Introduction
Many-Core Programming
Many-core processor는 많은 수의 core를 가져 대규모의 병렬 연산이 가능한 프로세서를 의미하며, 이를 활용하는 것을 many-core programming이라고 부른다. 유사한 용어인 multi-core는 수~수십 개 정도의 core들에 대한 의미를 주로 포함하는 것과는 달리, many-core는 그보다 훨씬 많은 수천~수만 개의 core들에 대하여 사용한다.
최근 many-core programming은 GPU(Graphics Processing Unit)가 게임, 계산과학, 인공지능 등 다양한 workload들을 처리하기 시작하면서 매우 중요해지고 있는 추세이다. 특히 GPT, ViT 등 Transformer 기반의 거대 AI 모델들은 실수의 행렬곱이라는 병렬화가 매우 잘 되는 연산을 주로 사용하여 수천 개의 core를 동시에 활용하는 것이 가능하다.
이 글에서는 many-core programming 환경의 대표 주자라고 할 수 있는 NVIDIA의 CUDA에 대해 살펴보고, 간단한 예제를 제시하고자 한다.
먼저, 앞으로 자주 사용할 두 개념인 Floating Point와 FLOPS, 그리고 GPU의 대략적인 구조에 대해 알아보자.
Floating Point
컴퓨터의 메모리는 유한하기에, 소수점으로 표기할 시 무한한 자릿수를 가진 $\sqrt{2}$와 같은 실수를 정확히 저장하는 것은 불가능하다. 이 때문에 컴퓨터에서는 실수를 최대한 근사하여 $a \times 2^{b}$로 표현하고 두 정수 $a$(가수부, mantissa)와 $b$(지수부, exponent)를 저장한다.1 이를 부동소수점 또는 floating point 표기법이라고 한다.
부동소수점 표기법에서 대략적으로 $a$의 크기는 표현의 정밀도를 결정하고 $b$의 크기는 표현할 수 있는 숫자의 범위를 결정하게 된다. 구체적으로 floating point로 저장된 실수는 메모리에 다음 [Figure 1]과 같이 저장된다. 전체 수의 부호는 가장 앞의 sign bit이 표시하며, 지수부는 부호 있는 정수의 표기를 따르고, 가수부는 부호 없는 정수의 표기를 따른다.2 이 글에서 앞으로 나올 ExMy와 같은 표기는 $x$ bit exponent, $y$ bit mantissa를 가진 floating point 표기법이라는 의미이며, 실제 크기는 sign bit를 포함해야 하므로 $x+y+1$ bit이다.

이외에도 IEEE 754(wiki) 표준에는 NaN(Not a Number), INF(Infinity) 등 특수한 상황을 나타내는 방법이 명시되어 있으나 이 글에서는 다루지 않을 것이다.
현재 CUDA 및 NVIDIA GPU에서 지원하는 대표적인 실수 표기법들은 다음과 같다.
- FP64 : E11M52, IEEE double-precision
- FP32 : E8M23, IEEE single-precision
- FP16 : E5M10, IEEE half-precision
- TF32 : E8M10, TensorFloat32, A100 이상
- BF16 : E8M7, Brain Floating Point 16, A100 이상, GCP TPU docs
- FP8 : E4M3 or E5M2, H100 이상, arXiv
TF32, BF16, FP8은 인공지능 학습 및 추론을 위해 개발된 부동소수점 표기 방식으로써, mantissa가 큰 IEEE floating point 표준들과 달리 exponent가 상대적으로 큰 특성을 가지고 있다. 보다 구체적으로, TF32와 BF16은 FP32와 같은 exponent를 가지고 TF32는 FP16과 같은 mantissa를 가진다. TF32가 32-bit를 사용하는 방식이 아님과, AI/DL 프레임워크 TensorFlow의 약자인 TF와 혼동하기 쉬움에 주의하자.
작은 크기의 mantissa는 multiply hardware의 크기와 메모리 사용량을 줄이는 장점이 있으며 neural network의 정확도가 model weight의 mantissa보다 exponent의 크기에 더 많이 영향을 받는 특징이 있어 정확도 또한 크게 감소하지 않는다. 이에 따라 최근 출시된 GPU인 H100에서는 FP8 행렬곱을 Tensor Core hardware에서 직접 지원하는 등 인공지능 추론에서 낮은 정밀도의 floating point들이 선호되고 있다.
