Introduction
이번 글에서는 작년 11월에 처음 arXiv에 게재되었고 ICLR 2024 poster로 발표될 예정인 FlashFFTConv에 대해 다루어 보고자 한다.
먼저 introduction에서는 논문과 조금 다르게 필자가 생각하는 motivation들을 적어 보고자 한다.
Scaling Law of LLM
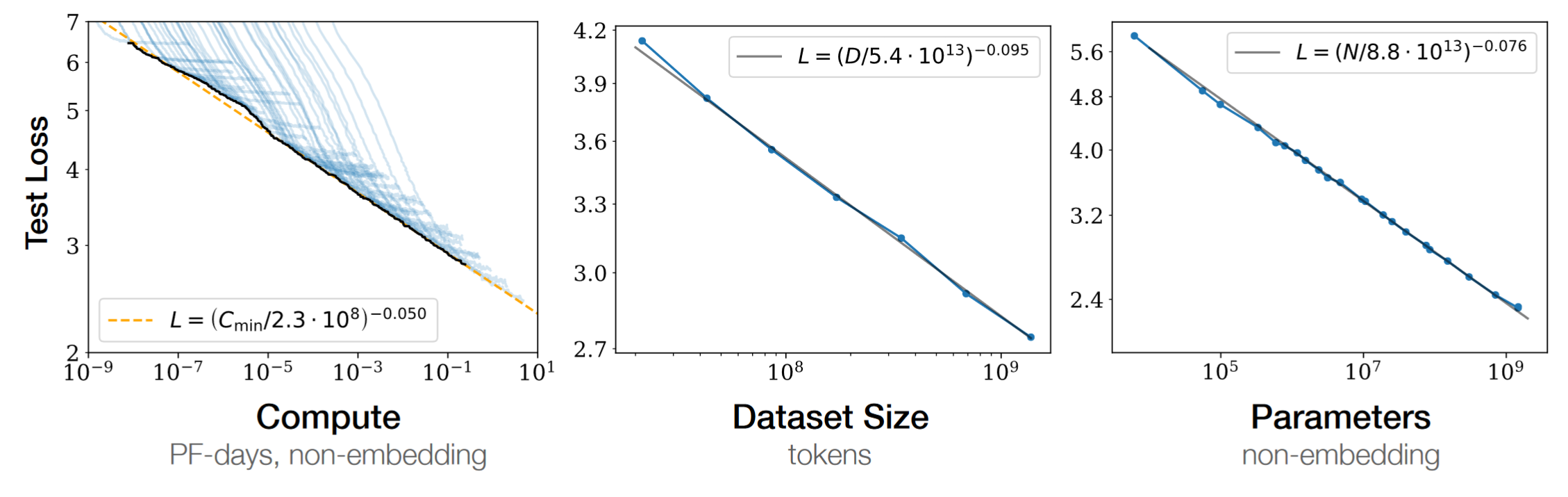
Scaling Laws for Neural Language Models는 OpenAI에서 연구한 결과를 정리한 article로, 다음 [Figure 1]의 결과를 제시한다. [Figure 1]은 여러 metric들이 지수적으로 증가함에 따라, LLM의 성능이 개선되는 것을 잘 보여주고 있다. 이러한 transformer 기반 모델의 특성은 현재 LLM을 NLP의 중심으로 만들었을 뿐만 아니라 computer vision 등 다른 분야에서도 SOTA accuracy를 달성하는 데 큰 역할을 했다.
Accelerating Transformers
모델의 구조를 바꾸지 않더라도 속도를 개선시킬 수 있다면 더 큰 모델을 돌릴 수 있기 때문에, scaling law에 따라 같은 compute 자원 상에서 정확도가 높아지게 된다. 따라서 transformer based model을 가속하는 것은 model architecture 자체를 개선하는 것과 함께 ML 및 NLP 연구의 중요한 방향으로 자리잡고 있다.
Quantization, FP8과 같은 low-precision floating point나 mixed-precision training/inference, FlashAttention, 2:4 Sparsity 등이 대표적인 예시로써 현재 존재하는 GPU의 architecture을 효율적으로 활용하거나 일부 바꾸어 큰 성능 개선을 이끌어냈다. 이러한 방법들에 대해서는 추후 다른 글에서 더 자세히 다루어 볼 것이다.
Long Sequence Modeling
하지만 transformer based model은 약 16K token 이상의 long sequence task에 대한 근본적인 약점이 있다. 책 단위의 summary나 고해상도 이미지의 computer vision task, 일반적으로 높은 sample rate를 가지고 있는 음성 파일들에 대한 lossless한 분석 등은 모두 매우 긴 sequence에 대한 처리를 요구하기에 long sequence task는 중요하지만 해결 방법이 아직 완전히 정립되지 않았다.
