SALIENCYMIX: A SALIENCY GUIDED DATA AUGMENTATION STRATEGY FOR BETTER REGULARIZATION
SALIENCYMIX: A SALIENCY GUIDED DATA AUGMENTATION STRATEGY FOR BETTER REGULARIZATION
최근에 Data Augmentation 기법과 관련한 논문들을 읽을 일들이 있었습니다. 관련 자료들을 찾다가 saliency map을 이용하여 cutmix와 조합한 saliencymix에 대한 논문을 접했고 해당 논문의 기법을 사용할 일이 있었습니다. 그 내용이 상당히 쉽고 직관적이며 구현 및 사용에도 큰 어려움이 없어 꽤나 유용한데 반해, 이를 번역한 자료가 없는 것 같아 이참에 한글로 정리해보려 합니다.
ICLR 2021 논문인 SaliencyMix는, 기본적으로 CutMix를 기반으로 하고 있습니다. 기존의 CutMix가 가지고 있던 한계점을 saliency detection을 통해 해결하는 방법을 제안하고 있으며, 실제로 CutMix보다 항상 더 나은 결과를 보이게 됩니다. 논문에서 사용된 기법을 읽어보면, 해당 논문이 직관적으로 CutMix가 가지고 있던 한계점을 극복하며, 평균적으로 더 나은 결과를 낼 수 있다는 결론을 이해하기 쉽습니다.
SaliencyMix의 설명에 앞서, 쉬운 이해를 위해 간단히 cutmix에 대해 설명하도록 하겠습니다.
CutMix (2019)
ICCV 2019 논문인 CutMix는 image data augmentation 분야에서 당시 굉장히 강력하여 augmentation 분야에 엄청난 바람을 불었던 논문입니다. 그 아이디어와 구현 난이도의 간단함에 비해 굉장한 성능의 향상을 보여 당시에 가장 뜨거웠던 Mixup (2017)과 Cutout (2017)을 제치고 굉장히 좋은 data augmentation 성능을 보였습니다. 놀랍게도 그 아이디어는 mixup과 cutout이 가지고 있던 아이디어에서 간단한 변형을 준 것이어서 사람들이 쉽게 이해하고 적용할 수 있었습니다.
CutMix는 augmentation 과정에서 랜덤하게 선택된 두 개의 이미지를 섞으려는 시도에서 시작합니다.
Mixup
Mixup의 경우, 랜덤으로 선택된 두 개의 이미지를 beta distribution에 따라 선택된 비율 $\lambda$ 에 따라 두 이미지를 $\lambda$ 와 $(1-\lambda)$ 만큼 pixel-wise하게 섞어 새로운 이미지를 만들어 냅니다. 이렇게 만들어진 이미지의 라벨은 기존의 하나의 이미지의 라벨을 갖는 것이 아닌, 사용된 두 개의 이미지의 라벨을 해당 비율만큼 가지게 됩니다. 이렇게 만들어진 이미지는 모델이 training data들 사이의 linear behavior를 가지게 해주어 overfitting과 adversarial data에 대한 robustness를 가지게 된다는 장점이 있습니다.

Cutout
Cutout의 경우는 두 개의 이미지를 사용하는 기법은 아닙니다. 많은 기존의 data augmentation 기법들처럼 기존에 존재하는 training data에 변형을 주는 방식으로 새로운 data를 만들어내게 됩니다. 그 아이디어는 상당히 간단한데, 바로 기존에 존재하는 이미지의 특정 영역을 아예 제거해버리는 방법으로 새로운 이미지를 만들어내게 됩니다. 주어진 영역 중 어떤 영역을 선택하고 어떤 모양으로 선택하여 제거할 것인가는 논문에 여러 다양한 방법이 나와 있어 확인해보실 수 있습니다(결과적으로는 ‘영역의 크기’ 이외에는 결과에 큰 차이가 없기는 합니다). Cutout이 가지는 의미는 이를 사용하여 학습을 진행한 모델의 activation 영역이 커진다는 점입니다. 즉, 주어진 이미지에서 라벨을 분류하기 위해 이미지에서 더 많은 feature들을 찾아내고 이를 사용하게 된다는 것입니다. 이는 cutout을 해석하는 과정에서 가장 크게 영향을 미치는 점입니다. mixup을 포함하여 최근에 많이 연구되는 data augmentation들이 많이 개선을 목표로 했던 점은 바로 모델이 이미지의 특정 영역, 즉, 가장 영향을 크게 미치는 feature에 집중하여 학습을 진행한다는 점이었습니다. 학습하는 과정에서 중요한 feature들에 집중하여 이를 학습하게 되는 경향이 있는데, 이는 조금 덜 중요한 feature들의 경우 덜 집중되거나 무시되는 경향을 만들어내고 결국 주어진 training data에 overfit하게 되며 robustness가 떨어지는 결과를 낳게 됩니다.