FLOPS
FLOPS는 FLoating point Operations Per Second의 줄임말으로, 프로세서 또는 컴퓨터의 성능을 나타내기 위해 주로 사용한다. FLOPS와 어떤 프로그램의 부동소수점 연산 총 개수를 의미하는 FLoating point OPerations의 약자인 FLOPs는 분명히 구별해야 함에 주의하자.
지난 2020년 출시된 GPU인 A100은 FP16 연산에 대해 최대 78TFLOPS의 성능을 가지며, Tensor Core를 이용하여 행렬곱 또는 그와 유사한 연산을 한다면 312TFLOPS에 달하는 연산 능력을 가진다. 현재 시장에 출시된 고성능 CPU가 몇백 GFLOPS ~ 몇 TFLOPS 수준의 성능을 가지는 것과 비교하면 엄청난 차이이다.
CPU and GPU
GPU가 수많은 연산을 빠르게 처리할 수 있다면, 우리는 왜 CPU를 사용하고 있을까? 다음 그림들로부터 CPU와 GPU의 큰 차이를 발견할 수 있다.
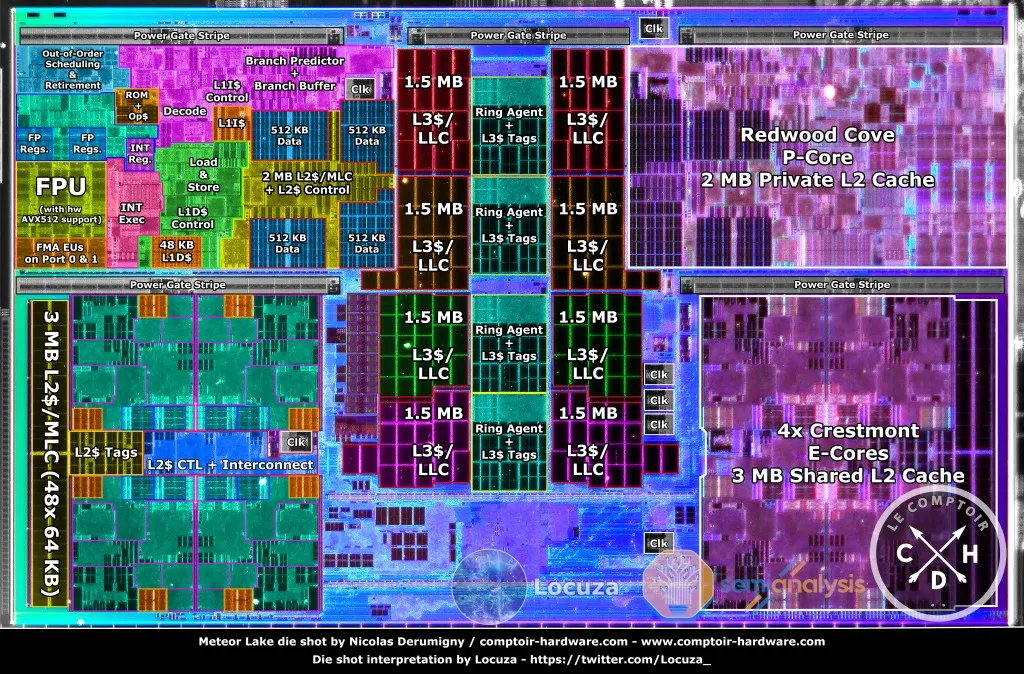
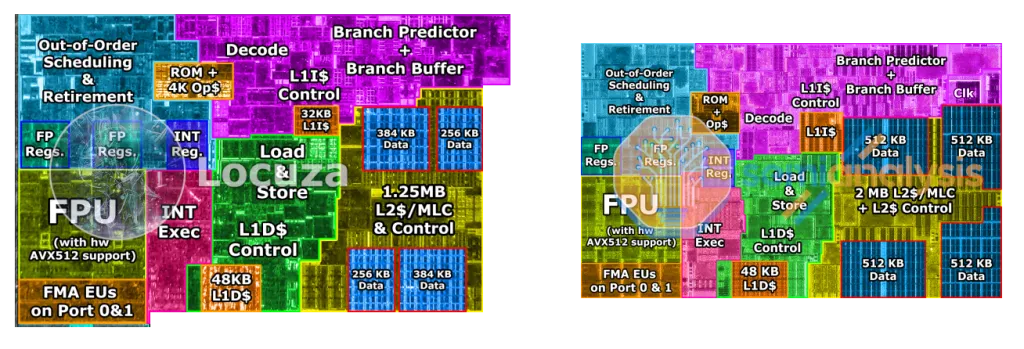
[Figure 2]3와 [Figure 3]3은 CPU의 내부 구조를 나타낸다. 참고로, Meteor Lake는 최신 Intel 노트북 CPU의 제품군명이다. [Figure 2]는 CPU 전체에서 물리적으로 코어가 차지하는 면적의 비율을 보여 준다. Ring과 L3 cache가 중앙 부분을 차지하고 있고, 좌우로 코어가 위치하고 있다. [Figure 3]에서는 코어의 내부를 볼 수 있는데, [Figure 3] 우측의 Redwood Cove Core 구조가 [Figure 2] 상단 좌우에 하나씩 들어가는 것이다. 실제 연산이 일어나는 곳은 [Figure 3]의 FPU와 INT Exec 뿐이고 나머지는 모두 instruction fetch, decode 및 cache, branch prediction과 관련된 부분이다. 즉, CPU에서 연산이 수행되는 곳의 면적은 생각보다 매우 작다는 것을 알 수 있다.
