RandomMix: A mixed sample data augmentation method with multiple mixed modes
RandomMix: A mixed sample data augmentation method with multiple mixed modes
RandomMix는 2022년도 5월 난징대에서 연구하여 arxiv에 공개된 data augmentation 논문입니다. 꽤나 최근에 나온 논문으로, 논문 자체의 내용이 크게 어렵지 않으면서도 지금까지 발표된 여러가지 mixed sample data augmentation들에 비해 높은 성능을 보여 SOTA를 달성했습니다. 뿐만 아니라 이미지의 robustness, diversity, cost의 관점에서도 좋은 향상을 보여주어 살펴볼 필요가 있는 논문입니다.
들어가기에 앞서, 본 글은 해당 논문을 그대로 번역하는 것이 아닌 관련된 다른 논문들의 설명을 추가하며 RandomMix 및 여러 data augmentation과의 비교 및 동향등을 함께 정리한다는 점을 말씀드립니다.
Abstract
Data augmentation 기법은 뉴럴 네트워크의 generalization을 높여주어 학습 과정에서 학습 데이터 세트에 overfitting하는 경우를 막아주는 역할을 한다는 것이 실험적으로 보여져왔습니다. 특히, Mixup의 등장으로 두 가지 이상의 이미지를 섞어내는 Mixed Sample Data Augmentation(MSDA)가 화두가 되었으며, 굉장히 높은 성능을 보여 주목을 끌었습니다. 이 과정에서 두 이미지를 라벨 비율대로 섞는 Mixup(2017), source image에 target image를 섞는 Cutmix(2019) 등이 굉장히 큰 주목을 받아왔습니다(Mixup, Cutmix에 대한 간단한 설명은 이전에 포스팅한 SaliencyMix에서 확인하실 수 있습니다).
이러한 MSDA 기법의 성능을 향상하기 위해서 최근 논문들에서는 이미지의 saliency region을 확인하고, 해당 영역들을 mixed image에 최대한 남기려는 형태의 노력이 많이 이루어졌습니다. 이전에 제가 소개했던 SaliencyMix도 같은 이유로 saliency area를 남기는 형태로 mixing하고, cutmix의 label mix 방식을 따르는 방식이었죠. 최근에는 Saliency Map을 이용하는 것 뿐만 아니라, Class Activation Map(CAM)을 활용하는 형태의 논문이 나오기도 했습니다(SnapMix, 2021). 결국에 이러한 시도들도 모두 기존에 제시되었던 MSDA 기법들의 label mixing 및 image mixing에서 납득되지 않는 mixing 결과를 개선하기 위한 형태로 적용된 것으로 볼 수 있습니다.
그러나 이 논문은 MSDA의 최근 동향인 saliency information을 이용하는 형태의 기법들의 cost에 주목합니다. 기존의 Mixup의 경우는 두 이미지를 얼마의 label 비율로 섞을 것인지에 대한 lambda를 beta distribution을 통해 구하기만 하면 바로 mixing이 가능해서 이미지 크기만큼의 시간으로 바로 구할 수 있어 전체 학습 시간에 영향을 거의 미치지 않았습니다. 마찬가지로, CutMix의 경우도 주어진 target image를 어느 영역을 사용할 것인지, source image도 어느 영역을 사용할 것인지에 대한 random한 좌표만 정해지고나면 mixing에서는 큰 시간이 들지 않아서, 적용하더라도 학습 시간이 달라지지는 않는 장점이 있었죠.
그러나 최근에 등장한 기법들은 달랐습니다. 기본적으로 Saliency information을 구하기 위해서 pre-trained된 모델을 사용하여 주어진 이미지의 saliency map을 구하고, 이 중 어떤 영역이 saliency한지 saliency area를 찾아내야 했습니다. 이전에 다루었던 SaliencyMix 또한 이를 구해야하는 점으로 인해 기존의 방법들보다 time efficiency가 조금 떨어진다는 점이 논문에 나와있었습니다.

