Suffix Automaton으로 Suffix Array 문제들을 풀어보자 1
최근 공부 중에 Suffix Automaton이라는 자료 구조를 새로 알게 되어, Suffix Array 태그가 붙은 문제들을 전부 Suffix Automaton으로 풀어보려 시도했습니다. 그리고 꽤 많은 문제들이 Suffix Automaton을 사용할 때 훨씬 편리하게 풀린다는 것을 발견했습니다. 그 과정에서 알게 된 여러 테크닉들을 정리하고자 합니다.
이 글에서는 Suffix Automaton 자체에 대한 상세한 설명보다는 문제 풀이에 필요한 개념 위주로 간략하게 설명합니다. 아래에 Suffix Automaton에 대해 자세히 설명된 글이 있으니, 참고하시면 좋을 것 같습니다.
Suffix Automaton이란?
Suffix Automaton을 간단히 설명하면 Suffix Trie의 효율적인 구현이라고 할 수 있습니다. 문자열 $S$의 모든 Suffix를 Trie에 넣는다고 생각해 봅시다. Trie가 무엇인지에 대해서는 이 글에서 다루지 않으므로, 다른 글을 참고하시기 바랍니다.
Trie를 이용하면 어떤 문자열 집합 ${S_1, S_2, \cdots, S_n}$에서 어떤 문자열 $P$를 Prefix로 가지는 원소가 존재하는지 $O(\vert P\vert )$에 검사할 수 있습니다. 그렇다면 Trie에 들어있는 것이 $S$의 모든 Suffix라면 어떻게 될까요?
어떤 문자열 $S$의 모든 부분 문자열은 $S$의 Suffix의 Prefix이므로, 어떤 문자열 $P$가 $S$의 부분 문자열인지 $O(\vert P\vert )$에 검사할 수 있을 것입니다. 또한, Trie에 있는 각각의 노드는 정확히 하나의 부분 문자열에 대응될 것입니다.
$S=\rm{abcbc}$일 때 $S$의 Suffix들인 ${\rm{abcbc}, \rm{bcbc}, \rm{cbc}, \rm{bc}, \rm{c}}$로 Suffix Trie를 구성하면 아래와 같습니다.
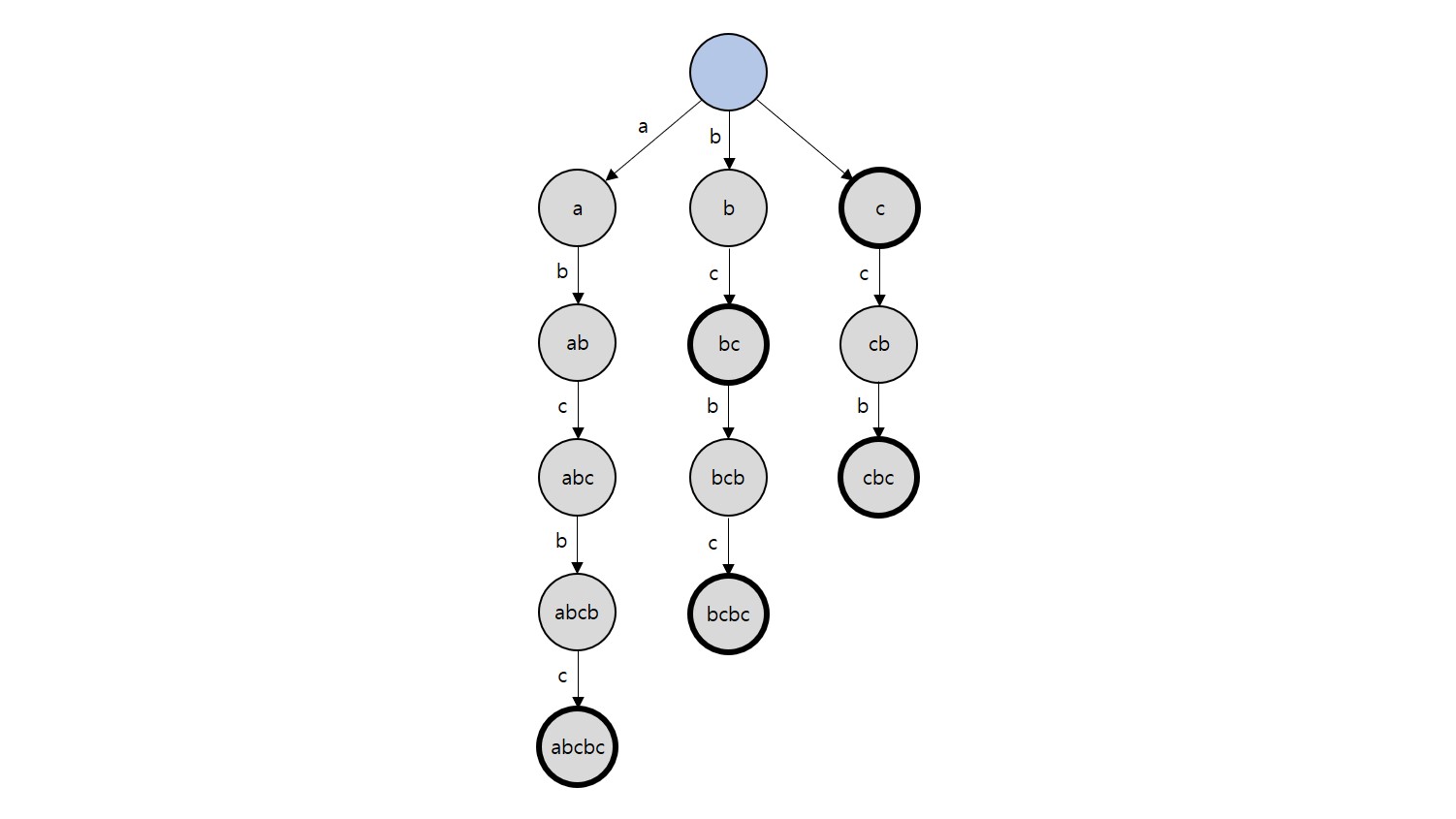
아래 그림처럼 $S$의 부분 문자열인 $\rm{bcb}$는 Trie에서 찾을 수 있고, $S$의 부분 문자열이 아닌 $\rm{aba}$는 Trie에서 찾을 수 없습니다.
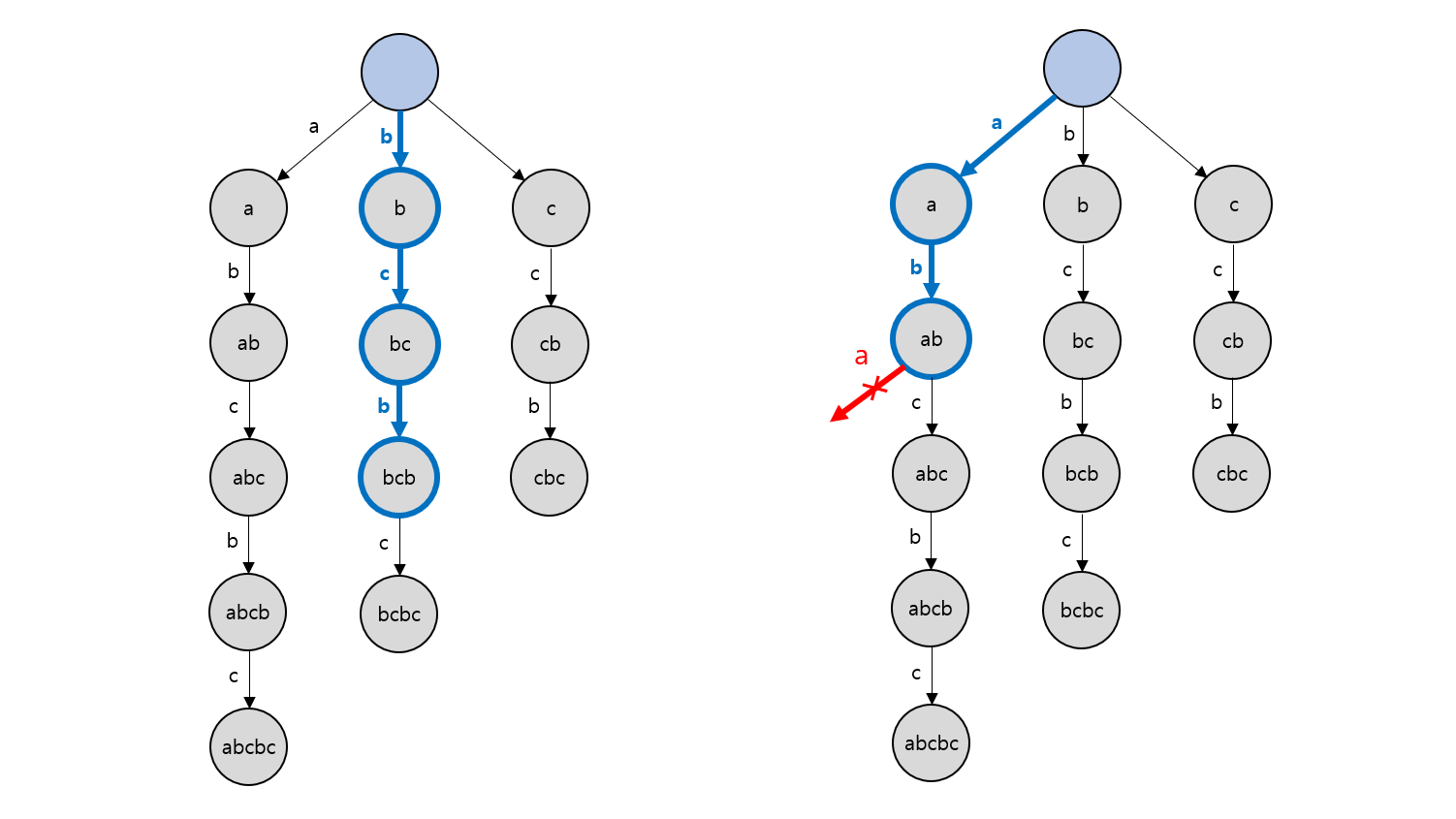
결국 어떤 문자열 $S$에서 부분 문자열 $P$가 등장하는지를 $O(\vert P\vert )$ 시간에 알 수 있게 되며, 이러한 Suffix Trie를 구성할 수만 있다면 문자열 $S$의 부분 문자열을 다루는 데에 있어 강력한 도구가 될 것입니다. 그러나 구성에 걸리는 시간이 $O(\vert S\vert ^2)$이고, 노드의 개수 역시 $O(\vert S\vert ^2)$이기에 실제로 활용하기는 사실상 불가능합니다. 따라서, 다른 방법이 필요합니다.