이 과정에서 cutout은 주어진 이미지의 특정 영역을 제거하여, 해당 영역이 가지고 있던 feature를 이미지 상에서 제거하는 역할을 하게 됩니다. 즉, 이 과정에서 모델이 집중하던 feature가 이미지에서 제거되었다면, 나머지 영역들에 있는 feature들에 집중하는 역할을 하게 되며, 이 과정에서 기존 이미지에서는 집중하지 않았던 feature들을 찾아 모델이 학습할 수 있는 결과를 낳게 되어 성능의 향상을 만들어 냅니다.

CutMix
CutMix는 Cutout을 기반으로 두고 있습니다. 기존의 Cutout의 경우, 특별한 이미지 영역을 선택하고 제거하기 때문에, 그 과정에서 해당 영역은 아예 아무런 정보가 없게 되어 정보의 손실을 일으키게 됩니다. 이를 해결하기 위해 cutout으로 제거한 영역을 training data의 또 다른 이미지 하나를 선택하고, 해당 영역만큼 다른 이미지의 영역으로 대체하여 2개의 이미지를 섞으려는 시도가 바로 CutMix 기법입니다. 이렇게 만들어진 새로운 이미지의 경우, 합쳐진 이미지에서 각각의 원본의 이미지가 차지하고 있는 영역의 크기의 비에 해당하는 값을 라벨로 가지게 됩니다. 즉, 7:3의 비율로 a와 b 이미지를 cutmix를 통해 섞게 되었다면, 해당 이미지는 0.7a + 0.3b 만큼의 각각의 이미지 라벨을 가지게 됩니다.
기존의 mixup의 경우, 두 이미지를 $\lambda$ 비율로 섞는 과정에서 원본 이미지의 객체가 다른 이미지로 덮이면서 실제 이미지의 왜곡이 일어나는 경우가 발생하게 되는 문제점이 있었습니다. 그러나 CutMix의 경우, 각각의 이미지가 존재하는 영역은 다른 이미지의 간섭을 받지 않기 때문에 각 이미지의 객체가 가지는 정보를 그대로 유지할 수 있게 됩니다.
실제로 cutmix를 통해 생성된 이미지에서 각각의 이미지의 object를 잘 확인할 수 있는지 확인하기 위해 CAM(Class Activation Map)을 통해 확인할 때에, 섞인 이미지의 각각의 영역에서 object를 상당히 잘 구분해낸다는 것을 알 수 있습니다. 이 과정에서 모델은 각각의 object에 해당하는 feature에서 자기가 속한 이미지에서 제외된 영역만큼의 feature가 제거된 이미지가 되고, 이 과정은 해당 영역만큼 제거된 다른 영역들의 feature 집중할 수 있도록 하는 역할을 하게 됩니다.

Cutmix는 여러가지 benchmark dataset들에 대해서 기존의 mixup과 cutout보다 더 나은 결과를 보이며 좋은 성능을 내는 data augmentation 기법이 되었습니다.
SaliencyMix (2020)
SaliencyMix는 이러한 CutMix를 기반으로 하고 있습니다. Saliencymix는 Cutmix가 가지고 있는 단점을 saliency map을 사용해서 해결하려는 노력에서부터 시작합니다.