그러나 SaliencyMix는 Saliency Map을 구하는 과정에만 시간을 조금 사용하고, 이후에는 주어진 Saliency Map에서 가장 높은 값을 가지는 위치를 argmax를 통해 얻어내어, 해당 좌표를 이용하는 CutMix와 동일하게 진행되기 때문에, 다른 시간은 많이 필요하지 않아서 꽤나 빠른 편에 속합니다.
더욱 높은 성능을 보여주면서 Saliency information을 사용하는 논문들로는 PuzzleMix(ICML 2020)와 Co-Mixup(ICLR 2021 Oral) 등의 논문이 있습니다. 위 논문들은 그냥 Saliency Map을 구하여 해당 정보를 사용하는 것 뿐만 아닌, image를 mixing하는 과정에서 saliency area의 손실, 영역의 겹침 등을 고려하여 최대한 saliency area를 살리면서 새로운 mixed image를 생성합니다. 또한 Co-Mixup의 경우, 기존의 방법들처럼 두 개의 이미지를 섞는 방식이 아닌, 3개 이상의 이미지를 섞을 때에도 saliency information을 고려하면서 섞을 수 있는 알고리즘을 고안하였고, 그 결과 앞선 여러 MSDA 기법들에 비해서 뚜렷한 성능 향상을 보여주며 해당 시점의 SOTA를 찍어 ICLR 2021의 Oral presentation으로 선정되는 결과를 보여주기도 하였습니다. (두 논문의 자세한 동작 원리 및 contribution은 더 있으나, 지금은 Saliency information을 활용한 기법이라는 점에 초점을 맞추도록 하겠습니다. 자세한 내용은 논문을 살펴보시면 좋습니다)
그러나 해당 논문들은 이미지를 섞는 과정에서 정보의 손실을 최대한 줄이기 위해 많은 time cost가 사용된다는 단점이 있습니다(실제로 해당 기법들을 사용해보았을 때, PuzzleMix는 Mixup 대비 약 2배 정도, Co-mixup은 2~3배 정도의 시간이 소요되었습니다). 물론 Co-Mixup 등의 논문에서도 time efficiency가 떨어진다는 점을 인지하고, 해당 알고리즘을 brute-force하게 구현하는 것보다는 훨씬 더 빠르도록 optimize를 거쳐 소요 시간을 줄였으나 단순한 형태의 mixing보다는 느릴 수 밖에 없었습니다.
이러한 관점들에서 최근에는 cost efficiency를 추구하는 형태의 여러 논문들이 게시되기도 하였으나, 꽤나 많은 수의 논문들이 기존의 mixup, cutmix 혹은 단순한 형태의 enhanced MSDA보다는 성능이 높으면서 빠르게 동작하는 것을 보여주고, 자신들이 가진 논문의 contribution으로 성능의 SOTA보다는 이외의 것들에 초점을 맞추어 설명하는 경우들이 있었습니다. 즉, Co-Mixup보다도 더 성능이 좋으면서 빠른 논문들을 찾아보기가 쉽지는 않았습니다.
이러한 상황 속에서, 저자들은 자신들이 기존의 Saliency information을 사용하는 논문들에 비해 굉장히 빠르게 동작하면서도, accuracy, robustness, diversity 등 여러 방면에서 기존보다 효율적인 RandomMix를 제안합니다. 심지어 논문에서 말하는 table만 확인하면, 기존의 PuzzleMix, 심지어 Co-Mixup보다도 더 성능이 뛰어나다고 이야기합니다. 더욱이 RandomMix는 이미지를 mixing하는 파이프라인이 굉장히 간단하여 어떤 모델들에서도 매우 쉽게 적용할 수 있다는 강점을 가지고 있음을 말합니다.
Method
기존의 Mixup의 경우, 두 개의 source image와 target image를 준비하여, beta distribution에서 얻은 lambda 값에 비례하여 각각의 이미지를 pixel-wise하게 비율대로 섞는 방식으로 구현됩니다.
