WiSE-FT: Robust fine-tuning of zero-shot models (CVPR 2022)
WiSE-FT: Robust fine-tuning of zero-shot models (CVPR 2022)
본 논문은 대규모 pretrained model에 대한 zero-shot model과 fine-tuning model의 장점을 결합하는 방식인 wiSE-FT를 제안합니다.
이에 대한 더 나은 이해를 위해, 먼저 zero-shot model이 무엇인지에 대해 이야기하고, 해당 논문이 어떠한 방법을 제안하여 해당 문제를 해결하였는지 소개하도록 하겠습니다.
Zero-shot model
zero-shot이란 모델을 특정 데이터 셋 A에 대해 학습시킨 이후, 이에 대한 다른 추가 train이나 fine-tuning 없이 바로 이와 다른 distribution을 가지거나 혹은 없는 라벨을 포함한 데이터 셋 B에 대해서 inference하는 것을 의미합니다. 결국 간단히 말하자면, zero-shot model은 해당 모델을 학습하는 과정에서 다루지 않았던 라벨이나 데이터, 혹은 더 나아가 다루지 않았던 task에 대해 사용하는 것을 의미하게 됩니다.
보통 일반적인 경우, zero-shot model은 좋은 성능을 내기 어렵습니다. 학습 과정에서 보지 않았던 데이터나 task를 다루기 때문에, 모델은 이것이 무엇인지 파악하기 어렵고 이에 대한 정확도가 많이 낮아지게 됩니다. 그래서 이러한 zero-shot이 가능한 모델들은 일반적으로 굉장히 큰 대규모 데이터 셋에 대해 학습한 모델들을 사용합니다. 많은 양의 데이터들을 학습하는 과정에서, 실제로 해당 데이터 셋에 존재하는 class들에 대한 정보를 잘 가지고 있으며, 또한 만약 inference 과정에서 입력으로 사용된 데이터가 학습 중에 사용된 적 없는 라벨이더라도 다른 라벨들과의 유사도 및 맥락에 대한 이해가 높아 random한 결과보도 훨씬 더 좋은 성능에 그치는 것이 아닌, 유의미한 정도의 성능을 보이는 것이 알려져 있습니다.
CLIP
이러한 zero-shot model로 사용되는 대표적인 예시로는 바로 CLIP(2021) 이 있습니다. CLIP은 약 4억개에 해당하는 image-text pair 데이터 셋에서 학습된 image-text multimodal task를 수행하는 모델입니다. 가장 기본적인 목적으로는 어떠한 특정 이미지에 대해 잘 설명하는 텍스트 문장을 매치하는 task를 수행하거나, 혹은 어떠한 주어진 텍스트 문장에 가장 잘 일치하는 이미지를 찾아내는 task를 수행합니다.
CLIP을 학습하는 과정은 다음과 같습니다.
- 주어진 데이터 셋에서 N개의 batch를 선택하고, N개의 이미지, 텍스트 라벨들을 모두 pair로 만들어 총 N^2개의 테이블을 만든다.
- N^2개의 테이블에서, 실제 올바른 이미지-텍스트 쌍에 대해서는 cosine similarity가 최대가 되도록 학습하고, 이외의 다른 올바르지 않은 쌍들에 대해서는 cosine similarity가 최소가 되도록 cross-entropy loss를 사용하여 학습한다.
