Optuna: hyperparameter optimization
Introduction
딥러닝 모델을 구현함에 있어서 hyperparameter를 결정하는 것은 어려운 문제입니다. 일반적으로 hyperparameter를 결정하기 위해서는 hyperparameter에 대한 여러 번의 실험을 진행합니다. 실험을 진행하는 가장 간단한 방법은 실험을 할 때마다 코드의 hyperparameter들을 직접 변경하는 방법이 있습니다. 이 방법을 사용할 경우 새로운 실험을 진행할 때마다 코드가 변경되기 때문에 버전 관리도 쉽지 않고, 매번 코드를 수정하는 것이 번거롭다는 단점이 있습니다. 이보다 약간 개선된 방법은 command line argument로 hyperparameter를 설정하는 방법이 있습니다. 이 방법을 사용할 경우에는 새로운 실험을 진행할 때마다 코드가 변경되지 않는다는 큰 장점이 있습니다. 각 실험을 구분할 때도 해당 실험에 대한 command line만 관리하면 되기 때문에 hyperparameter를 직접 변경하는 방법보다는 실험을 더 쉽게 관리할 수 있습니다.
하지만 command line arqument를 이용하는 것 역시 충분히 효율적인 방법이 아닙니다. 이 경우에도 hyperparameter의 수가 많다면 해야 할 실험의 양이 많고, 그를 직접 수행하기에는 어렵습니다. 또한 어떤 값으로 실험을 진행해야하는지, 최적의 성능으로 수렴하고 있는지, 각 hyperparameter 간의 연관성이 있느지, 각 hyperparameter가 성능에 얼마나 영향을 미치는지 등의 문제에 대한 답을 찾는 것은 여전히 어려운 문제이며, 이로 인해 최적의 hyperparameter를 찾는데 오랜 시간이 걸릴 것입니다.
이러한 문제를 해결하기 위해 사용할 수 있는 많은 도구들이 개발되어왔고 현재에도 유망한 분야로 연구가 지속되고 있습니다. 현재는 hyperparameter 탐색을 위해 Hyperopt, Tune, Hypersearch, Skorch, BoTorch, HiPlot, Optuna 등의 도구를 사용할 수 있으며, 이번 글에서는 가장 범용적으로 사용되는 Optuna를 어떻게 사용하는지에 대해 알아보고자 합니다.
Optuna
Optuna는 일본의 Prefered Networks 사에서 개발되었습니다. 논문을 보면 Optuna에 대해 자세히 알 수 있습니다. Optuna는 hyperparameter를 결정하기 위해 주로 사용되는 framework로 홈페이지에는 아래와 같이 소개되어 있습니다.
Optuna를 아주 간략하게 설명하면 단순하게 여러 hyperparameter에 대해서 자동으로 실험을 수행해주는 도구인데 각 실험을 trial이라고 부릅니다. Optuna는 sampler로 각 hyperparameter의 값을 선택하고, 해당 조건에서 실험(trial)을 수행한 다음, 해당 방향으로의 조정을 계속하는 것이 좋은지를 prunor로 판단하여 최적에 수렴하지 않는다고 판단되면 해당 trial을 prune하고 다른 방향으로 다시 trial을 수행하는 방식으로 동작합니다.
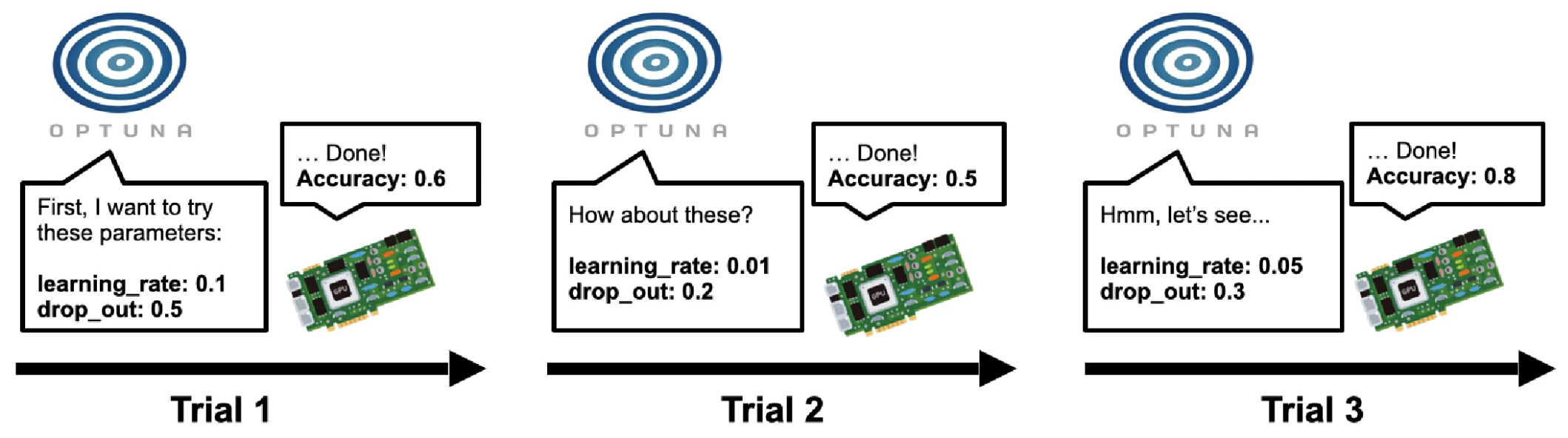
Optuna가 주로 사용되는 이유는 아래와 같습니다.
