Noise or Signal: The Role of Image Backgrounds in Object Recognition (ICLR 2021)
Noise or Signal: The Role of Image Backgrounds in Object Recognition (ICLR 2021)
Deep learning 분야에서, 모델의 generalization을 올리는 것은 굉장히 중요한 일입니다. Generalization이 떨어지는 모델의 경우, 주어진 학습 데이터에만 과적합하여 이외의 다른 데이터들에 대해서는 성능이 낮아지는 문제가 발생할 수 있으며, 주어진 train data들만이 가지는 특성들에 대해 큰 bias를 가지게 될 수 있습니다.
이러한 문제를 해결하기 위한 방법론들은 굉장히 다양한 접근들로 제시되어왔습니다. Train data를 건드리는 data augmentation들도 존재하고, train 과정에서 과적합되는 것을 방지하기 위한 sharpness-aware, flooding 등의 방법들도 존재합니다. 이러한 시도들은 더 많은 종류의 데이터를 모델에게 주어 generalization을 키우거나, 혹은 train 과정에서 noise들을 학습하는 것을 방지하는 등으로 개선 효과를 본다고 알려져 있습니다.
그러나 computer vision task를 하는 과정에서, 많은 경우에 효과를 본다고 알려져있는 generalization을 높이는 method들이 큰 효과를 보지 못하거나, 혹은 성능을 매우 크게 낮추는 경우들이 존재하는 것을 경험한 사람들이 꽤 많을 것입니다. 이러한 경우는 특히, 실험 환경에서 사용되는 benchmark dataset을 사용하는 경우가 아닌 실생활에서 얻은 dataset이나 혹은 medical 분야 등에서 경험적으로 꽤 많이 확인해보셨을 겁니다.
이에는 굉장히 다양한 이유들이 존재할 수 있습니다. 모델의 특성, 데이터 셋의 특성, 데이터의 수, 라벨의 수 등등 여러가지 원인들이 존재할 수 있지만, 그 중 하나로는 오늘 이야기할 foreground와 background도 그 이유에 포함되어 있을 수 있습니다.
Noise or Signal: The Role of Image Backgrounds in Object Recognition은 2021년 ICLR에 accept된 논문으로, 이미지를 학습하는 과정에서 모델이 라벨을 분류하는 과정에서 background에 얼마나 큰 영향을 받는지에 대해 연구한 논문입니다. 그 과정에서 알게되는 사실들은 우리가 만든 모델이 데이터 특성에 따라서 실제 foreground에만 집중하지 않을 수 있다는 것, 그리고 더 나아가서는 우리가 사용하는 여러가지 generalization 테크닉들이 실제로 효과를 볼 수 있을지에 대해 주어진 task에 따라서 많은 고민을 해야한다는 것을 확인할 수 있게 해줍니다.
Abstract
본 논문에서는 최신 object recognization model들이 주어진 이미지의 background signal에 얼마나 의존하는지에 대한 경향을 평가합니다. 기존의 모델들은 주어진 train dataset에 대해 학습하는 과정에서, 이들을 올바른 label로 분류하는지를 loss로 계산하고, 이 loss를 최소화하는 방식으로 학습됩니다. 그리고 이 모델을 이용해서 실제 test dataset을 분류하고, 실제 label과 얼마나 일치하는지를 사용해 accuracy를 구하게 됩니다. 이를 통해, 모델이 train dataset을 보고 학습하는 과정에서, test dataset의 label에 매치하여 이들에 대한 correlation을 generalizing하는 것으로 성능을 향상시킬 수 있습니다.
그러나 실제 모델이 학습하는 과정은 사용한 dataset에 따라서도 correlation이 의존적으로 변하게 됩니다. 즉, 어떠한 데이터를 사용하냐에 따라서 모델이 주어진 데이터에서 인지하는 것이 달라지게 된다는 것입니다. 이 과정에서 학습하는 것은 실제 사람의 인지와는 다른 것들일 수 있습니다.