Suffix Automaton은 하나의 노드에 여러 개의 문자열이 대응될 수 있게 함으로써 $O(\vert S\vert )$개의 노드만으로 Suffix Trie의 기능을 유지하는 자료구조입니다. 또한, Suffix Automaton을 구성하는 과정에서 Suffix Link 등의 유용한 추가 정보도 얻을 수 있습니다. 다음은 위와 동일하게 $S=\rm{abcbc}$로 Suffix Automaton을 만든 결과입니다.
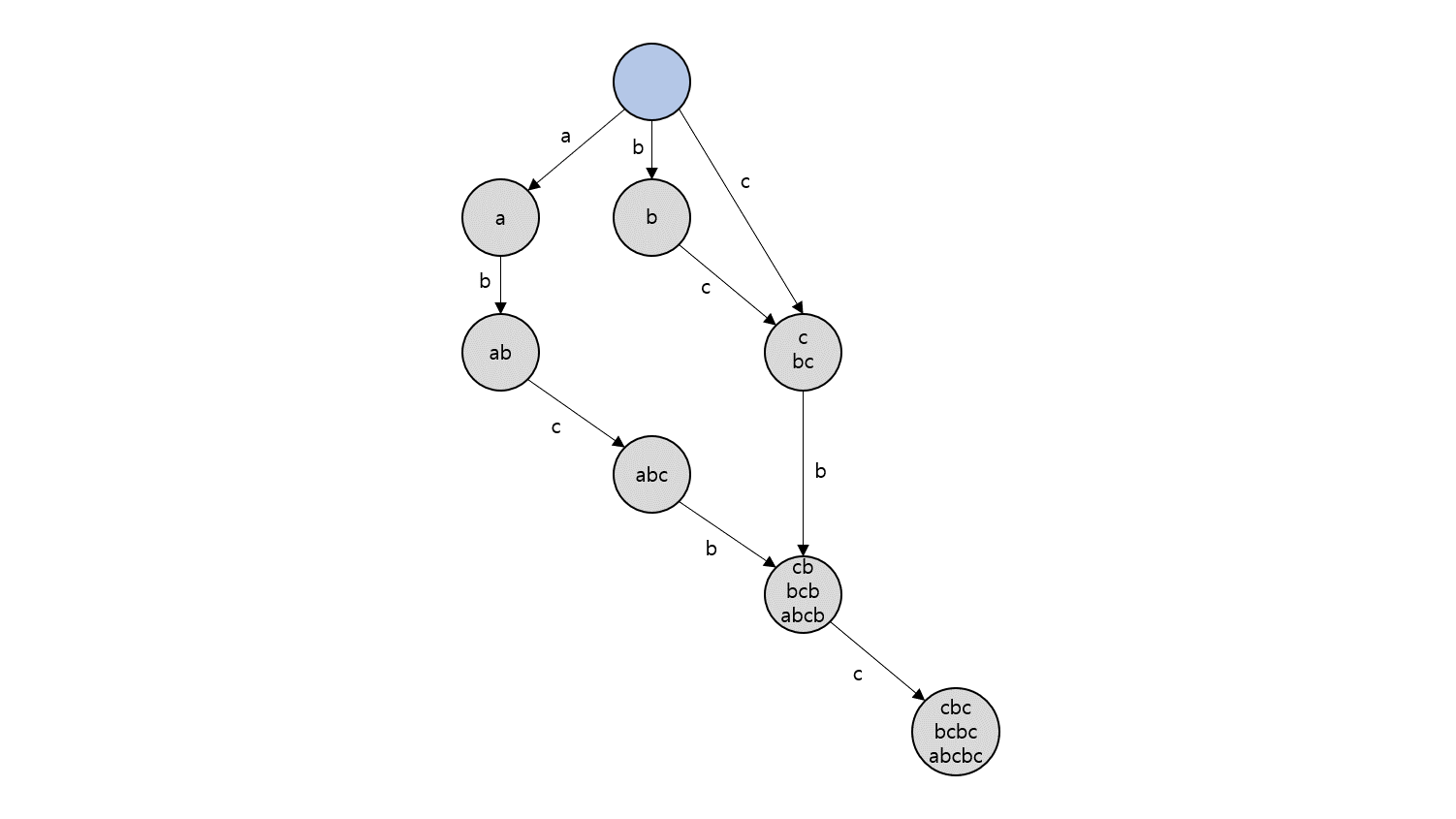
Suffix Trie와 동일하게, 루트 노드에서부터 글자를 하나씩 따라가면 $\rm{bcb}$는 찾을 수 있고 $\rm{aba}$는 찾을 수 없습니다. 단, 차이점은 한 노드에 여러 문자열이 대응될 수 있다는 것입니다.
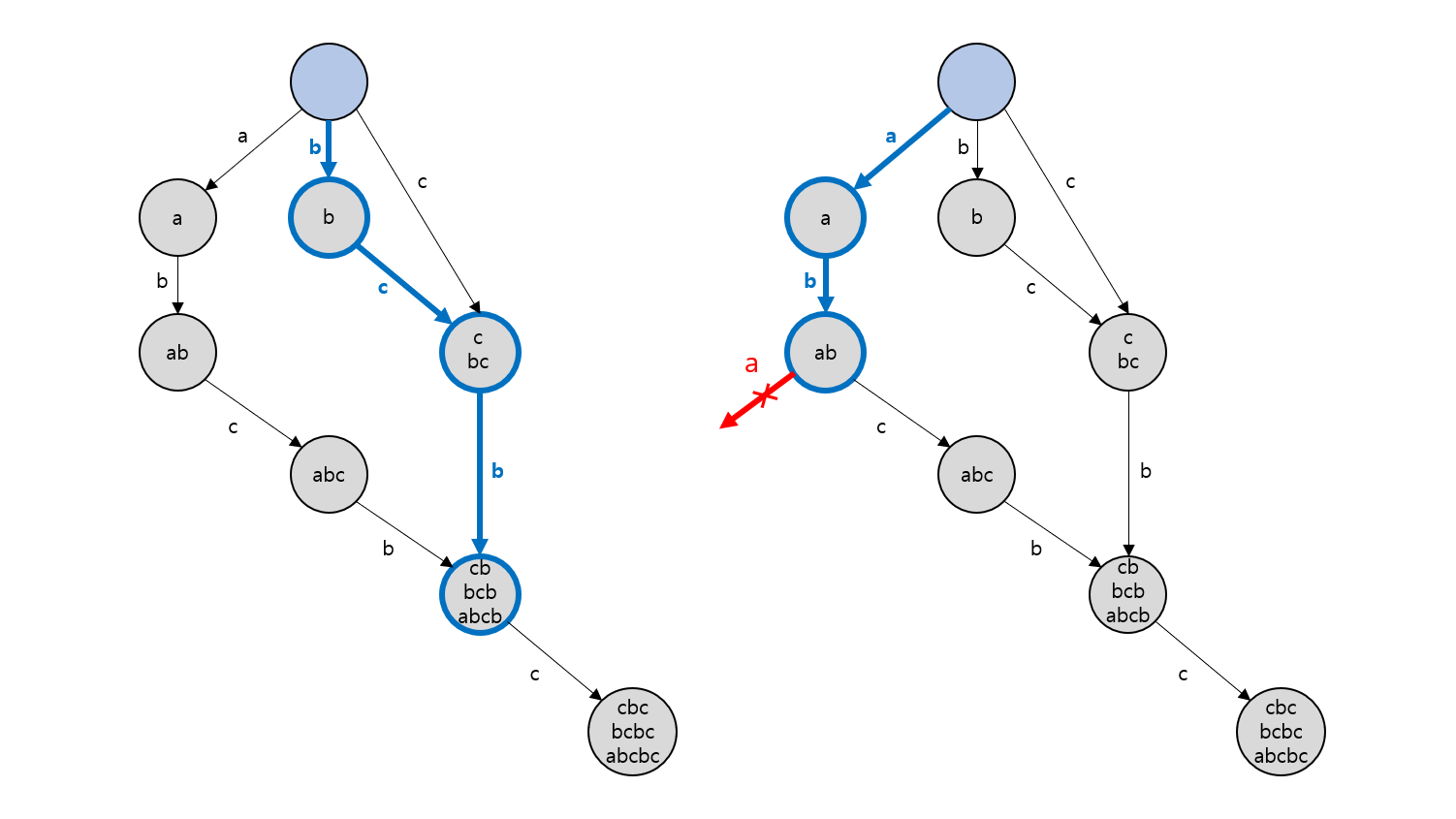
상태
위에서 Suffix Automaton의 한 노드(상태, state라고도 불리움)에는 여러 개의 문자열이 대응된다고 언급했습니다. 한 노드에는 구체적으로 어떤 문자열들이 대응될까요?
