Foundation Model and Transfer Learning
최근 딥러닝 관련 challenge나 딥러닝을 이용한 task를 수행할 때 pretrained model을 사용하지 않으면 높은 성능을 내기 어려운 상황입니다. 그 중에서도 scale이 커서 일반화된 성능을 내는 모델들을 foundation model이라고 합니다. 이번 글에서는 이러한 foundation model에 대해 자세히 알아보겠습니다.
최신 AI 연구 트렌드
최근 AI 연구에서의 트렌드는 모델을 포함하여 dataset, computing resource 등 뭐든 크게 만드는 것입니다. 모델이 크면 서비스가 요구하는 latency를 만족하기 어렵고 상시 많은 resource를 사용할 수 없습니다. 따라서 큰 모델이 학습한 지식을 작은 모델에 주입시키는 knowledge transfer 과정을 거치고, 작은 모델이 실제 서비스에 사용됩니다. 이 때 큰 모델을 학습하는 과정을 pre-training이라고 하며, 작은 모델에 지식을 주입하는 과정을 transfer learning이라고 합니다.

https://tv.naver.com/v/23650477
이러한 방식 말고도 큰 모델 자체에 다시 새로운 task를 학습시키는 방법도 있습니다. 이러한 방식을 fine-tuning이라고 하며, 이렇게 학습이 완료된 모델에 새로운 task를 학습시키면 빠른 시간에 높은 성능을 달성합니다.
예를 들어 GPT-3의 사례를 살펴봅시다. GPT-3는 간단히 말해서 다음 단어(token)를 추론하는 task를 푸는 language model입니다. GPT-3를 활용한 transfer learning (fewshot learning)을 하면 소설 쓰기, 시 쓰기, 레시피 만들기, 댓글 쓰기 등 다양한 task에 대해서 빠른 시간에 높은 성능을 달성할 수 있습니다. 링크를 통해 OpenAI에서 제공하는 다양한 예제들을 살펴볼 수 있습니다.

https://beta.openai.com/examples
Foundation model
foundation model이라는 용어는 스탠포드 대학의 On the Opportunities and Risks of Foundation Models논문에서 처음 제안되었습니다. 간단히 정의하면 그 자체가 서비스에 사용되지 않지만, transfer learning 과정을 거쳐 서비스에 사용되는 모델입니다. 논문의 Abstract에서 주요한 내용을 살펴보면 아래와 같습니다.
- AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks.
- We call these models foundation models to underscore their critically central yet incomplete character.
- Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities, and their effectiveness across so many tasks incentivizes homogenization.
- Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream.
위 내용에서 emergent capabilities, homogenization라는 용어가 생소하기 때문에 그에 대해 자세히 알아보도록 하겠습니다.
AI의 발전 방향: Emergence and Homogenization
AI는 Emergence와 Homogenization을 증가시키는 방향으로 발전하고 있습니다.
Emergence는 기능이 explicit하게 의도되는 것이 아닌 implicit하게 유도되는 것을 의미합니다. 즉, 사람이 명시적으로 정할 부분이 줄어드는 방향 혹은 부가적인 기능이 커지는 방향으로 발전한다는 것입니다. (의도했던 능력 + 추가 능력) 예를 들어 어떤 알고리즘으로, 어떤 feature를 사용하여, 어떤 기능을 수행하도록 학습할지 등등이 있습니다.
Homogenization은 각 프로그램마다 혹은 각 task마다 서로 다른 알고리즘, 아키텍처, 모델을 사용하는 것이 아니라, 동일한 하나의 모델로 여러 문제를 해결한다는 의미입니다. 말로 풀어서 설명하기에 약간은 애매한 개념들이지만, 아래 그림을 살펴보면 이해에 도움이 되실 거라 생각합니다.
