Federated Learning And Split Learning
들어가며..
스마트폰이 나오고, 세월이 지나면서 누구나 스마트폰을 사용하는 시대가 되었습니다. 거기에, 스마트폰의 성능도 나날히 발전하면서 스마트폰에서 할 수 있는 일들도 점점 늘어났습니다. 기존에는 컴퓨터의 성능으로만 가능하던 인공지능의 학습 또한, 현재는 스마트폰으로도 가능해지는 시대가 되어가고 있습니다.
각자의 스마트폰으로 통신이 가능해지고, 인공지능의 학습이 가능해진 것은 큰 영향을 미쳤습니다. 기존에는 데이터를 전부 서버로 보낸 뒤, 서버에서 인공지능을 학습해야만 했습니다. 하지만 이제는 개인이 가진 스마트폰의 하드웨어를 이용하여 학습을 할 수 있게 되고, 언제 어디서나 통신을 할 수 있는 상황이 되어 학습의 형태가 변화하게 되었습니다.
이번 글에서는, 기존과 다르게 새롭게 나온 학습 방법인 Federated Learning과 Split Learning에 대해 간단하게 알아보려고 합니다. 각각의 학습 방식이 어떠한 방식으로 이루어지는지, 장점과 단점은 무엇인지 알아봅니다.
Federated Learning
Federated Learning 이란?
이전에는 인공지능 학습이라 함은 데이터를 갖는 노드와 학습을 하는 노드가 일치하기 마련이었습니다.
Federated Learning, 한국어로 연합 학습이라고 부르는 이 학습방법은 데이터 샘플을 교환하지 않는 채로 학습하는 모델을 의미합니다. 해당 학습 방식은 클라이언트가 서버로 부터 모델을 받은 뒤, 각자 개인이 갖고 있는 데이터로 학습을 진행하는 방식입니다. 학습을 진행한 후에는 학습된 모델의 매개변수만을 서버로 보내, cost를 절약하며 개인이 갖는 데이터를 보호할 수 있습니다.
실제로 학습이 어떠한 방식으로 진행되는지 그림을 통해 알아보고, 어떠한 알고리즘으로 진행되는지를 봅시다.
기존의 학습 방법