- PyTorch, TensorFlow, Keras 등 여러 machine learning framework와 함께 사용될 수 있습니다.
- search space와 objective를 하나의 함수에 정의할 수 있습니다.
- 이후에 알아볼 것이지만, trial이라는 object를 이용해서 각 hyperparameter와 그 search space를 쉽게 sample할 수 있습니다.
- 다양한 optimization 방법들을 제공합니다.
- 다른 optimization 도구들을 optuna에서 사용할 수 있습니다.
- https://optuna.readthedocs.io/en/stable/reference/integration.html
- 다른 도구들보다 시각화가 잘 구현되어 있습니다.
- open source이며 무엇보다 docs가 잘되어 있습니다.
Samplers: where to look
아무래도 hyperparameter optimization에서 가장 중요한 부분은 어떤 값으로 실험을 진행해서 최적의 hyperparameter를 빠르고 정확하게 찾는가에 관한 것일 것입니다. 따라서 hyperparameter의 값을 sample하는 알고리즘은 hyperparameter optimization에서 가장 중요한 요소 중 하나입니다.
Optuna에서 sampler가 어떻게 동작하는지에 관해서는 docs에 상세히 설명되어 있으므로, 자세한 설명은 생략하도록 하겠습니다. Optuna에서 제공하는 sampler는 docs에서 확인할 수 있고, 더불어 integration을 이용해서 다른 framework의 sampler 알고리즘을 사용할 수도 있습니다.
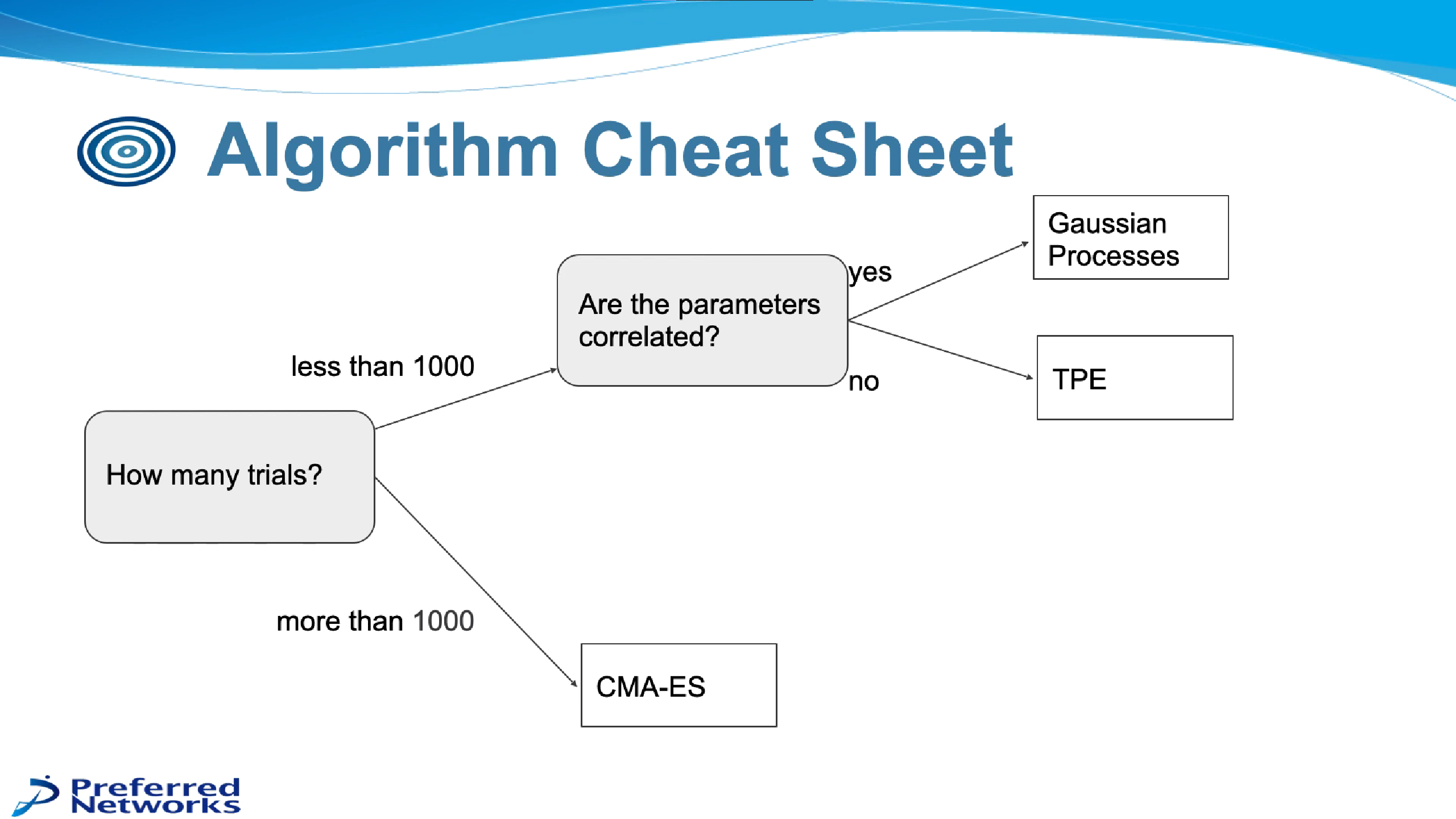
sampler는 크게 model-based와 아닌 것으로 구분이 가능합니다. model-based 알고리즘으로는 주로 GP(Gaussian Processes), TPE(Tree-structured Parzen Estimator), CMA-ES(Covariance Matrix Adaptation Evolution Strategy) 등이 있고, 그 외에는 Random Search, Grid Search 등이 있습니다.