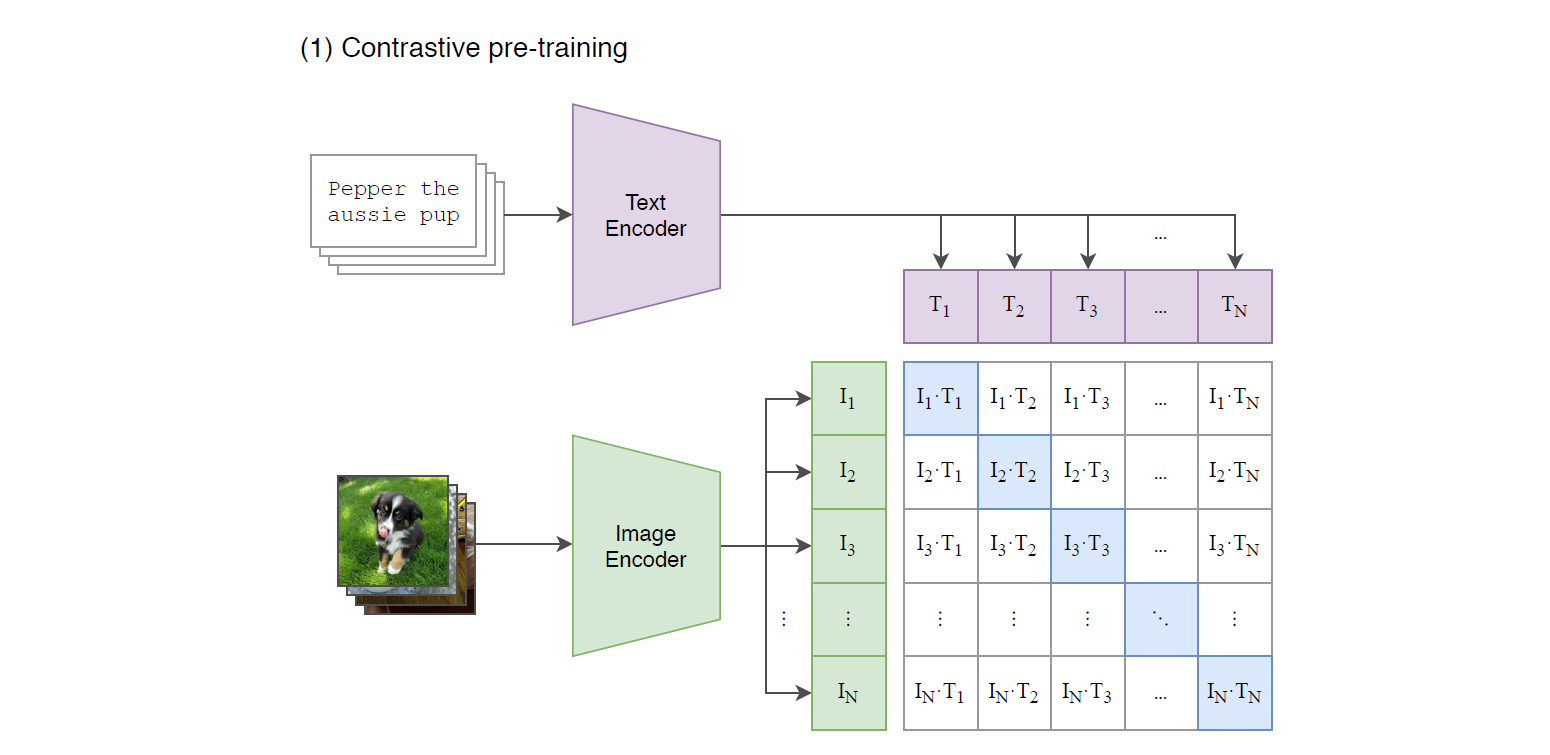
이와 같이 학습된 CLIP 모델의 경우, 이미지와 텍스트 사이의 상관관계에 대한 정보를 잘 학습하게 됩니다. 그 결과로 어떠한 텍스트 맥락이 어떠한 이미지를 의미하는지, 어떠한 이미지가 어떠한 텍스트 맥락으로 해석되는지에 대한 유사성을 잘 파악하게 됩니다.
이렇게 학습된 CLIP의 경우, 이미지-텍스트 multimodal이 가능하고, 입력으로 다양한 형태로 넣어줄 수 있기 때문에 여러 태스크에 사용하는 것이 가능합니다.
이 중 우리는 오늘 이야기할 WiSE-FT와 관련 있는 zero-shot inference에 대해 이야기해보도록 하겠습니다.
Zero-shot inference of CLIP
CLIP에서 zero-shot inference를 하는 과정은 다음과 같습니다. CLIP을 학습할 때 사용하지 않은, unseen 데이터 셋에 대해 특정 이미지가 어떠한 object인지를 classification 하고싶은 경우, 다음과 같이 동작합니다.
- inference를 통해 확인하고 싶은 object를 image 하나로 선정하여 CLIP의 image encoder에 넣는다.
- unseen 데이터 셋에 존재하는 모든 label들에 대해, label text로 만들어서 CLIP의 text encoder에 넣는다.
- image encoder와 text encoder에서 나온 모든 pair들에 대해 cosine similarity가 가장 큰 label text에 해당하는 label을 inference result로 사용한다.