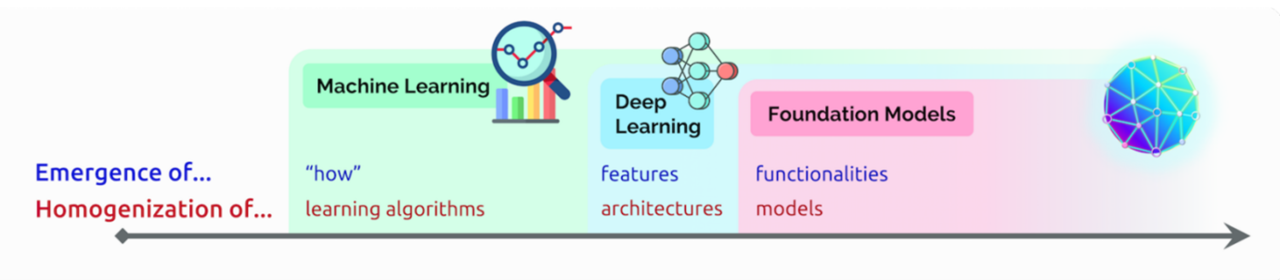
https://arxiv.org/pdf/2108.07258
다음으로 실제로 Emergence와 Homogenization가 어떻게 발전하였는지 구체적으로 살펴보겠습니다.
https://tv.naver.com/v/23650477
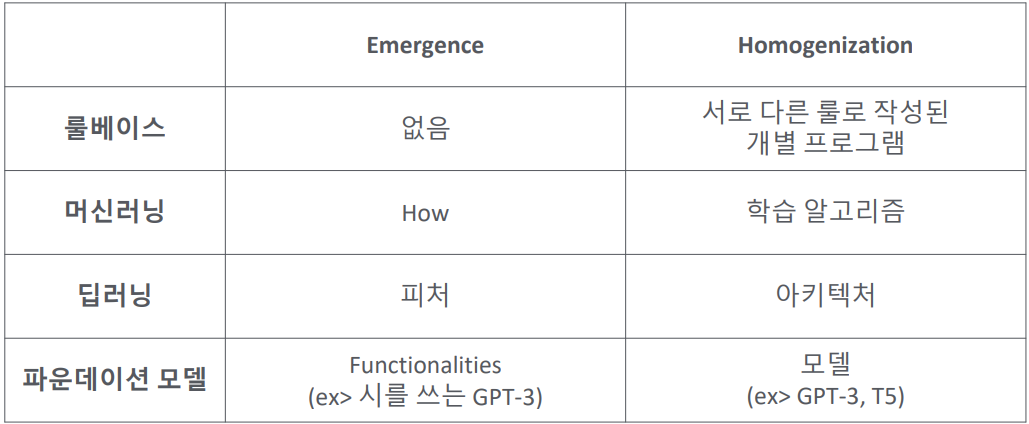
- 룰베이스: 70 ~ 80년대
- 프로그래머가 작동한 룰 그대로 작동할 뿐 그 외의 기능이 존재하지 않음
- 이러한 명확한 한계로 2번의 AI winter를 야기함
- 머신러닝: 90년대
- ai가 입출력 사이의 관계를 학습 → 변수들 사이 관계가 자동으로 생성됨 (how)
- 기계학습 모델은 같은 알고리즘일수록 비슷한 특징을 가짐
- → task를 풀 때 어떤 알고리즘 (SVM, neural net, decision tree, …)을 적용할지 고민
- 딥러닝: 2010년대
- 피처를 자동으로 생성 → data만 많이 넣어주면 전처리 과정을 자동으로 수행
- 기계학습 알고리즘으로 모델링을 하면 how를 알 수 있었지만, task마다 별도의 입력 전처리를 거쳐야 했음
- → 모델링에 많은 시간 소요
- task를 풀 때 어떤 아키텍처 (CNN, LSTM, Transformer, …)를 사용할지 고민
- 피처를 자동으로 생성 → data만 많이 넣어주면 전처리 과정을 자동으로 수행
- 파운데이션 모델: 2020년대
- functionality를 자동으로 생성
- ex. 다음 단어를 예측하는 language model로서 GPT-3를 학습시켰더니, 의도치 않게 시, 코드, 소설 등을 쓰는 기능을 가지게 됨
- functionality를 자동으로 생성
위 내용은 한 마디로 AI는 기능은 더 많아지고 빌드하기 쉬운 형태로 발전하고 있다고 요약할 수 있을 것 같습니다.
Foundation Model for Business
다음으로 실제 비즈니스에서 foundation model이 어떻게 사용되며, 그를 위해 어떤 연구가 이루어지고 있는지에 대해 알아보겠습니다. 주된 내용은 Naver에서 최근 hyper scale AI를 위해 진행한 연구들입니다. 따라서 주로 쇼핑, 유저 임베딩 등 Naver의 주요 사업과 크게 관련이 있습니다.
Related works
BERT, GPT 등의 pre-text task를 응용해 business model을 만들려는 시도가 아래와 같이 있었습니다.