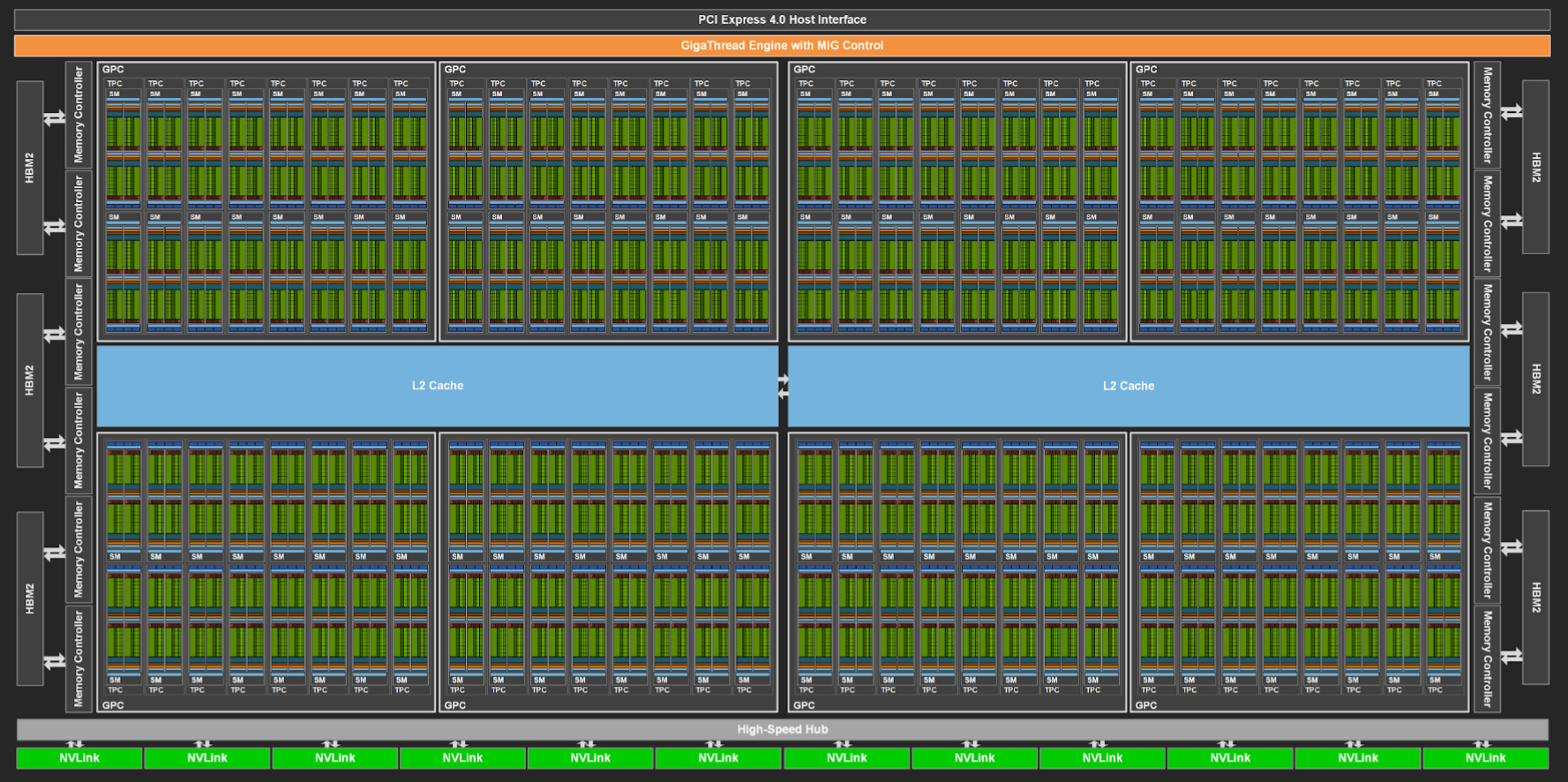
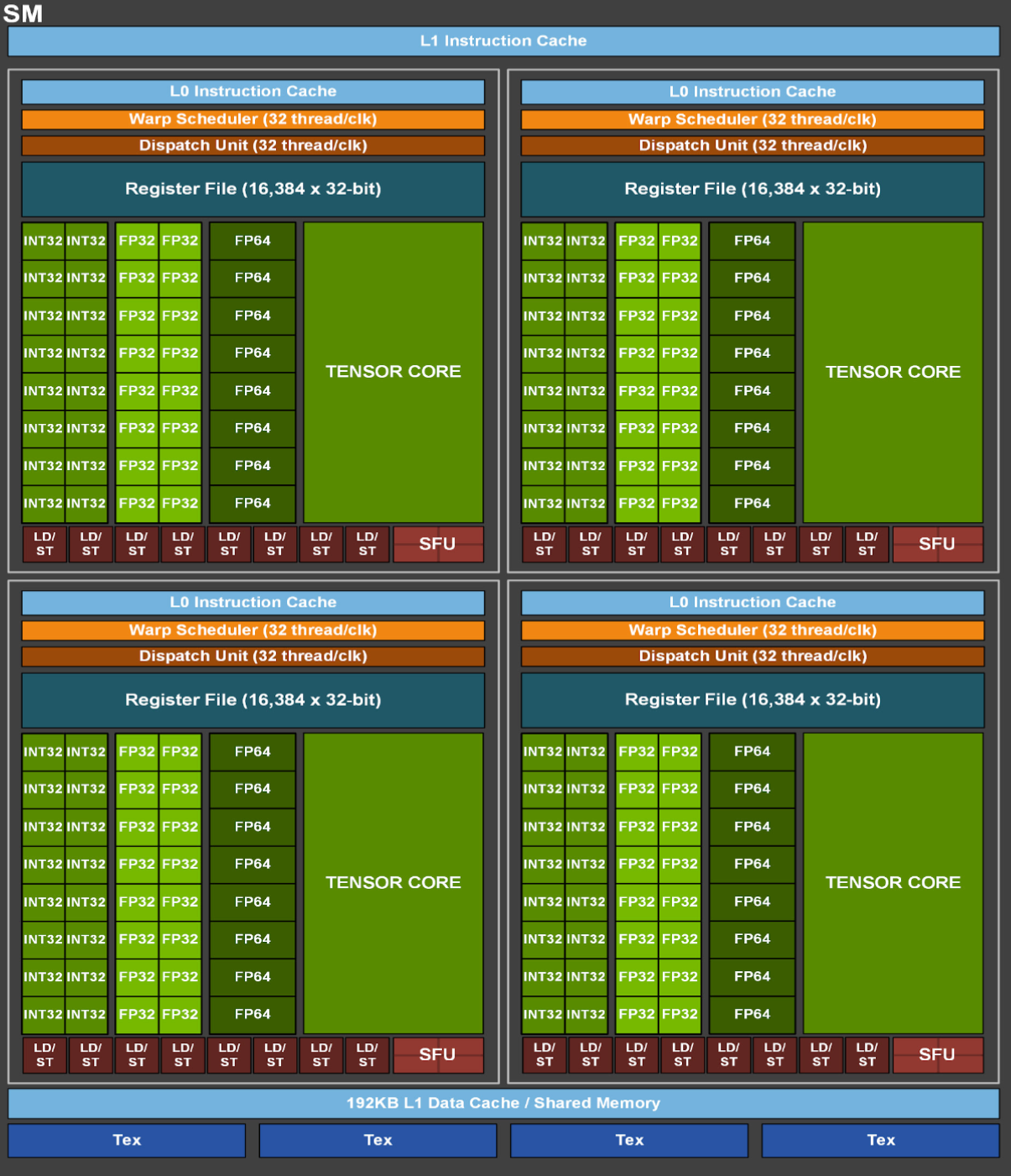
[Figure 4]4와 [Figure 5]4는 비율이 정확하지 않지만, 각각 [Figure 2]와 [Figure 3]에 대응되는 그림이다. [Figure 4]에서는 SM(Streaming Processor, GPU에서 독립적으로 사용되는 단위 중 하나) 128개가 GPU 대부분의 면적을 차지하고 있음을 알 수 있다. [Figure 5]에서는 SM 안의 구조를 볼 수 있는데, 초록색 계열로 칠해진 연산이 일어나는 부분이 SM 안의 대부분을 차지하고 있다. 즉, GPU 면적의 대부분은 실제 연산기가 사용한다.
