Vision Transformer (1)
들어가며
Transformer을 다룬 지난 포스트에서 self-attention이 등장하게 된 배경과 그 알고리즘에 대해 알아보았다. 놀라운 것은 self-attention이 machine translation과 같은 자연어처리 문제들뿐만 아니라 컴퓨터 비전 분야에서도 높은 성능을 보이고 있다는 것이다. 그 시작은 Transformer의 발표 직후인 2018년으로 거슬러 올라간다. Transformer의 성공을 지켜본 컴퓨터 비전 연구자들은 먼저 CNN 구조에 self-attention을 더하거나 이미지의 각 픽셀을 문장의 각 단어로 간주해 self-attention을 적용하려 했다. 하지만 이 방법에는 두 가지 단점이 있었다.
- 이미지 사이즈에 비례해서 문장의 길이가 길어진다. 비전 분야에서는 low-resolution에 속하는 128x128 이미지조차도 16384 픽셀이다. 1픽셀을 1단어로 생각한다면, 128x128 이미지는 300페이지짜리 책만큼 길다. 당연히 연산량이 매우 많고 성능이 좋지 않다.
- CNN이 효과적이었던 것은 convolutional kernel이 이미지의 local한 feature을 포착할 수 있었기 때문이다. 하지만 이미지를 flat하게 만들어 pixel의 sequence로 간주한다면, 이미지의 특성이 사라지고 local한 feature을 포착할 수 없다.
그리고 Google Brain 팀은 2021년, 1과 2를 해결하면서 Transformer의 아이디어를 그대로 이어받은 Vision Transformer (ViT)를 발표했다.