이는 self-attention 연산이 sequence length에 quadratic한 cost를 가지기 때문으로, Longformer, Linformer 등의 기법들이 대안으로써 제시되었다. 최근 출시된 Mistral 7B, Mixtral 8x7B 등에서도 유사한 방법인 Sliding Window Attention(SWA)을 사용하고 있지만 long sequence에서 training 과정에서의 어려움과 정확도의 감소는 transformer 계열의 모델들이 여전히 해결하기 어려운 문제로 남아 있다.
SSM Based Model
State Space Model(SSM)은 제어 이론 계열에서 주로 사용되던 시계열 모형으로써 입력 $u(t)$, 출력 $y(t)$에 대해 내부 상태 $x(t)$를 가지는 다음 [Equation 1]과 같은 모델이다. 이 때 네 가지 parameter $A, B, C, D$가 시간에 따라 변화하지 않는 상황을 Linear Time Invariant(LTI)라고 부르고 이산화된(ML에서 사용하는 시계열, 문자열 등은 대부분 입력 시간이 연속이 아니므로 자연스러운 가정이다.) LTI SSM은 convolution과 FFT를 이용해 $O(NlogN)$ 시간 복잡도에 $N$개의 항을 계산할 수 있음이 알려져 있다. 이는 길이 $N$의 두 sequence에 대한 FFT를 계산하고 pointwise multiplication 후 inverse FFT를 통해 convolution이 계산 가능하기 때문이다.
\[\begin{align} \dot{x}(t) = A(t)x(t)+B(t)u(t) \\ y(t) = C(t)x(t)+D(t)u(t) \end{align}\]이를 기반으로 하는 S4, S5, H3 등 SSM based model들은 sequence length $N$에 대해 $O(N^2)$의 시간복잡도를 가지던 기존의 transformer based model과 달리 효율적이고 빠른 long sequence에 대한 추론이 가능하여 많은 주목을 받고 있다. SSM based model들의 최신 동향에 대해서도 다른 글에서 가능하면 다루어 볼 것이다.
FlashFFTConv
결론적으로, FFT를 활용해 convolution을 빠르게 계산하는 것은 SSM based model의 발전과 함께 중요한 task로 떠오르고 있다. FlashFFTConv는 제목과 같이 order-$p$ Monarch decomposition, tensor core, kernel fusion 등 다양한 기법을 사용하여 연산을 최대 7.93배 가속시켰고, 모델 전체에서도 최대 4.4배 가속을 이루어냈다. GitHub 링크
FlashConv in H3
cuFFT 등 기존의 FFT 구현을 활용한 convolution 계산은 시간복잡도가 $O(NlogN)$임에도 불구하고, 16K ~ 32K 정도의 길이에서는 FlashAttention을 이용해 GPU의 병렬적인 하드웨어를 잘 활용할 수 있는 $O(N^2)$의 attention보다 느리다. 하지만 현실적으로는 training 과정의 문제로 인해 attention도 사용하기 어렵기에 앞에서 소개한 H3 논문의 경우에는 특수한 SSM 구조를 이용한 FlashConv라는 알고리즘을 제시한다. 이는 짧은 FFT 여러 개를 계산한 후 적절한 처리를 해 주면 SSM에서 사용하고자 하는 전체 FFT를 계산할 수 있기 때문이다.
이 때 FlashConv에서는 짧은 FFT에 대해서도 최적화 기법을 Fused Block FFTConv라는 이름으로 제시하는데, 이는 다음 다음 [Equation 2]를 이용한다. [Equation 2]는 1차원 길이 $N$에 sequence에 대한 FFT의 계산을 $N = N_{1} \times N_{2}$을 만족하도록 $N_{1} \times N_{2}$ matrix로 reshape한 후, 행에 대한 FFT를 진행한 후 twiddle factor라고 불리는 복소수들을 element-wise하게 곱하고, 다시 열에 대한 FFT를 진행하는 것으로 바꿀 수 있다는 것을 의미한다. 이 때 행 또는 열에 대한 FFT는 16~64 정도로 길지 않으므로 행렬곱으로 바꾸어 계산해도 연산의 개수가 많이 증가하지 않는다. 동시에, 16 정도 크기의 행렬곱은 NVIDIA GPU의 architecture상 Tensor Core를 사용하여 매우 빠르게 계산할 수 있다. 이 때문에 연산의 개수가 증가하지만 오히려 기존 FFT보다 속도가 빨라지는 결과가 나타난다.
Order-$p$ Monarch Decomposition
하지만, Hyena 등과 같이 State Passing 알고리즘을 사용할 수 없는 SSM 기반 모델들도 있기에 FlashConv는 완전한 해결책이 되지 못하였다. 이에 저자들은 FlashFFTConv 논문에서 FlashConv에서 사용했던 기법을 order-$2$ monarch decomposition이라고 정의한 뒤, 이를 확장시켜 higher order monarch decomposition들을 제안한다.