그리고 CutMix의 경우, 이러한 Mixup의 방식과 특정 영역을 모두 black으로 바꿔버리는 Cutout을 합친 방식으로, target image의 영역을 source image의 랜덤한 위치에 삽입하는 방식으로 새로운 이미지를 만들어냅니다.
그리고 여기서 CutMix가 가진 단점을 보완하는 논문인 ResizeMix(2020), FMix(2021)에 대해서도 알아야합니다.
사실 RandomMix가 가지는 가장 큰 contribution을 이해하는 것에는 위 논문들을 정확하게 이해해야 하는 것과는 거리가 있기 때문에, 간단히 설명하고 넘어가도록 하겠습니다.
ResizeMix
ResizeMix는 CutMix가 가진 가장 큰 단점을 해결하려는 노력에서부터 아이디어가 시작합니다. 이전 SaliencyMix의 경우, CutMix를 개선할 때에 기여한 가장 큰 contibution은 다음과 같습니다.
- 기존의 CutMix의 경우, target image에서 엉뚱한 영역을 잘라서 source image에 붙일 경우, 의미없는 이미지 mixing이 일어남과 동시에 label ratio도 망가진다.
SaliencyMix는 이 점을 target image에서 Saliency한 영역을 찾아서 이미지를 잘라내는 방식으로 CutMix의 단점을 개선하였습니다.
그러나 ResizeMix는 CutMix를 진행하는 과정에서, target image에서 잘못 이미지를 잘라내는 경우를 방지하기 위해서, source image의 Cutout된 영역 자체에 target image 자체를 해당 크기대로 resize하여 붙여넣는 방식을 제안합니다.
이 과정에서 ResizeMix는 기존의 MSDA 기법들이 중시하던 Saliency information을 활용한다는 것이 과연 중요한 것일지부터 확인하면서 시작합니다. 기존의 문제가 되었던 부분들을 실제로 다음과 같은 영역들로 구분하면서 실험을 진행합니다.
source image/target image의 patch를 선정하는 과정에서
- Non-saliency region
- Saliency region
- Random region
이렇게 3가지 경우로 나누어서 각각의 경우들을 매칭하면서 결과를 확인합니다. 이를 통해 얻은 결과는 우리의 예상과는 다르게도, random한 영역의 target patch를 random한 영역의 source patch에 붙여넣을 때가 가장 성능이 좋다는 것을 보여주면서, saliency information을 활용하는 것이 크게 의미없다는 것을 실험적으로 보여줍니다.

이를 통해, ResizeMix의 저자들은 Saliency information을 활용하려는 시도들이 MSDA에서 크게 중요하지 않다는 것을 주장합니다. 그러나 실험 결과에서, Non-saliency region을 사용하게 되는 경우는 label의 misallocation을 유발하게 되어, 결과적으로 no labeled object에 label을 부여하는 경우가 발생할 수 있어서 결과에 악영향을 줄 수 있다는 점을 이야기합니다.
그 결과, CutMix를 진행하되, 정보가 없는 영역이 mixing되는 것을 예방하면서 굳이 saliency area를 선정하지 않아도 된다는 점을 착안해, target image를 그대로 resize하여 모든 정보를 source image patch에 넣어주는 방식인 ResizeMix를 제안합니다.
실제 실험 결과에서 ResizeMix는 SaliencyMix, PuzzleMix보다도 더 높은 Top-1 accuracy를 보이면서 성능이 향상되었다는 점을 저자들은 주장합니다.