- Zhang et al., 2020
- Xie et al., 2020
- Gu et al., 2021
하지만 위 연구들은 NLP와 vision field에서 여겨졌던 foundation model들에 비해 큰 한계점들이 존재합니다. 먼저 foundation model로 확장되기에는 model, dataset 등의 scale이 부족합니다. 또한 다양한 downstream task로의 확장이 부족합니다. Naver에서는 이러한 한계점을 해결하기 위해 아래와 같은 연구를 진행하였다고 합니다.
ShopperBERT
ShopperBERT는 기존 NLP에 쓰이던 BERT의 아이디어를 차용해 만든 모델입니다. 사용자의 쇼핑 구매 기록을 Masked Language Model (MLM) 방식으로 학습하고, 최종적으로 이 구매 기록을 이용해 유저 임베딩을 추출합니다. 1,300만 유저와 4,800만개의 상품을 대상으로 2년치 구매 기록 (8억)을 수집해 학습했으며, SentenceBERT를 이용해 상품명을 embedding vector로 넣어줍니다. 상품의 계층별 카테고리 (총 7,945)를 supervision으로 사용하였으며, 6개의 Downstream tasks에서 pre-trained된 user embedding을 feature-based MLP 방식으로 학습 시킨 후 성능을 평가하였습니다.
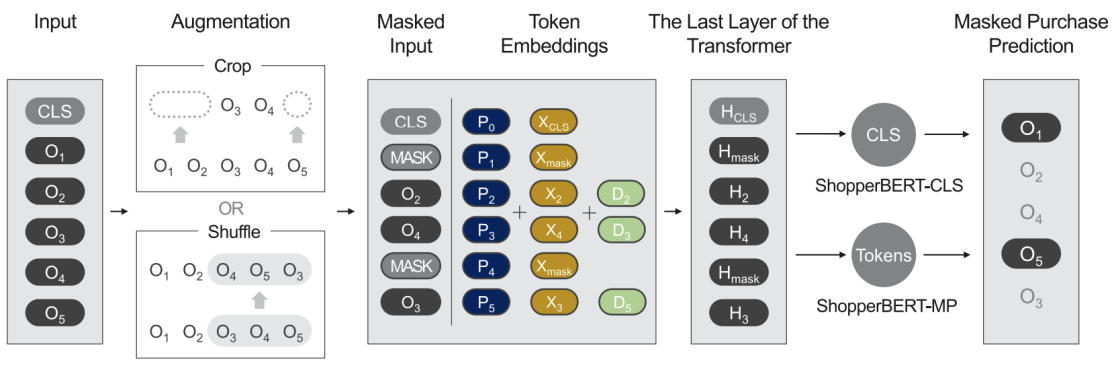
concept figure: https://arxiv.org/ftp/arxiv/papers/2106/2106.00573.pdf
ShopperBERT의 동작 과정은 위 그림과 같습니다. 구매 상품들을 상품 단위로 나타내는 것이 아닌, 하위 카테고리로 분류하여 input으로 넣어줍니다. 이후 이 목록을 적절한 방식으로 augmentation한 뒤, 랜덤하게 [MASK] 토큰을 씌워, 최종적으로 그 [MASK] 토큰 위치의 카테고리가 무엇인지 맞추는 pretext-task를 풉니다. 유저 임베딩을 추출할 때는 이렇게 학습한 ShopperBERT에 아무런 augmentation을 적용하지 않고 원본 그대로 사용자의 구매 기록을 넣어 [CLS] 토큰으로 임베딩을 추출합니다. 최종적으로 추출한 유저 임베딩을 사용해 각 downstream tast를 풉니다.