Order-$p$ monarch decomposition은 예상할 수 있듯이, $N = N_{1} \times \cdots \times N_{p}$로 표현하여 FFT를 진행하는 것이다. 단, 각각의 $N_{i}$들이 16의 배수여야 Tensor Core을 충분히 사용할 수 있으며, $p$의 증가는 연산량의 증가를 의미하기에 higher order monarch decomposition들은 long sequence에 대한 FFT에서만 사용하여야 효율성이 보장된다.
논문의 저자들은 관련하여 cost model을 제시한다. 논문의 3.2절과 Figure 4를 보면 더 자세한 설명이 있으나, 결과만 언급하자면 2K까지는 $p=2$, 32K까지는 $p=3$을, 64K부터는 $p=4$를 사용하는 것이 좋다고 한다. 이는 4K = $16^3$, 64K = $16^4$임에서 나온다. 또한, order-$4$에서는 on-chip SRAM cache 용량의 제한 때문에 전체 sequence를 담을 수 없어, 행렬곱-(order-$3$ monarch decomposition)-행렬곱 각각을 별도의 GPU kernel을 사용해 계산한다.
이를 통해 H100-SXM GPU에서 cuFFT 기반의 구현과 비교하여 sequence length 1K에서는 6.54배 빠르며, 8K까지는 4배 이상 빠른 convolution 계산이 가능하다. 다만, $p=4$에서는 2배 이상 빨라지지는 못했는데 이는 연산량의 증가로 인한 결과로 생각된다.
Filter Reuse and Kernel Fusion
SSM에서의 convolution은 $y = (x * K) = \text{IFFT}(\text{FFT}(x) \times \text{FFT}(K))$와 같이 표현할 수 있는데, 여러 개(multi batch)의 $x$에 대해서 filter $K$는 일정하기 때문에 $\text{FFT}(K)$는 미리 계산해둔 후 batch-wise하게 reuse할 수 있다. 이외에도 FFT matrix $F$, $F^{-1}$, twiddle factor matrix $t$, $t_{inv}$는 batch뿐만 아니라 hidden dim 방향으로도 reuse할 수 있기 때문에 성능을 더 높일 수 있다. 자세한 psuedocode는 논문의 Algorithm 1을 참고하면 좋을 것 같다.
또한, 위에서 설명한 알고리즘에서 굳이 중간 과정을 저장할 필요가 없기 때문에 모든 계산 과정을 한 번에 처리하여 $x$와 $\text{FFT}(K)$를 입력으로 받아 바로 $y$를 출력하도록 CUDA kernel을 구현하였다. 이뿐만 아니라 ML에서는 convolution 이후의 결과값을 다른 값과 elementwise multiplication을 하는 경우도 많기 때문에 해당 과정까지 한 번에 진행하도록 구현하였다. 이 경우 논문에서 언급하는 최대 성능 향상인 7.93배를 확인할 수 있다. 이를 kernel fusion이라고 한다.
Sparse Convolution
논문의 저자들은 근사를 통해 연산을 더욱 가속시키는 추가적인 알고리즘으로 partial convolution, frequency-sparse convolution을 추가적으로 제시하였다. 해당 알고리즘에 대해서는 논문의 3.3과 부록을 참고하면 좋을 것 같다.
Conclusion
최근 ML에서 long convolution을 사용하는 SSM(State Space Model) 기반의 모델 구조가 큰 관심을 받고 있는데, FlashFFTConv는 트렌드에 맞추어 뻔한 주제가 될 수 있는 FFT를 바탕으로도 좋은 building block을 제시한 논문이라고 생각한다.
이뿐만 아니라 Problem Solving(PS)에서도 다항식 곱셈으로 대표되는, long sequence의 convolution을 계산하는 것은 유의미한 task이고 계산과학에서도 fourier transform은 자주 사용되는 기법이다. 물론 해당 논문에서는 FP16/BF16만을 target으로 하기에 지금 당장 HPC(High Performance Computing) 관련 application들에 적용하기에는 precision 문제가 있겠지만, ICLR 리뷰를 보면 저자들도 해당 문제에 관해 인식하고 있는 것 같고 알고리즘이 FP16/BF16에 심하게 dependent하지는 않아 확장될 여지가 있을 것이다.
다만, 최근 FFT convolution 대신 parallel scan을 사용하면서 filter을 precompute할 필요가 없어 selective한 특성을 구현할 수 있는 Mamba가 발표되었다. FFT convolution을 사용하는 SSM 기반 모델들이 Mamba 대비 어떠한 이점을 가질 수 있을지 많은 연구가 필요할 것 같다.