FMix
FMix는 2020년도에 arxiv에 등록된 논문입니다. 사실 FMix는 그 자체를 모두 이야기하기에는 다루어야하는 내용이 꽤나 많은 논문입니다. 저자들의 기존의 MSDA에 대한 문제 인식 및 동기, 그리고 contribution에 대해서 이야기할 거리가 많습니다. 그러나 본 포스트에서는 RandomMix에서 사용하는 기법 중 하나라는 것 이외에는 FMix에 대해서 크게 다루지는 않을 예정입니다. 그 이유는 제가 처음 FMix를 읽을 때에도 의심되는 부분이었으며, 결과적으로 FMix가 ICLR 2021 blind submission에서 reject 되기도 한 이유인 성능의 개선 및 결과 분석의 신빙성 때문입니다. 물론 FMix가 가지는 contribution이 굉장히 중요하고 큰 의미를 가질 수도 있습니다. 그러나 많은 리뷰어들이 성능의 개선이 크지 않다는 점, 방법론과 결과 분석의 논리적 연결이 약하다는 점을 의심했고, 결과적으로 분석 과정의 근거 및 설득력에 의구심을 가져 reject를 받았습니다. 물론 아닐 수도 있으나, 검증이 크게 되지 않고 성능 또한 크게 개선되지 않은 논문을 다루는 것이 큰 의미가 있을지에 대해 확신할 수 없기 때문에, FMix의 방법론 정도만 다룬 후 넘어가겠습니다.
FMix 논문은 결과적으로, CutMix의 경우 cutting할 image patch를 결정할 때 정사각형 혹은 직사각형의 모양으로 잘라서 붙여넣게 됩니다. 그러나 FMix의 저자들은 CutMix의 기존 방식처럼 사각형 모양으로 자르는 것이 아닌 임의의 mask를 만들어서 해당 mask대로 source와 target image를 mixing하는 방법을 제안합니다.
이 때, 만들게 되는 임의의 마스크는 Fourier 공간에서 샘플링된 low frequency image에 임계값을 적용하여 얻는 임의의 이진 마스크를 사용합니다. 이러한 형태의 마스크는 결과적으로 다양한 형태로 만들어지고 데이터의 차원에 상관없이 적용 가능하다는 장점과 해당 마스크를 구하는 과정에서 특별한 time cost가 발생하지 않는다는 장점이 있어, 매 훈련마다 다양한 형태의 이진 마스크를 만들어서 여러가지 adversarial attack에 대해 강건성을 가질 수 있다고 이야기합니다.
이러한 접근은 기존의 네모난 형태의 mask를smooth하게 만들어서 모델의 robustness를 증가시키려는 노력을 한 SmoothMix과 비슷하게 느껴질 수도 있습니다.
결과적으로 FMix의 형태가 어떤 식으로 합성되는지 이미지를 보여드리는 것으로 넘어가겠습니다.

RandomMix
이제 대방의 RandomMix가 적용되는 방법론에 대한 이야기를 할 차례입니다. 사실 어떻게 보면, 제가 확인한 바에 의하면 RandomMix의 경우도 conference 등에 제출되거나 peer review를 받은 상태가 아닌 것으로 알고 있습니다. 그 이야기는 곧, 과연 이 논문에서 다루는 내용의 증거 및 신빙성과도 연결될 수 있다고 볼 수 있겠습니다.
그러나 해당 논문에서 기여하는 알고리즘 자체가 굉장히 단순하면서도 결과적으로 지금까지 보여준 여러 높은 성능의 논문들보다 훨씬 좋은 결과를 보여주고 있습니다. 비단 accuracy 뿐만 아니라, robustness, time cost, diversity 등 다양한 관점에서 굉장히 좋은 성능을 보여주면서 기존의 MSDA 논문들의 연구 방향성을 다시 고려해볼 수 있도록 해주는 논문이기에 해당 내용을 알려드릴 필요성이 있다고 생각합니다.