이전에는 서버에 데이터를 전부 보낸 뒤, 서버 측에서 학습을 진행하였습니다.
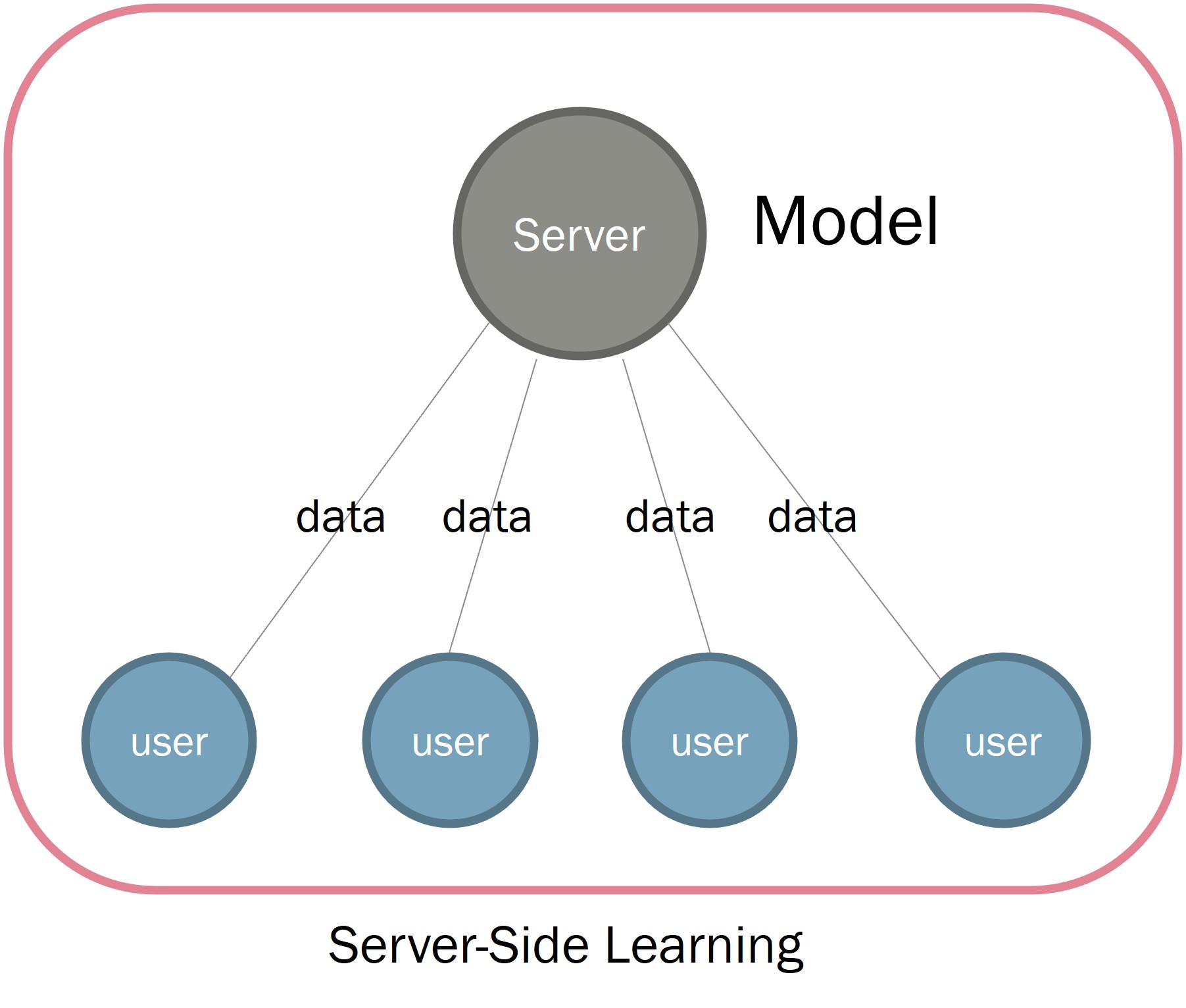
각 Client user들은 서버를 통해 자신이 갖고 있는 데이터를 송신합니다. 그리고 서버는 데이터를 받은 뒤, 서버에서 갖고 있는 모델을 학습시킵니다.
이부분은 굉장히 취약한 부분이 많습니다. 물론 기본적인 방법이기 때문에, Learning rate에 관한 문제는 모델만 따라가게 될 것이니 Accuracy도 잘 나올 것으로 예상됩니다.
하지만 큰 문제는 데이터를 서버로 보낸다는 점입니다. 이 정보가 남에게 공유해서는 안될 중요한 정보일 경우, 정보를 누군가와 공유한다는 자체만으로 프라이버시에 문제가 생기게 됩니다. 특히 최근에는 모든 정보 공유에 관해서는 허가를 받는 시대인 만큼, 이러한 정보를 어딘가에 송신한다는 것은 어려울 수 있습니다.
만약에 공유해도 되는 정보라고 해도 문제점이 없어지는 것은 아닙니다. Client User가 갖고있는 데이터의 수가 굉장히 많아, 서버에 보내야 하는 경우에는 비용이 추가적으로 발생하게 됩니다.
Fedrated Learning
Federated Learning은 여러 Client가 서버에 데이터를 전송하지 않습니다. 대신 서버에서 인공지능 학습 모델을 받아옵니다. Client user들은 서버에서 받아온 모델을 가지고 개개인이 가진 데이터를 이용하여 학습을 진행합니다.
이러한 방식으로 진행이 된다면, 각 User들은 같은 모델에서 시작하더라도 결국 다른 모델로 학습의 결과가 나타나게 될 것입니다. 또한, 여러 Client가 가진 데이터를 공유해서 학습하는 것이 아닌 개개인이 학습하는 결과가 됩니다. 이 문제들을 해결하기 위해서는, 각 User들이 학습시킨 모델을 합쳐주는 과정이 필요합니다.
다음의 사진을 통해서 방법에 대해서 이해를 해봅시다.