Suffix Automaton에 문자열 $S$가 들어있다고 합시다. $S$의 어떤 부분 문자열 $P$에 대해, $S$에서 $P$가 등장하는 위치를 전부 찾아봅시다. 이 때, $S$에서 $P$가 등장하는 위치를 등장하는 $P$의 오른쪽 끝 인덱스로 표현합시다.
예를 들어 $S=\rm{banana}$이면, $\rm{a}$가 등장하는 오른쪽 끝 인덱스는 각각 $1, 3, 5$이고, $\rm{ana}$가 등장하는 오른쪽 끝 인덱스는 $3,5$입니다.
이처럼 $S$에서 $P$가 등장하는 오른쪽 끝 인덱스의 집합을 $endpos(P)$라고 합시다. $S=\rm{abcbc}$라면, 각 부분 문자열에 대한 $endpos$는 아래와 같이 구할 수 있습니다.
- $endpos(\rm{a}) = {0}$
- $endpos(\rm{ab}) = {1}$
- $endpos(\rm{abc}) = {2}$
- $endpos(\rm{abcb}) = {3}$
- $endpos(\rm{abcbc}) = {4}$
- $endpos(\rm{b}) = {1, 3}$
- $endpos(\rm{bc}) = {2, 4}$
- $endpos(\rm{bcb}) = {3}$
- $endpos(\rm{bcbc}) = {4}$
- $endpos(\rm{c}) = {2, 4}$
- $endpos(\rm{cb}) = {3}$
- $endpos(\rm{cbc}) = {4}$
여기서 $endpos(P)$가 동일한 문자열들을 모아보면,
- ${0} : \rm{a}$
- ${1} : \rm{ab}$
- ${2} : \rm{abc}$
- ${3} : \rm{cb, bcb, abcb}$
- ${4} : \rm{cbc, bcbc, abcbc}$
- ${1, 3} : \rm{b}$
- ${2, 4} : \rm{c, bc}$
이는 위에서 $S=\rm{abcbc}$로 만든 Suffix Automaton에서 각 노드에 대응되는 문자열들의 목록과 일치합니다.
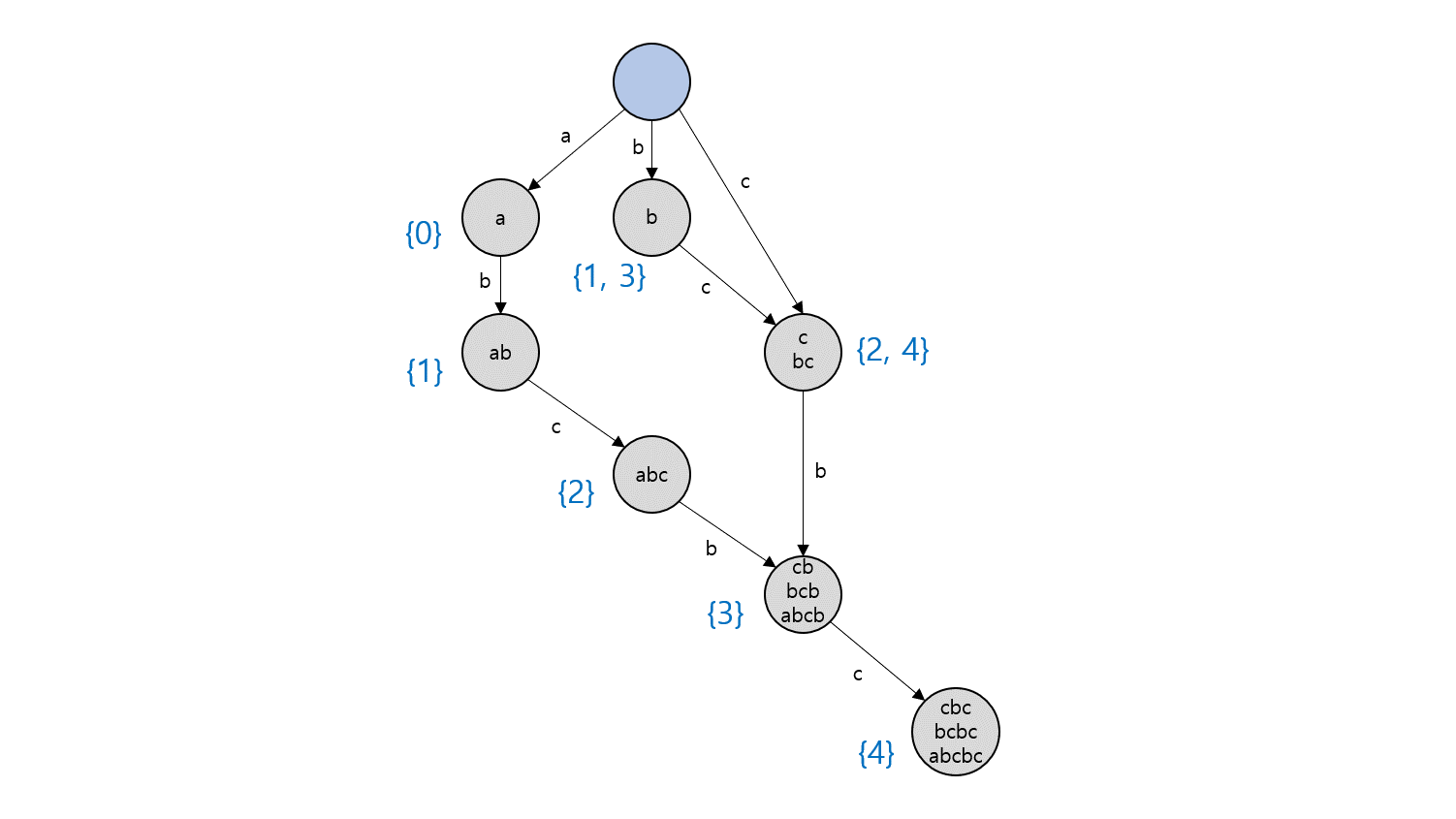
이처럼 Suffix Automation은 $endpos$가 동일한 문자열들을 하나의 노드에 대응시키는 규칙을 가지고 있습니다. 즉, Suffix Automaton의 한 노드에는 발생하는 끝 지점의 집합이 동일한 모든 부분 문자열들이 대응됩니다.
그러나 Suffix Automaton을 만들 때 각 노드에 대응되는 문자열을 실제로 모두 찾아서 저장하기에는 공간이 너무 많이 소모됩니다. 따라서, Suffix Automaton은 최소한의 정보로 한 노드에 대응되는 문자열들을 표현하게 됩니다.
struct Node {
int len;
Node *link;
};
Suffix Automaton의 한 노드에는 두 개의 속성이 있는데, 하나는 정수 $len$이고 나머지 하나는 다른 노드를 가리키는 포인터 $link$입니다. 어떻게 $len$과 $link$만으로 한 노드에 대응되는 부분 문자열들을 전부 표현할 수 있는걸까요?
문자열 $S$의 임의의 부분 문자열 $P=S[l..r]$를 잡아봅시다. 그리고 어떤 문자열들이 $P$와 같은 $endpos$를 가지는지 규칙을 찾아봅시다. 직관적인 이해를 위해 $P$의 오른쪽 끝점을 고정하고, 왼쪽 끝점을 이리저리 움직인다고 상상해 봅시다. 무슨 일이 일어날까요?
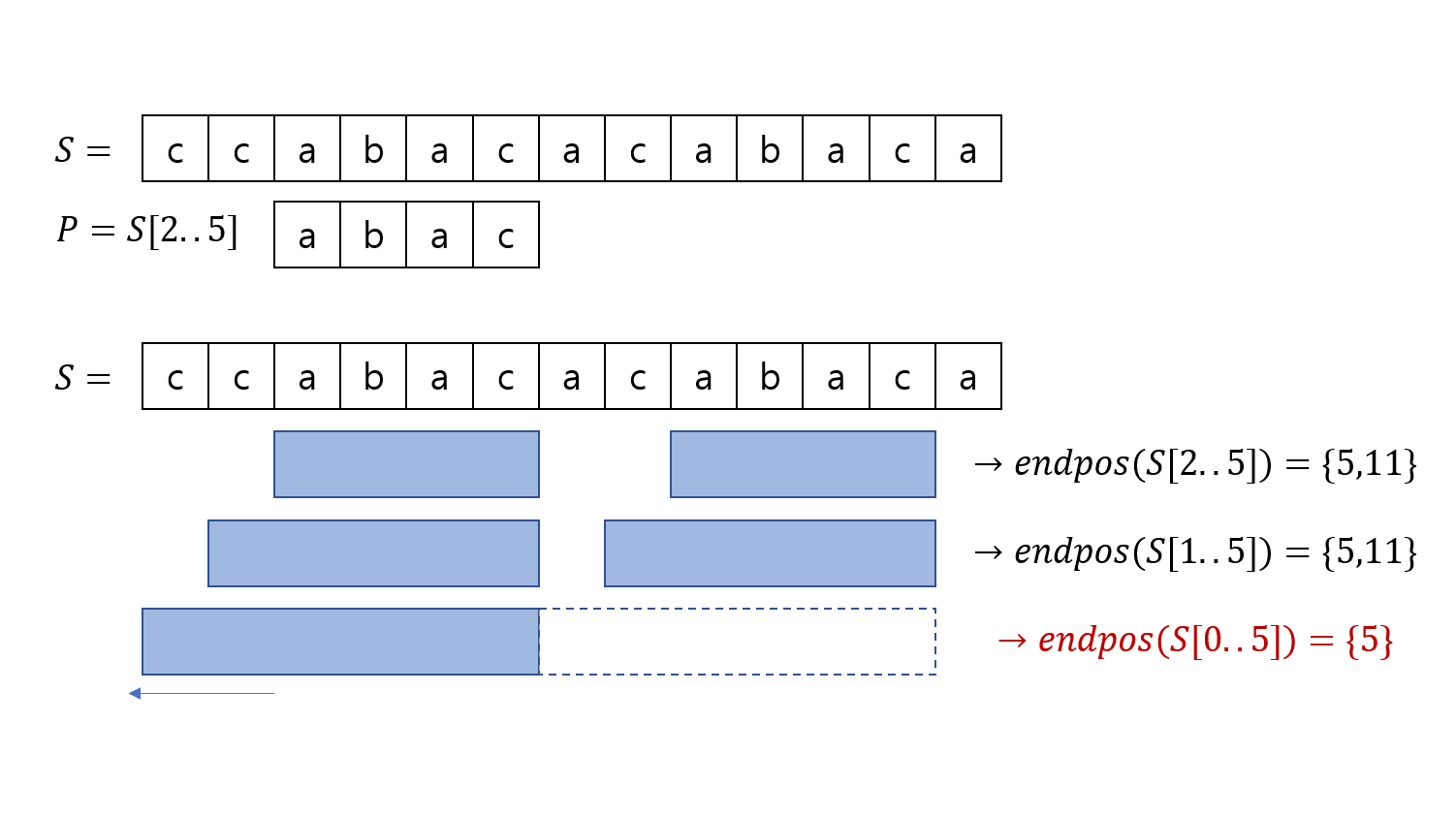
아래는 이해를 돕기 위한 $S=\rm{ccabacacabaca}$이고, 부분 문자열 $P=S[2..5]=\rm{abac}$인 예시입니다. $S$에서 $P$가 나타나는 모든 부분을 파란색으로 표시했습니다.