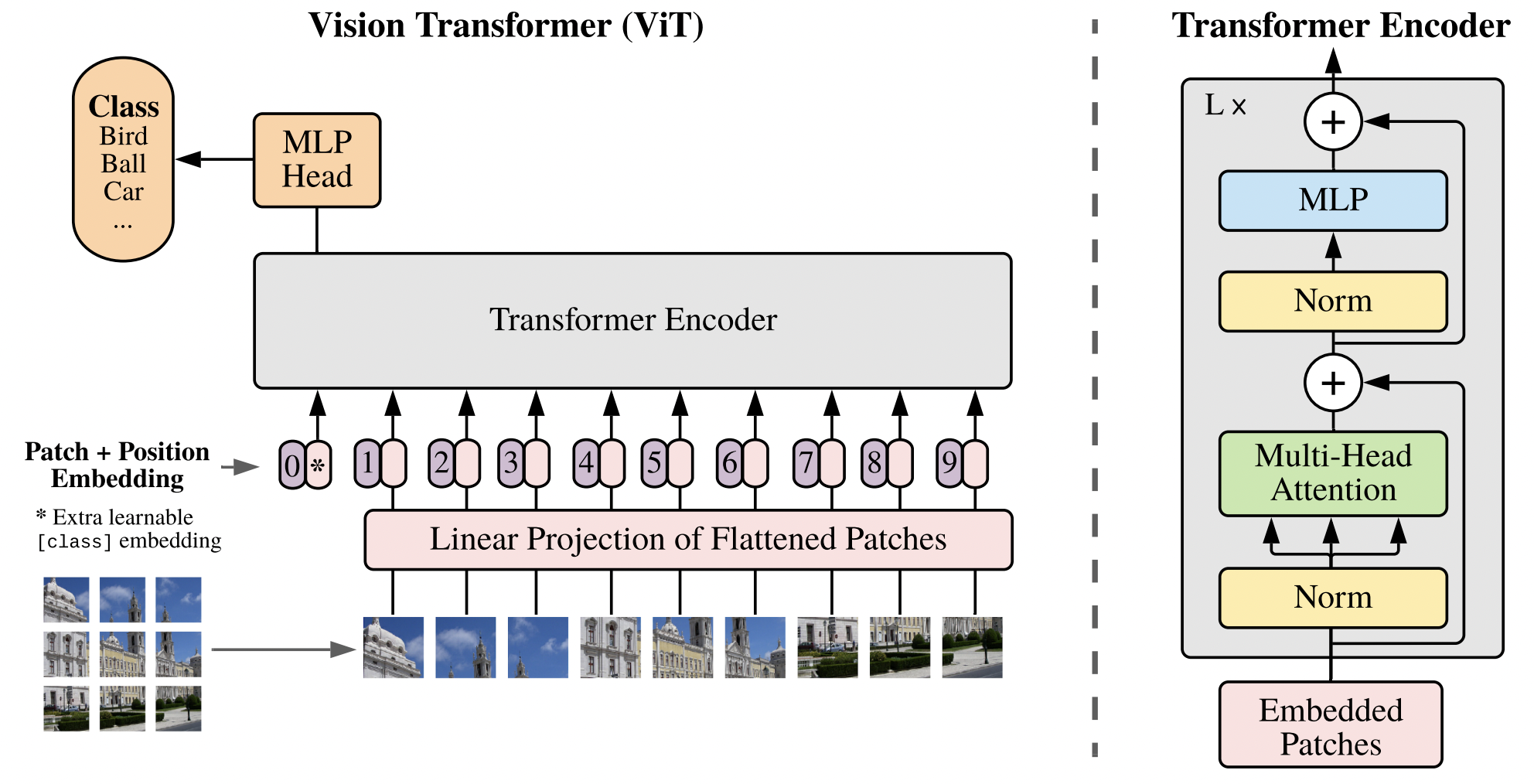 그림 1. Overview of ViT
그림 1. Overview of ViT
이미지의 기본 단위: Patch
 그림 2. 강아지와 고양이를 구분하는 태스크. 위처럼 이미지의 patch를 주면 구분하는 것이 매우 쉽지만, 아래처럼 pixel을 준다면 구분하기 어려울 것이다.
그림 2. 강아지와 고양이를 구분하는 태스크. 위처럼 이미지의 patch를 주면 구분하는 것이 매우 쉽지만, 아래처럼 pixel을 준다면 구분하기 어려울 것이다.
문장의 기본 단위는 단어이다. 하지만 이미지의 기본 단위가 픽셀이어야 할까? Convolutional layer의 작동 원리를 생각하면, 이미지는 주변 픽셀을 patch로 함께 볼 수 있을 때 훨씬 이해하기 쉽다. 그림 2에서 아래에 있는 pixel만 보고 그것이 고양이의 이미지인지 강아지의 이미지인지 구분하는 것은 사람에게는 불가능하고 neural network에게도 어려운 일일 것이다. 강아지와 고양이에 해당하는 절대적인 pixel 값과 위치가 있는 게 아니라, 주변 픽셀과 비교하여 이루는 feature을 보아야 하기 때문이다.
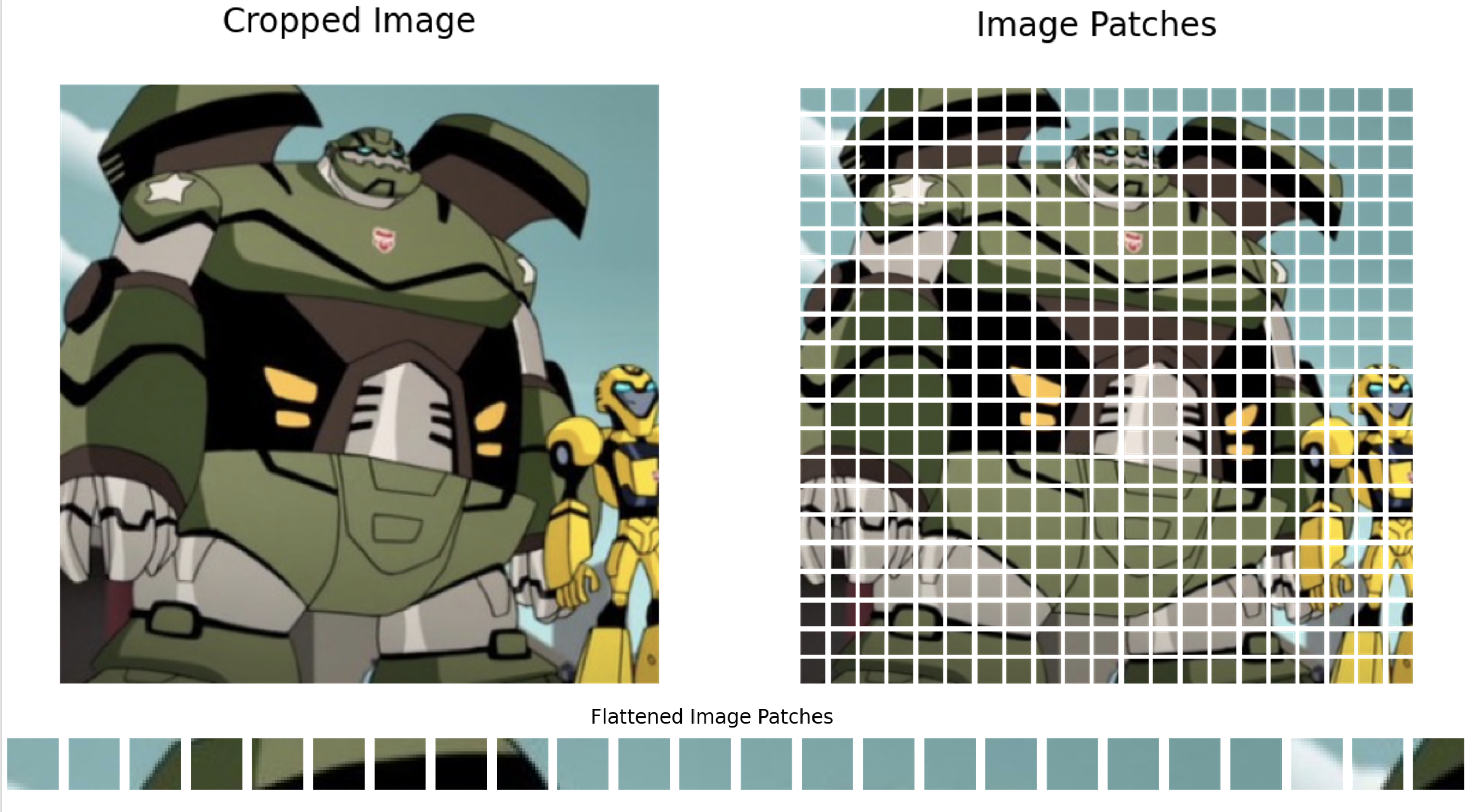 그림 3. ViT의 접근 방식. 이미지를 patch로 나눈다. (출처)
그림 3. ViT의 접근 방식. 이미지를 patch로 나눈다. (출처)
그래서 ViT의 저자는 이미지의 기본 단위를 pixel이 아니라 16x16 등 정해진 크기의 patch로 정의한다 (그림 3).
Self-attention