예를 들어, 입력된 이미지의 질감이나 색감 등 실제 사람이 어떠한 object를 인식하는 것과는 거리가 먼 것들이 실제 label과의 correlation이 높다면, 모델들은 이에 bias를 가지고 학습하게 된다는 것입니다. 이러한 이유로 모델의 correlation 특성 의존성을 이해하는 것은 모델이 어떻게 동작하는지 이해하기 위해 필수적이라는 것을 알 수 있습니다.
이미지 background는 object 인식 과정에서 label과 굉장히 큰 correlation을 갖게 됩니다. 모델에만 해당하는 이야기가 아닌, 사람 또한 실제 background information을 사용하여 object를 인식한다는 것이 잘 알려져있습니다. 그러나 이러한 background information을 사용한다는 것은, recognition에서 굉장히 큰 힌트가 되기도 하지만, 어떠한 경우에는 주어진 환경, scene에 대해 너무나도 큰 bias를 가지게 되는 위험 또한 존재합니다.
이를 분석하기 위해, 이 논문에서는 vision task를 해결하는 모델들이 주어진 data background에 얼마나 큰 correlation을 가지고 인지하게 되는지를 다양한 방법들을 통해 분석합니다.
Method
Prior Experiment
실제 dataset을 사용하여 정량적으로 분석하기에 앞서, ImageNet-9를 기반으로 생성한 합성 데이터들을 ImageNet에 pretrained된 ResNet-50 모델에 넣었을 때에, 이들 label을 어떻게 분류하는지에 대해 간단한 실험 결과를 확인할 수 있습니다.

Figure 1을 보면 다음과 같은 8가지의 합성을 통해서 모델이 해당 이미지의 label을 올바르게 맞추는지 검증합니다.
- 실제 곤충 이미지
- 곤충의 background 이미지만 사용하고, foreground 영역은 검정으로 지움
- 곤충의 background 이미지를 사용하고, foreground 영역은 background로 채움
- 곤충의 background 이미지만 사용하고, foreground object는 검정으로 지움
- 곤충의 foreground 이미지만 사용하고, foreground obejct 이외에는 검정으로 지움
- 곤충의 foreground 이미지만 사용하고, background 영역은 다른 곤충 이미지의 background로 채움
- 곤충의 foreground 이미지만 사용하고, background 영역은 다른 라벨 이미지의 background로 채움
- 곤충의 foreground 이미지만 사용하고, background 영역은 다음 라벨 이미지의 background로 채움
이에 대한 결과로 실제 맞추게 된 결과는 figure 1에 나온 것처럼, 절반의 task에서 실패한다는 것을 확인할 수 있습니다. 이 중에서 실제로 foreground가 존재함에도 불구하고 실패하는 5, 8번의 경우도 존재합니다. 또한 어떻게 본다면, 4번 task도 실제 이미지에서 foreground의 영역 contour 자체는 나비 모양으로 생겼지만, 결과는 bird로 예측하는 2번 task와 다르지 않다는 것도 확인할 수 있습니다.
위 figure가 보여주는 background와 model prediction 사이의 관계는 다음으로 설명할 수 있습니다.
먼저, 2번과 4번 task에서는 foreground가 존재하지 않았음에도 불구하고 bird라는 label을 predict 했습니다. 이는 많은 경우에, 나무나 풀, 그리고 하늘이 있는 배경에서 새가 존재했기 때문에 생긴 bias로 볼 수 있습니다. 이 과정에서 foreground 자체만 확인했을 때에는 label을 확인하기 어려우니 background information에 맞춰서 편향된 것입니다.
