SmoothMix: a Simple Yet Effective Data Augmentation to Train Robust Classifiers (CVPRW 2020)
SmoothMix: a Simple Yet Effective Data Augmentation to Train Robust Classifiers
SmoothMix는 제가 앞서 소개했던 RandomMix, SAGE 등에 비하면 꽤나 오래전에 나온 논문입니다. 그렇기 때문에 해당 논문에서 baseline들로 비교하고 있는 기법들도 꽤나 기본적인 것들만을 사용하여 비교하고 있으며 엄청 특출난 성능을 보인다고 보기는 어렵습니다. 그러나 해당 mixup 방법 및 발견한 model의 이미지에서의 visualization attention, 그리고 data augmentation이 어떻게 Robustness에 영향을 줄 수 있는지 에 대한 기초적인 접근 방향의 아이디어를 찾을 수 있습니다. 최근에 computer vision과 data augementation에서 고려되고 있는 성질등을 생각했을 때, 한 번 읽어보면 MSDA에 관한 이해를 높이는 데 도움을 받을 수 있을 것입니다.
실제로 해당 논문은 Workshop 논문임에도 불구하고 꽤나 높은 인용수를 가지고 있습니다. 현재 SmoothMix에 대한 한글 자료를 찾을 수 없기에, 제가 직접 자료를 만들고 포스팅하려합니다.
Introduction
최근에 DNN들은 image를 사용하는 다양한 task에서, 다양한 종류의 data augmentation 기법을 사용하여 성능을 향상시키는 것이 가능했습니다. Data augmentation을 사용하여 실제 사용하는 데이터의 수를 늘리는 방식으로 DNN은 overfitting 문제와 해당하는 train dataset에 대해 memorize하는 문제를 해결하는 것으로 알려져있습니다. 이러한 data augmentation의 경우, 어떠한 comptuer vision task에 대해서도 dataset에 굉장히 쉽게 적용하여 사용할 수 있다는 장점이 있으며, 그 종류에 따라 기존의 모델이 잘 해결하지 못하는 여러 task들 자체를 해결해주는 역할을 할 수 있습니다(이미지 flip, rotation 등).
이러한 여러 data augmentation 방법들 중 일부는 이미지의 일부를 dropout하는 방식으로 구현됩니다. 이미지의 일부를 dropout하여 해당 정보를 의도적으로 손실시켜, 이미지가 다른 영역에 대한 정보를 사용하여 유추할 수 있도록 하는 효과를 볼 수 있으며(Cutout), 어떠한 방법에서는 해당 방식으로 dropout된 영역에 다른 이미지를 채워넣어 두 개의 이미지를 mix하는 방식을 채용하기도 하였습니다(CutMix).
이러한 방법론들은 실제 data augmentation에서 굉장히 높은 성능 향상을 만들어냈습니다. 그러나 이러한 regional dropout 방법론들은 해당 dropout되는 영역에서 인접한 픽셀들이 급격하게 변화하는 ‘Strong-Edge Problem’을 일으킬 수 있습니다.
결과적으로 이러한 strong-edge problem은 두 가지의 사이드 이펙트를 일으킵니다.
- 픽셀의 급격한 변화가 일어나면 해당 영역에서 local convolution operation에 영향을 준다.
- 이러한 급격한 픽셀 변화가 일어나는 영역은 네트워크가 실제로 잘 캐치할 수 있는 특성이 되기 때문에, 해당 영역에 대해 네트워크의 포커스가 맞춰지게 되며, 이러한 이유로 기존의 dropout 메소드들이 가지고 있던 해당 영역 이외의 정보를 사용하여 추론한다는 기본 전제에 상충된다.
실제로 dropout을 베이스로 하는 data augmentation들에서 이러한 현상이 발생하는지 확인하기 위해, 저자들은 CAM(Class Activation Map)을 통해 학습된 네트워크가 이미지의 어느 영역의 정보를 활용하여 해당 label을 추론하고 있는지 확인합니다.