ViT에서는 이렇게 나누어진 patch를 self-attention의 input으로 쓸 수 있도록 1차원 행렬로 flat하게 변형한다. 그리고 각 patch마다 patch encoding과 position encoding을 얻는다. Position encoding은 각 patch가 본래 이미지의 어떤 위치에서 왔는지에 대한 정보를 준다. ViT 논문에서 저자들은 patch이 원래 position을 (x, y) 2차원 값으로 주는 것이 가장 효과적이라고 밝히고 있다. 또 patch encoding은 patch 전체를 설명할 수 있는 하나의 값을 multi layer perceptron을 통해 생성해낸 것이다. 즉 Patch encoding은 patch의 가장 간결한 하나의 representation이다 (지난 포스트 참고). 최종적으로 ViT의 input은 아래와 같다.
- Flatten된 patch
- Position encoding
- Patch encoding
ViT의 목표가 Transformer 논문의 self-attention을 그대로 이미지에 차용하는 것이었기 때문에, 이후에 이어지는 self-attention 과정은 지난 포스트와 같다.
 그림 4. ViT variants.
그림 4. ViT variants.
논문에서 제시된 ViT 모델의 variant들은 그림 4와 같다. 컴퓨터 비전에서 가장 흔히 사용되는 backbone인 ResNet-101이 44M의 parameter을 가지는 것을 생각하면, 632M의 parameter은 엄청난 숫자다. 지난 포스트의 마지막에서 짧게 밝혔듯이 대개 self-attention 모델은 convolutional layer보다 훨씬 많은 parameter 수와 그에 따라 훨씬 길어진 학습 시간을 필요로 한다.