그리고 5, 8번의 경우에는 온전히 foreground가 존재함에도 불구하고 나비인 insect로 분류하지 않은 이유를 굉장히 잘 확인할 수 있습니다. 이들 task에서 분류된 라벨은 instrument입니다. 이는 많은 경우, 악기들이 배경이 갈색이나 어두운 배경에서 찍힌 사진들로 구성되어있기 때문에, 검정색이라는 배경에 bias를 가져 이처럼 분류했음을 생각해볼 수 있습니다.
이제부터는 실제 많은 다른 label들에 대해서도 이러한 background information이 model에 얼마나 많은 영향을 주는지 확인하기 위해서 정량적인 분석을 위한 실험을 시작합니다.
Methodology
실제로 모델에서 image background information이 어떤 영향을 주는지 확인하기 위해서 ImageNet-9로부터 새로운 합성 데이터셋을 만듭니다.
- Base Dataset: ImageNet-9를 base dataset으로 사용합니다. ImageNet-9는 기존의 ImageNet에서 9개의 coarse-grained classes만을 사용한 데이터 셋입니다. 이를 만들어내기 위해서, 저자들은 ImageNet의 annotated bounding box가 존재하는 데이터들만 사용하여 실제 이미지의 foreground와 background을 분리하여 variation을 만들 수 있는 이미지들만 사용하여 각 label들에 대해 5045개의 training dataset과 450개의 test image들을 만들었습니다.
- Varations of ImageNet-9: 기존의 ImageNet-9에서 bounding box information을 사용하여, figure 1에서 선보여진 7개 종류의 variation을 만들어서 실험을 진행합니다.
- Lager Dataset: ImageNet-9L은 실제 모델을 학습하는 과정에서 모델의 generalization을 올리기 위해서, bounding box가 존재하지 않은 이미지들을 모두 포함한 총 9개의 라벨에 대한 ImageNet의 부분집합 데이터 셋입니다. 이를 사용하여 실제 모델을 학습시킵니다.

위 Table 1은 앞서 제가 figure 1에서 설명했던, 각 variation들이 어떤 식으로 만들어졌는지 설명하는 내용과 동일합니다.
이러한 데이터 셋들을 사용하여, 이젠 실제로 background signal이 어떠한 영향을 주는지 실험합니다.
Quantifying Reliance on Background Signals
Backgrounds suffice for classification
이번 실험에서는 background만 존재하는 데이터들만 사용하여 모델을 학습하고, 그 결과를 확인합니다. 여기에서 사용되는 variation들은 앞선 figure 1에서 이야기된 2, 3, 4번에 해당되는 경우들입니다.
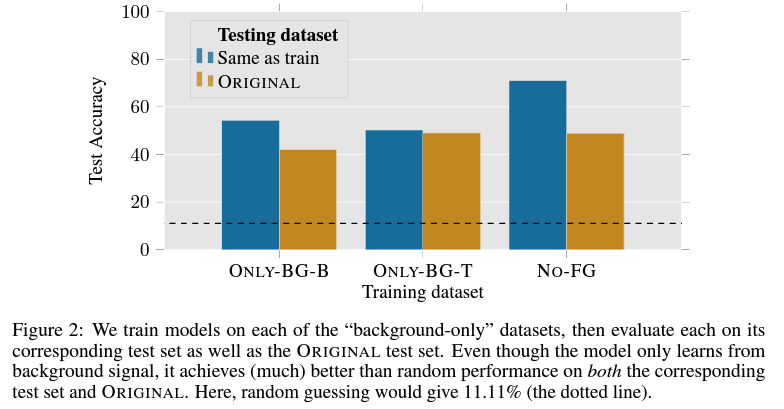
실제 실험 결과를 figure 2를 통해 확인하게 되면, 주어진 train dataset에서는 어떠한 foreground도 존재하지 않았지만, 이들만 사용한 데이터를 통해 학습한 모델이 모두 40% 이상의 정확도를 보여준다는 것을 확인할 수 있습니다. 전체 label이 9개가 존재한다고 생각하면, 이는 절대 random한 결과(random이면 약 11%의 정확도를 보여야 함)를 보이는 것이 아닌, 실제 background information만을 활용해도 test dataset을 꽤나 높은 확률로 맞출 수 있다는 결과를 보여줍니다.