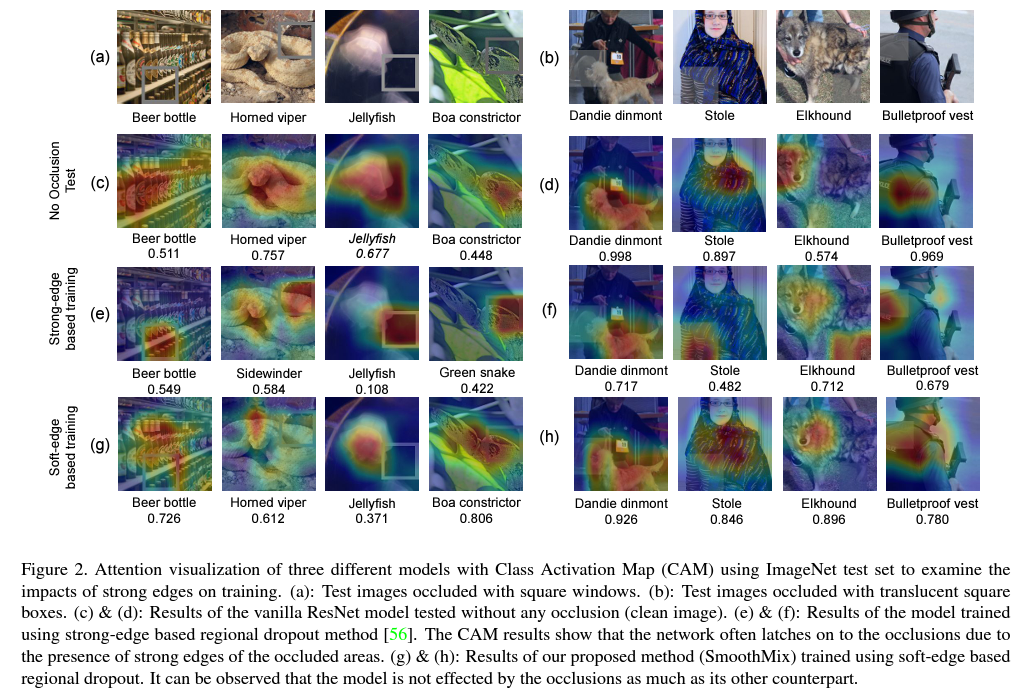
이를 확인하는 과정으로, 다음과 같은 모델들에 대한 CAM result를 비교합니다.
- ImageNet을 학습한 기본 ResNet
- Strong-edge based region dropout을 통해 ImageNet을 학습한 ResNet
- Soft-edge based region dropout을 통해 ImageNet을 학습한 ResNet (SmoothMix)
실제 위 figure에서 각각 원본과 해당 순서의 모델들의 CAM result를 확인할 수 있습니다.
여기에서 확인할 수 있는 결과로는, 일단 기본적인 ImageNet에서 학습한 모델의 경우 실제로 이미지에서 어떠한 이미지인지 확인하기 명확한 위치의 region을 보고 추론하고 있다는 것을 알 수 있습니다. 해파리의 경우는 해파리의 형태를 캐치하여 판단하고 있으며, 뱀을 확인하는 과정에서는 뱀의 머리를 위주로 보면서 추론하고 있음을 알 수 있습니다. 이미지를 판단하는 데 있어서 명확한 요소를 보고 판단하고 있으나, 어떻게 보면 해당 영역에 대한 정보만을 위주로 판단하고 있기에, 이미지에서 해당 정보가 손상되어있을 때에 추론이 어려울 수 있습니다.