Attention is all you need
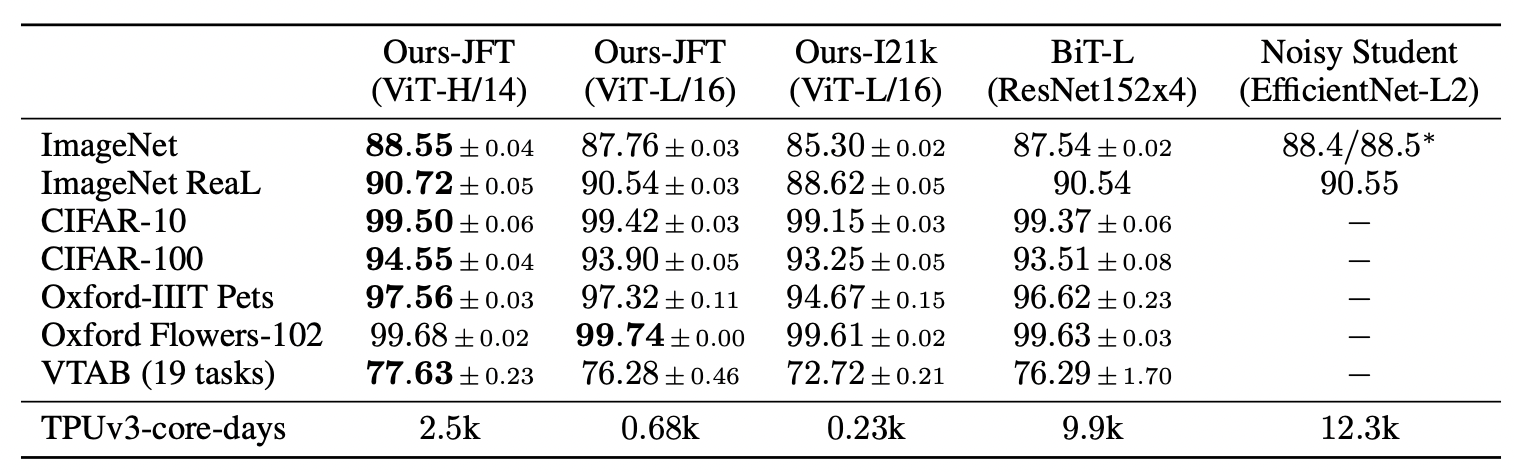 그림 5. ViT와 CNN 기반 state-of-the-art 모델 (BiT, Noisy Student) 의 accuracy 비교. 각 벤치마크에서 가장 높은 성능은 볼드 처리됨.
그림 5. ViT와 CNN 기반 state-of-the-art 모델 (BiT, Noisy Student) 의 accuracy 비교. 각 벤치마크에서 가장 높은 성능은 볼드 처리됨.
ViT의 저자들이 그들의 모델과 비교한 것은 당시 CNN 모델 중 가장 효과적이었던 것 두 개다. 하나는 152레이어의 ResNet 4개를 사용해 supervised transfer learning을 진행한 BiT 모델이고, 다른 하나는 거대한 unlabeled 이미지 데이터셋에서 semi-supervised learning을 진행한 EfficientNet 구조의 Noisy Student 모델이다. 그림 5에서 볼 수 있듯이, ImageNet, CIFAR-10, CIFAR-100 등 거의 모든 잘 알려진 Image classification 벤치마크에서 ViT는 가장 높은 성능을 달성했다.
성능은 분명 많은 것을 말해주지만, 왜 self-attention이 convolution보다 효과적인지에 대한 근본적인 의문이 남는다. 논문에서는 그 이유에 대해 많은 것을 설명하고 있지는 않다. 하지만 지난 포스트에서 설명했듯이, 멀리 있는 단어와의 dependency를 계산할 수 있다는 것이 그 이유일 것이라 추측해볼 수 있다. Convolution은 정해진 receptive field 크기로 인해 멀리 있는 feature과의 dependency를 계산하기 어렵다. 하지만 이미지를 patch로 나누고 patch간에 self-attention을 한다면, 본래 이미지에서 얼마나 멀리 떨어져 있었는지와 관계 없이 모든 patch의 정보를 이용할 수 있다.