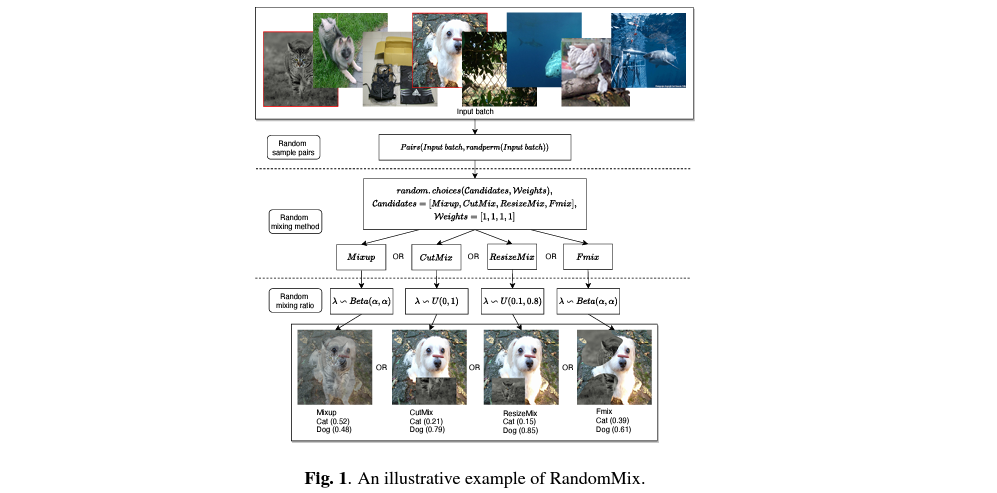
RandomMix의 목적은 모델이 adversarial attack들에 대한 robustness를 가지고, 동시에 training 과정에서 우리가 앞서서 이야기했던 Mixup, CutMix, ResizeMix, FMix 총 4가지의 방법들을 통해 만들어진 이미지 데이터 셋을 사용하는 걸 통해 훈련 데이터의 diversity를 증가시키겠다는 것입니다.
그 과정은 다음과 같습니다.
- RandomMix를 하는 과정에서, Mixup, CutMix, ResizeMix, FMix를 확률적으로 선택하고 선택된 data augmentation을 적용한다.
굉장히 심플하고도 간단합니다. 물론 이 과정에서 각각의 augmentation을 선택할 확률을 어떻게 주냐는 문제를 고민할 수 있겠으나, RandomMix 논문에서는 각각의 weight를 모두 1로 주었습니다. 이를 통해 random하게 선택된 augmentation을 적용하면서 학습 과정에서 이미지들에 서로 다른 data augmentation을 확률적으로 적용하겠다는 것이 RandomMix의 목표입니다.
이를 통해 더욱 다양한 형태의 train image들이 만들어지면서 diversity가 증가하게 되는 결과를 낳고, 이를 통해 robustness와 accuracy의 향상도 기대하면서 RandomMix의 실험이 진행됩니다. 또한 저자들이 선택한 4개의 방법론 모두 time cost가 거의 없기 때문에, RandomMix의 경우도 굉장히 빠르게 동작한다는 것을 알 수 있고, 특별히 계산하거나 적용해야하는 제한 조건이 없기 때문에, 어떠한 모델과 파이프라인에도 적용할 수 있다는 장점이 있습니다.
이제 이러한 기법을 적용한 RandomMix의 결과를 살펴보겠습니다.
Experiment
실험은 다음과 같은 2개의 파트로 나누어서 진행됩니다.
- CIFAR / ImageNet Dataset에 대한 Generalization Performance
- CIFAR-100에서의 Robustness Test 및 Tiny-ImageNet에 대한 Diversity experiment
Generalization Performance
CIFAR-10/100
32x32 픽셀의 이미지들로 구성된 CIFAR-10과 CIFAR-100 dataset에 대해서는 PreAct-ResNet18과 WideResNet-28-10 모델을 사용하여 학습을 진행합니다. 실험 조건은 두 데이터 셋에 대해 모두 동일하게 했으나, 사용한 모델에 따라서 4가지 MSDA의 선택 weight를 다르게 주었습니다.
공통된 실험 조건은 다음과 같습니다.
- 200epochs train
- 256 batch size
- SGD optimizer
- 0.1 learning rate
- 0.9 momentum
- 5e-4 weight decay
- α = 1
그리고 PreAct-ResNet18의 경우, (Mixup, CutMix, ResizeMix, FMix)의 weight를 모두 (1, 1, 1, 1)로 주었으나, WideResNet-28-10의 경우, (Mixup, CutMix, ResizeMix, FMix)의 weight를 (3, 1, 1, 1)로 주어, 50%로 Mixup을, 50%로 나머지 augmentation 방법들이 동일한 비율로 선택되게끔 만들었습니다.