다음으로 Strong-edge based region dropout을 사용한 모델의 결과에서는 strong-edge를 이미지에 합성해둔 square window에 굉장히 큰 영향을 받고 있다는 것을 알 수 있습니다. 그 예시로, 해파리 사진에서는, 해당 window 내에 해파리에 대한 정보가 존재하지 않음에도 불구하고, 기존의 region dropout을 사용한 이미지를 통해 학습한 경험을 모델이 알고 있기 때문에 해당 window에 집중하여 추론을 적용하고 있음을 알 수 있습니다. 수치 자체가 완전하게 confidence를 나타내는 것은 아니지만, 이를 통해서 해파리가 존재하지 않는 영역을 중심으로 추론하고 있다 보니, 해파리라는 결론을 낼 때의 score가 상당히 낮음을 알 수 있습니다. 이 뿐만아니라, 다른 사진들에서도 만들어둔 window에 초점을 맞추어 해당 영역이 추론에 큰 영향을 미친다는 것을 알 수 있으며, 그 일례로 ‘Boa constrictor’는 아예 ‘Green snake’로 분류되었습니다.
그러나 아직 소개되지 않은 SmoothMix를 사용하게 되면, 이러한 square window가 존재하는 상황에서도 해당 영역 이외의 실제로 object에서 중요한 영역을 잘 캐치하여 추론에 사용하고 있으며, 이 뿐만아니라 기존의 baseline resnet보다 더 다양한 영역들을 보면서 추론을 진행하고 있음을 알 수 있습니다.
이제 저자들이 어떻게 Soft-edge based region dropout인 SmoothMix를 구현하였는지 소개하도록 하겠습니다.
Method
Mask Generation
기본적으로 저자들은 dropout할 영역을 mask로 만들기 위해서 mask generation을 생각합니다. 이에 대해 디테일한 마스크의 생김새와 만드는 방법은 이후에 서술될 예정입니다.
기본적으로, 특정한 random mask를 생성하기 위해, 저자들은 이미지의 너비 W와 높이 H에 대해 uniformly 결정되는 center point를 다음과 같이 구하게 됩니다.
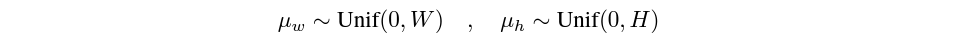
그리고 이러한 중심점으로부터 얼마나 mask가 퍼져나가는지를 결정하기 위해 $sigma$가 결정되면 이에 맞추어 mask의 크기가 변하게 됩니다.
어떠한 방식을 통해 만들어진 마스크가 G라고 할 때, 각 마스크의 픽셀 단위의 ratio 누적합 $lambda$는 다음과 같이 계산됩니다.

Types of Masks
우리는 앞서 저자들이 strong-edge를 사용하여 dropout을 시키면 안된다는 점에 초점을 두었다는 것을 알고 있습니다. 이에 맞추어, SmoothMix는 어떻게 Soft-edge Mask를 만들 것인지에 초점을 둡니다.