이는 결과적으로, train dataset에서 가지고 있는 background information과 실제 test dataset에 존재하는 background information이 높은 correlation을 가지고 있다는 것으로 요약할 수 있습니다. 이러한 correlation을 가지고 있기 때문에, 실제로 foreground에 대한 정보를 모르고도, background를 사용하여 inference를 하는 것이 가능했습니다.
Models exploit background signal for classification

이번 실험에서는 foreground와 background를 실제 같은 이미지가 다닌 다른 이미지들끼리 섞어서 합성한 데이터 세트에 대해 test할 때에 어떠한 현상이 일어나는지 확인합니다.
Table 2를 확인하게 되면, 이번 실험에서는 2개의 모델을 사용하게 됩니다. 하나는 기존의 ImageNet에서 pretrained된 다양한 모델들, 또 다른 하나는 ImageNet-9L을 사용하여 학습한 모델들이 존재합니다. 그리고 실제 이들을 original imagenet, ImageNet-9, ImageNet-9L, 그리고 variation들에 대한 test를 할 때에 accuracy가 어떻게 되는지 확인할 수 있습니다.
결과를 통해 알 수 있는 점은, Only-BG-T의 경우처럼 background info만 존재하는 경우에도 상당히 모델이 잘 맞췄다는 것을 확인할 수 있는 점과(앞선 실험과 비슷한 결론), Mixed variation의 경우, 실제로 기존의 foreground는 전혀 건드리지 않고 똑같이 존재함에도 불구하고, background information이 변했다는 이유로 정확도가 낮아진다는 것입니다.
이 중에서도, 같은 label을 가지는 mixed-same보다 다른 label의 background를 가질 수도 있는 mixed-rand의 정확도가 더 낮다는 것을 통해, background information에 의해서 실제로 모델의 오분류할 가능성이 커진다는 것을 확인할 수 있습니다.
즉, 이 말은 곧 모델이 어떠한 object를 추정하는 과정에서 주어진 이미지의 background information 또한 함께 사용하여 추론하게 된다는 것입니다. 그러한 과정에서 background information에 대한 bias를 얻게 되어 큰 영향을 미칠 수도 있게 됩니다.
Models are vulnerable to adversarial backgrounds
Background information이 model에 얼마나 안좋은 영향을 미치는지 확인하기 위해서, 이번에는 적대적으로 선택된 background에 대한 모델의 robustness를 측정합니다. 이를 수행하기 위해서, 저자들은 각각의 foreground에 대해, 이 foreground를 다른 background와 조합했을 때에 해당 이미지를 background label로 추정하게 하는 foreground가 얼마나 많은지 확인합니다. 이를 한 결과, 총 87.5%의 foreground들이 자신과 매치했을 때, background로 예측하게 하는 background가 존재한다는 것을 확인할 수 있습니다.

figure 3의 경우, 보여지는 이미지들은 모두 꽃을 background로 가지고 있는, 실제 원본이 insect가 아닌 이미지들입니다. 이 중에서 label에 해당하는 foreground를 background로 채우는 adversarial backgrounds가 적용되었습니다. 그 결과로 실제 이 라벨을 가지는 이미지의 background information은 높은 확률로 insects로 분류될 정도로 높은 bias를 준다는 것을 확인할 수 있습니다.

figure 4는 반대로, 실제 insect 이미지의 background에 다른 label의 foreground를 가지는 이미지를 분류하는 과정에서, 실제 foreground를 insect로 분류하는 데 성공한 success rate와 그 counts입니다. 즉, 이는 다른 라벨의 foreground를 가지고도, 주어진 이미지가 background에 해당하는 insect로 분류하는 경우가 꽤 많이 존재한다는 것을 보여주어, adversarial하게 background에 영향을 받음을 확인할 수 있습니다.