이러한 조건 아래에 실험 결과는 다음과 같습니다.
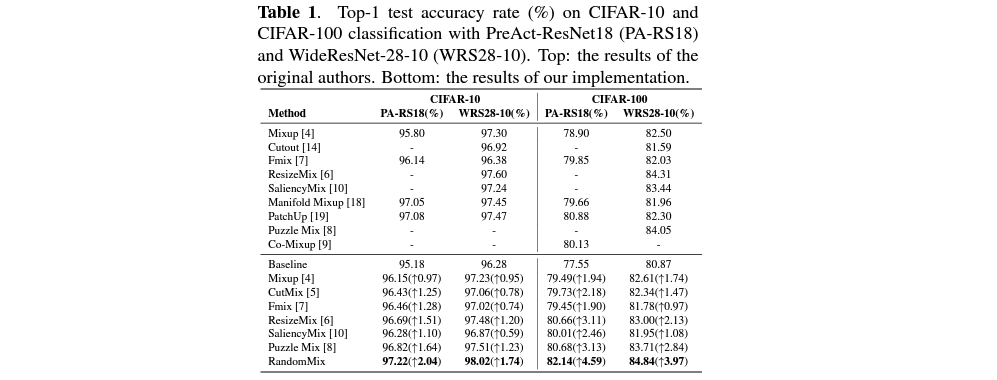
결과를 살펴보면 RandomMix가 기존의 굉장히 성능이 높았었던 여러 MSDA 기법들보다 성능이 꽤나 많이 향상되었다는 것을 볼 수 있습니다. 그러나 해석하는 과정에서 우리는 각 논문들이 도출해낸 결과도 함께 살펴봐야 합니다. 예를 들어, ResizeMix의 경우 해당 논문에서는 PuzzleMix보다도 좋은 결과를 냈다는 결과를 보여주었지만, RandomMix 논문에서는 PuzzleMix보다 모든 부분이 좋지 않다는 점 등이 있습니다. 이는 실험에서의 configuration 등에 대한 부분이 달라서일 수도 있으나, 결과의 신빙성 등에 대해서도 우리가 심도있게 살펴볼 필요가 있음을 시사합니다.
일단 해당 논문의 결과만 살펴본다면 PuzzleMix보다는 좋은 결과를 냈다는 것을 확인할 수 있습니다. 왜 original author의 결과를 보여줄 때에는 Co-mixup이 들어가 있는데, reproduced result를 공유할 때에는 넣지 않았는지 의문이기는 합니다. 그러나 전반적으로는, 굉장히 단순한 관찰과 아이디어를 사용했는데 결과의 향상이 보인다는 점이 긍정적입니다.
ImageNet/Tiny-ImageNet
ImageNet experiment에서도 앞선 configuration과 동일한 셋팅을 사용합니다. 다만 학습하는 모델이 이번에는 PreAct-ResNet18만 사용한다는 차이점이 존재합니다. 각각의 4가지 MSDA의 적용 비율도 기존과 동일합니다.

ImageNet test에서도 다른 MSDA들에 비해서 성능 차이가 꽤나 유의미하게 난다는 사실을 볼 수 있습니다. RandomMix에 적용한 4개의 data augmentation 기법들보다도 더욱 성능이 향상되었다는 것이, 여러개의 data augmentation 기법을 랜덤하게 사용하는 것이 효과가 있다는 것을 실험적으로 보여준다고 볼 수 있습니다.
또한 해당 표에는 Cost에 대한 부분의 비교도 들어있음을 확인할 수 있습니다. Cost에 대한 항목은 바로 time cost에 대한 내용으로, 기존 baseline에 비해 얼마나 느리게 동작했는지 비율을 보여줍니다. PuzzleMix의 경우, baseline 대비 2배 이상 느린 것을 확인할 수 있으나, RandomMix는 1.01배로 기존과 거의 동일하다는 것을 알 수 있어, 시간 효율도 높다는 것을 확인할 수 있습니다.