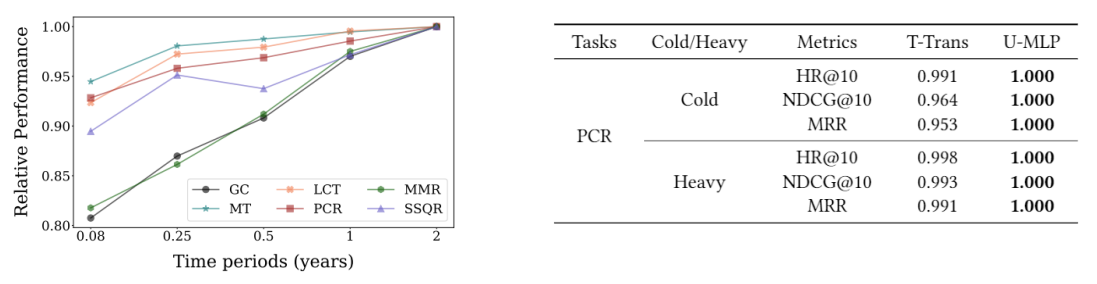
실험 및 가설 검증: https://arxiv.org/ftp/arxiv/papers/2106/2106.00573.pdf
왼쪽은 데이터 수집 기간에 따른 상대적 성능 변화를 나타낸 그래프입니다. 실험적으로 유저 기록을 오랜 기간 수집할수록 모델이 downstream에서 더 좋은 성능을 보이는 것을 알 수 있습니다. 오른쪽은 downstream 서비스에서 구매 기록이 적은 cold 유저와 구매 기록이 많은 heavy 유저에 대해서 pre-train된 유저 임베딩이 얼마나 효과적이었는지 비교한 표입니다. T-Trans는 downstream 데이터를 가지고 학습한 복잡한 추천 모델, U-MLP는 pre-train된 유저 임베딩을 활용해 학습한 단순한 모델을 의미합니다. cold, heavy 유저에 대해서 모두 U-MLP의 성능이 좋으며, 특히나 cold 유저에 대해서 성능 차이가 크다는 것을 확인할 수 있습니다.
ShopperBERT는 쇼핑 데이터를 이용한 pretrained user embedding이 쇼핑과 연관된 다양한 task에서 task-specific 추천 모델을 뛰어넘을 수 있음을 보여주었습니다. 이는 Global user embedding을 학습하고 사용하는 것이 실제로 가능함을 의미하며 학습된 user embedding을 이용하면 편리하고 빠르게 MLP 모델을 이용하여 복잡한 추천 모델의 성능을 뛰어넘을 수 있게 됩니다. (2,458배 빠른 속도)
다만 ShopperBERT는 기존 foundation model들과는 다르게 모델 크기를 늘려도 성능 향상이 두드러지지 않습니다. 이는 상품의 카테고리를 맞추는 task가 상당히 쉽다는 것을 의미합니다. 또한 downstream task가 쇼핑과 연관된 도메인에 국한된다는 한계도 존재합니다. 부가적으로는 train dataset이 한 가지 도메인의 dataset (Unimodal dataset)이었으며 오로지 Naver에서만 사용할 수 있고 다른 시스템으로의 전이가 불가능하다는 한계가 존재합니다.
SimCLR를 활용한 개선
저자는 ShopperBERT에서 사용하던 target objective가 다방면의 규모 확장을 제한한다고 판단하여, Equivalent predictive objective가 아닌 contrastive objective를 사용하는 contrastive learning으로 연구방향을 바꾸었습니다. 그를 위해 vision field에서 활용되는 contrastive model 중 가장 널리 알려진 SimCLR를 채택해 활용하였습니다. SimCLR는 contrastive setup을 따르기 때문에 상품의 카테고리 등과 같은 정보를 target objective로 사용할 필요 없다는 것이 큰 장점입니다. 따라서 오로지 구매 상품의 상품 설명만을 이용해 자연어 레벨로 떨어진 구매 기록 데이터를 구축하였습니다. 즉, ShopperBERT와 달리 상품명 텍스트 피쳐 자체를 학습하게 됩니다. 쇼핑 구매 기록을 일부분 바꿔치거나, 일정 기간으로 잘라 두 가지 augmentation data를 만들고 contrastive setup으로 학습하여 최종적으로 ShopperBERT에 비해 Downstream Tasks에서 7~12% 성능이 상승하였습니다.