이에 저자들은 기본적으로 두 가지 형태의 Mask를 만들어 Soft-edge window를 설정하는 것을 고안합니다.
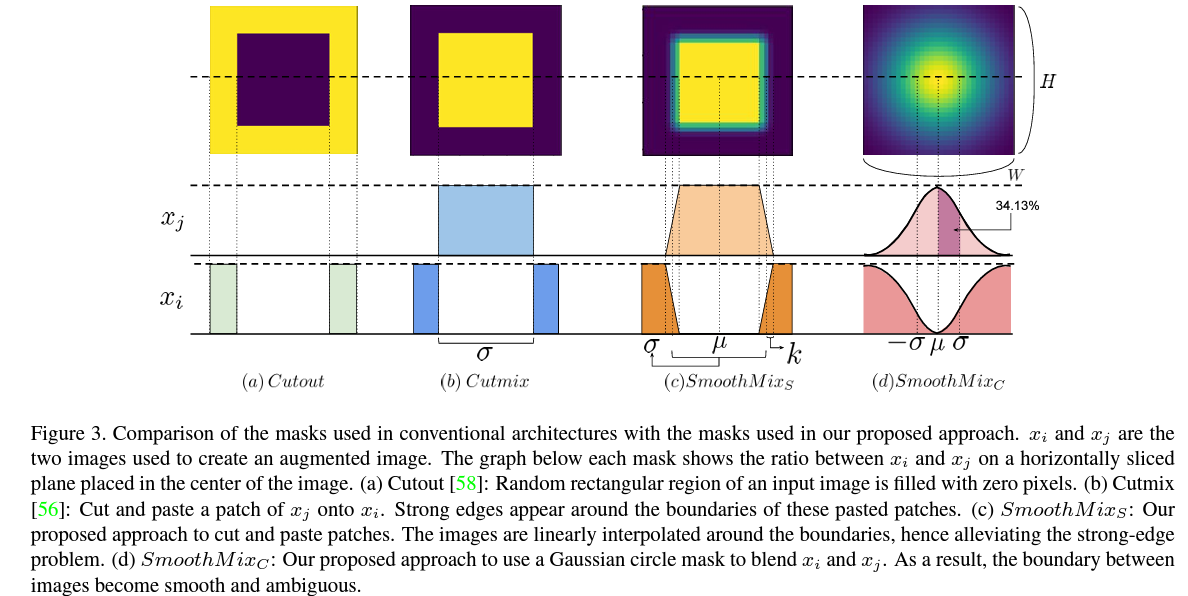
첫 번째 방법은 SmoothMix S 방법입니다. 이는 기존의 Cutout, CutMix에서 사용하고 있는 기본적인 square window를 기반으로 하고 있습니다. 해당 square window를 통해 mask를 만들어내지만, 실제로 주변의 바운더리에 대해서만 linear interpolation을 통해 한 번에 0, 1로 나뉘는 것이 아닌, 특졍 0에서 1로 점진적으로 out되는 mask를 만들어줍니다. 이를 통해, 우리는 해당 square window의 boundary에서도 선형적으로 소실되는 형태의 mask를 만들어줄 수 있습니다.
이러한 boundary linear interpolation mask를 만들기 위해, 저자들은 smooth region k에 대해 다음과 같은 형태로 mask를 만들어냅니다.
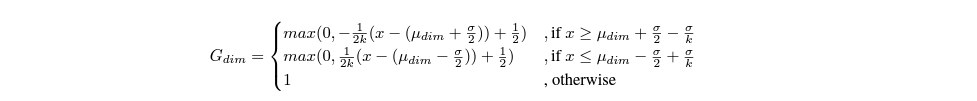
두 번째 방법은 SmoothMix C 입니다. 이는 해당 region dropout mask를 만들 때에, Gaussian circle mask를 만드는 것입니다. 특정 중심점으로부터 가우시안 분포를 따르는 형태로 외각으로 가면서 내부로 갈수록 점진적으로 소실되는 형태의 mask를 만들게 됩니다. 이렇게 하면 기존의 square window보다 사람이 보았을 때에도 훨씬 부드럽게 mask가 형성된다는 것을 알 수 있습니다.
이 때, 우리는 생성하는 mask를 아예 원형으로 하는 것이 아닌, 가로와 세로에 해당하는 width와 height에 대해 따로 설정하여 타원 형태의 mask를 만들 수 있습니다. 이는 각각에 대해 사용하는 하이퍼파라미터에 대해 다음과 같이 정의할 수 있습니다.

이렇게 만들어낸 마스크는 그대로 dropout의 방식을 적용하여 사용할 수 있지만, 저자들은 이에 대해 추가로 해당 마스크에서 dropout되는 영역을 기존의 CutMix에서 사용하는 방식대로 다른 이미지를 넣어 Mixup하는 방식을 사용합니다.
Blending Images and Labeling
위 과정을 통해 만들어낸 마스크 G에 대해, 우리는 또 다른 이미지를 하나 선택하고, (1 - G)에 해당하는 마스크를 만들어, 각 픽셀의 mask ratio의 합이 1이 되도록하는 새로운 이미지를 생성할 수 있습니다. 이를 생성하는 과정은 기존의 CutMix에서 사용하던 mixup 방식을 그대로 차용할 수 있습니다.
그 결과, 우리가 합성에 사용하려는 이미지가 각각 $(x_{i}, y_{i}), (x_{j}, y_{j})$라고 할 때 새롭게 생성되는 이미지는 다음과 같이 정의할 수 있습니다.