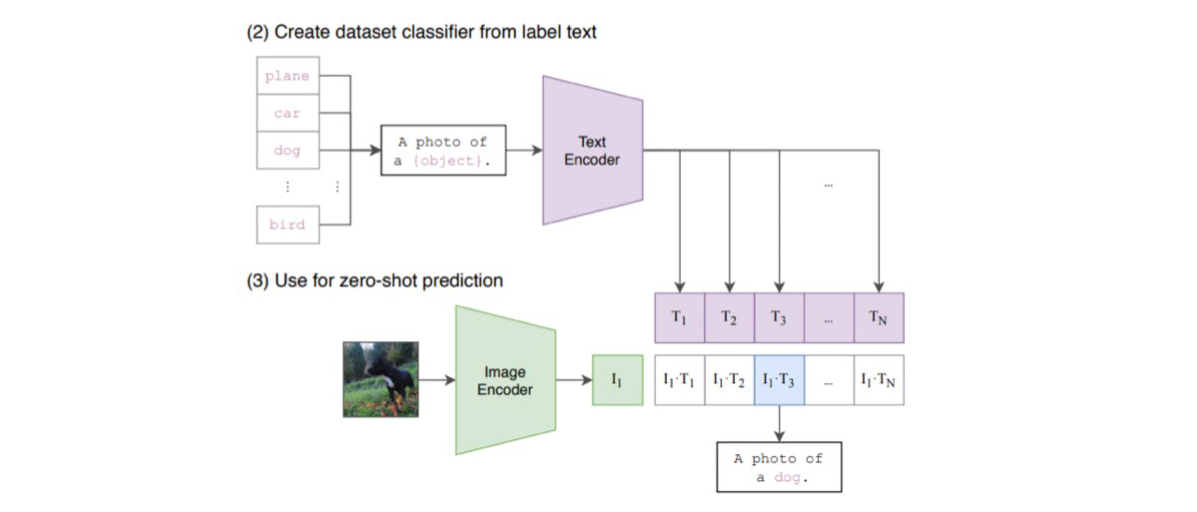
특정 text에 대응하는 image를 찾아내고 싶은 경우, 이와 반대로 image encoder에 후보 image들을 넣어서 similarity를 구할 수 있습니다.
이와 같은 방식으로 동작하는 CLIP은 놀랍게도 unseen image와 label들에 대해서도 굉장히 잘 동작합니다. 그 이유는 CLIP이 대규모 dataset에 대해 pretrained되는 과정에서 text와 image의 semantic information에 대해 굉장히 잘 이해하고 있어서, 실제로 확인하지 않았던 label에 대해서도 그것이 어떠한 semantic을 가지고 있는지 유추할 수 있다는 것입니다. 이러한 이유로, CLIP은 zero-shot에서도 상당히 잘 동작하는 결과를 보입니다.
Abstract
그러나 이러한 CLIP의 경우, 아무리 zero-shot에 대해 잘 동작한다 하더라도 해당하는 unseen dataset에 대해 transfer learning을 진행하는 것보다는 성능이 더 낮습니다. 아무래도 해당하는 데이터를 확인한다면, 해당하는 target distribution을 잘 캐치할 수 있게 되며, 이 과정에서 정확도가 더 높아지게 됩니다.
하지만, 많은 경우에 zero-shot 모델과 transfer learning을 통한 fine-tuning에 대해 큰 문제점이 드러나는 부분이 있습니다. 그리고 이 부분이 본 논문에서 저자들이 태클하는 문제 상황이 됩니다.
본 논문에서 저자들은 CLIP과 같은 대규모 pretrained model을 fine-tuning하여 사용하는 과정에서 발생하는 distribution shift에 취약하다는 점을 지적합니다.
많이 알려진 사실로, CLIP과 같은 zero-shot model들은 distribution shift에 대해 robustness를 갖는다는 점이 있습니다. 예를 들어, zero-shot으로 레몬 이미지를 판단하게 된다면 해당하는 이미지가 실물 이미지이든, 플라스틱 모형이든, 그림이든 어느정도 해당 이미지가 레몬이라는 것을 잘 파악하게 됩니다.