Robustness & Diversity
Robustness
Robustness experiment에서는 WideResNet-28-10을 CIFAR-100 dataset에 적용하여 진행합니다. 이와 동시에 해당 dataset에 adversarial noise, natural noise, sample occlusion 등의 기본적인 robustness challenge에 사용하는 기법들을 적용합니다. 이 과정에서 Fast Gradient Sign Method(FGSM) attack을 적용하고, natural noise의 경우 CIFAR-100-C를 사용하면서 Corruption Error를 사용하여 natural noise robustness를 측정합니다. Occlusion robustness를 측정하기 위해 0으로 채워진 random occlusion block을 생성하여 샘플을 만듭니다.
그리고 각 4개의 data augmentation의 weight 또한 다르게 하며 성능을 측정합니다.
이에 대한 각각의 결과는 다음과 같습니다.

해당 표에서 설명하는 Mixed Mode란 mixing하는 과정에서 lienar mixed mode를 하는지 아니면 masked mixed mode를 하는지에 대한 부분입니다. 설명에 따르면 linear mixed mode의 경우, noise에 좋아지지만 occlusion에는 더 약한 결과를 보이며, masked mixed mode의 경우 이에 반대라고 합니다.
실제로 RandomMix는 위에 사용한 4개의 data augmentation을 각각 적용할 때보다 전반적으로 robustness가 향상된다는 것을 알 수 있습니다. 물론, Corruption error의 경우 Mixup이, Occlusion의 경우 ResizeMix가 가장 나은 성능을 보였으나, RandomMix가 이들에 비해 크게 부족하지 않으면서도, 그에 반해 다른 data augmentation들은 가장 높은 성능의 기법보다 성능이 한참 모자란 것을 확인할 수 있습니다.
또한, weight를 다르게 주는 것으로 각 Robustness의 성능이 다르게 나오는 것을 확인할 수 있습니다. 이는 아무래도 Mixup의 비율을 얼마나 높게 주냐에 따라서, 만들어지는 train image 중 Mixup으로 만들어진 이미지의 비율이 높은 상황에 따라 Robustness에 영향을 받는 것 같네요.
Diversity
Diversity experiment에서는 PreAct-ResNet18을 Tiny-ImageNet dataset에 적용하여 진행합니다.
Diversity에 대한 측정은 기본적으로 mixing을 할 때에 얼마나 많은 data augmentation들을 조합하여 사용하는 것이 accuracy performance 향상에 도움이 되는지 비교하는 실험입니다. RandomMix는 기본적으로 Mixup, CutMix, ResizeMix, FMix라는 4개의 MSDA를 사용하여 구현되어 있습니다. 그러나 만약 이 중 하나의 기법이 없는 것이 더 도움이 될 수도 있으며, 여러 기법을 조합하는 것이 성능 향상에 도움이 되지 않는다면, RandomMix의 contribution은 상당히 퇴색될 수 있습니다.
이에 실제로 정말로 여러 기법들을 random하게 선택하여 사용하는 것이 좋은지에 대한 실험을 진행합니다.
실험 결과는 다음과 같습니다.
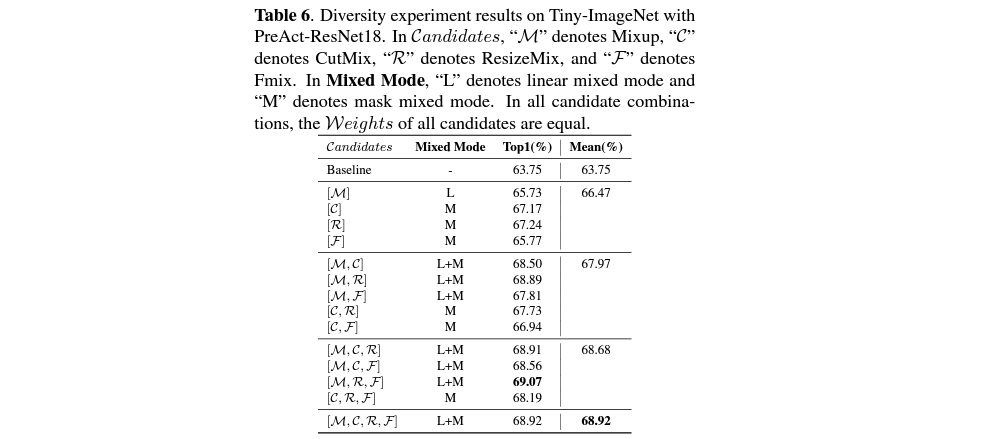
여기에서 denote를 설명한 대로, candidates는 Mixup, CutMit, ResizeMix, FMix를 의미합니다. 이들의 조합에 따라서도 달라지는 Top-1 performance에 대한 측정을 보여주고 있습니다.