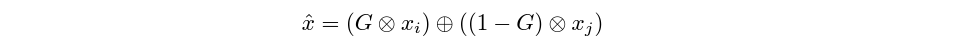
그리고 이렇게 새롭게 생긴 이미지의 label의 경우는, 앞서 mask의 ratio 누적합을 이용하여 다음과 같이 표현할 수 있습니다.

Experiments
SmoothMix의 평가는 다음과 같은 데이터 셋들에서 이루어집니다.
먼저 가장 기본적인 Baseline reference distribution dataset에 대해 평가를 진행합니다. 해당 데이터셋들로는
- CIFAR-10
- CIFAR-100
- ImageNet
등의 가장 기본적인 데이터 셋들이 사용됩니다.
Image Classification Results
기본적으로 smoothmix의 image classification 성능을 측정하기 위해, 다음과 같은 다양한 종류의 data augmentation 기법들과 비교를 진행합니다.
- Cutout, Mixup, CutMix, Manifold Mixup, Dropblocks, etc…
이에 대한 기본 baselince 모델로는 PyramidNet-200을 사용하며, SmoothMix S의 경우 k=0.2, $sigma$는 0 과 1 사이에서 유니폼하게 샘플링되며, SmoothMix C의 경우, $sigma$는 0.25~0.5 사이에서 샘플링됩니다. 각각의 데이터 셋에 대해 사용하는 configuration의 경우 상이하게 다를 수 있기 때문에, 해당 디테일은 논문에서 확인해보실 수 있습니다.


CIFAR 데이터 셋들에 대한 Top-1, Top-5 error는 다음과 같습니다. 위에서 확인할 수 있듯, SmoothMix 자체로는 기본적인 reference dataset에 대한 성능을 크게 향상시키지는 못했습니다. 기존의 다른 data augmentation 기법들이나 mixup보다는 더 좋은 성능을 보였으나 cutmix보다는 더 좋은 성능을 내지 못했습니다.

이러한 결과는 ImageNet result에서도 확인할 수 있습니다. 기존의 CIFAR 데이터 셋에서 확인할 수 있던 결과와 마찬가지의 비슷한 양상을 보인다는 것을 알 수 있습니다.
어떻게 보면 크게 이상한 결과는 아닐수도 있습니다. 앞서 SmoothMix라는 아이디어를 착안하기 위해서 실험했던 Strong-edge based region dropout과 같은 경우는, 의도적으로 이미지에 square window를 추가하는 adversarial이 가미된 상황 에서의 결과이기 때문입니다.
우리가 실제로 test data로 사용하는 경우에는 기존의 train dataset과 같은 distribution을 가지는 데이터 중, 그저 unseen dataset만 사용한 경우이기 때문에 이러한 경우에서는 오히려 이미지에서 중요한 요소에 집중하여 모델이 학습하는 것이 더 좋은 결과를 낼 수 있으며, MSDA 등의 기법으로 generalization을 높이는 것으로도 충분할 수 있습니다.
그렇기에, 저자들은 이러한 data augmentation의 reference dataset에 대한 성능을 올리는 것에 중점을 두는 것이 아닌, 다양한 adversarial cases 에 초점을 맞추어 실험을 진행합니다.
Corrupted Image Classification
해당 결과를 소개하기 이전에 corrupted, adversarial case에 대한 경우를 먼저 살펴보도록 하겠습니다.
우리가 특정 reference dataset에 대해 학습하는 경우, 실제로 우리가 이러한 reference distribution에 가까운 데이터들을 수집하여 해당 모델에 사용할 수 있다면, 큰 문제없이 해당 모델들이 주어진 task를 잘 수행할 수 있습니다. 그러나 우리는 의도적으로 손상되거나 적대적인 공격을 받은 데이터 셋이 모델에게 주어질 수 있습니다. 여기에서 adversarial case의 경우는 의도적인 noise 등을 추가하여 의도적으로 모델이 실패하도록 만들기 위한 case들에 해당하기는 하지만, 꼭 이렇게 인위적으로 손상을 일으키는 경우가 아니더라도 data가 손상되는 경우는 다수 존재할 수 있습니다.