기존의 cutmix의 경우, 두 개의 이미지를 특정 영역을 선택하여 선택하여 섞는 과정을 통해 만들어지는 이미지에서, cutout된 영역은 다른 이미지에서 해당 cutout된 영역이 차지하고 있던 영역을 그대로 복사하여 가지고 오게 됩니다. 이러다 보니, 다음과 같은 문제가 발생하게 됩니다.
- 선택된 영역을 채우는 이미지에 객체가 존재하지 않는 경우에도, 새롭게 생성된 이미지의 라벨은 영역의 비 만큼의 각 이미지의 라벨을 가지게 된다.
앞선 CutMix에 사용된 이미지를 살펴보도록 하겠습니다.
해당 이미지는 고양이외 배를 섞은 이미지가 되지만, 실제 cutmix를 통해 합성되는 이미지에서 배가 차지하는 영역은 해당 영역의 크기보다 훨씬 더 작다는 것을 알 수 있습니다. 이보다 더한 경우, 만약 cutmix를 진행하는 과정에서 이미지 라벨에 해당하는 객체가 선택되지 않고 배경만 합성된다면, 이렇게 생성된 이미지가 올바른 라벨을 가지게 되는지에 대한 의문에서 부터 SaliencyMix는 시작하게 됩니다.
SaliencyMix는 cutmix를 적용하는 과정에서, source image에서 특정 영역을 복사하여 target image에 붙여넣는 과정에서, source image 내에 object가 존재할 가능성이 높은 영역을 선택하여 이를 target image에 붙여넣어 이러한 문제를 해결하려 시도합니다. 이에 만약 해당 과정이 잘 이루어지게 된다면, 아래와 같이 고양이와 배를 mix하는 과정에서 배 object 영역을 잘 찾아내어 고양이 이미지에 붙여넣을 수 있습니다.

Saliency Map
앞서 saliencymix의 목표를 이루기 위해서, 우리는 특정 이미지 내에서 실제 label에 해당하는 object가 어디에 있는지 찾아내는 것이 중요합니다. 하지만 만약 우리가 특정 label에 해당하는 object가 어디에 있는지 알아낼 수 있다면 쉽겠지만 실제로는 그렇게 쉽지 않습니다. 왜냐하면 이 문제를 해결하는 것 자체가 바로 image segmentation이 되기 때문입니다. Image classfication을 위해 이보다 더 어려운 image segmentation을 사용하는 것은 쉽지 않은 일이 됩니다.
그래서 saliencymix에서는 이와 유사한 방법을 적용하기 위해 saliency map을 사용하게 됩니다.
saliency map이란 물체에서 시각적으로 중요한 영역, 객체에 해당하는 지점들을 찾아서 어떠한 영역들이 시각적으로 중요한 영향을 미치는지 확인하기 위해서 도입된 아이디어입니다. 이미지를 확인하는 과정에서, 사람은 모든 픽셀들을 확인하는 것이 아닌, 이미지에서 중요한 영역들을 찾아서 먼저 확인하게 됩니다. 이처럼, saliency map은 이미지에서 중요한 영역들이 무엇인지를 각각의 pixel들에 대해 score를 매겨 이를 visualize 하여 보여줍니다.

이러한 Saliency Map을 구하는 방법은 크게 두 가지가 존재합니다. 바로 Bottom-up approach와 Top-down approch입니다. 각각에 대해 간단히 설명 하고 진행하도록 하겠습니다.
Bottom-up approch의 경우, saliency map을 구하기 위해 고전적으로 사용해오던 unsupervised한 approch입니다. 특정 이미지에서 어떠한 영역이 중요한 영역인지 판단하는 과정을 다른 영역에 비해 pixel 값이 급격하게 변화가 일어나는 위치(밝기, 색상의 변경, 대비의 발생 등)를 찾고 이들을 사용하여 mapping을 진행하게 됩니다. 즉, 이를 위해서 해당 이미지가 어떠한 이미지인지, 어떠한 object를 포함하고 있는지에 대한 정보가 필요없이, 고전적인 계산 기법들을 통해 각 이미지 pixel들의 saliency score를 계산하여 구하게 됩니다. 이로 인해 이미지의 종류에 상관없이 사용할 수 있으며 이미지의 크기 등에 대해서도 robust한 결과를 보입니다.