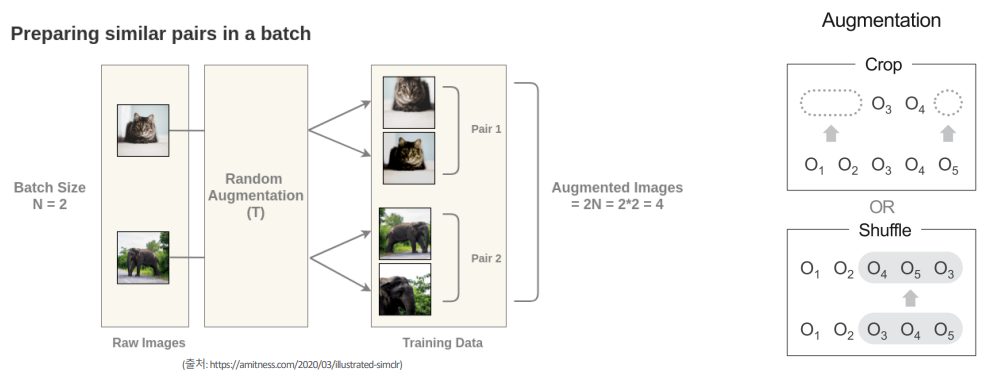
Concept Figure: https://tv.naver.com/v/23650477
기존의 SimCLR는 한 개의 이미지를 augmentation을 통해 2개의 이미지로 만들고, constrative learning을 통해 유사도를 최대화하는 방향으로 학습합니다. 저자는 이 아이디어를 차용해 유저의 구매 기록을 자르거나 섞어서 서로 다른 2개의 augmented 구매 기록을 만들고, 같은 유저는 유사도가 높게, 서로 다른 유저는 유사도가 낮게 만드는 contrasive learning을 이용해 모델을 학습시켰습니다. 유저 피처를 뽑는 방법과 평가 프로토콜은 shopperBERT와 동일하게 진행하였습니다.
이 연구에서는 Contrastive objectiv를 사용함으로써 pre-text task가 더욱 어려워졌고 모델 크기를 키울 수록 성능이 향상되었습니다. 또한 Pre-train하는데 있어 상품명만 필요함으로 다른 시스템으로의 전이 가능합니다.
다만 여전히 downstream task가 쇼핑과 연관된 도메인에 국한되어 있으며, train dataset이 한 가지 도메인의 dataset (Unimodal dataset)이었으며 SimCLR를 학습하기 위한 적절한 aumentation 기법을 도출하지 못했다는 한계가 존재합니다.
Contrastive Learning User Encoder (CLUE)
CLUE는 앞선 연구에서의 SimCLR와 마찬가지로 contrasive model입니다. CLUE에서는 augmented 서비스 기록이 아닌, 동일한 유저의 서로 다른 서비스 기록을 가져와 유사도를 최대화하도록 학습합니다. 725 million 파라미터 모델과, 50 billion 서비스 로그를 학습시켰으며 텍스트화 된 인풋을 사용하기 때문에 domain과 system을 넘나드는 transfer learning이 가능하다는 것이 특징입니다.

https://tv.naver.com/v/23650477
따라서 위 그림처럼 CLUE는 네이버 서비스 내의 다양한 서비스 기록을 받아 각종 downstream task로 이를 transfer할 수 있습니다.
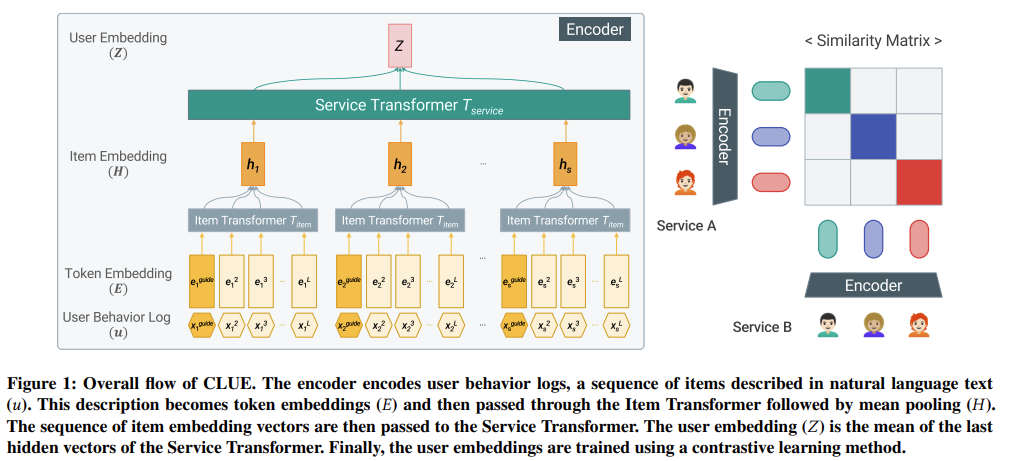
https://arxiv.org/pdf/2111.11294.pdf
위 그림은 CLUE의 학습방법을 간소화해 나타낸 것입니다. 텍스트화된 유저의 서로 다름 서비스 기록을 encoding하여 vector로 뽑아낸 뒤, 유사도를 최대화하는 방향으로 학습하며, 이 방식으로 augmentation 기법이 필요없고, 다양한 서비스 도메인을 함께 학습하기 때문에 multimodal하다는 점이 CLUE의 큰 2가지 장점이라고 합니다. 이 방식으로 뽑아낸 유저 피처를 downstream에 transfer했을 때 SimCLR 모델에 비해 10~20% 성능이 향상되었습니다.