해당하는 결과로 보면 data augmentation을 1개 혹은 2개를 사용하는 경우엔 baseline보다는 좋은 결과를 보여주지만, 모든 것을 다 사용하는 것보다는 좋지 않음을 확인할 수 있습니다. 그러나 이 중 3개를 선택하여 사용하는 조합의 경우, (M, R, F)를 사용하는 것이 가장 성능이 좋다는 것을 알 수 있습니다. 그러나 저자들을 몇 개를 선택해서 할 경우의 performance들의 평균값인 Mean value를 제시하며, best combination을 찾으려는 시도를 하기 어려울 때에는 모든 것을 그냥 다 선택해서 사용하는 것이 평균적인 performance를 향상시킬 수 있는 방법임을 보여줍니다.
실제로 RandomMix의 contribution 중 하나는 baseline과 비교하여 time cost가 크게 차이나지 않는 MSDA 방법을 제안하는 것도 있으므로, best combination을 찾는 일이 들어가는 것은 오히려 time cost적으로 손해일 수 있고, 모든 것을 사용하는 것이 평균적으로 나으면 그대로 사용하는 것이 좋다는 말도 틀린 선택이 아니라고 생각합니다.
마치며
이번 포스트에서는 올해 5월에 arxiv에 올라온 RandomMix에 대한 논문을 다루어보았습니다. 실제로 요새 많은 논문에서는 무작정 performance를 향상시키는 형태의 MSDA 논문들이 나온다기 보다는, 특정 영역에서 기존보다 더 나은 형태의 MSDA 논문들이 많이 나오고 있습니다. 또한 기존의 MSDA 논문들이 수학적, 통합적으로 증명된 바가 없다는 점에서 많은 의구심을 가진 목소리가 나오기도 하고, 이를 증명하는 형태의 논문이 발표되기도 하면서 기존과 같은 방식의 data augmentation paper는 쉽게 받아들여지기 어려울 수 있습니다.
또한 MSDA와 관련된 논문을 읽을 때에 주의 깊게 살펴봐야하는 점은, configuration, dataset, model등을 변경하는 것으로 논문들마다 table에 기재된 성능이 재각각일 수 있다는 점입니다. 이를 통해 특정 문제 상황에서는 오히려 좋지 않을 결과가 나올 수도 있음을 염두해두고 날카로운 시선으로 논문을 봐야할 것 같습니다.
소개한 RandomMix의 경우, 굉장히 단순한 형태의 기법을 적용하는 것으로 많은 부분에서 굉장히 좋은 퍼포먼스를 보여주고 있고, 이를 다루면서 알려드릴 수 있는 다양한 종류의 MSDA 기법들이 있어서 정리해보았습니다.
관심이 있으시다면 해당 논문을 직접 읽어보시는 것을 추천합니다.
Related Paper
1. RandomMix: A mixed sample data augmentation method with multiple mixed modes
2. ResizeMix: Mixing Data with Preserved Object Information and True Labels
3. FMix: Enhancing Mixed Sample Data Augmentation
4. Puzzle Mix: Exploiting Saliency and Local Statistics for Optimal Mixup
5. Co-Mixup: Saliency Guided Joint Mixup with Supermodular Diversity