우리가 실제로 사용하려는 이미지가 실물 이미지라면, 해당하는 실물 이미지 셋에 대해 fine-tuning 혹은 linear probing을 거쳐서 target distribution을 학습하게 되면 실물 이미지에 대해 더욱 더 잘 판단하게 됩니다. 그러나 이와 같이 특정 target distribution에 대해 fine-tuning을 거치게 되면, target distribution에 대해서는 굉장히 높은 정확도 향상이 일어나지만, 같은 라벨이지만 약간의 distribution shift가 일어난 다른 dataset에 대해서는 오히려 zero-shot의 경우보다 정확도가 더 떨어지게 됩니다.
이러한 이유로, zero-shot 모델은 robustness 관점에서 좋고, fine-tuning model은 target accuracy 관점에서 더 좋은 성능을 낸다는 성질이 있습니다.
여기에서 저자들은 어떻게 하면 zero-shot 모델의 robustness를 갖추고, fine-tuning의 target accuracy를 갖출 수 있는지에 대해 고민하고, 이를 해결하기 위해 wiSE-FT라는 방법을 시도합니다.
Method
먼저 본 논문의 method를 소개하기에 앞서, 해당 논문은 거의 100% 실험적인 결과로 이루어진 논문임을 명시합니다. 아래의 method들 및 result들에 대한 수학적 설명 및 증명들은 거의 없고, 실제 실험적으로 굉장히 많은 데이터 셋들과 굉장히 많은 셋팅 하에서 실험으로 얻어낸 결과들로 결론을 내고 있습니다.
굉장히 많은 종류의 데이터 셋과 benchmark들에서 검증이 되었으나, 이에 대한 특정 dataset에 대해서는 실제로 아래와 같은 결과가 재현되지 않을 가능성이 있으니, wiSE-FT를 사용할 예정이시라면 실제 테스트를 통해 한 번 확인해보신 후 사용하시는 것을 추천드립니다.
모든 것이 실험적으로 이루어져있더라도, 굉장히 많은 경우들을 따지고 실험을 진행하여 이에 대한 보편적인 특성을 인정받아 CVPR에 accept된 논문입니다.
Weight-Space Ensembles for Fine-Tuning (WiSE-FT)
저자들은 fine-tuning과 같은 transfer learning 기법을 사용하여 target distribution에 맞추는 과정에서, robustness가 손상되는 점을 이야기하였습니다. 또한 이러한 fine-tuning을 하게 되면 다양한 조건의 hyperparameter(train epoch, batch size, learning rate 등)들에 대해서도 약간의 변화에도 큰 영향을 받게 됩니다.
이뿐만 아니라, 큰 learning rate를 사용하는 등의 강한 fine-tuning을 사용하게 되면, target distribution에 대한 accuracy는 증가하지만 이에 상응하게 distribution shift에 대한 robustness가 감소하게 됩니다.
이러한 상황을 해결하기 위해 zero-shot과 fine-tuning의 장점을 결합한 WiSE-FT를 제안합니다.
WiSE-FT는 다음과 같이 구현됩니다.
- 대규모 데이터 셋에 대해 pretrained된 zero-shot model A를 준비한다.
- zero-shot model을 원하는 target dataset에 대해 fine-tuning한 fine-tuning model B를 준비한다.
- linear combination을 위한 0과 1 사이의 hyper parameter a를 설정한다.
- A와 B의 model parameter weigths들을 앞서 구한 a의 비율로 linear combination한 새로운 WiSE-FT 모델 C를 사용한다.
위와 같이 굉장히 간단한 zero-shot model과 fine-tuning model의 weight-space linear combination을 통해 WiSE-FT 모델을 만들어낼 수 있습니다. 이 과정에서, 두 모델이 구해져있기만 하다면 weight을 linear combinatio하는 것은 추가적인 cost가 발생하지도 않아서 cost 관점에서도 굉장히 큰 이점을 갖습니다.


그렇다면 이것이 왜 가능할까요?
많은 경우, neural net들은 layer 단위의 weight linear combination이 불가능합니다. 이들을 단순히 선형으로 결합한다고 해서, 두 가지 task를 모두 해결할 수 있는 모델을 만드는 것은 불가능하며, 심지어 몇몇의 경우에는 이러한 linear combination으로 만들어낸 모델이 random initialization과 비슷한 정도의 성능을 내는 경우도 발생하게 됩니다.