Top-down approach의 경우, 실제 label을 가진 training data를 통해 neural network를 학습시켜서 만들어내는 supervised-learning을 사용합니다. saliency detection에 대한 task를 해결하는 model을 만들어, 해당 NN을 이미 label이 분류되어 있는 dataset을 통해 학습을 진행합니다. 이렇게 만들어진 model의 경우, 특정 이미지에서 이미 학습을 진행했던 label에 대한 saliency detection을 model의 정확도만큼 잘 수행할 수 있게 됩니다. supervised-learning을 통해 학습 통해 pre-trained 된 model을 사용하기 때문에 기존의 bottom-up approach에 비해 성능이 더 좋은 경우가 많습니다.
Saliencymix에서는 이러한 두 가지 중 bottom-up approach를 사용합니다. Top-down approach의 경우 특정 label들에 대해 학습을 진행해야 하기 때문에, 학습하는 과정에서 사용한 dataset에 대해 더 biased 된 경향을 보일 수 있어, 해당 논문에서는 label에 대한 정보를 알 수 없는 unseen image들에 대해서도 보편적으로 generalize하게 사용할 수 있는 bottom-up approch를 사용합니다.
실제로 해당 논문에서는 OpenCV의 cv2에 내장되어있는 saliency map을 구하는 함수(cv2.saliency)를 통해 saliency map을 구합니다.
(물론 해당 논문에서 bottom-up approch를 사용한 것이지, top-down approch를 통해 saliency map을 구하는 경우도 있습니다. 이에 대한 예시로 puzzlemix (2020)가 있습니다)
BBox(Bounding Box)
SaliencyMix는 이렇게 source image에 대한 saliency map을 구하고, 여기에서 bbox를 찾아내어 해당 영역을 target image에 붙여넣는 방식으로 mix를 진행합니다. 이 때, bbox를 구하는 방법은 saliency map에서 가장 큰 interest score를 가진 pixel의 위치를 구한 이후, 해당 위치를 중심으로 하는 특정 크기의 정사각형 영역을 선택하는 방식으로 구하게 됩니다.
bbox의 크기를 선택하는 과정은 beta distribution에 따르는 특정한 랜덤 값 $\lambda$ 에 대해 다음과 같이 구하게 됩니다.
- cut_W = sqrt(1 - $\lambda$) * W
- cut_H = sqrt(1 - $\lambda$) * H
beta distribution에 사용하는 beta는 사용자가 직접 넣는 hyper parameter에 의해 결정됩니다.
이렇게 구한 bbox가 실제 이미지의 크기 범위 밖으로 벗어나는 경우, 벗어난 영역만큼 반대로 bbox를 밀어서 이미지 영역을 선택하게 됩니다. (해당 과정은 saliencymix code를 읽어보시면 수월하게 이해할 수 있습니다)
Experiment Result
해당 논문에서는 이렇게 만들어진 saliency mix를 다양한 computer vision task에 적용하여 결과의 향상을 확인하였습니다.
Image Classification
Image classification의 경우, Resnet, WideResNet에 해당하는 model들을 사용하여 학습을 진행하여 CIFAR-10, CIFAR-100, ImageNet 등의 image classfication을 위한 benchmark dataset들을 통해 top-1, top-5 error를 확인하였습니다.
본 포스팅에서는 대략적인 경향과 결과에 대한 설명을 진행할 예정이며, 실험에 사용된 자세한 셋팅 조건은 논문을 참고해주시면 되겠습니다.