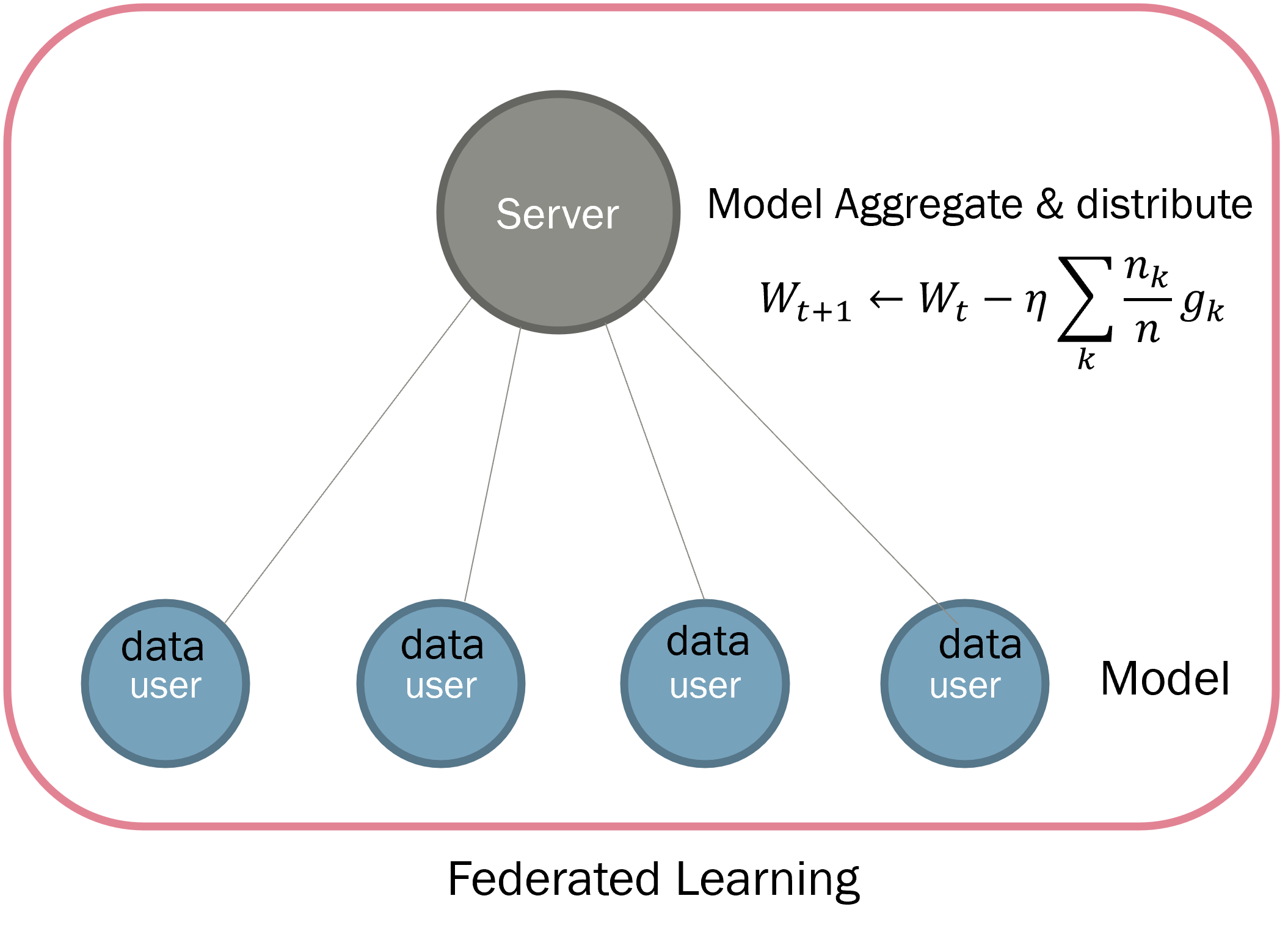
먼저 유저는, 각 학습 단위별로 Server에서 모델을 받아오게 됩니다. 그리고 이 모델을 이용하여 각 Client들은 개별적으로 학습을 진행합니다. 한 epoch의 학습이 완료된다면, 각 Client들은 처음에 받은 모델과 달라진 학습된 모델을 갖게 됩니다.
이 모델을 합치는 Aggregation은 기본적으로 각 Model에서 발생한 Gradient들을 각 Client가 학습한 데이터의 수로 가중치를 준 뒤, 서버의 모델을 학습하는 방법을 사용합니다.
학습이 완료된 뒤에 각 Client는 처음에 받은 모델과 학습이 완료된 뒤의 모델을 비교하여, 각 Client 별로 모델에 대한 gradient를 계산합니다.