그러나 CLIP과 같은 대규모 pretrained 모델에 대해서는, 이러한 형태의 linear combination을 하는 것이 가능하다는 게 실험적으로 발견되었습니다. 이 과정에서, zero-shot 모델과 fine-tuing model들의 weight-space가 linear path로 연결되어있다는 것을 발견하여, 이러한 형태의 weight linear combination을 수행하는 것이 가능했던 것입니다. 그러하여 이러한 수행을 거치고 나서도 target distribution에 대한 accuracy가 굉장히 높게 나오게 됩니다.
이를 통해, WiSE-FT는 두 모델의 linear combination을 통해, 새롭게 생성된 모델의 weight-space가 zero-shot model이 가지고 있는 distribution shift에 대해서 강인하다는 점과 fine-tuning의 target distribution에 대해 성능이 뛰어나다는 두 가지 장점을 모두 갖춘 영역에 존재할 수 있도록 만들어준다는 것이 저자들이 실험적으로 낸 WiSE-FT의 결론이 됩니다.
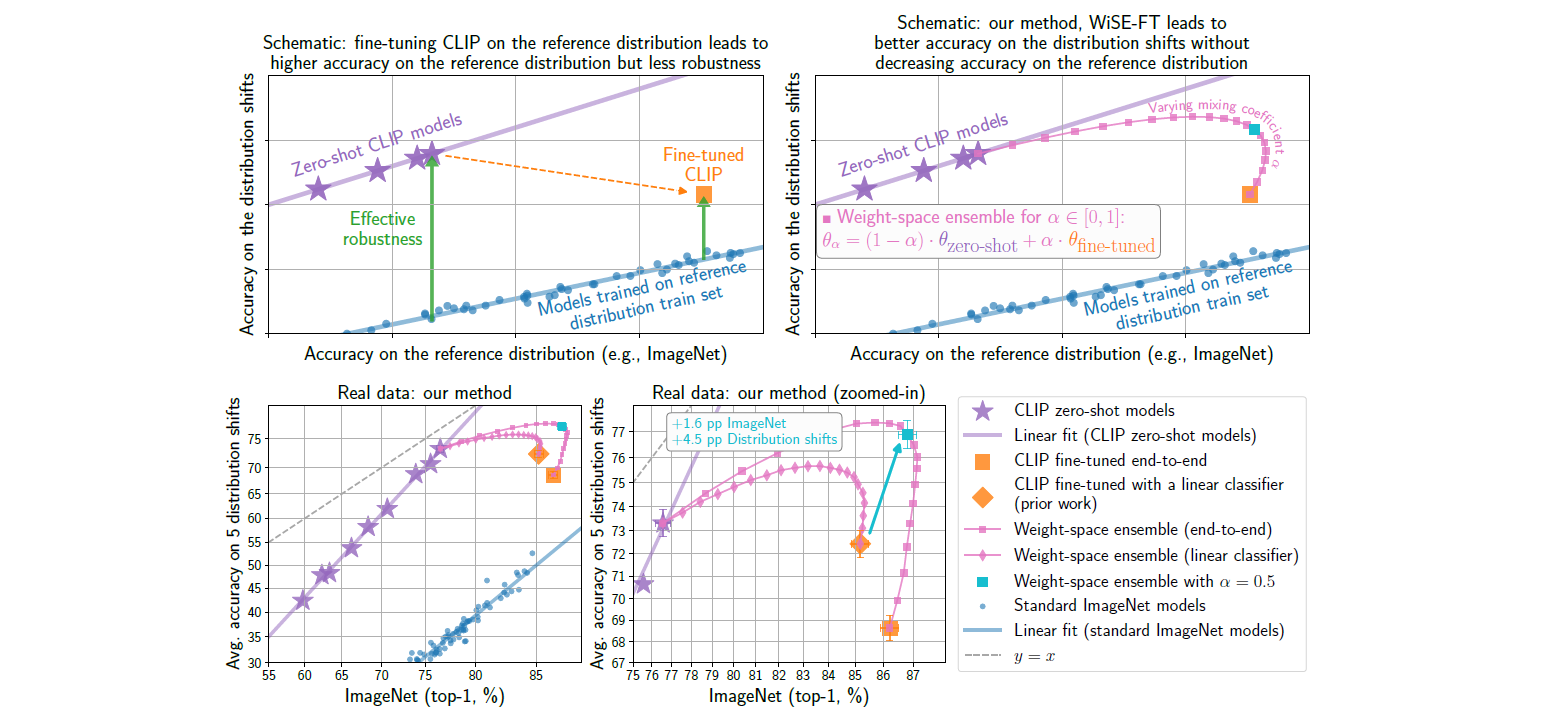
Results
Main Result
저자들은 이러한 WiSE-FT가 실제로 많은 데이터셋에서 올바르게 동작하는지 확인하기 위해 여러가지 데이터 셋에서 실험을 진행합니다.