Optuna에서는 아래 조건에 따라 sampler 알고리즘을 선택하는 것이 좋다고 제안하고 있습니다.
Prunors: stopping trials early
sampler와 함께 hyperparameter optimization의 중요한 요소 중 하나인 prunor는 국문으로는 가지를 치는 것을 의미합니다. 즉 prunor 알고리즘에 따라서 얼마나 빨리 최적의 상태에 도달하는지가 결정됩니다. 아래 그림을 보면 prunor가 어떤 역할을 하는지 바로 이해할 수 있습니다.
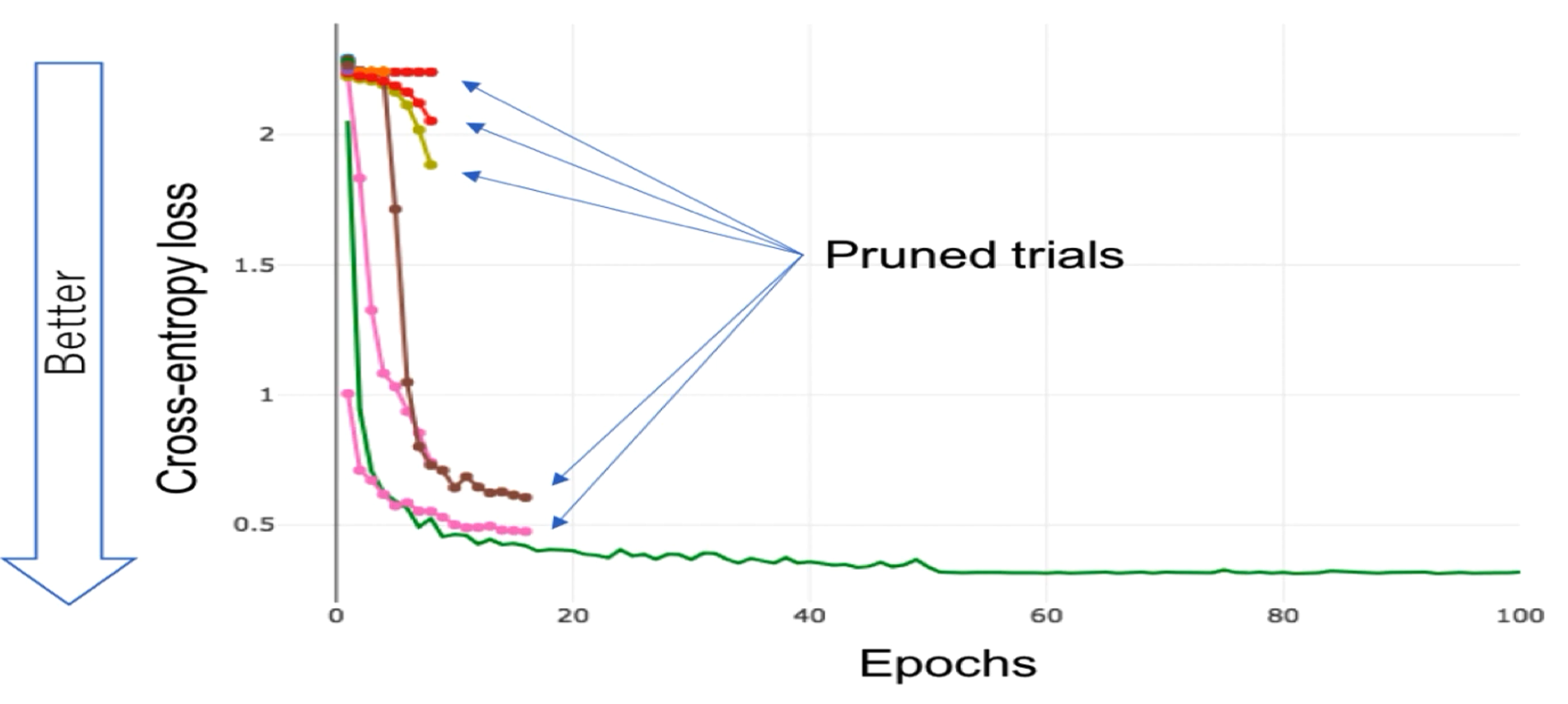
예시로 pruning 성능에 따라서 최적의 상태에 도달하는 시간이 확연하게 차이가 난다는 것을 확인할 수 있습니다.