그리고 이를 서버에 전송하여, 서버에서는 이 gradient들을 학습한 데이터의 개수로 가중치를 적용하여 학습을 진행합니다.
위와 같은 방법을 사용하여, 각 Client들이 데이터를 Server에게 넘겨주지 않은 채로, Server에서는 모델을 학습시키는 방법이 제안되었습니다
Federated Averaging
위에서 알아본 Federated Learning은 기본적인 형태입니다.
그렇기 때문에, 문제 부분들은 각 Client 부분에서 모델의 변화량, 즉 gradient를 계산해야한다는 문제점이 있습니다. 각 Client들(예를 들어 스마트폰, IoT 장비)이 인공지능에 대한 학습이 가능하다고는 하더라도, 그 외로 모델의 Gradient를 계산하는 것은 추가적인 비용이 소모됩니다.
이러한 문제점을 해결하기 위해서 나온 기법은 Federated Averaging 으로, 기본적인 알고리즘은 다음과 같습니다.

위 사진을 통해서 Federated Averaging을 이용한 알고리즘을 사용했을 때 달라진 부분은 Server Executes 에서 제일 마지막 줄과, ClientUpdate 쪽에서 마지막에 Server로 return하는 값입니다.
먼저 ClientUpdate 측면을 먼저 보면, 각 Client는 각 Update가 종료될 떄 Gradient가 아닌 모델 w를 return하는 것을 볼 수 있습니다.
그러면 서버에서는 이 서버 $k$에서 학습한 모델 $w_{t+1}^k$들을 가지고 어떻게 학습하는지를 보아야 합니다. 실제로 서버에서는 각 Client들의 모델을 받아, 모델에 가중치를 매겨 평균을 매기는 방식을 활용합니다.
기존의 Gradient를 사용하는 방법은 모델의 차이를 활용하는 부분이었습니다. 기존의 모델과, 학습이 완료된 모델 간의 격차를 계산하는 방식이었습니다.
그렇기 때문에, 위 사진과 같이 Server에서 Model Aggregate하는 과정에서는 다음과 같은 수식을 통해서 각 Client의 모델을 가중치 평균 매기는 것으로 계산할 수 있습니다.
\[w_{t+1} \leftarrow w_{t} - \eta \Sigma_{k=1}^K { n_k \over n} w_{t+1}^k\] \[w_{t+1}^{k} \leftarrow w_{t}^k -\eta g_k\]위 수식에서 $w_t$는 $t$번째가 완료된 뒤의 서버의 모델을 의미합니다. 그리고 $w_t^k$는 $k$번째 client가 t번째 학습을 완료하였을 때의 모델을 의미합니다.
이를 기준으로, 위의 두 식은 자명하게 만족하는 식이라고 할 수 있습니다. 아래족 식은, 새로운 $w_{t+1}^k$ 에 중요한 데이터입니다.
이를 동시에 적용하게 되면 $g_k$를 계산하지 않아도 사진 속의 알고리즘과 같이 공부할 수 있는 형태로 적용됩니다.
활용 예시
예를 들어, 구글의 Gboard 라는 어플리케이션이 있습니다. 구글의 Gboard는 키보드 어플리케이션으로, 검색을 하거나 컨텍스트를 활용하는 것들의 기록을 저장 및 학습에 사용합니다. 개인이 키보드를 사용하는 기록을 서버로 전송하는 부분은 꽤나 민감할 수 있습니다.
구글은 이러한 문제를 해결하기 위해서 Federated Learning을 사용합니다. 휴대폰에서 기록들을 로컬로 저장해둔 뒤, 학습을 진행합니다. 이전부터 이 기술을 사용하기 위해서 스마트폰에서 더욱 효율적으로 사용되도록 네트워크를 최적화하는 기술과 Federated Optimization에 대한 연구도 진행했습니다.