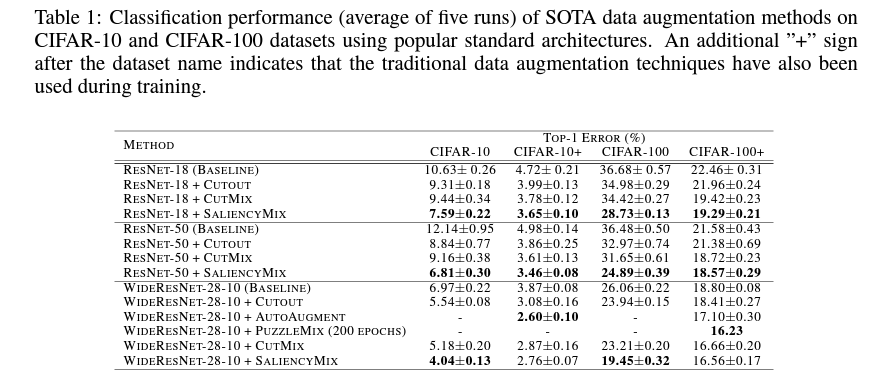
위 테이블에서 확인할 수 있듯, CIFAR image dataset에서 saliency mix는 실제로 기존의 cutout과 cutmix에 비해서 더욱 개선된 top-1 error를 보임을 확인할 수 있습니다.
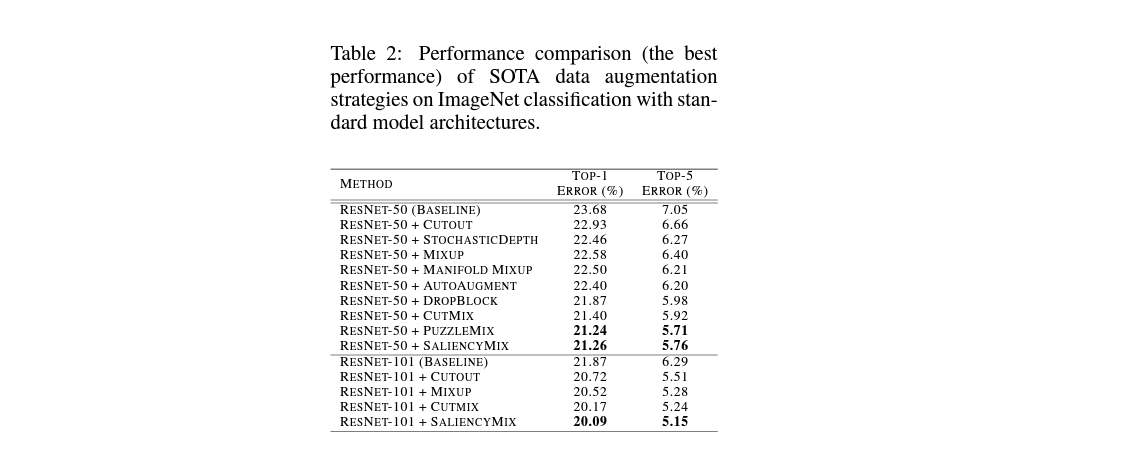
또한 ImageNet에서도 saliency mix는 cutout, mixup, cutmix보다도 더 개선된 top-1, top-5 error를 보인다는 것을 확인할 수 있습니다.
Object Detection
Object detection의 경우, ResNet-50을 backbone으로 사용하는 Faster RCNN을 기반으로 실험을 진행하며, benchmark dataset으로 Pascal VOC 2007과 2012 dataset을 사용합니다.
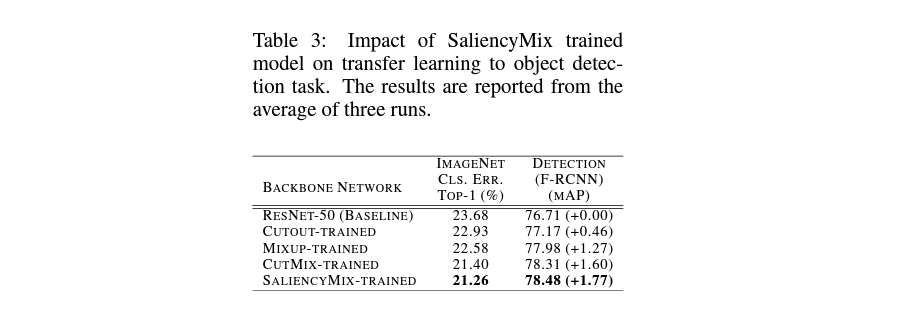
위 테이블에서 확인할 수 있듯, saliencymix는 mixup, cutout, cutmix보다 더 높은 성능을 보였습니다.