Beyond CNN, Beyond self-attention
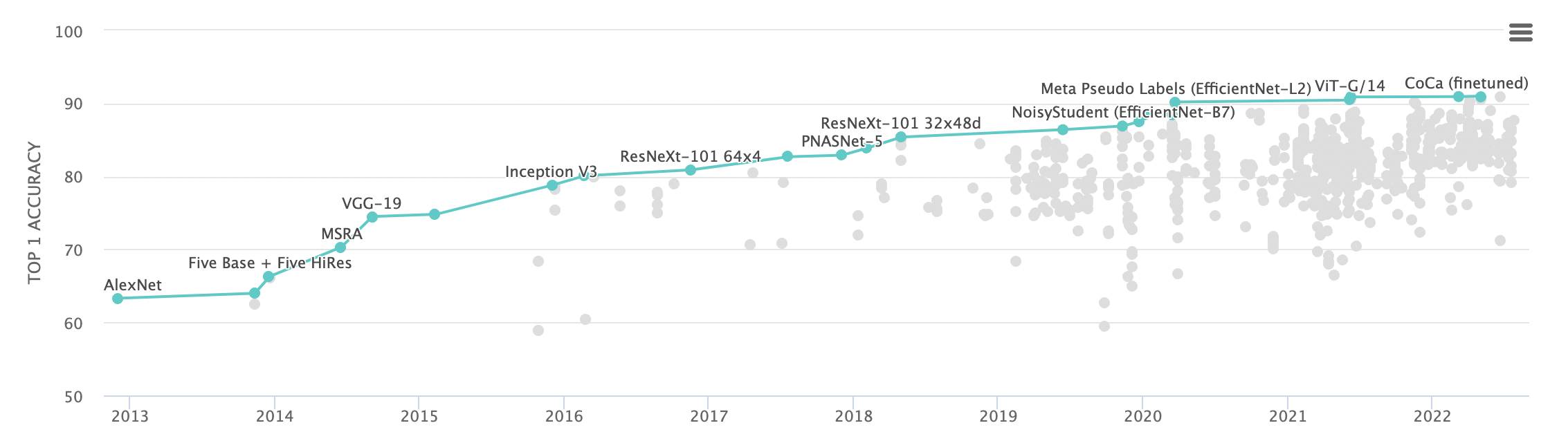 그림 6. ImageNet Top 1 accuracy로 정렬된 Image classification 리더보드. (출처)
그림 6. ImageNet Top 1 accuracy로 정렬된 Image classification 리더보드. (출처)
그림 6을 보면 ViT가 비교 대상으로 삼은 Noisy Student과 ResNet 모델이 2021년까지 최고의 모델이었다는 것을 확인할 수 있다. 그러나 ViT가 발표된 2021년 이후 리더보드의 상위권은 모두 self-attention 기반의 모델로 바뀌었다. 이 논문에서 발표된 ViT-Huge조차 현재 ImageNet 리더보드에서 25위이다. 1년이라는 짧은 시간동안 24개의 더 나은 모델이 제시되었다는 뜻이다. 그중에서는 구조적으로 ViT를 발전시킨 Swin transformer도 있고, 추가적인 데이터를 이용할 수 있는 더 나은 학습 방식을 제시한 모델들도 있다.
1980년대에 제시된 CNN은 2010년대까지 컴퓨터 비전에서 가장 강력한 모델이었다. ImageNet이 2010년대 중반 AI winter을 완전히 끝냈고 그 주역은 ResNet일 것이다. 많은 비전 모델의 backbone으로 사용되던 ResNet은 2021년 self-attention에게 1등의 자리를 내주었다. 하지만 겨우 1년 사이에 ViT보다 나은 모델이 24개나 발표되었다. 사실, self-attention은 이미 별로 새롭지 않은 주제가 되어버렸다. Masked autoencoder, MLP-Mixer 등 너무나도 많은 모델들이 새롭게 발명되고 있다. 조금 다른 태스크로 눈을 돌려 view synthesis를 살펴본다면 2021년을 지배한 neural radiance field도 있다. 그 발명은 모델 architecture에만 한정된 것이 아니다. Label된 이미지는 한정적이니 인터넷의 모든 정보로부터 학습하려는 self-supervised, semi-supervised, multimodal learning 방식들도 수없이 고안되고 있다.
마치며
Standford AI Index report에 따르면 2020년 발표된 AI 논문이 34736편이라고 한다. 이는 2015년 5478편에서 6배나 증가한 수치이다. 하루에 논문 1편을 읽어도 발표된 논문의 1%를 읽는 것이니 현직 연구자들조차도 딥러닝의 발전 속도를 좇는 것이 가능할까 걱정한다고 한다. 게다가 학생인 나에게 그 30000이라는 숫자는 까마득히 크게 느껴진다. 하지만 나는 ViT와 같은 거대한 발자국들을 따라가는 것이 하나의 방법이 될 수 있다고 생각한다.
Self-attention 그 너머가 궁금한 사람들에게 CVPR 2022에서 Google 팀이 강연한 Beyond Convolutional Neural Networks 튜토리얼을 소개하며 포스트를 마치겠다.