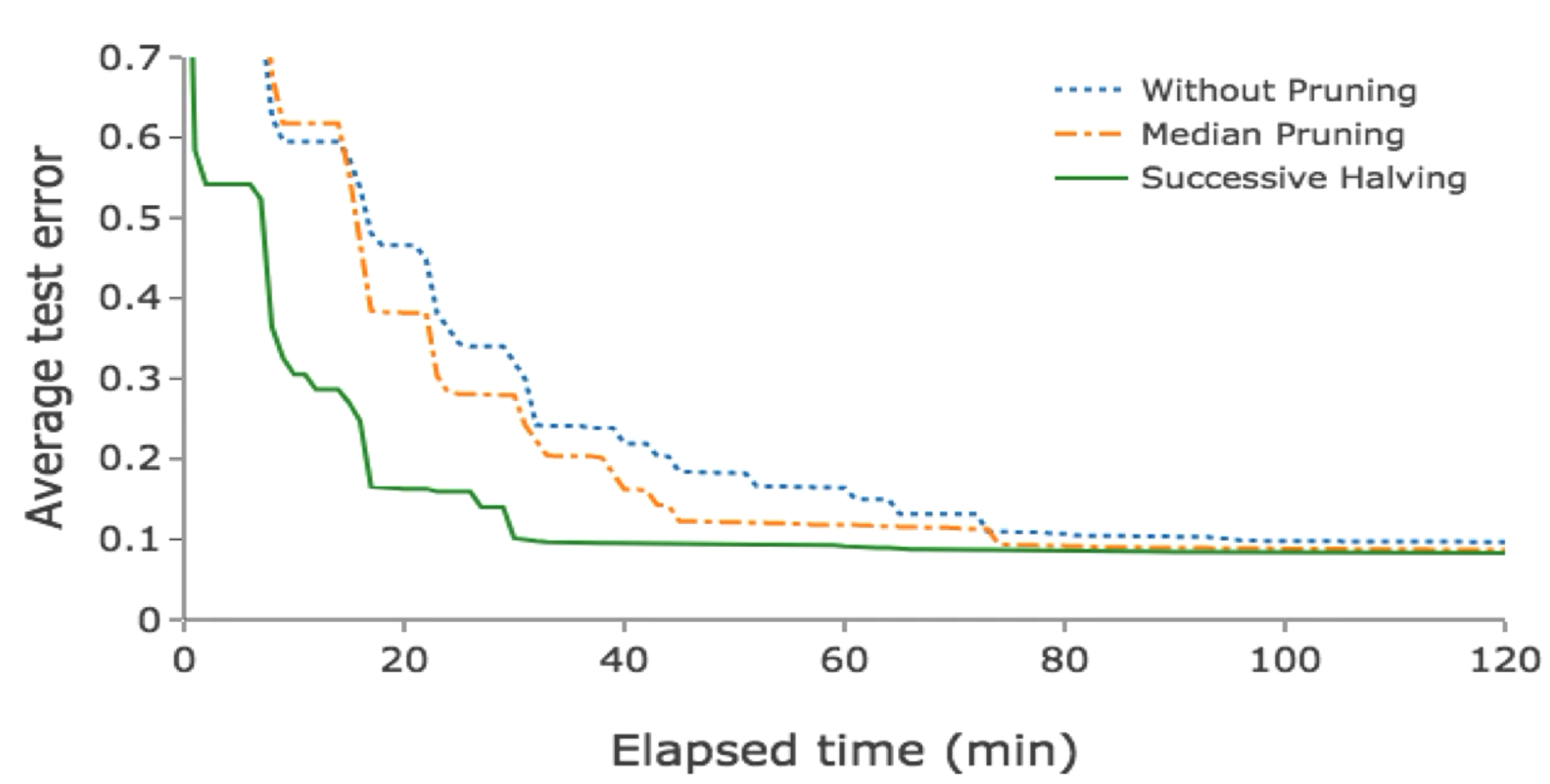
구현
그럼 직접 Optuna를 사용해서 hyperparameter optimization을 수행해보겠습니다. 문제 상황은 사람의 얼굴 사진을 보고 그 사람의 나이대를 예측하는 것으로 설정했습니다. dataset은 kaggle에 공개된 dataset을 활용하였습니다. framework는 pytorch를 사용하였고 사용한 code는 github에서 확인할 수 있습니다.