Training on MIXED-RAND reduces background dependence
이번에는 foreground와 background의 label이 다른 경우인 Mixed-Rand가 얼마나 background dependence를 낮출 수 있는지에 대한 실험입니다. 이는 Mixed-Rand dataset으로 학습한 모델을 가지고 실제 여러 variation들에 대해 얼마나 robust한 test accuracy를 보이는지 확인합니다.
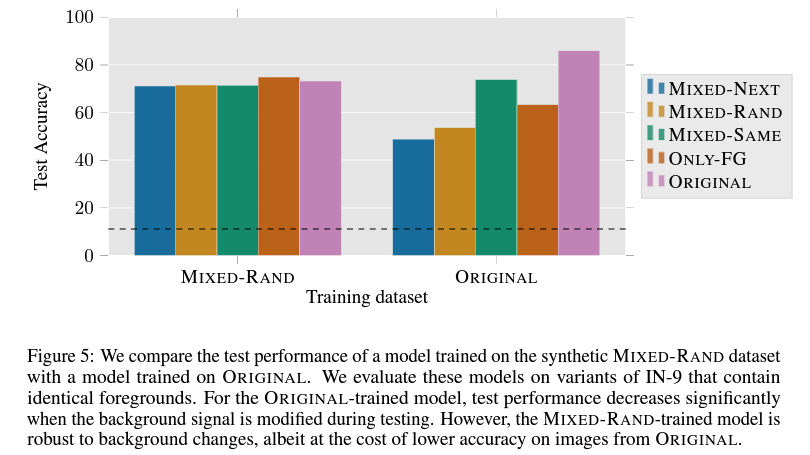
실제 위 figure 5를 확인하게 되면, foreground와 background를 mix한 dataset을 사용하는 것으로 variation들에 대해 평균적인 accuracy가 높고 그 편차가 크지 않다는 것을 확인할 수 있습니다. 이는 실제로 이러한 데이터 셋에서 학습된 모델의 경우, background robustness가 증가한다는 것을 확인할 수 있는 부분입니다.

이는 실제로 모델이 바라보게 되는 saliency map을 통해서 확인할 수 있습니다. mixed-rand model의 경우, 기존의 original보다 foreground에 더 집중해서 분류하고 있다는 것을 알 수 있습니다.
그러나 여기에서 조금 더 생각하게 되면, mixed-rand dataset을 통해 학습할 경우, 기존의 original data에 대해서는 accuracy가 떨어지는 것을 확인할 수 있습니다.
우리는 앞선 robustness를 증가하는 것 이외에도, 왜 이러한 현상이 일어났는지에 대해 살펴볼 필요가 있습니다. 우리가 여기에서 추론할 수 있는 결과로는, 결국에 background information에 robust한 모델이 실제로는 original dataset에서 성능이 떨어진다는 사실을 확인할 수 있습니다. 이는 어떻게 보면, 실제 data의 경우, background information을 활용하는 것이 주어진 foreground를 추론하는 과정에서 꽤나 효과적인 bias라는 것을 생각해볼 수 있습니다.
예를 들면, 우리가 어떠한 object가 A인지 B인지 foreground만 보고는 알기 어려운 경우를 생각해보겠습니다. 근데 만약, 여기에서 우리가 A는 물에서 살고, B는 땅에서 산다는 사실을 알고 있다면 어떻게 될까요? 우리는 헷갈리는 와중에도, 배경을 보고 만약 물일 경우 A로, 땅일 경우 B로 추론을 할 수 있을 것입니다.
이러한 경우가 바로 background information이 추론 과정에서 좋은 방향의 bias를 주는 경우로 생각해볼 수 있습니다.