$P$의 왼쪽 끝점을 바깥쪽으로 점점 늘리다 보면 어느 순간 $endpos$가 달라지게 됩니다. 문자열이 왼쪽으로 길어질수록 출현 조건이 강화되는 셈이니, 기존에 있던 $endpos$의 지점 하나(혹은 여러개)가 사라지는 순간이 있을 것입니다.
이번에는 반대로 $P$의 왼쪽 끝점을 안쪽으로 점점 줄인다고 생각해 봅시다. 이번에도 마찬가지로, 줄이다 보면 어느 순간 $endpos$가 달라집니다. 문자열이 짧아질수록 출현 조건이 약화되는 셈이니, 새로운 지점이 $endpos$에 추가되는 순간이 존재하겠죠.
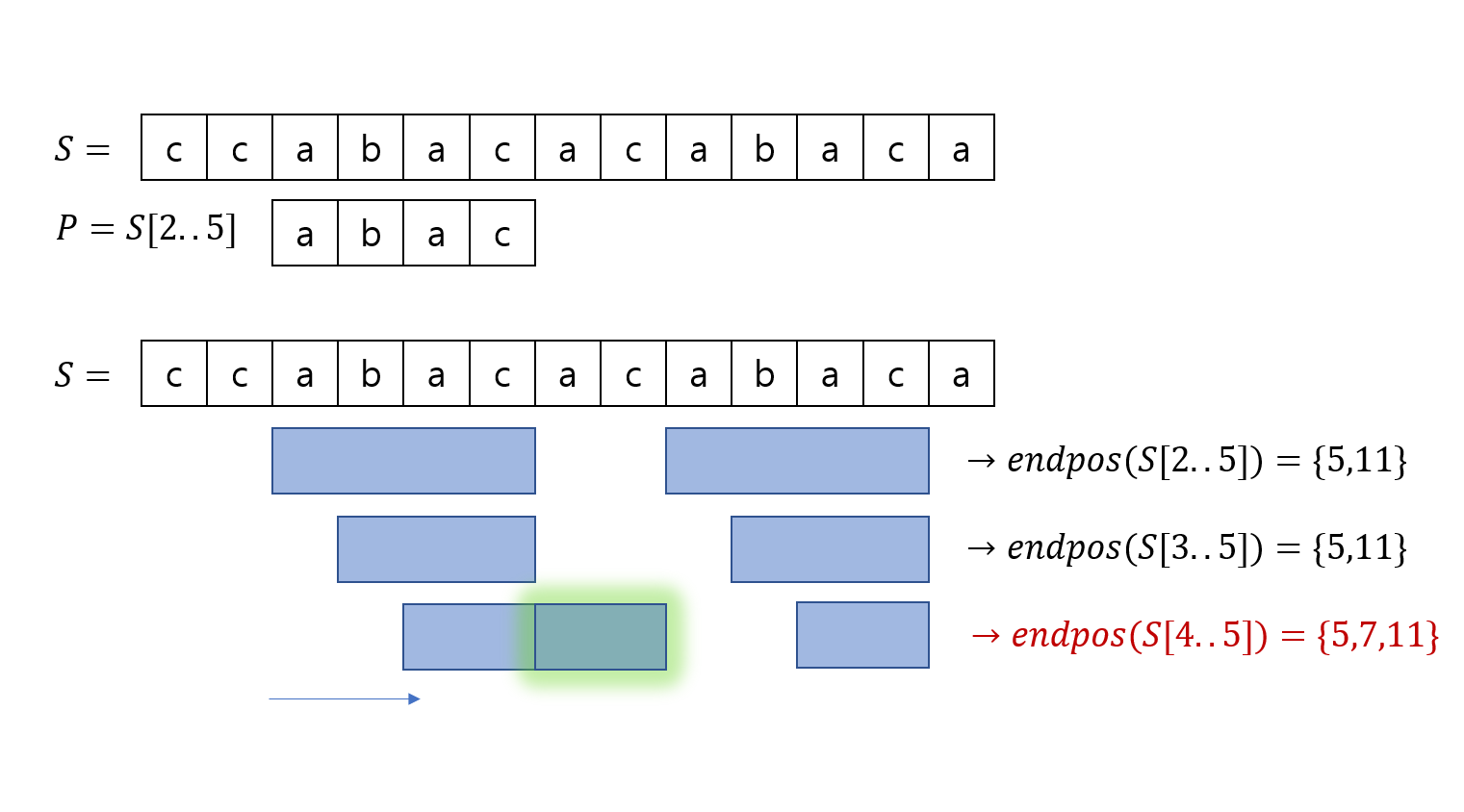
따라서, $P=S[l..r]$에서 오른쪽 끝점 $r$을 고정하고 왼쪽 끝점 $l$ 을 좌우로 이동했을 때 $endpos$를 같게 유지할 수 있는 가장 왼쪽 지점 $l_{min}$과 가장 오른쪽 지점 $l_{max}$가 존재할 것입니다.
또한, $l_{min}\le l \le l_{max}$를 만족하는 모든 부분 문자열 $S[l..r]$들은 모두 동일한 $endpos$를 가진다는 것을 알 수 있습니다. $endpos$가 동일하다는 것은, 이 부분 문자열들이 모두 같은 노드에 대응된다는 것을 의미합니다.
따라서 $endpos={5,11}$에 해당하는 문자열을 아래처럼 묶어서 표시할 수 있습니다.
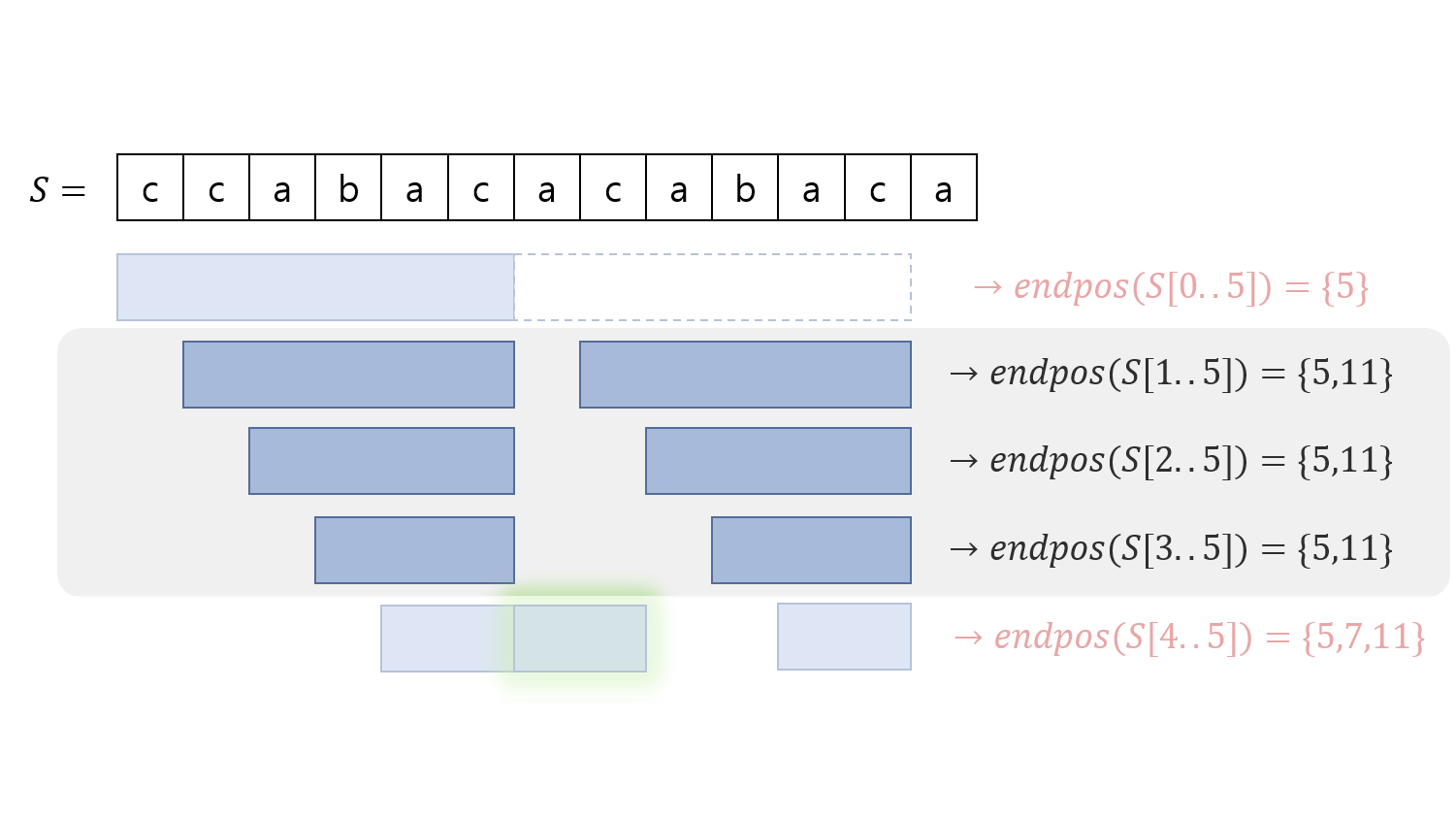
그러므로 Suffix Automaton의 한 노드에 대응되는 문자열들은 일종의 연속적인 구간을 형성함을 직관적으로 볼 수 있고, 구간의 시작과 끝에 해당하는 정보만 저장해도 이 구간을 표현할 수 있게 됩니다. (이는 단순히 이해를 돕기 위한 설명일 뿐 전혀 엄밀한 내용이 아니므로 유의하시기 바랍니다.)