정리하자면, CPU는 instruction을 decode, fetch, out-of-order schedule하고 branch를 적극적으로 predict하는 것에 많은 영역을 소비하게 된다. 이를 통해 몇 개의 강력한 코어들(multi-core)을 가져 다양하고 복잡한 명령어들을 순차적으로 빠르게 처리할 수 있다. 반면 GPU는 그러한 기능들을 대부분 과감히 제거하고 연산기의 수를 극단적으로 늘려(many-core) 단순하지만 많은 수의 병렬적 연산을 빠르게 처리하는 특징을 가진다. 이에 따라 CPU와 GPU는 빠르게 계산할 수 있는 알고리즘의 종류가 다르며, 두 종류의 연산기를 필요한 곳에 적절히 사용하도록 코드를 작성하는 것은 최적화에서 매우 중요한 요소가 된다.
CUDA
CUDA(Compute Unified Device Architecture)는 NVIDIA의 고성능 GPU 애플리케이션 개발 환경이다. GPU 프로그램을 개발함에도 C++의 문법을 사용할 수 있어 편리하고 직관적이라는 장점이 있다. 언어 문법 뿐만 아니라 CUDA compiler인 nvcc는 g++와 매우 비슷하게 사용할 수 있어 적응하기 쉽다.
VRAM(Video RAM)은 일반적인 RAM과는 달리 그래픽카드 안에 GPU와 함께 들어 있어 GPU와 넓은 대역폭으로 빠르게 데이터를 주고받을 수 있다. GB 단위의 데이터를 저장할 수 있기에 필요한 operand들의 1차적인 저장소로써 주로 사용된다. 아래에서 Host는 CPU(+RAM), Device는 GPU(+VRAM)을 의미한다.
Installation
CUDA 설치는 NVIDIA 홈페이지 등을 참고하자. (최신 버전 설치 / 구버전 archive)
nvcc --version의 실행 결과가 다음과 유사하면 설치에 성공한 것이다. 필자의 경우, 타 프레임워크와의 호환성 등으로 인해 CUDA 11.8을 사용한다.
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
Vector Add
이 코드는 두 길이 $N=10^{8}$의 float vector $A$와 $B$를 랜덤하게 생성한 후 $C=A+B$를 계산하는 것을 CPU(single core)와 GPU에서 각각 실행하여 속도를 비교하는 프로그램이다. CUDA runtime API를 호출할 때는 cudaError_t를 사용한 에러처리를 해야 하나, 편의를 위해 생략하였다.
필자의 컴퓨터 사양은 다음과 같다.
- CPU: Intel Core i5-13500
- RAM: 마이크론 Crucial DDR5-5600 32GB
- GPU: NVIDIA GeForce RTX 4070 (VRAM 12GB)
- OS: Ubuntu Desktop 22.04
해당 컴퓨터에서 코드를 실행한 결과는 다음과 같다. CUDA kernel을 이용한 것이 CPU보다 70배 이상 빠른 것을 확인할 수 있다. 다만 처음 실행은 GPU의 로딩 등으로 인해 느릴 수 있으니 여러 번 실행해 보자.
$ nvcc -o vectorAdd.cubin vectorAdd.cu
$ ./vectorAdd.cubin
The answer is correct! CPU: 190.609024 ms, GPU: 2.599744 ms
vectorAdd.cu에 사용된 CUDA API 또는 문법들은 다음과 같다. 전체 API docs는 여기에서 볼 수 있다.