dataset
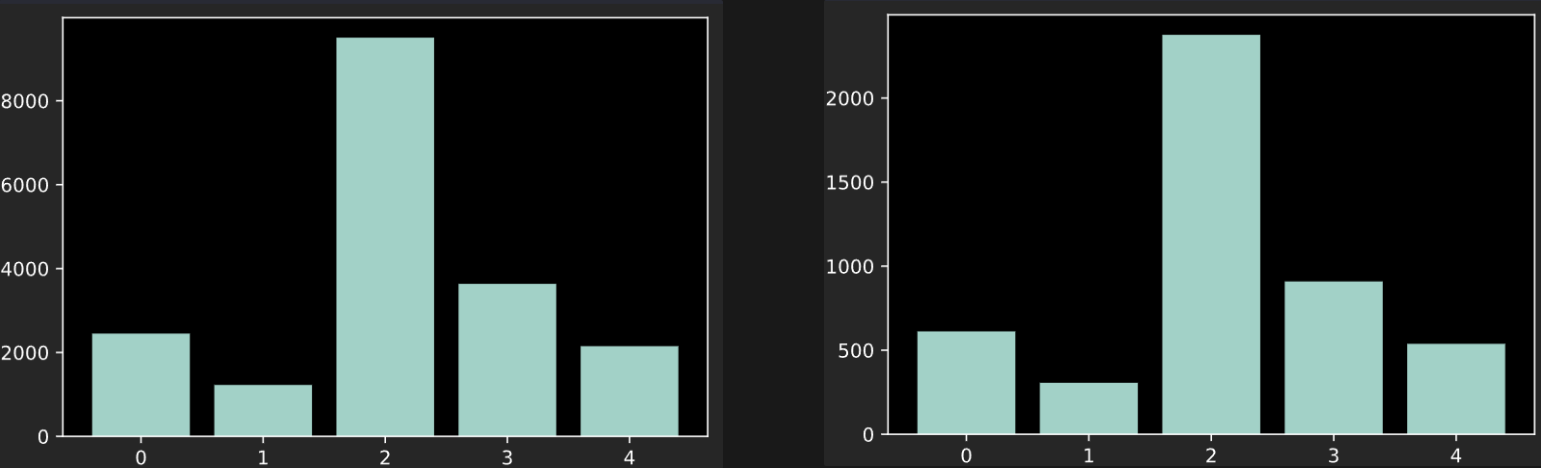
Kaggle의 AGE, GENDER AND ETHNICITY (FACE DATA) CSV이라는 dataset을 사용하였습니다. 해당 dataset에는 23705개의 데이터가 존재하고 각 데이터는 이미지, 나이, 인종, 성별로 이루어져 있습니다. 나이를 정확히 예측하기는 어렵기 때문에 5개의 범위로 나누었습니다. train data와 test data를 8:2 비율로 나누었습니다. train data, test data에 존재하는 나이대의 비율은 아래와 같습니다.
model
class Model(nn.Module):
def __init__(self, trial, age_features, ethnicity_features, gender_features):
super(Model, self).__init__()
self.name = "Model"
num_fc_layers = trial.suggest_int("num_fc_layers", 4, 8)
last_fc = trial.suggest_int("last_fc", 8, 64)
# fc layer
self.fc_layers = [nn.Flatten()]
input_feat = img_size * img_size
for i in range(num_fc_layers):
output_feat = trial.suggest_int(f"fc_output_feat_{i}", 8, 64)
p = trial.suggest_float(f"fc_dropout_{i}", 0, 0.5)
self.fc_layers.append(nn.Linear(input_feat, output_feat))
self.fc_layers.append(nn.ReLU())
self.fc_layers.append(nn.Dropout(p))
input_feat = output_feat
self.fc_layers.append(nn.Linear(input_feat, last_fc))
self.fc_model = nn.Sequential(*self.fc_layers)
# classifier
self.age_classifier = nn.Linear(last_fc, age_features)
self.eth_classifier = nn.Linear(last_fc, ethnicity_features)
self.gen_classifier = nn.Linear(last_fc, gender_features)
def forward(self, x):
output = self.fc_model(x)
age = self.age_classifier(output)
eth = self.eth_classifier(output)
gen = self.gen_classifier(output)
return age, eth, gen
model은 단순하게 FC만을 이용해서 구현했습니다. 여기서 사용되는 hyperparameter에는 num_fc_layers, last_fc, fc_output_feat, fc_dropout이 있습니다. 먼저 num_fc_layers는 model을 구성할 fc layer의 수를 의미하며 [4, 8]의 범위를 가지도록 하였습니다. 각 fc layer는 linear, relu, dropout으로 구성이 되는데, 이때 사용되는 hyperparameter가 fc_output_feat, fc_dropout입니다. 각 layer에 대한 값이 구분될 수 있도록 fc_output_feat_{i}와 같은 방식으로 각 layer의 번호를 각 변수의 이름 뒤에 붙혔습니다. output의 크기를 [8, 64] 범위에서 선택되도록 하였고, dropout 비율은 [0, 0.5] 범위의 값을 가지도록 구현했습니다.
