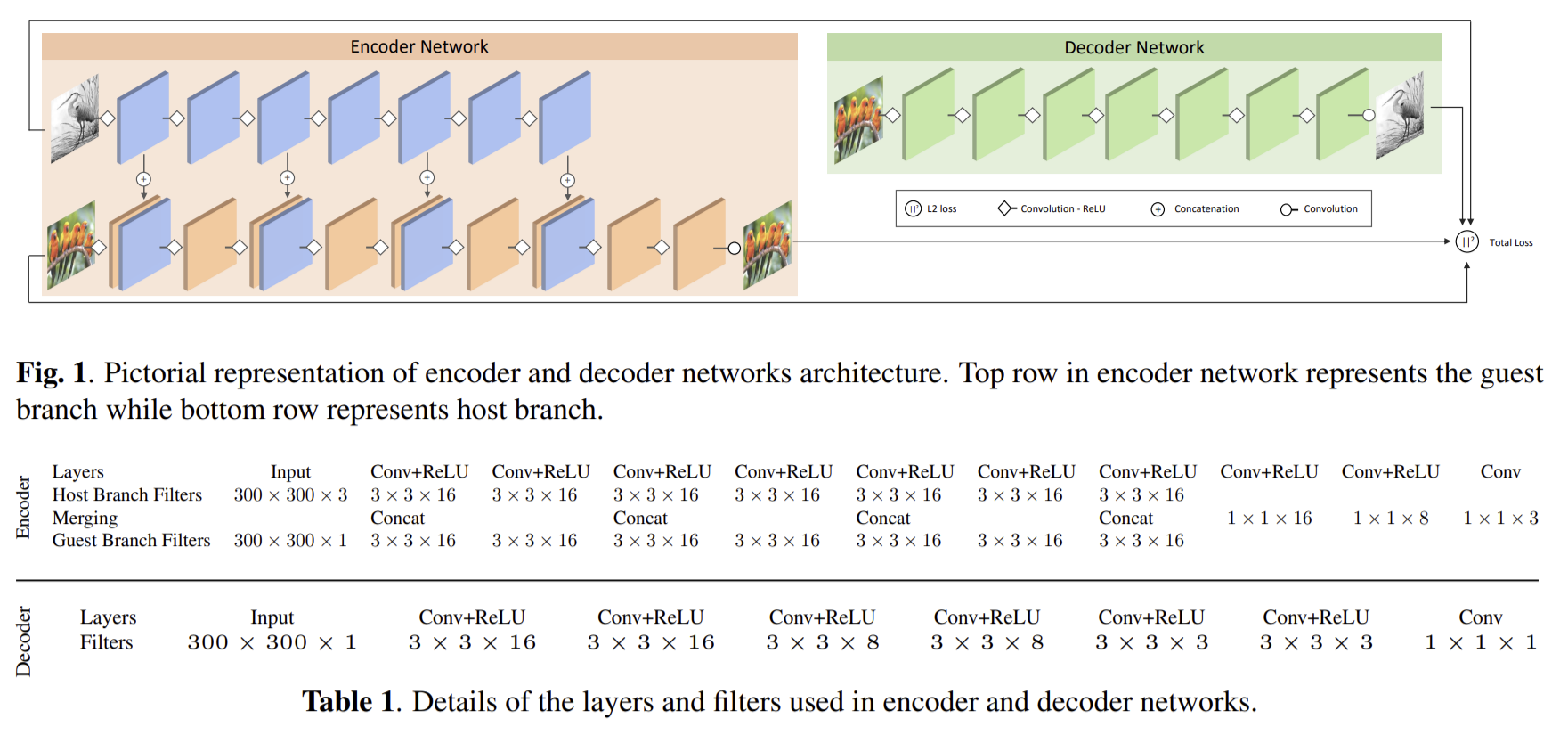
EDS의 구조는 위 사진과 같습니다. 크게 encoder와 decoder로 나누어지고, encoder는 다시 host branch와 guest branch로 나누어집니다. 전체적인 구조는 굉장히 단순하게 CNN으로 구성되어 있습니다. 다만 특이한 부분은 encoder입니다.