- IN(reference, ImageNet), IN-V2, IN-Sketch, ObjectNet, IN-A
- CIFAR10/100
- Cars (Car labels)
- DTD (Describable Textures Dataset)
- SUN397 (Scene UNderstanding)
- Food101 (Food labels)
- etc(WILD dataset)
이외에도 appendix에 많은 종류의 데이터 셋에서 실험한 결과들을 추가해놓았습니다.
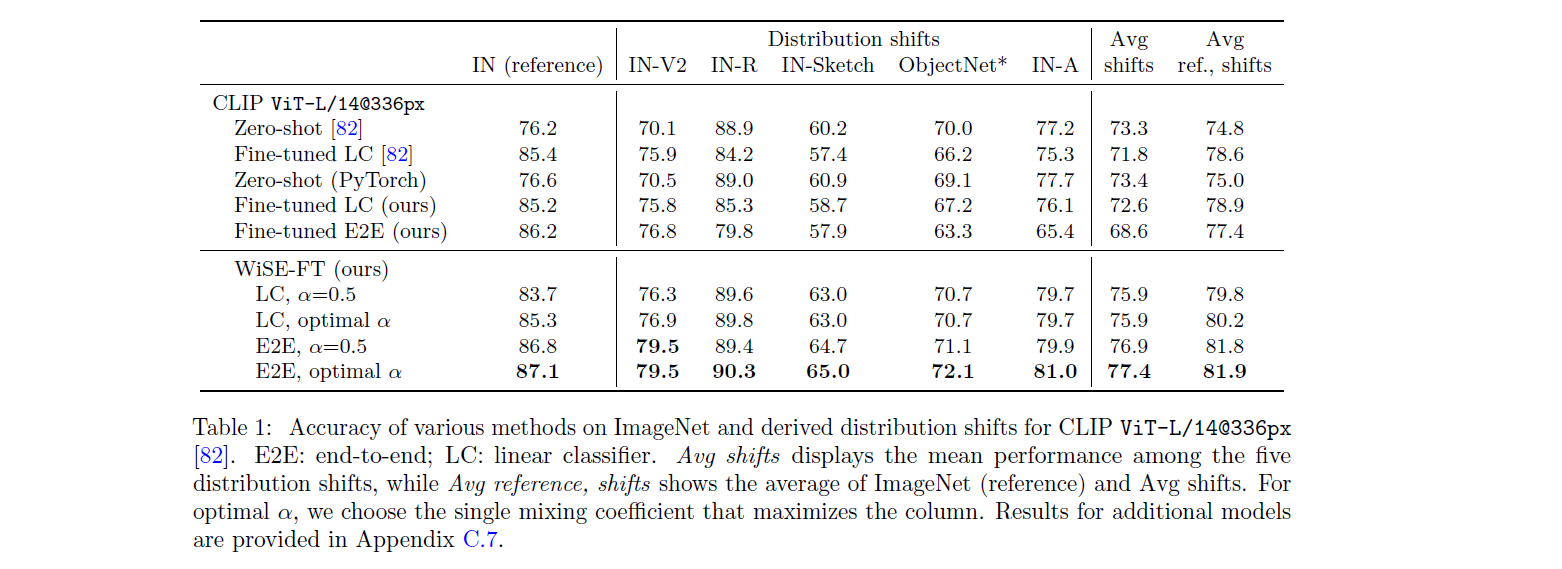

실제 이러한 데이터 셋들에 대해 실험한 결과, WiSE-FT는 fine-tuning과 zero-shot model에 비해 target과 distribution shift 모두에서 좋은 성능을 보이는 것을 확인할 수 있습니다.
또한 저자들은, 이 과정에서 mixing coefficient를 0.5로 사용하면 특별한 튜닝 없이도 굉장히 좋은 성능을 낼 수 있다는 것을 확인하였습니다.