나이, 인종, 성별을 모두 추론하기 위해서 각 label에 대한 linear layer를 사용했습니다. 이때 linear layer의 input 크기를 last_fc라는 hyperparameter로 정의하였습니다.
objective function
def objective(trial):
model = Model(trial, age_features, eth_features, gen_features).to(device)
opt_name = trial.suggest_categorical(
"optimizer",
["Adam", "Adadelta", "RMSprop", "SGD", "MADGRAD"],
)
lr = trial.suggest_float("lr", 1e-4, 1e-2, log=True)
if opt_name == "MADGRAD":
optimizer = madgrad.MADGRAD(model.parameters(), lr=lr)
else:
optimizer = getattr(optim, opt_name)(model.parameters(), lr=lr)
for epoch in range(1, n_epochs + 1):
train(model, train_dataloader, optimizer, epoch, weight_path=None, quiet=(epoch % period))
accuracy = test(model, test_dataloader, quiet=True)
trial.report(accuracy, epoch)
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return accuracy
objective 함수에서 추가적으로 정의한 hyperparameter는 lr과 opt_name입니다. lr은 learning rate로, [1e-4, 1e-2] 범위릐 값을 가지도록 하였고, opt_name은 suggest_categorical 함수를 사용해서 Adam, Adadelta, RMSprop, SGD, MADGRAD 중에서 optimizer가 선택되도록 구현하였습니다.
각 trial에서 미리 정의한 n_epochs만큼의 학습을 진행하게 되고, 그 후 test한 결과에 따라서 해당 trial이 prune될지 안될지가 결정됩니다.
study
storage = "sqlite:///test.db"
study_name = "001"
sampler = SkoptSampler(
skopt_kwargs={
"base_estimator": "RF",
"n_random_starts": 10,
"base_estimator": "ET",
"acq_func": "EI",
"acq_func_kwargs": {"xi": 0.02},
},
warn_independent_sampling=False
)
study = optuna.create_study(study_name=study_name, direction="maximize", storage=storage, sampler=sampler, load_if_exists=True)
study.optimize(objective, n_trials=20)
Optuna에서는 study 객체에서 hyperparameter optimization이 진행됩니다. sampler로는 scikit optimize의 SkoptSampler를 사용하였습니다.
skopt는 Bayesian optimization이며, 이때 acq_func는 Acquisition Function을 의미하고 다음 값을 결정하기 위해 사용되는 함수입니다. 여기서는 가장 많이 사용되는 Expected Improvement(EI)를 사용하였습니다.
beat trial
pruned_trials = [t for t in study.trials if t.state == optuna.trial.TrialState.PRUNED]
complete_trials = [t for t in study.trials if t.state == optuna.trial.TrialState.COMPLETE]
print("num_trials_conducted: ", len(study.trials))
print("num_trials_pruned: ", len(pruned_trials))
print("num_trials_completed: ", len(complete_trials))
trial = study.best_trial
print("[+] results: -----------------------------------------")
print(" | results from best trial:")
print(" | accuracy: ", trial.value)
print(" | hyperparameters: ")
for key, value in trial.params.items():
print(f" | {key}: {value}")
print(" +----------------------------------------------------")
num_trials_conducted: 20
num_trials_pruned: 15
num_trials_completed: 5
[+] results: -----------------------------------------
| results from best trial:
| accuracy: 69.45792026998524
| hyperparameters:
| fc_dropout_0: 0.05927094105851344
| fc_dropout_1: 0.29084040718075477
| fc_dropout_2: 0.13455450122716334
| fc_dropout_3: 0.29114171437625075
| fc_output_feat_0: 36
| fc_output_feat_1: 40
| fc_output_feat_2: 28
| fc_output_feat_3: 34
| last_fc: 43
| lr: 0.0015423462806943048
| num_fc_layers: 4
| optimizer: MADGRAD
+----------------------------------------------------
위 결과를 분석해보면 20번의 trial을 진행하였고, 그 중에서 15개가 prune되었음을 확인할 수 있습니다. 가장 accuracy가 높았던 trial에서 사용된 hyperparameter의 값 또한 알 수 있고, 이를 최적의 hyperparameter로 판단할 수 있습니다.
Skopt Sampler vs Ramdom Sampler + Visualization
sampler가 optimization 성능에 어떤 영향을 미치는지를 확인하기 위해 Skopt Sampler와 Ramdom Sampler의 성능에 대해 비교를 해보았습니다.
또한 Optuna에서 제공하는 시각화 도구를 활용하여 결과를 시각화해보았습니다.
best trial
-
Skopt Sampler
num_trials_conducted: 100 num_trials_pruned: 73 num_trials_completed: 27 [+] results: ----------------------------------------- | results from best trial: | accuracy: 69.56338325247837 | hyperparameters: | fc_dropout_0: 0.13376861811536073 | fc_dropout_1: 0.15357136269549693 | fc_dropout_2: 0.07170506034936153 | fc_dropout_3: 0.04104589071975262 | fc_dropout_4: 0.38519700327029344 | fc_output_feat_0: 55 | fc_output_feat_1: 53 | fc_output_feat_2: 62 | fc_output_feat_3: 62 | fc_output_feat_4: 28 | last_fc: 55 | lr: 0.002676347859117992 | num_fc_layers: 5 | optimizer: Adam +---------------------------------------------------- -
Ramdom Sampler
num_trials_conducted: 100 num_trials_pruned: 87 num_trials_completed: 13 [+] results: ----------------------------------------- | results from best trial: | accuracy: 67.60177177810588 | hyperparameters: | fc_dropout_0: 0.016225409134656366 | fc_dropout_1: 0.4284657526506286 | fc_dropout_2: 0.13551661039530455 | fc_dropout_3: 0.1982516747418307 | fc_dropout_4: 0.04493982076202707 | fc_dropout_5: 0.062072207295049364 | fc_output_feat_0: 36 | fc_output_feat_1: 61 | fc_output_feat_2: 49 | fc_output_feat_3: 46 | fc_output_feat_4: 57 | fc_output_feat_5: 13 | last_fc: 24 | lr: 0.0001700730078227611 | num_fc_layers: 6 | optimizer: MADGRAD +----------------------------------------------------
Skopt Sampler를 사용했을 때 더 높은 accuracy를 달성하였습니다.