예를 들면, 우리가 구할 수 있는 북극곰의 이미지는 많은 경우 빙하가 함께 있거나 눈 덮인 얼음 위의 사진들이 주어지는 경우가 많을 것입니다. 그렇지만 만약 동물원 안에 있는 북극곰 사진이 있을 수도 있고, 혹은 케이지에 넣어서 이동중인 북극곰의 사진이 주어질 수도 있습니다.
또는 어떠한 경우에는 눈이 너무 많이 내리거나 폭풍우가 오는 상황에서의 장미꽃 사진이 주어질 수도 있으며, 50년 전에 찍어두어서 많은 풍화가 일어난 탁자의 사진이 있을 수도 있습니다.
이러한 다양한 자연적인 상황 속에서도 train에서 사용된 reference dataset과는 distribution이 많이 다르거나 손상된 corrupted case들이 존재할 수 있습니다.
많은 경우, 이러한 상황에서 모델의 성능이 떨어지는 것이 잘 알려져있습니다. 또한 data augmentaion을 사용하는 것이, 모델이 주어진 reference dataset 뿐만아니라 distribution shifted case에서도 좀 더 robustness를 갖는다는 것도 알려져있습니다.
그러나 앞서서 저자들이 확인하였던 strong-edge based region dropout과 같은 경우에서, 특정 data augmentation을 사용하였을 때에 추론을 실패하는 failure case가 발생한다는 것을 알 수 있습니다.
이에 대한 관점에서, 저자들은 SmoothMix가 이러한 corrupted case에 대한 robustness를 갖추고 있다고 주장하며 다음 데이터 셋들에 대해 검증을 진행합니다.
- CIFAR-100-Corrupted
- ImageNet-Corrupted
위의 Corrupted dataset들은 기존의 CIFAR, ImageNet Dataset들에 대해 특정한 corrupted type들을 넣어 새롭게 만들어낸 데이터셋들입니다. 이 과정에서 Gaussian noise, snow, motion blur, fog 등등 다양한 종류의 corruption들이 반영되어 있습니다.

실제 해당 데이터 셋에서 사용하는 corruption의 디테일들은 다음 논문에서 확인해보실 수 있습니다.
Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations
이러한 corrupted dataset에서의 result는 다음과 같습니다.
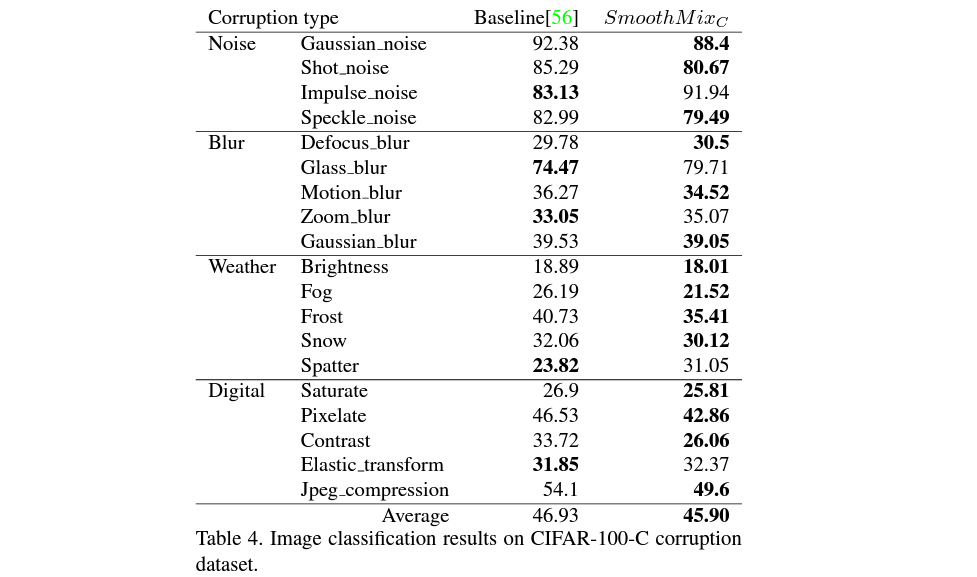

위의 table에서 baseline으로 설정되어있는 것은 바로 기본적인 strong-edge based region dropout을 사용한 CutMix 모델입니다. 저자들은 CutMix에서 사용했던 기본 configuration을 유지하여 baseline을 만들고, 이를 SmoothMix와 비교하였습니다.