실제 dataset을 사용하여 정량적으로 분석하기에 앞서, ImageNet-9를 기반으로 생성한 합성 데이터들을 ImageNet에 pretrained된 ResNet-50 모델에 넣었을 때에, 이들 label을 어떻게 분류하는지에 대해 간단한 실험 결과를 확인할 수 있습니다.
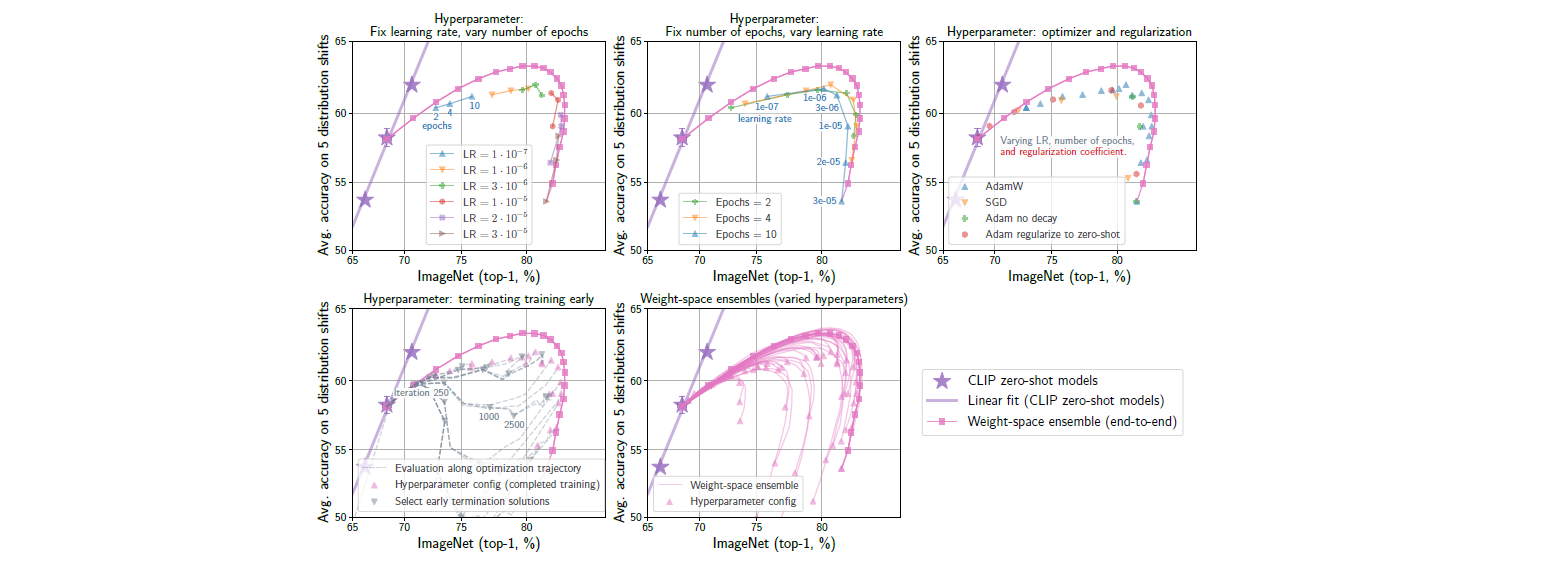
Hyperparameter variation and alternatives
저자들은 WiSE-FT의 강점으로, hyper-parameter tuning이 거의 필요하지 않으며, 사용하더라도 mixing coefficient 하나만 신경쓰면 된다는 점을 강점이라 이야기합니다.
앞서 언급한 것처럼, 많은 경우 fine-tuning은 여러 hyper parameter에 큰 영향을 받습니다. 그러나 WiSE-FT는 어떠한 hyper-parameter로 tuning된 모델을 사용하더라도, 좋은 mixing coefficient를 잡으면 optimal과 큰 차이가 나지 않는 모델을 성공적으로 만들어 낼 수 있습니다.
Discussion
실제로 저자들은 이러한 WiSE-FT가 왜 좋은 성능을 내는지를 분석하기 위해 다양한 분석방법들을 사용합니다. 이 챕터에서는 그 중에서 메인으로 사용된 분석들에 대해서 다루도록 하겠습니다. 실제로 더 많은 분석들을 논문에서 확인하실 수 있습니다.
먼저, 저자들은 zero-shot model과 fine-tuning이 서로 상호보완적이라는 것을 이야기합니다.