optimization history
-
Skopt Sampler
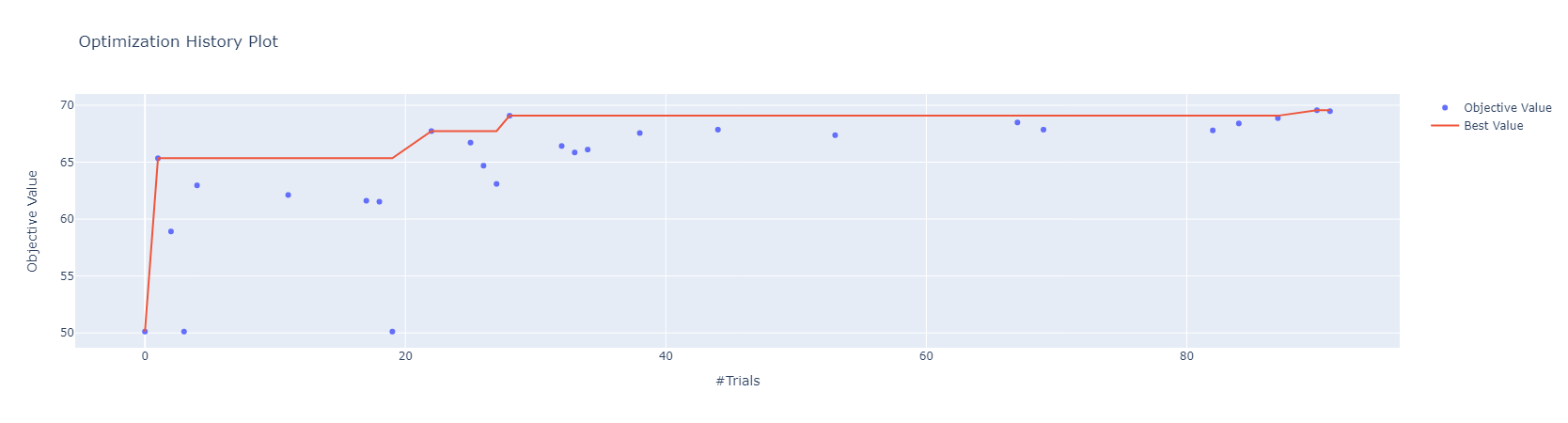
-
Ramdom Sampler
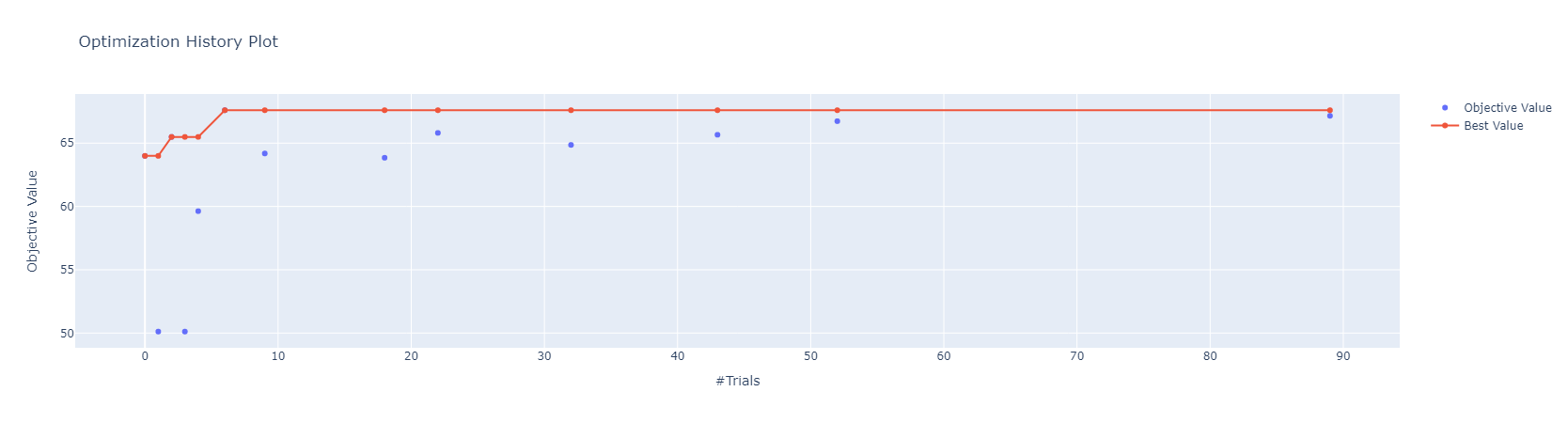
Skopt Sampler를 사용했을 때는 best trial이 많이 업데이트되었지만, Ramdom Sampler를 사용했을 때는 그러지 않음을 확인할 수 있습니다.