analysis
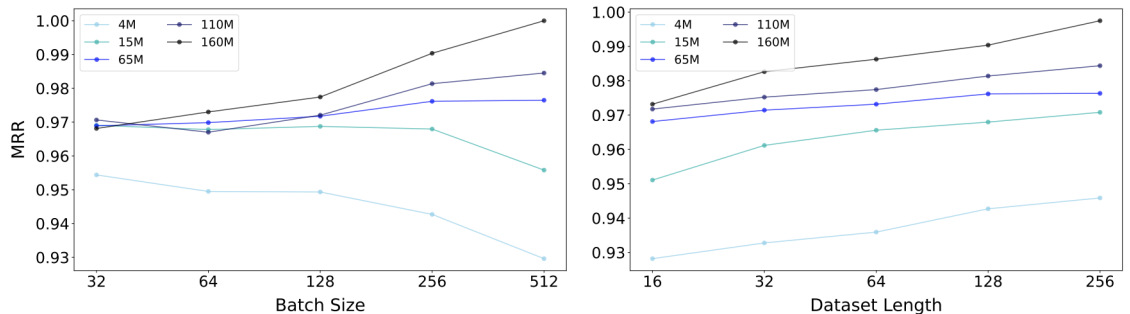
왼쪽은 데이터셋 길이를 고정하고 batch size와 model size를 변형해가며 성능을 측정한 그래프입니다. batch size와 model size 모두 적절하게 증가시켜야 성능이 향상됨을 확인할 수 있습니다. 오른쪽은 batch size를 고정하고, datset length와 model size를 변형해가며 성능을 측정한 그래프입니다. dataset length를 증가시키면 항상 성능이 향상됨을 확인할 수 있습니다.
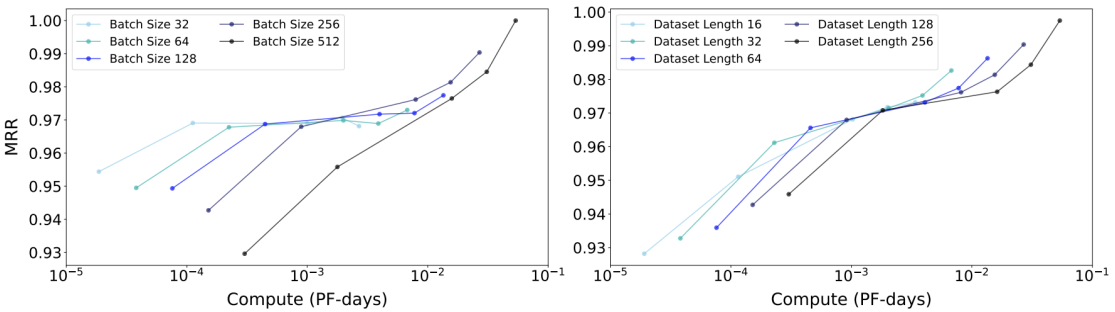
위 그래프를 보면 배치 사이즈가 작다면 Compute Resource를 투자해 모델 크기를 키워도 성능이 향상되지 않음을 알 수 있습니다. 다만 배치 사이즈가 크다면 모델 크기를 증가시켜 성능 향상이 가능합니다. 즉, Compute Resource는 데이터셋 길이보다 모델 크기에 먼저 투자하는 게 좋다는 것을 실험적으로 확인한 것입니다.