- zero-shot model은 distribution shift에 강하고
- fine-tuning model은 reference distribution에 강하다
이를 실제로 보이기 위해서, 그러면 zero-shot model과 fine-tuning 모델의 linear classifier가 얼마나 다른지를 CKA(centered kernel alignment)를 통해 분석하는 것과, 실제 reference distribution과 distribution shift 데이터 셋들에 대해, 각각의 모델이 override하는 상황(한 쪽이 맞추고, 다른 한 쪽이 틀리는 경우)의 비율이 어떻게 되는지 분석합니다.
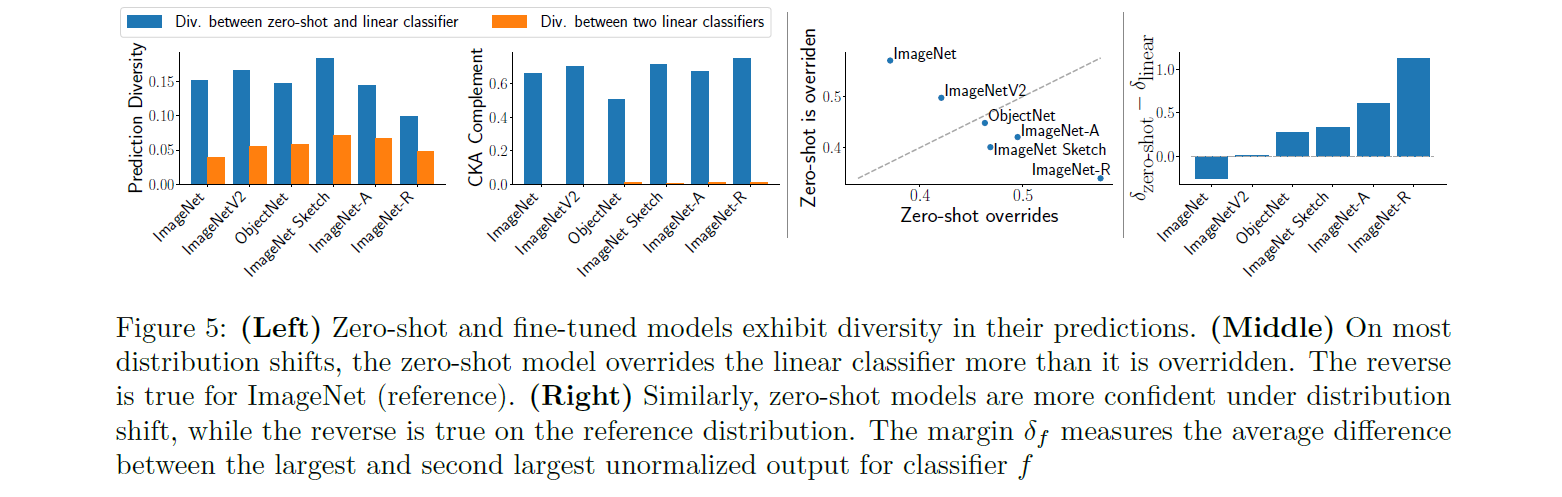
이를 통해 분석한 결과로, 위 그림에서 확인할 수 있듯이 서로 다른 조건의 fine-tuning 사이의 diversity보다 zero-shot과 fine-tuning 사이의 diversity가 훨씬 더 크다는 것을 알 수 있으며, 또한 reference에 대해서는 fine-tuning이, distribution shift에 대해서는 zero-shot model이 override한다는 것을 알 수 있습니다.
Conclusion
결과적으로 WiSE-FT는 대규모 pretrained model에서는 weight-space가 linear path를 통해 연결되어 있으며, zero-shot model과 fine-tuning의 linear classifier의 diversity가 크다는 점, 그리고 두 모델이 서로에게 reference와 distribution shift 관점에서 정보를 제공해줄 수 있는 부분이 많다는 점을 이용하여 weight-space linear combination을 통해 두 모델보다 더 좋은 성능을 내는 모델을 만들어 낼 수 있었습니다.
이러한 형태의 weight combination은 지금까지 많은 경우에서 실패했었기에, weight를 조합하는 형태의 새로운 접근방법이 가능하다는 것은 앞으로의 deep learning 연구에서 큰 도움이 될 수 있을 것입니다.