먼저 encoder의 guest branch는 원본 payload image를 input으로 받습니다. guest branch는 convolution layer들로 구성되어 있고 중간중간에 특정 layer들의 output이 host branch로 전달됩니다. host branch는 원본 cover image를 input으로 받습니다. 마찬가지로 convolution layer들로 구성되어 있고 중간중간에 guest branch에서 전달받은 output들이 결합됩니다.
encoder에서는 이렇게 host branch에서 guest branch로부터 몇 차례 payload image에 관한 정보들을 전달받아서 cover image에 stack함으로써 cover image에 payload image를 은폐합니다. 한 image 속에 image를 은폐한다고 했을 때, 생각할 수 있는 기본적인 구조라고도 생각됩니다. 간단하게 말하자면, cover image와 payload image를 조금씩 변환하면서 서로 합치는 과정이라고도 말할 수 있기 때문입니다.
decoder는 encoder와 반대 과정으로 생각해보면 encoded cover image를 조금씩 변환하면서 중간중간 분리를 해주는 방식으로 구현해야겠다고 생각할 수도 있는데, 분리를 해주는 과정은 convoultion layer에서 추가적으로 구현해줄 필요가 없으므로 단순하게 convolution layer들로 구성되어 있습니다.
Loss function
EDS에서는 encoder와 decoder를 동시에 학습하며, 3가지 loss function을 사용합니다.
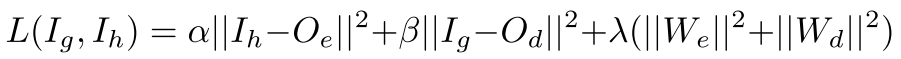
첫 번째 항은 encoder loss입니다. $I_h$는 input host, 즉 원본 cover image를 나타내고, $O_e$는 encoded cover image를 나타냅니다. 따라서 단순히 원본 cover image와 encoded cover image의 차이가 작도록 학습시키는 항입니다.
두 번째 항은 decoder loss입니다. $I_g$는 input guest, 즉 원본 payload image를 나타내고, $O_d$는 decoded payload image를 나타냅니다. 따라서 encoder loss와 유사하게, 원본 payload image와 decoded payload image의 차이가 작도록 학습시키는 항입니다.
세 번째 항은 network의 weight의 크기를 의미합니다. $W_e$는 encoder의 weight, $W_d$는 decoder의 weight를 나타냅니다. 짧은 식견으로 예상하자면, 임의의 한 convolution layer에서 image가 크게 변환되지 않고, 약간의 변화만을 주도록 학습시키기 위해서 필요한 항이 아닐까 생각합니다. (이는 L2 regularization으로 overfitting을 방지하기 위함입니다.)
Evaluation
1차
- Xavier initialization
- Adam optimizer (learning rate = 1e-4)
- batch size = 32
- $\alpha$ =1
- $\beta$ =1
- $\lambda$ = 0.0001
- image size = 32 * 32
저자는 위와 같은 parameter로 학습을 진행하였고, 그 결과는 아래와 같습니다.
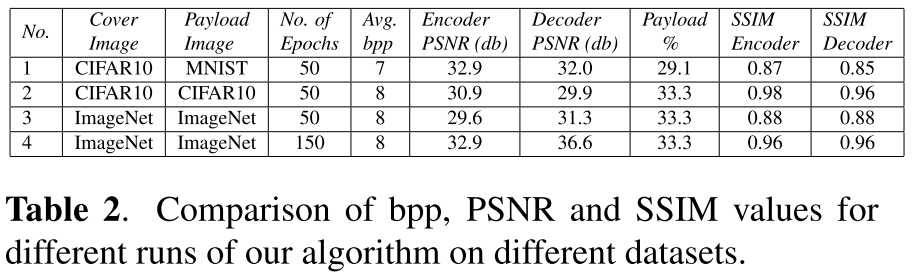
50 epochs만큼 학습을 진행하여도 충분히 높은 성능을 달성하였음을 알 수 있습니다.