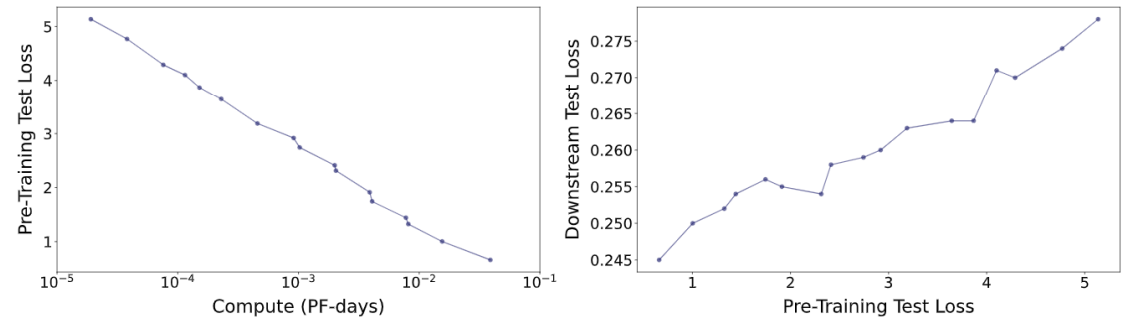
왼쪽 그래프를 보면 Compute Resources가 많이 투입될 수록 Test Loss가 linear하게 줄어든다는 사실을 확인할 수 있고, 오른쪽 그래프를 보면 Pre-text task의 test loss가 작다면 downstream의 test loss도 작은 경향이 나타남을 확인할 수 있습니다.

위 그래프와 표를 보면 더 많은 Epoch을 학습할 수록, 모델 사이즈가 클 수록 Downstream 성능이 향상됨을 확인할 수 있습니다. User Embedding의 Output Dimension이 Downstream 성능에 영향을 미치지 않는다는 것은 저장소 크기와 직결되는 문제이기에 자원 절약에 큰 도움이 되는 결과라고 할 수 있습니다.
CLUE에서는 model size를 키우고 compute resource를 투입해 그에 상응하는 충분한 성능 향상을 확보할 수 있음을 확인했습니다. 또한 단일 서비스 로그가 아닌 다양한 서비스 로그를 텍스트화에 학습에 사용했기 때문에 다양한 domain과 system으로의 효과적인 transfer가 가능하다는 의미이고 이는 모델에게 매우 큰 확장성을 부여합니다.
실제 Business에서의 Transfer Learning을 활용한 유저 임베딩
마지막으로 이러한 연구들이 실제로 사업에 활용될 때의 형태, 결과 등에 대해서 알아보고 글을 마치도록 하겠습니다. 주요 task는 유저의 특징을 파악하는 유저 임베딩입니다. 다시 말해 word2vector처럼 각 유저를 나타내는 vector가 해당 유저의 특징을 담고 있도록 하는 임베딩하는 과정입니다.
유저 피처

https://tv.naver.com/v/23650477
유저 피쳐는 각 유저을 특징을 포함하며 각 유저를 지칭하는 vector를 의미합니다. 여기서 비즈니스 모델을 하나의 거대한 foundation model이라고 생각하시면 될 것 같습니다. 이 비즈니스 모델은 기본적으로 서비스 기록을 이용해서 유저의 범용적인 피처를 추출합니다. 이 유저 피처는 100 ~ 1000 차원 정도의 실수 벡터의 형태이며 이 실수 벡터를 여러 downstream에 적용하여 각 서비스에 맞게 활용하게 됩니다.

https://tv.naver.com/v/23650477
위 그림은 앞선 방식과 비슷한 방식으로 downstream 데이터 자체의 과거 기록을 이용하여 유저 피처를 추출하는 과정을 나타냅니다. 이 방식으로 추출한 유저 피처는 downstream task에 더욱 특화된 피처가 될 것입니다. 따라서 앞서 추출한 피처와 결합하여 최종적인 유저 피처를 형성하고, 이를 각 서비스에 활용합니다.
유저 임베딩 시각화
위 방식으로 추출한 유저 피처를 2차원으로 시각화한 자료입니다.
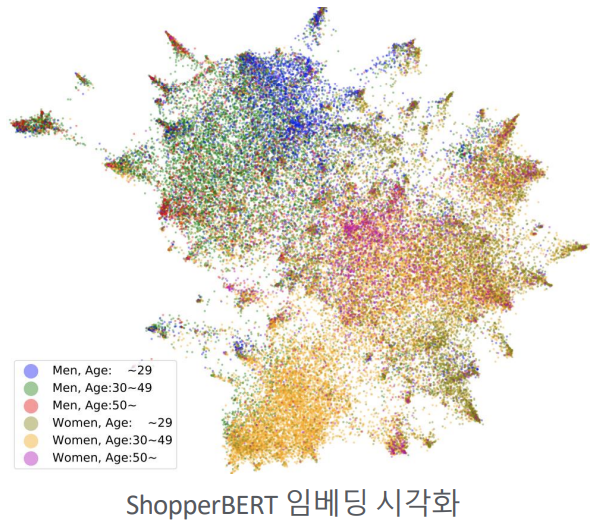
ShopperBERT: https://tv.naver.com/v/23650477
ShopperBERT로 임베딩된 결과를 보면 성별, 나이로 cluster가 형성되는 형상임을 확인할 수 있습니다.