Benchmark Progress and Background Dependence
이번에는 실제로 기본적인 computer vision benchmark에서 exploiting background correlation으로부터 robust해지기 위해서 어떠한 방식들이 존재해야하는지에 대한 실험을 공유합니다.

figure 8은 범례에 존재하는 여러 variation dataset들에 대해, 실제 ImageNet accuracy와 이러한 synthetic dataset에 대한 accuracy를 그린 그림입니다. 여기에서 확인할 수 있는 것은, ImageNet에서 학습한 모델의 accuracy가 높으면 높을수록, 실제 background adversarial한 attack에 대한 accuracy 또한 높아진다는 것입니다.
그러나 Only-BG-T와 같은 경우를 보면, background information만 존재하는 경우에도 label 분류 정확도가 함께 올라간다는 것을 확인할 수 있습니다. 이는 앞서 이야기한 것처럼, 모델의 성능이 증하갈 때에 background information 활용 또한 함께 올라간다는 것과, 이에 대한 bias를 같이 갖추게 된다는 것을 의미합니다. 이는 결국, 어떻게 보면 background informatino이 실제 inference 과정에서 큰 도움을 주고 있으며 이러한 정보가 존재해야만 높은 정확도를 가질 수 있다는 것을 시사하는 것으로 볼 수 있습니다.
Conclusion
결과적으로 우리는 classifier가 얼마나 이미지 background에 의존적인지에 대한 연구를 확인할 수 있었습니다. 그 결과로 모델은 adversarial한 경우나, 혹은 평균적인 경우에도 background에 robust하지 않다는 것을 확인할 수 있으며, 모델이 이러한 background를 활용한다는 것을 알 수 있습니다. 이는 실제로 모델에 대한 공격으로 background adversarial attack등이 들어올 때에 모든 이미지의 87.5% 정도가 이러한 background change에 의해 속을 수 있다는 것을 의미합니다.
그러나 많은 경우에, background information은 그 자체로도 모델이 정확한 추론을 하기 위해 많은 도움을 줄 수 있습니다. 비록 그 정보 자체가 bias에 의한 것일 수 있지만, 인간의 시각 처리와 비슷하게 background에서 정보를 추출하면 만약 주어진 foreground가 흐릿하거나 왜곡되는 등의 손상을 입은 경우에도, 어렵지 않게 추론하는 것이 가능할 수 있습니다.
그리고 해당 논문에서 제시한 foreground-background mixing 방법을 통해서, 이러한 adversarial한 attack에 robust한 classfier를 만드는 방법을 제시하여 더욱 robustness를 올리는 것도 가능함을 알 수 있습니다.
Personal Opinion
앞선 논문을 통해서 알 수 있는 것과, 실제 여러가지 데이터 셋을 통해 경험한 것은 바로, 모델이 이러한 background robustness가 절대 높지 않다는 것이며, 그리고 augmentation 등의 method를 사용할 때에 이러한 종류의 손상이 존재하지 않는지 고려해봐야한다는 것입니다.
실제로 medical dataset을 사용한 경우 중 기존의 data augmentation 기법이나, 혹은 이전에 소개했었던 simple copy-and-paste와 같은 기법으로 augmentation을 할 때에 오히려 성능이 감소하는 경우도 존재했었다는 것을 들은 적이 있고, 어떠한 task에 사용되느냐에 따라서 data augmentation 적용 여부가 달라지기도 한다는 점이 이러한 background information에 영향을 받은 경우일 수도 있다는 생각을 합니다.
항상 많은 논문들을 리뷰하면서도 작성하는 내용이지만, 언제나 논문들은 주어진 환경과, 많은 경우 정제된 benchmark dataset을 이용한다는 점을 늘 염두해두고 있어야 합니다. 이러한 것을 고려해서, 어떠한 요소들이 부작용을 주는지, 혹은 줄 수 있는지를 미리 생각해보고 적용하게 된다면 많은 경우에서 원인을 빠르게 찾을 수 있을 것입니다.