Adversarial Attack
Adversarial Attack에 대해 간단히 설명하면, image에 의도적인 손상을 가해 model이 제대로 image classification을 진행하지 못하게 만드는 공격을 이야기합니다. 사람이 보았을 때에도 이미지에 변화가 생긴 것으로 인식하는 attack 뿐만 아니라, image를 사람이 육안으로 보았을 때에는 아무런 변화가 없음에도 불구하고 각각의 pixel에 해당하는 data에는 심각한 손상이 일어나서 model의 입장에서는 기존에 training data로 사용되던 image에 비해 엄청나게 큰 변동이 일어난 상태로 만드는 adversarial attack등도 존재합니다.
해당 실험의 경우, Resnet을 model로 사용하여 FGSM (2014) 을 사용하여 ImageNet에 adversarial attack을 적용한 validataion dataset을 통해 실험을 진행하였습니다.

실제 위 테이블에서 확인할 수 있듯, saliencymix는 cutout, mixup, cutmix에 비해 adversarial attack에 대한 robustness가 향상되었음을 확인할 수 있습니다.
Training Time
모델이 train을 진행하는 과정에서, 그 소요시간이 얼마나 단축되는 가는 model training에서 굉장히 중요한 요소입니다. 이를 위해 training data를 사용해 새로운 image를 생성하는 data augmentation 과정 또한, 소요 시간이 train time에 영향을 주기에 얼마나 빠르게 동작하는지가 중요합니다.
이를 측정하기 위해 논문에서는 Resnet을 architecture로 사용하고 CIFAR-10을 학습하는데 걸리는 시간을 측정하여 saliencymix의 training time을 측정하였습니다.

그 결과, saliencymix의 경우 source image에 대해 saliency map을 추출하는 과정이 추가되어 다른 data augmentation에 비해서는 소폭의 training time이 더 필요했다는 것을 확인할 수 있습니다.
CAM Analysis
결과의 향상을 visualization을 통해서 확인하기 위해, 논문에서는 saliency mix 및 여러가지 data augmentation 기법들에 대해 CAM을 통해서 모델이 주어진 이미지에서 특정 label에 해당하는 object를 찾기 위해 어떠한 feature들에 대한 activation이 높게 나타났는지 CAM을 통해 확인하였습니다.

주어진 이미지의 왼쪽을 보면 각각의 label에 대해 어떠한 pixel들이 높은 activation을 나타냈는지 확인할 수 있습니다. 각각 tent, marmot, vizsla의 image들에 대해 saliencymix가 다른 data augmentation이나 baseline에 비해 실제 사람이 육안으로 확인하는 object에 더욱 가까운 영역에 높은 activation을 보였다는 것을 확인할 수 있습니다.
또한 오른쪽 이미지를 확인하면, mixup, cutout, cutmix에 비해 saliencymix의 경우 augmented image에서 각각의 label에 해당하는 object가 image 내에 잘 남아있어 해당 label의 feature들에 더 높고 정교하게 activation map이 나타난다는 것을 확인할 수 있습니다.
마치며
Mixup과 Cutmix는 image data augmentation에서 뜨거운 감자였던 획기적인 논문이었습니다. 그리고 Saliency Mix는 cutmix를 개선하기 위해 간단한 아이디어를 적용하여 성능의 향상을 이루어냈습니다.
물론 현재에는 Co-mixup (2021)을 비롯한 다양한 data augmentation 기법들이 새롭게 등장하면서 saliency mix의 성능이 가장 좋다고 이야기할 수는 없지만, 사용방법이 간단하고 코드가 굉장히 짧다는 장점이 있어, data augmentation을 사용할 일이 있다면 사용해볼만한 논문입니다.