CLUE: https://tv.naver.com/v/23650477
CLUE로 임베딩된 결과도 마찬가지로 대체적으로 cluster가 형성되는 것을 확인할 수 있습니다.

CLUE: https://tv.naver.com/v/23650477
위 word cloud는 특정 클러스터에서 구매한 상품들의 핵심 키워드를 나타낸 것입니다. 운동 관련 단어들이 많은 것으로 보아 특정 주제로 유저들이 clustering된다는 것을 확인할 수 있습니다.
다른 서비스의 기록이 도움이 되는가?
앞서 살펴본 것처럼 CLUE에서는 서로 다른 다양한 서비스 기록을 받아 각종 downstream task로 이를 transfer할 수 있습니다. 따라서 Naver 내의 서로 다른 서비스 로그들을 서로 관계가 없어보이는 서비스에 transfer 해보았을 때 아래와 같이 성능이 향상된다는 것을 확인할 수 있습니다.
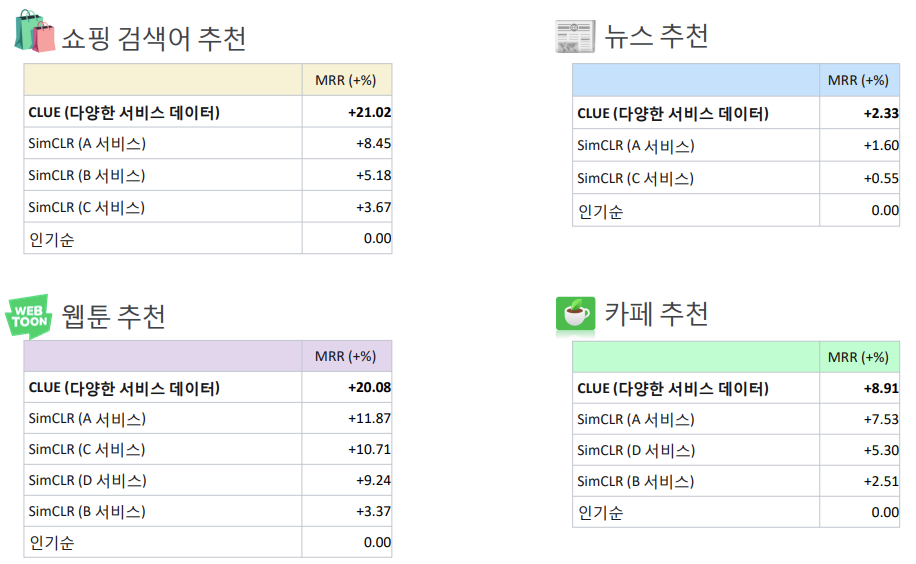
https://tv.naver.com/v/23650477
결론
오늘은 foundation model, transfer learning, 실제 비즈니스 (Naver)에서의 연구 및 실제 적용 결과에 대해서 살펴보았습니다. 현재 모델의 크기가 너무나 커져서 적절한 foundation model을 하나 학습시키는 것에 필요한 자원이 너무나 많은 실정이고 서비스에 사용하기도 적절하지 않아서, 학습 방법 등과 같은 학습 자체에 관한 연구들에 초첨이 맞추어지고 있습니다. 하지마 어떠한 서비스든 높은 성능을 위해서는 공개된 foundation model을 통한 transfer learning을 수행하는 것이 필수가 된 만큼 foundation model에 관한 연구는 지속될 것이라 생각합니다. 혹시나 딥러닝 관련 challenge나 딥러닝을 이용한 task를 수행하고 계시다면 거대한 데이터셋을 이용해 큰 모델을 학습시킨 후 transfer learning을 시도해보시거나 foundation model을 활용한 transfer learning을 시도해보시는 것을 추천드리며 글을 마치겠습니다.