위에서 소개한 노드의 $len$과 $link$가 바로 그 역할을 하는 속성들입니다.
노드의 $len$ 속성은 해당 노드에 대응되는 부분 문자열의 왼쪽 끝점을 바깥쪽으로 점점 늘릴 때, $endpos$를 동일하게 유지하면서 왼쪽으로 늘릴 수 있는 최대치의 길이입니다. 즉, 한 노드가 표현하는 부분 문자열들 중 가장 긴 것의 길이입니다. 예를 들어, 위의 예시에서 $endpos={5,11}$에 해당하는 노드를 $v$라 하면 $v.len$은 $5$가 될 것입니다.

노드의 $link$ 속성은 해당 노드에 대응되는 부분 문자열의 왼쪽 끝점을 안쪽으로 점점 줄일 때 처음으로 $endpos$가 달라지는 지점이 존재할 텐데요, 그때 달라진 $endpos$에 해당하는 노드를 향하는 포인터입니다. ($endpos$가 달라진다는 건, 결국 그 문자열에 대응되는 노드가 달라진다는 것이니까요.)
예를 들어, 위의 예시에서 $endpos={5,11}$에 해당하는 노드를 $v$라 하면 $v.link$는 ${5,7,11}$에 해당하는 노드 $w$를 향하는 포인터가 될 것입니다.
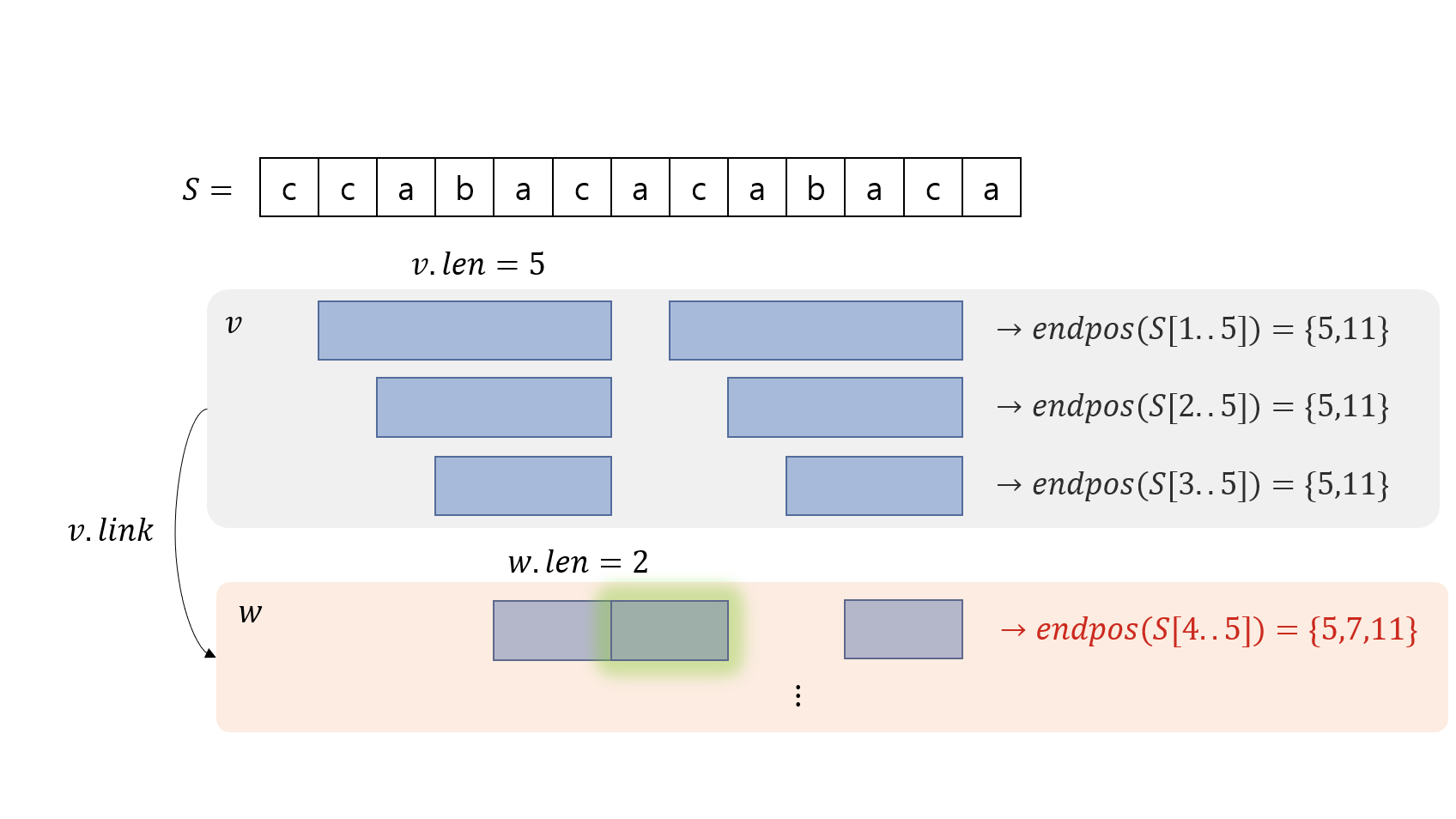
따라서, 어떤 노드 $v$에 대응되는 부분 문자열들 중 왼쪽 끝점을 바깥쪽으로 가장 길게 늘릴 수 있는 길이는 $v.len$, 안쪽으로 줄였을 때 가장 처음 $endpos$가 달라지는 지점의 문자열 길이는 $v.link.len$입니다.
그러므로, 어떤 노드 $v$에 해당하는 $endpos$에서 오른쪽 끝점 $r$을 하나 뽑았을 때, ($endpos$의 정의상 아무거나 뽑아도 동일한 문자열을 의미하게 됩니다.) 어떤 노드 $v$가 표현하는 $S$의 부분 문자열들은,
- $S[r-v.len+1.. r]$
- $S[r-v.len+2.. r]$
- $\cdots$
- $S[r-v.link.len-1..r]$
- $S[r-v.link.len..r]$
위처럼 나열할 수 있습니다. 즉, 오른쪽 끝점 $r$을 고정했을 때 왼쪽 끝점 $l$이 $r-v.len+1 \le l \le r-v.link.len$ 을 만족하는 부분 문자열 $S[l..r]$의 집합입니다. 따라서, 어떤 노드 $v$가 표현하는 서로 다른 부분 문자열의 개수는 $v.len - v.link.len$임도 알 수 있습니다.
위에서 예시로 제시했던, $S=\rm{abcbc}$로 만든 Suffix Automaton에 $len$과 $link$를 표시하면 아래와 같습니다. 각 노드의 $link$는 빨간색 화살표로 표시되었습니다.