여기에서 확인할 수 있는 것은 이러한 다양한 종류의 corruption에 대해선 smoothmix가 cutmix보다 더 나은 성능을 보였다는 것입니다. 물론 어느정도는 상이한 부분이 있기는 하지만, Fog등에 대한 case에서는 smoothmix가 cutmix에 비해 굉장히 월등한 성능을 보여주기도 합니다.
굉장히 많은 case에서 성능이 향상된 것을 통해, 저자들은 이러한 smoothmix가 기존의 reference distribution에 대한 성능도 어느정도 유지하면서, 기존의 data augmentation들보다 높은 robustness를 갖춘다고 주장합니다.
Conclusion
결과적으로 SmoothMix는 strong-edge based DA, MSDA 등을 사용할 때에 해당 edge에 대해 모델이 attention을 갖게 된다는 점을 문제로 삼아, 이러한 단점을 해결할 수 있는 smooth mask를 이용한 augmentation 기법을 제안하였습니다. 실제 실험 결과들로도 이러한 결과가 어느정도 잘 보여졌으며, robustness가 증가했다고 볼 수 있습니다.
그러나 해당 논문을 실제로 받아들이는 과정에서 꼭 실험을 해보고 확인해보시길 바랍니다
SmoothMix에서 제안한 방식과 실제로 strong-edge case에서 기본의 data augmentation 기법들이 문제를 가지고 있다는 것은 논문을 통해 잘 알 수 있습니다. 그러나 그렇다고해서 무조건적으로 결과를 수용하기에는 조금 어색한 부분들이 있습니다.
이는 해당 논문이 틀렸다는 것이 아닌, “실제로 결과를 납득하기 위해서는 추가적인 실험 결과들을 확인할 필요가 있다” 정도로 받아들여주시면 좋겠습니다.
-
먼저, 해당 논문에서 주장한 strong-edge case에 대해서는 data augmentation이 취약한 점을 갖는다는 것을 알 수 있습니다. 그러나 이것은 해당 data augmentation이 가지가 있는 하나의 failure case일 수도 있습니다. 다른 case들에 대해서는 더 좋은 성능을 보일 수도 있고, 혹은 smoothmix가 fail하는 case들이 존재할 수도 있습니다.
-
사용된 데이터 셋은 CIFAR, ImageNet으로 가장 기본적인 benchmark dataset이기는 하지만, 다양한 종류의 데이터 상황에 대해서도 이러한 경향상이 나타나는지는 미지수입니다. 물론 어느정도 받아들일수는 있으나, 본인이 사용하는 데이터 셋에서도 해당 경향성이 발견되는지는 검증이 필요합니다.
-
Corrupted case들에 대해서 비교하고 검증할 때에는 CutMix 하나만을 baseline으로 잡고 비교하였습니다. 물론, reference distribution에 대해서 가장 높은 성능을 보였던 CutMix였기에 사용한 것으로 볼 수 있습니다. 그러나 다른 data augmentation 기법들(Mixup 등)이 더 높은 robustness를 갖는지 여부 등은 확인해볼 필요가 있습니다. 앞선 SmoothMix의 robustness 측정 결과가 완전한 상위호환도 아니었기 때문에, 이러한 경향성이 실제로 뚜렷한 것인지 검증이 필요합니다.
물론 워크샵 논문이기 때문에 많은 검증이 들어가지 않았고, 분석이 들어가지 않았을 수 있습니다. 그러나 이 과정에서 확인한 strong-edge case에서의 접근이 상당히 좋았기 때문에, 여러 검증이 추가되어 해당 논문을 살펴보시면 많은 도움을 받으실 수 있을 것이라 생각합니다.