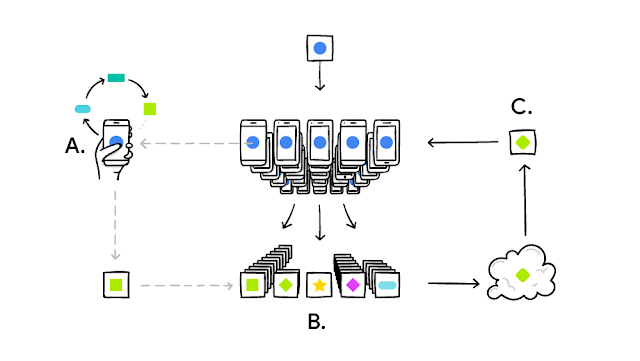
간단히 구조를 보면 다음과 같습니다. 스마트폰을 통해 활동하는 쿼리를 각각의 스마트폰에서 저장, 학습을 진행합니다. 그러나 스마트폰은 한정된 자원인 배터리를 갖고 있기 때문에, 즉각적으로 실행하는 것이 아닌 스마트폰을 충전기에 연결했을 경우 학습을 진행하는 방식을 사용한다고 이야기하고 있습니다.
이러한 Gboard와 같이, 서버로 보내기에는 조금 껄끄러운 데이터들을 활용한 학습을 할 때에 Federated Learning이 좋은 역할을 해준다는 것을 알아볼 수 있습니다.
Split Learning
Split Learning
Federated Learning은 모델 전체를 나눠준 뒤, 이를 통해 학습을 진행했다고 하면 Split Learning은 모델을 Split한 뒤, Splitted Model을 나눠준 뒤 학습을 진행하게 됩니다.
먼저 모델을 보기 전에, 학습 모델에 대한 이미지를 먼저 봅시다.

보통의 학습은 Client나 Server에서 학습할 때에는 모델 전체를 학습합니다. 하지만, Split Learning은 이 모델을 중간에 분리하여, 모델을 두개로 나누게 됩니다. Client용 모델과, Server용 모델을 나누어 Client와 Server가 반반을 나누어갖게 됩니다. 그렇게 되면, Client는 모델을 전체를 받는 것이 아닌, 학습 모델 중 중간 Layer까지만 받아서 학습을 진행하게 됩니다. 중간까지 학습을 진행하게 되면 원본 데이터는 알아볼 수 없는 상태가 되기 때문에, Smashed Data라고 부릅시다. Split Learning은 클라이언트가 Smashed Data를 만든 뒤, Server에게 이를 전송하는 식으로 학습이 진행됩니다.
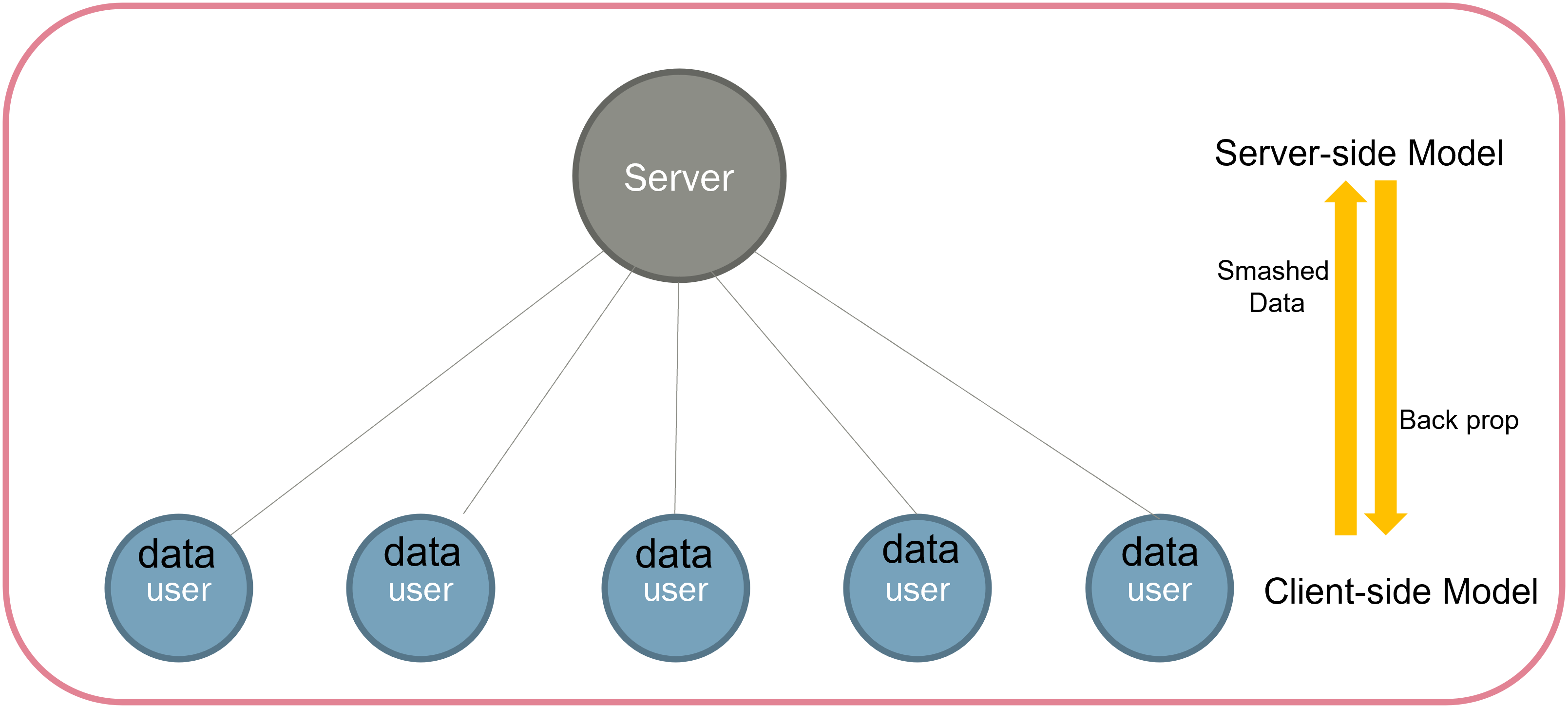
서버는 학습 모델의 중간 데이터인 Smashed Data를 Client로부터 받은 뒤, 서버가 가진 나머지 Layer에서 학습을 진행합니다. 그리고 이 결과를 가지고 Back propagation을 진행하는 것이 과정입니다. 실제로 이 과정이 일어난다는 것은 위 그림을 통해서 간단하게 이해할 수 있습니다.