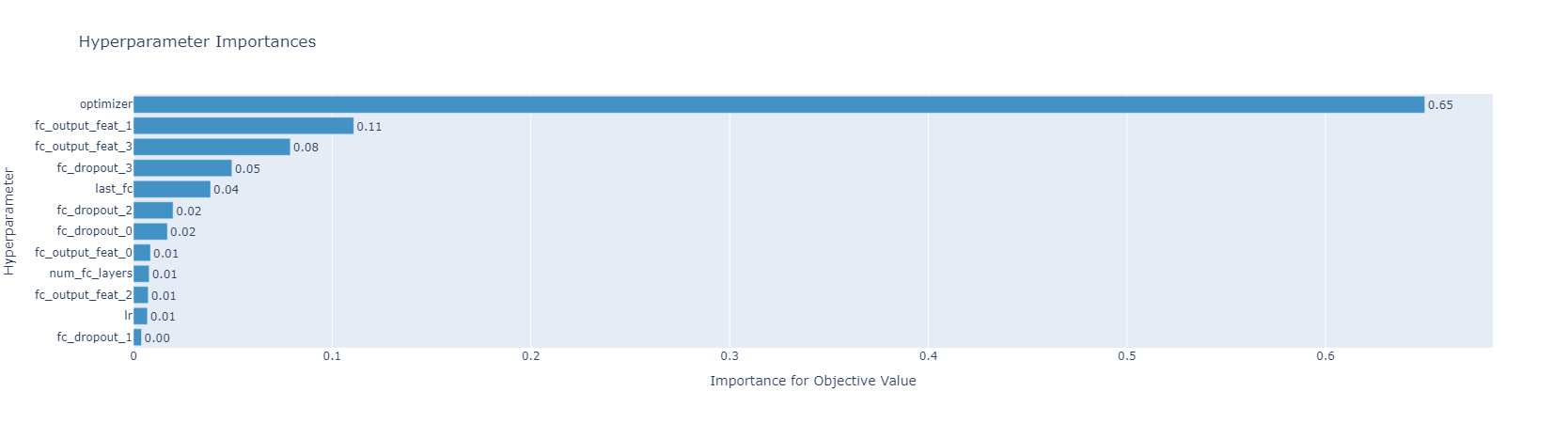
hyperparameter importances
-
Skopt Sampler
-
Ramdom Sampler
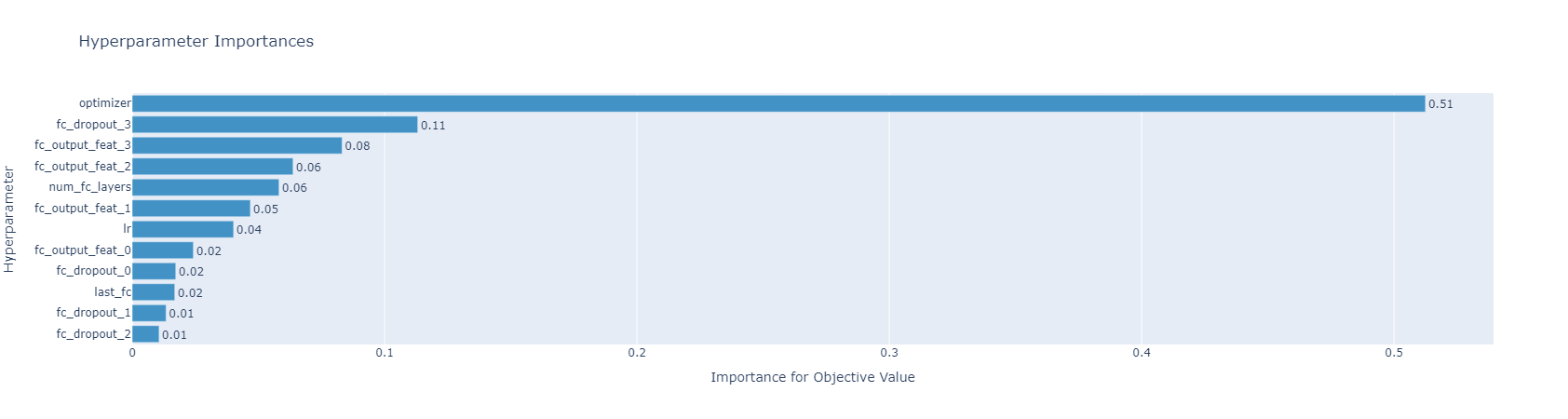
위 그래프는 optuna.visualization.plot_param_importances 함수를 이용해서 각 hyperparameter의 중요도를 확인한 결과입니다. 두 그래프 모두 optimizer가 압도적으로 중요하다고 말하고 있고, 그에 비해 나머지 hyperparameter의 중요도는 두 그래프에서 유사하다고 할 수 있습니다.
Reference
- https://optuna.org/
- Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta,and Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Framework. In KDD.
- https://neptune.ai/blog/optuna-vs-hyperopt
- https://optuna.readthedocs.io/en/stable/index.html