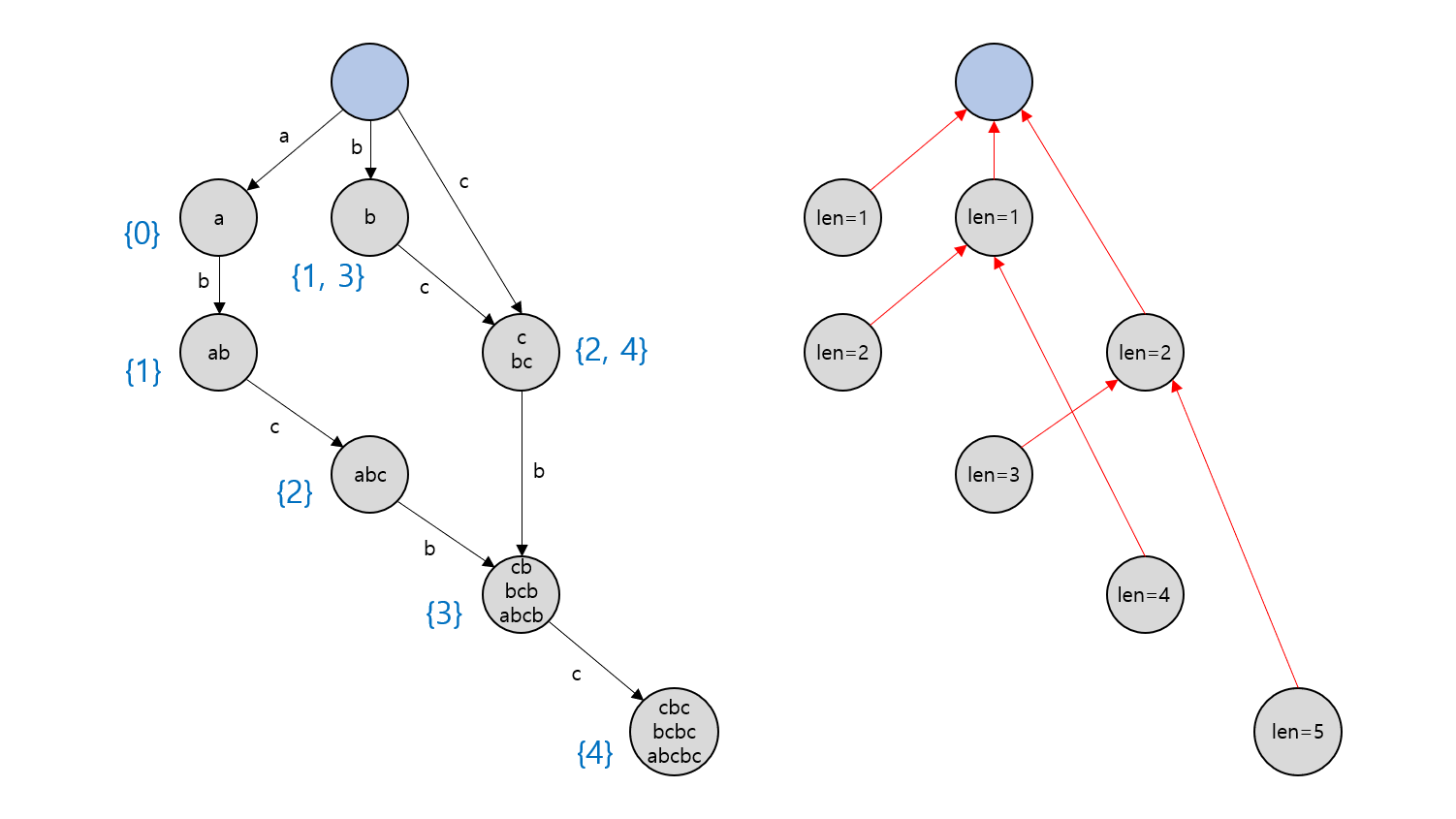
각 노드 $v$에 대응되는 부분 문자열의 개수가 $v.len - v.link.len$과 동일함을 쉽게 확인할 수 있습니다. (루트 노드의 $len$은 $0$으로 정의됩니다.)
위의 그림에서 노드마다 써져 있는 문자열의 목록과 $endpos$ 집합은 실제로 존재하는 데이터가 아님에 유의하세요. $len$과 $link$만으로도 충분히 Suffix Automaton을 구성할 수 있기 때문에, 각 노드에 대응되는 문자열에 관한 정보는 오른쪽 그림처럼 $len$과 $link$가 전부입니다. 또한 $len$과 $link$ 만으로는 현재 노드가 표현하는 문자열이 실제로 무엇인지 알 수 없다는 점도 유의하시기 바랍니다.
위의 설명에서 나온 것처럼, 실제 문자열을 복구하려면 오른쪽 끝점 $r$이 될 $endpos$의 원소를 적어도 하나 알아야 하며, 이를 위해서는 Suffix Automaton의 각 노드에서 추가적인 정보를 관리해 주어야 합니다. 자세한 내용은 아래 링크를 참고하시기 바랍니다.
https://cp-algorithms.com/string/suffix-automaton.html#first-occurrence-position
그러나 원래 문자열이 무엇이었는지 알 필요 없이 풀 수 있는 문제들도 꽤 많기 때문에, 필요에 따라 구현하여 사용하시면 되겠습니다.
이 글에서는 $len$과 $link$의 이해를 돕기 위해 직관적인 개념 위주로 설명하였습니다. 단순 문제 풀이를 위해서는 이 정도로만 이해해도 충분하고, 위 설명이 딱히 틀렸다고 볼 수도 없지만 엄밀함이 부족한 것은 사실입니다.
이 글에 증명이 단 하나도 없는 것은 직관적인 이해를 위해 의도된 것이며, $len$과 $link$가 어떻게 엄밀하게 정의되는지는 Suffix Automaton을 설명한 다른 글들을 참고하는 것을 추천드립니다.
DAG
위에서 Suffix Automaton이 어떻게 상태(혹은 노드)를 정의하는지 알아보았는데요, 놀라운 점은 위처럼 상태 정의를 하더라도 노드끼리 잘만 연결해주면 문자열의 모든 부분 문자열을 찾을 수 있는 Suffix Trie의 성질을 유지할 수 있다는 것입니다.
실제로 Suffix Automaton을 구성하게 되면, 모든 노드들은 현재 노드가 표현하는 임의의 문자열 뒤에 문자 $c$를 추가했을 때 어느 노드로 이동하는지, 즉 다음 노드에 대한 정보를 가지게 됩니다. 아래 그림에서 간선에 문자가 적힌 간선들로 이루어지는 것이 바로 Suffix Automaton의 DAG입니다.
한 노드에 대응되는 문자열이 여러 개인데 이런 일이 가능하다는건, 한 노드에 대응되는 여러 문자열들 중 어느 것을 골라도, 뒤에 문자 $c$를 추가했을 때 이동하는 노드가 모두 동일하기 때문이란 것을 확인할 수 있습니다.
또한, 각 노드별로 문자 $c$를 추가했을 때 어떤 노드로 이동해야 하는지, 즉 다음 노드가 무엇인지는 Trie를 구현할 때와 동일하게 특정 자료구조(ex. map)을 이용하여 저장할 수 있습니다. 후술하겠지만 map은 예시일 뿐, 다른 자료구조를 사용하는 경우도 자주 있습니다.
struct Node {
int len;
Node* link;
map<char, Node*> next;
}
Suffix Automaton의 DAG는 Suffix Trie의 성질을 유지하고 있지만, 한 가지 차이점은 Suffix Automaton의 노드가 연결되어 있는 구조가 트리가 아닌 DAG라는 점입니다.
즉, 루트 노드에서 어떤 노드에 도달하는 경로가 유일하지 않을 수 있으며, Suffix Automaton에서 서로 다른 문자열을 찾더라도 같은 노드에 도달할 가능성이 있다는 것을 의미합니다. 이는 Suffix Automaton에서 한 노드가 여러 개의 문자열에 대응될 수 있다는 점을 생각하면 자연스럽다고 볼 수 있습니다.
또한 이러한 연결 관계가 DAG의 성질을 가지고 있기 때문에, Suffix Automaton의 DAG 상에서 DP(Dynamic Programming)를 진행해 줄 수 있습니다. 어떤 문제에서 DP를 활용할 수 있는지는 다음 포스트에서 다루도록 하겠습니다.
Suffix Link
Suffix Automaton의 DAG도 유용한 성질이지만, Suffix Automaton을 문제풀이에 활용할 수 있는 핵심은 단연 Suffix Link라고 해도 과언이 아닙니다.
Suffix Link는 위의 상태 정의에서 이야기한 $link$를 의미합니다. $link$는 현재 노드가 표현하는 문자열의 왼쪽 끝을 안쪽으로 점점 줄일 때, $endpos$가 처음으로 달라지는 지점에 해당하는 노드를 향하는 포인터입니다.
따라서 문자열 $P$가 대응되는 노드를 $v$라 하고, $v$에서 Suffix Link를 타고 이동하면, $P$의 Suffix 중에서 $v$가 표현하지 못하는 가장 긴 $P$ 의 Suffix로 이동하게 됩니다. 아래는 $S=\rm{abcbc}$로 만든 Suffix Automaton에서 Suffix Link를 표시한 것입니다.