- CUDA kernel 관련
__global__: CUDA에서 정의한 매크로로써,__global__이 붙은(annotated) 함수들을 CUDA kernel이라고 부른다. 이러한 함수는 Host와 Device5 모두에서 호출될 수 있으며 Host가 Device에게 명령을 내릴 수 있게 한다.kernel_name<<<blockDim, threadDim>>>(args):kernel_name의 kernel을args인자를 사용해 실행(launch)한다.<<< >>>안에 들어간blockDim,threadDim위치의 인자는 다음 글에서 자세히 설명할 예정이니, 병렬성의 양과 구조를 조정하는 것이라고만 기억해 두자.threadIdx,blockDim,blockIdx: 앞에서 지정해준 구조에 따라 생성된 많은 thread들 중 지금 실행되는 thread의 위치를 의미하는 변수이다. 이 또한 다음 글에서 자세히 설명할 것이다.
- Device Memory 관련
cudaMalloc: Device memory(VRAM)를 allocate한다.cudaFree: Device에 allocate되었던 memory를 free한다.cudaMemcpy: Memory copy가 필요할 때 사용할 수 있다. 네 번째 인자가cudaMemcpyKindtype을 가지는데,cudaMemcpyHostToHost,cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost,cudaMemcpyDeviceToDevice등의 option이 있어 알맞게 사용하면 된다. 위의 예제에서는 kernel의 input인 $A$와 $B$를 host to device로, output인 $C$를 device to host로 memcpy하였다.
- Event 관련
cudaEventCreate:cudaEvent_t자료형의 변수를 초기화한다.cudaEventRecord: 현재 상태를 capture하여 작업이 끝날 때의 상태를 저장하도록 한다.cudaEventSynchronize: Event가 capture한 작업이 모두 끝날 때까지 기다려 event의 기록을 종료시킨다.6cudaEventElapsedTime: 두 개의 event가 종료된 시간차를 ms 단위로 반환한다.
정리하자면 CUDA kernel vectorAdd는 device memory(VRAM)를 가리키는 pointer 3개를 인자로 받으며, CUDA가 제공한 정보로부터 thread가 계산해야 할 고유한 index를 얻어낸 뒤 C[idx] = A[idx] + B[idx]를 수행하게 되는 것이다. 각 thread는 한 번의 덧셈만을 수행하지만 thread를 대략 $N=10^{8}$개 생성하여 필요한 모든 연산이 끝나게 된다.
Conclusion
이 글에서는 주요 개념들인 many-core programming, Floating Point, FLOPS와 GPU의 특징을 소개한 후 single precision float vector의 덧셈 연산을 CUDA C++로 구현하여 성능을 CPU와 비교해 보았다. 다음에는 Vector Add example에서 설명하지 않고 넘어간 block과 thread에 대해 다룰 예정이다.
이 글은 책 CUDA by Example의 1~4장을 참고하여 작성되었다. 조금 오래됐지만 필자가 처음 CUDA를 공부할 때 봤던 책으로, 좋은 예제와 함께 설명을 제공하는 입문서라고 생각한다.
1 표현하고자 하는 실수가 0이 아니라면 가수부의 첫 자리는 이진수 표현에서 반드시 1이고, 0이라 할지라도 가수부를 모두 0으로 저장하면 되므로 첫 자리는 제외하고 저장한다.
2 일부 부동소수점 표준의 경우, 지수부에 일정 수를 더한 값을 저장하여 부호 없는 정수의 표기법을 사용하기도 한다.
3 Meteor Lake Die Shot and Architecture Analysis by Locuza and SemiAnalysis
4 NVIDIA Ampere architecture whitepaper by NVIDIA Corporation
5 Device에서의 kernel call은 Compute Capability 5.0 이상의 기능이나, GTX, RTX 등 현재 사용되는 대부분의 NVIDIA GPU가 이를 만족한다.
6 Synchronize가 필요한 이유는 CUDA가 기본적으로 async하게 작동하기 때문이다. 즉, kernel의 호출 이후에 CPU가 kernel 종료까지 기다리는 것이 아니라 병렬적으로 작업을 수행하게 된다. 따라서 synchronize 작업을 하지 않는다면 실행 시간이 이상하게 측정될 수 있다.