굉장히 단순하게 보면, 기존의 Sever-side learning에서의 학습을 Layer를 기준으로 자른 뒤, 서버와 클라이언트가 나눠가진 것 뿐입니다. 그렇기 때문에, Learning rate는 기존의 학습과 동일하게 나오게 됩니다.
Federated Learning과의 다른 점
Split Learning은 기존의 Federated Learning과는 다른 구조를 가지고 있습니다. 기존의 Federated Learning의 문제점이라고 한다면, 모델을 직접 Client에게 제공한다는 점이었습니다. Client가 신뢰 가능한 대상일 경우에는, 모델을 직접 전달하는 것은 문제가 되지 않습니다. 모델을 신뢰할 수 없는 대상에게 제공하게 되는 것은, 모델에 대한 보안도 문제가 됩니다. 하지만 그 뿐만이 아닌, 학습된 모델을 통해 학습 데이터를 찾아내는 Inversion Attack에 안전하지 못하게 됩니다.
Inversion Attack으로부터 안전하지 못한 경우, 다른 학습 데이터를 찾아낼 수 있다는 문제가 발생할 수 있습니다. 이와 관련해서는 이전에 Differential privacy를 설명했었습니다. 이를 통해서도 막아낼 수는 있겠지만, 완벽하다고는 할 수 없을 것입니다.
대신에, Federated Learning은 모델을 각각의 Client가 갖고 있었기 때문에 개별적으로 병렬적인 학습이 진행되었다면, Split Learning은 다릅니다. 서버가 갖고있는 모델과 Client가 갖고있는 모델이 서로 별개이기 때문에, Client는 Server에 연결함과 동시에 Client-side Model을 받게 됩니다. 그 뒤에 Server와 Client가 1:1로 연결된 상태로 학습이 진행되게 됩니다. 학습이 마무리되고 연결이 끊어지기 전에, Client는 자신이 학습시킨 모델을 서버에 다시 돌려줍니다. 이러한 이유로, 여러 Client들이 동시에 학습을 진행할 수 없다는 단점이 있습니다.
마무리
이번에는 서버에 데이터를 전송하지 않고, 여러 Client들이 학습을 진행하는 방법인 Federated Learning과 Split Learning에 대해 알아보았습니다. 다음에는 이들의 장단점을 활용하고 합쳐서 만든 SplitFed와, 이전에 작성하였던 DP가 섞인 논문에 대해서 리뷰해보려 합니다.