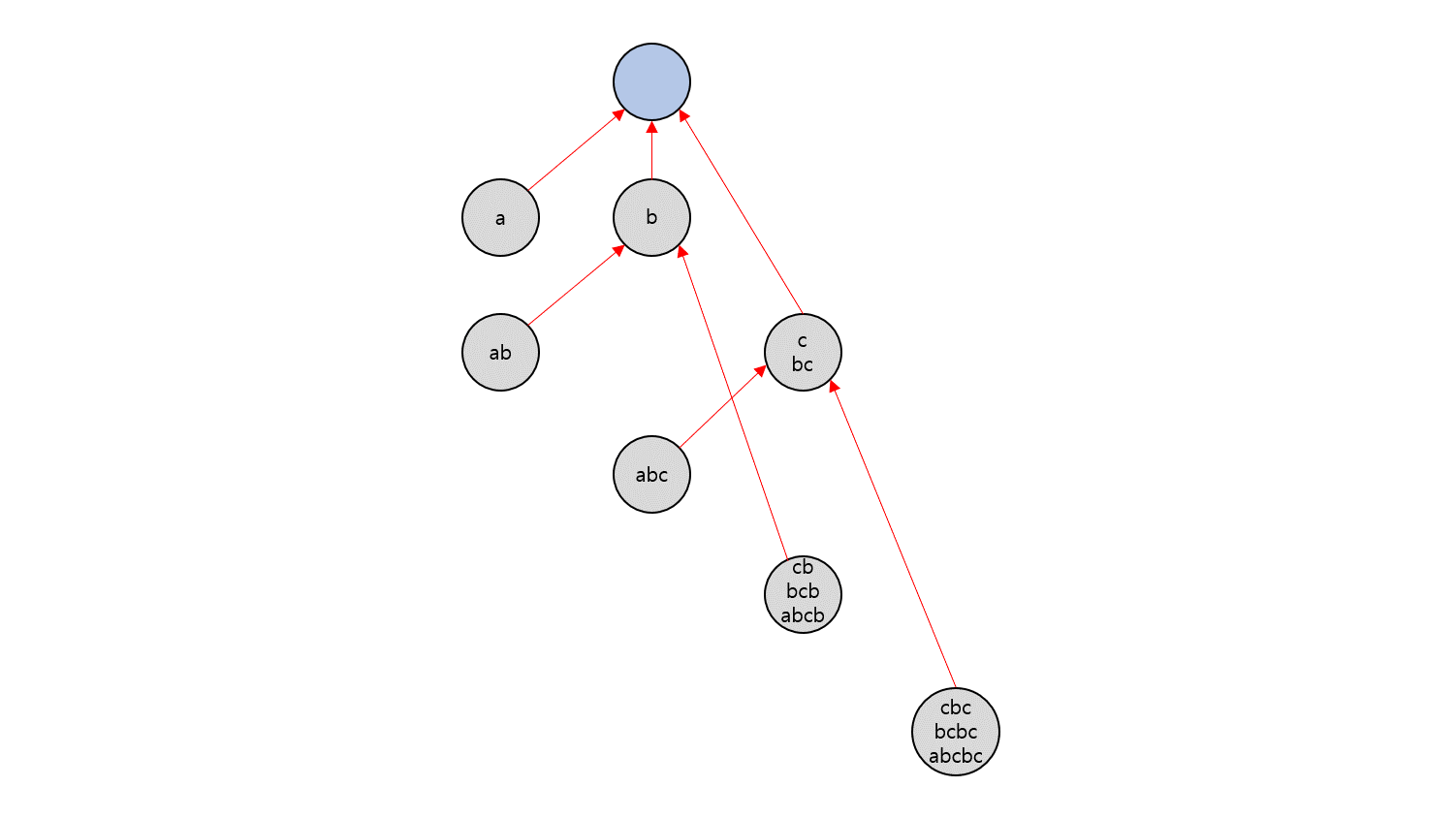
Suffix Link를 이어보면 결국 루트 노드를 루트로 하는 트리 구조를 가집니다. Suffix Link를 타고 올라가는 것은 자신의 더 짧은 Suffix를 표현하는 노드로 이동한다는 의미이므로, 결국에는 모든 문자열의 Suffix인 빈 문자열에 도달하게 될 것입니다. 루트 노드는 빈 문자열을 의미하는 노드로도 볼 수 있기 때문에 DAG의 루트 노드가 Suffix Link로 이루어진 트리에서도 루트를 담당합니다.
Suffix Link로 트리를 만들면 어떤 문자열의 Suffix에 관한 정보를 트리에서 쉽게 다룰 수 있게 됩니다. 예를 들어, 문자열 $P$가 어떤 노드 $v$에 대응된다고 합시다. 그러면 아래와 같은 분석이 가능합니다.
- $P$의 모든 Suffix를 보려면, $v$를 포함해 $v$의 모든 조상들을 보면 됩니다.
- 반대로, $P$를 Suffix로 가지는 모든 부분 문자열을 보려면 $v$를 포함해 $v$를 루트로 가지는 서브트리에 있는 모든 노드를 보면 됩니다.
이러한 성질은 위의 그림에서도 쉽게 확인할 수 있습니다. 또한 Suffix Link가 트리 구조를 가지기 때문에 DP, Sparse Table, Lowest Common Ancestor, Heavy Light Decomposition 등의 다양한 테크닉과 같이 활용할 수 있습니다. 이를 활용해서 풀 수 있는 문제 역시 다음 포스트에서 다루도록 하겠습니다.
알고리즘
Suffix Automaton을 만드는 $O(n)$ 알고리즘은 문자를 하나씩 넣으며, 새로 발생하는 문자열들에 해당하는 노드를 만들어준 후 기존의 DAG와 Suffix Link에 올바르게 연결해주는 방식으로 구현됩니다.
알고리즘 및 구현에 대한 상세한 내용은 이 글에서 다루지 않으며, 관심이 있으신 분들은 아래 링크를 참고하시기 바랍니다.
https://cp-algorithms.com/string/suffix-automaton.html#construction-in-linear-time
시간/공간 복잡도
Suffix Automaton을 만드는 알고리즘의 시간/공간복잡도는 기본적으로 둘 다 $O(n)$으로 보아도 무방하지만, 각 노드의 DAG 상의 다음 노드들을 저장할 때 어떤 자료구조를 사용하냐에 따라 디테일한 차이가 존재할 수 있습니다. 문자열에 존재하는 서로 다른 알파벳 종류의 개수를 $k$라고 합시다.
struct Node {
int len;
Node* link;
map<char, Node*> next;
}
위처럼 map을 이용한 구현을 하는 경우, Suffix Automaton에 문자 하나를 추가할 때 필요한 시간 복잡도는 $O(\log k)$가 됩니다. 따라서 전체 시간 복잡도는 $O(n \log k)$, 공간 복잡도는 $O(n)$이 됩니다.
$k$가 충분히 작은 경우 아래처럼 $k$칸의 배열을 이용하여 다음 노드를 저장할 수도 있습니다.
struct Node {
int len;
Node* link;
Node* next[K];
}
위처럼 배열을 이용하는 경우, Suffix Automaton에 문자 하나를 추가할 때 필요한 시간 복잡도는 $O(1)$이 됩니다. 따라서 전체 시간 복잡도는 $O(n)$입니다. 그러나 노드 하나 당 차지하는 공간 복잡도가 $O(k)$이므로 전체 공간 복잡도는 $O(nk)$입니다.
정리하면 다음과 같습니다.
- map을 이용한 구현 : 시간복잡도 $O(n \log k)$, 공간복잡도 $O(n)$
- 배열을 이용한 구현 : 시간복잡도 $O(n)$, 공간복잡도 $O(nk)$
대부분의 상황에서는 $k$가 상수로 주어지므로 어느 쪽이든 시간/공간 복잡도가 $O(n)$이라고 간주할 수 있습니다. 그러나 각각의 방식에 분명한 장/단점이 있으므로, 문제에 따라 적합한 자료구조를 선택하시면 되겠습니디.
또한, 위의 알고리즘대로 문자열 $S$에 대해 Suffix Automaton을 구성하면 최대 $2\vert S\vert -1$개의 노드를 가지고, DAG는 최대 $3\vert S\vert -4$개의 간선을 가짐이 증명되어 있습니다. 증명이 궁금하신 분들은 아래 링크를 참고하시기 바랍니다.
https://cp-algorithms.com/string/suffix-automaton.html#additional-properties
따라서, 존재하는 노드와 간선의 개수가 모두 $O(n)$이기 때문에
- Suffix Automaton의 DAG에서 탐색을 해도 $O(n)$
- Suffix Link로 이루어진 트리에서 탐색을 해도 $O(n)$
- Suffix Automaton 상의 모든 노드를 하나씩 봐도 $O(n)$
의 시간복잡도가 보장됩니다.
구현
아래에 제가 사용하는 구현체를 첨부하였습니다. 각 노드의 다음 노드는 배열로 저장하도록 되어 있습니다. 또한, 위의 설명에서는 다른 노드를 향하는 변수를 포인터로 표현했었습니다. 그러나 구현체에서는 포인터 대신 모든 노드의 배열 $v$을 만들고, 그 배열에서의 인덱스를 이용하여 다른 노드를 향하도록 하였습니다.
struct SuffixAutomaton {
struct Node {
int len, link, nxt[26];
bool has(char c) {
return nxt[c-'a'];
}
int get(char c) {
return nxt[c-'a'];
}
void set(char c, int x) {
nxt[c-'a'] = x;
}
void copy(Node& o) {
link = o.link;
memcpy(nxt, o.nxt, sizeof(nxt));
}
};
int head, tail;
vector<Node> v;
int push_node() {
v.push_back(Node());
return v.size() - 1;
}
SuffixAutomaton() {
push_node(); // dummy
head = tail = push_node(); // root
}
void push(char c) {
int cur = push_node();
v[cur].len = v[tail].len + 1;
v[cur].link = head;
int p = tail;
while(p && !v[p].has(c)) v[p].set(c, cur), p = v[p].link;
if(p) {
int q = v[p].get(c);
if(v[p].len + 1 == v[q].len) v[cur].link = q;
else {
int clone = push_node();
v[clone].copy(v[q]);
v[clone].len = v[p].len + 1;
v[cur].link = v[q].link = clone;
while(p && v[p].get(c) == q) v[p].set(c, clone), p = v[p].link;
}
}
tail = cur;
}
};
어떤 경우에 Suffix Automaton이 좋나요?
Suffix Automaton은 위에서 보듯이 구현이 매우 짧은 편이고, 코드 흐름을 이해하고 외우기도 쉬운 편입니다. 심지어 시간 복잡도도 $O(n)$이기 때문에 Suffix Array에 비해 큰 이점을 가지고 있습니다.
Suffix Array의 경우 잘 알려진 구현은 $O(n \log n)$의 시간 복잡도를 가지고 있으며, $O(n)$ 알고리즘이 존재하긴 하지만 구현이 복잡하다는 단점이 있습니다.