2차
저자는 위 1차 실험에서 ImageNet을 150 epochs만큼 학습한 모델을 사용해서 300*300 크기의 이미지들에 대해서 다시 실험을 진행하였고, 그 결과는 아래와 같습니다.
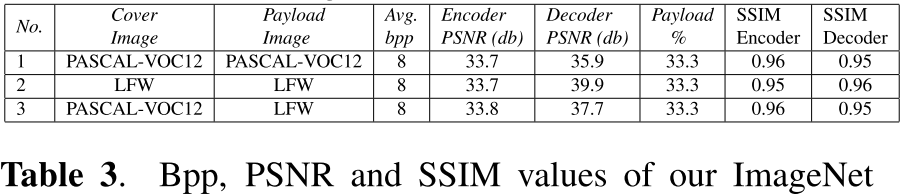
학습한 데이터와 다른 데이터로 실험을 진행했음에도 유사한 결과가 나왔음을 알 수 있습니다. 이로써 다양한 크기와 종류의 이미지에 대해서도 동일하게 학습된 모델을 사용할 수 있다는 것을 확인했고 높은 일반화를 가진다고 결론내릴 수 있습니다.
구현
논문에 있는 내용을 바탕으로 EDS를 구현해보았습니다. (구현 후 Papers With Code라는 사이트에도 올려보았는데, 오픈 소스를 찾고 공유하는데 좋은 사이트인 것 같습니다.)
논문에서와 같이 CIFAR10, ImageNet과 함께 CelebA에 대해서도 실험을 진행해보았고, 그 결과는 아래와 같습니다.
| Model (dataset) | PSNR (Encoder) | PSNR (Decoder) | SSIM (Encoder) | SSIM (Decoder) |
|---|---|---|---|---|
| CIFAR10 | 32.44 | 41.84 | 0.97 | 0.99 |
| CelebA | 33.00 | 41.37 | 0.97 | 0.99 |
| ImageNet | 28.57 | 38.33 | 0.94 | 0.99 |
저는 논문에서와 다르게 64 * 64 이미지를 사용하였고, 모든 dataset에 대해 150 epochs동안 학습을 진행하였습니다. 이와 같은 차이에 의해 실험의 결과가 다르기는 하지만, 유사한 결과가 도출되었습니다. 아래는 제가 학습한 모델로 출력한 이미지들입니다. 왼쪽부터 차례로 원본 cover iamge, 원본 payload image, encoded cover image, decoded payload image입니다.
-
CIFAR10


-
CelebA


-
ImageNet


Conclusion
위 제가 구현한 모델로 출력한 이미지를 보면 원본 cover image와 payload를 포함하고 있는 encoded cover image의 색이 약간 다른 것을 확인할 수 있습니다. 그렇다고 encoded cover image의 색이 어색하지는 않지만 상황에 따라 어색한 색으로 변환될 수도 있을 것입니다. 이러한 문제는 다른 논문들에서도 지적된 문제입니다. 예를 들어 Invisible Steganography via Generative Adversarial Networks에서는 RGB 이미지를 YCC color model로 변환하여 색을 나타내는 정보를 제외한 다른 정보에만 payload를 은폐하는 방식으로 이 문제를 해결하였습니다.
Image steganography에 대해 공부를 해보면서, 이 방식이 이미지 압축과 매우 유사하다고 생각했습니다. 한정된 크기의 파일에서 원본을 압축하여 빈 공간을 만들고, 그 자리에 payload를 저장하는 방식이라고도 볼 수 있기 때문입니다. 다만, image steganography에서는 압축할 정보, 압축 정도, 빈 공간의 위치 등을 잘 조율해서 원본 파일을 가시적으로 해치지 않도록 하는 과정이 필수적이긴 합니다. 이러한 관점에서, autoencoder 등 딥러닝을 이용해서 파일을 압축하는 방식을 제안하는 연구들이 많이 나와있는 것으로 알고 있는데, 그 분야에서 사용되는 아이디어를 image steganography에도 적용하면 성능 향상을 기대해볼 수 있지 않을까 합니다.