저는 Suffix Array와 Suffix Automaton 둘 다로 문제를 풀 수 있다면 Suffix Automaton으로 문제를 푸는 것을 선호하는 편입니다. 개인적으로 더 쉽고, 더 효율적인 풀이가 되기 때문입니다. 특히, 주로 Suffix Array로 풀린 문제의 Suffix Automaton 풀이를 발견하여 풀었을 때, 특별한 최적화를 하지 않았음에도 실행 시간 1위, 숏코딩 1위를 동시에 차지한 경우가 꽤 있었습니다.
경험상 Suffix Array를 사용하는 문제들 중 부분 문자열의 사전 순 순서가 전혀 중요하지 않은 문제들(ex. 서로 다른 부분 문자열의 개수)의 경우 Suffix Automaton 풀이를 구상하기 쉬웠던 것 같습니다.
또한, Suffix Array와는 Suffix Automaton은 다르게 뒤에 문자를 하나씩 넣으면서 구축할 수 있기 때문에(즉, Incremental하기 때문에), 특정 쿼리 문제를 Online으로 풀 수 있다는 장점 역시 존재합니다.
Suffix Automaton 자체만을 이용하는 테크닉
이 섹션에서는 다른 추가적인 알고리즘 없이 Suffix Automaton만을 활용하여 풀 수 있는 문제들을 소개합니다.
Suffix Automaton + 모든 상태 순회
어떤 문자열 $S$의 모든 부분 문자열에 대한 어떤 값을 구해야 할 때, 문자열 $S$에 대해 Suffix Automaton을 구축한 다음 존재하는 (루트가 아닌) 모든 노드를 순회하면서 답을 구하는 테크닉입니다.
Suffix Automaton에 존재하는 노드는 최대 $2\vert S\vert -1$개이기 때문에, 전부 순회하더라도 $O(n)$에 문제를 풀 수 있습니다.
그냥 Suffix Automaton만 이용하면 각 노드마다 알 수 있는 정보가 한정적이기 때문에, DP 등의 전처리를 진행한 이후 활용하는 경우가 대부분입니다. 이와 관련해서는 다음 포스트에서 다루도록 하겠습니다.
[연습 문제] 서로 다른 부분 문자열의 개수 2 (BOJ 11479)
문자열 $S$가 주어질 때 $S$의 서로 다른 부분 문자열이 몇개 있는지 세는 문제입니다. 이 문제는 Suffix Array와 Longest Common Prefix 배열을 이용해서 풀 수 있는 대표적인 문제입니다.
대신 Suffix Array 대신 Suffix Automaton을 이용한다면, 위에서 언급했던 사실을 이용해서 풀 수 있습니다.
- 어떤 노드 $v$가 표현하는 서로 다른 부분 문자열 개수는 $v.len - v.link.len$이다.
따라서, Suffix Automaton에 존재하는 모든 노드 $v$를 순회하며 $v.len - v.link.len$을 전부 더해주면 위 문제를 풀 수 있습니다. 시간 복잡도는 $O(n)$입니다.
Suffix Automaton + Incremental Update
아래 두 종류의 쿼리가 주어질 때 사용할 수 있는 테크닉입니다.
- 문자열의 맨 뒤에 문자 추가
- 특정 값 계산
Suffix Automaton의 구축 과정에서 문자 하나를 넣을 때 마다, 구해야 하는 특정한 값을 $O(1)$ 내지는 $O(\log n)$으로 올바르게 업데이트해줄 수 있는 경우에 매우 유용합니다. Suffix Automaton에 문자 하나를 넣을 때 마다 쉽게 업데이트를 관리해줄 수 있는 값인 경우, 특별한 알고리즘 없이도 Online으로 문제를 풀 수 있습니다.
[연습 문제] 서로 다른 부분 문자열 쿼리 2 (BOJ 16907)
서로 다른 부분 문자열의 개수 2 (BOJ 11479) 문제의 변형입니다. 뒤에 문자를 하나씩 추가하며, 쿼리가 주어질 때마다 서로 다른 문자열의 개수를 출력하는 문제입니다.
- 어떤 노드 $v$가 표현하는 서로 다른 부분 문자열 개수는 $v.len - v.link.len$이다.
위에서 활용했던 사실을 다시 보면, 한 노드가 표현하는 문자열의 개수는 $v.len$과 $v.link$의 영향을 받는다는 사실을 알 수 있습니다.
Suffix Automaton 알고리즘의 특성 상, 노드 $v$의 다른 속성들과는 다르게 $v.link$는 생성 이후에도 변경될 수 있습니다. 따라서 서로 다른 부분 문자열의 개수를 올바르게 관리하기 위해서는, Suffix Automaton에 문자 하나를 추가할 때
- 새로 생성되는 노드
- Suffix Link의 연결이 바뀌는 노드
를 전부 추적하여 변경된 (혹은 새로 생긴) 부분 문자열의 개수 $v.len - v.link.len$를 다시 구하여 반영해주어야 합니다.
새로 생성되는 노드의 개수와 Suffix Link의 연결이 바뀌는 곳 모두 $O(1)$이기 때문에 문자 하나를 추가할 때 $O(1)$의 작업으로 서로 다른 부분 문자열의 개수를 올바르게 관리할 수 있습니다. 따라서 문제를 Online으로 풀 수 있으며, 시간 복잡도는 $O(n)$입니다.
Suffix Automaton + Incremental Update + Revert
아래 세 종류의 쿼리가 주어질 때 사용할 수 있는 테크닉입니다.
- 문자열의 맨 뒤에 문자 추가
- 문자열의 맨 뒤에서 문자 제거
- 특정 값 계산
Suffix Automaton에서 문자 하나를 추가하는데 걸리는 시간이 $O(1)$이기 때문에, 문자 하나를 추가할 때 생긴 변경사항을 $O(1)$의 정보로 관리할 수 있습니다. 따라서, 문자가 추가될 때마다 변경사항을 스택에 추가하고, 제거 쿼리가 들어올 때 마다 스택의 가장 위 정보를 빼서 직전 상태로 복구해주면 공간복잡도 $O(n)$, 시간복잡도 $O(1)$에 제거 쿼리를 처리할 수 있습니다.
[연습 문제] May I Add a Letter? (BOJ 22276)
- 문자열의 맨 뒤에 문자 추가
- 문자열의 맨 뒤에서 문자 제거
두 종류의 쿼리가 주어질 때, 각 쿼리를 실행할 때마다 문자열에 2번 이상 등장하는 서로 다른 부분 문자열의 개수를 출력하는 문제입니다.
만약 2번 이상 등장하는 서로 다른 부분 문자열이 아닌, 모든 서로 다른 부분 문자열의 개수를 출력하는 문제였다면 어떻게 풀 수 있을까요?
위의 서로 다른 부분 문자열 쿼리 2 문제와 동일하게 서로 다른 부분 문자열의 개수를 Online으로 관리하면서, 바뀐 개수 정보도 포함하여 변경사항을 스택으로 관리하면 제거 쿼리도 쉽게 처리할 수 있습니다.
그렇다면, 2번 이상 등장하는 서로 다른 부분 문자열의 개수는 어떻게 Online으로 관리할 수 있을까요? 이를 위해 다음과 같은 관찰을 할 수 있습니다.
- 자신을 향하는 Suffix Link가 없는, 즉 Suffix Link의 indegree가 0인 상태의 문자열 등장 횟수는 1이다.
- Suffix Link를 탈 때마다 문자열의 등장 횟수는 무조건 증가한다.
- 따라서 Suffix Link의 indegree가 0이 아닌 상태의 문자열은 무조건 2번 이상 등장하는 문자열이며, 역도 성립한다.
따라서, 각 상태마다 본인을 향하는 Suffix Link의 개수를 관리해주면서, Suffix Automaton에서 문자 하나를 추가할 때
- Suffix Link의 연결 상태가 바뀌는 곳
- 노드가 표현하는 문자열의 개수가 바뀌는 곳
을 모두 추적합니다. 변화가 일어나는 곳의 개수가 $O(1)$이기 때문에 $O(1)$에 작업을 처리할 수 있습니다. 따라서,
- Suffix Link의 indegree가 0이 되는 곳
- Suffix Link의 indegree가 1 이상이 되는 곳
- indegree가 이미 1 이상인 노드에서 문자열의 개수가 변하는 곳
각각의 변화를 적절히 처리하면 문제를 풀 수 있습니다. 따라서 문제를 Online으로 풀 수 있으며, 전체 시간 복잡도는 $O(n)$입니다.
이 문제는 특히나 Suffix Array로 푸는 것보다 Suffix Automaton으로 푸는 것이 훨씬 쉬운 것 같습니다.
마치며
분명 Suffix Automaton에 대해서는 최소한의 내용만 설명하고 다양한 문제 풀이 테크닉에 관한 내용을 메인으로 다루고 싶었는데, Suffix Automaton 설명이 너무 길어진 나머지 분량 조절에 실패한 것 같습니다.
따라서 이번 포스트에서 설명하지 못한, Suffix Automaton과 다른 알고리즘을 함께 사용하는 테크닉은 다음 포스트인 Suffix Automaton으로 Suffix Array 문제들을 풀어보자 2에서 다루도록 하겠습니다. 다룰 예정인 내용은 아래와 같습니다.
- DAG + DP
- DAG + Small to Large
- Suffix Link + DP
- Suffix Link + Small to Large
- Suffix Link + Sparse Table
- Suffix Link + Heavy Light Decomposition
- $\cdots$
긴 글 읽어주셔서 감사합니다!