Software Combining
Intro
지난 포스트들에서는 구체적인 자료구조 (BST, List 등)을 concurrent하게 어떻게 구현할 수 있을지를 살펴보았다. 이번에는 조금 더 일반적인 트릭인 software combining 에 대해서 알아보자.
표현이 조금 모호할 수 있으나, 이 주제의 관심사는 ‘여러 스레드가 효율적으로 하나의 shared object에 연산을 하는 방법’의 한 갈래로, 한 스레드가 여러개의 스레드의 연산을 한꺼번에 처리해주는 것에 대한 논의이다. 그렇기 때문에 software ‘combining’이라는 이름으로 불린다.
가장 일반적인 논의는 ‘임의의 sequential한 object를 concurrent하게 wrapping하는 법’인 universal construction에 대한 것이 되겠지만, 이번 포스트에서는 Fetch-and-add, 그리고 stack을 예로 들어 combining tree와 combining funnel에 대해서 설명한다.
Key Points & Brainstorming
간단한 예시로, 하나의 정수 X 를 두고 많은 스레드들이 동시에 fetch-and-add 를 한다고 생각해보자. fetch-and-add(v) 연산은 현재 정수의 값을 가져오고, 그와 ‘동시에’ 정수에 v를 더한 값을 저장해야 한다. 여기서 ‘동시에’ (atomic) 일어난다는 점이 중요한데, 예를 들어 모든 연산에 대해 v=1인 경우에는 각 연산이 atomic하게 일어나기 때문에 모든 스레드들이 관찰한 값은 달라야 한다. fetch와 add가 동시에 일어나기 때문에 한번의 연산이 일어나면 무조건 정수가 증가하게 되고, 따라서 다른 연산은 같은 값을 볼 수 없기 때문이다.
하지만 이전 포스팅에서도 알아봤듯, concurrent programming에서 순서와 correctness는 모호할 수 있는 개념이다. 여기서의 기준은 마찬가지로 linearizability이다. 요약하자면 ‘상식적인 선 내에서 연산들을 정렬했을 때, sequential한 것과 같은 결과를 내야 한다’ 라는 뜻이다. 정확한 정의는 이전 포스팅을 확인해보자.
현대 CPU들은 fetch-and-add 연산은 보통 지원한다. LOCK XADD v X 를 하면 정수 X에 v를 더한 값을 저장하고, 기존에 들어있던 X의 값을 반환하는 식이다. 하지만 하드웨어가 이 기능을 지원하기 이전에는 Lock을 써서 atomic함을 보장하는 식으로 SW레벨에서 구현했어야 했을 것이다.
64개 스레드가 있다고 했을 때, 각각이 lock을 얻고, 연산을 하고, lock을 푸는 것을 반복하는 것은 상당한 병목을 야기한다. lock을 얻지 못한 스레드는 번번히 기다려야 하기 때문에, 단순한 연산일지라도 이러한 atomic 조건 때문에 lock의 성능을 넘지 못한다.
여기서 이런 생각을 해볼 수 있다. ‘연산이 이렇게 단순하다면, 차라리 lock을 잡고 있는 스레드한테 내 연산에 대한 정보를 다 넘겨주고, 그 스레드가 내 일까지 해오길 기다리는게 낫지 않을까?’ 이 아이디어가 software combining의 아이디어이다.
여기서 combining이 유효하게 작동하기 위해 필요한 조건이 있는데, 여러 개의 연산들이 효율적으로 ‘합쳐져’야 한다는 점이다. fetch-and-add같은 경우에는 자명하게 add되는 값들을 모두 합쳐주고, 시작점만 알고 있으면 다른 스레드들한테 각자의 반환값들을 할당해줄 수 있다. stack의 경우에는 약간 다른데, 같은 연산끼리는 합칠 수 없지만 push와 pop은 그 둘이 연속해서 일어났다 치고 서로 합쳐서 없앨 수 있다.
Combining Tree
https://people.cmix.louisiana.edu/tzeng/publications/journals/tc_0487.pdf Distributing Hot-Spot Addressing in Large-Scale Multiprocessors
The Art of Multiprocessor Programming Chapter 12.3
여전히 하나의 정수에 작용하는 fetch-and-add 연산에 대해서 생각해보자. 스레드 64개가 모두 동시다발적으로 연산을 시행할텐데, 기다리는 시간을 줄이기 위해서 서로 부딪히는 스레드끼리는 연산을 합쳐주고 싶다. 어떻게 ‘부딪히는’ 경우를 끌어낼 수 있을까?
Combining Tree는 각 스레드가 리프가 되는 binary tree를 만들어, 루트에 원본 데이터의 접근권을 놓는다. 모든 스레드들은 리프에서 출발해서 루트까지 올라가면서, 알맞은 타이밍에 만나는 연산이 있으면 서로 합친다.
두 스레드를 합치는 과정에서, 한 스레드는 받은 정보를 가지고 올라가고 (active), 다른 스레드는 그 자리에서 멈춘다 (passive). 올라갔던 active 스레드가 결과값을 가지고 다시 해당 노드에 오면, 기다리고 있던 passive 스레드가 해당 값을 가지고 다시 내려간다.
알고리즘을 풀어서 설명하면 다음과 같다:
- Precombine
- 각 스레드는 자신의 리프에서 출발해서 올라가면서, 각 노드에 합칠 수 있는 ‘기회를 열어두면서’ (
FIRSTstatus) 올라간다. - 만약 이러한 상태에서 다른 스레드가 해당 노드에 도달하게 된다면, 그 스레드는 자신의 정보를 노드에 전달하고 (
SECONDstatus) 해당 위치에서 기다린다.
- 각 스레드는 자신의 리프에서 출발해서 올라가면서, 각 노드에 합칠 수 있는 ‘기회를 열어두면서’ (
- Combine
- 각 스레드가 도달할 수 있던 가장 위까지 도달하고 나면, 이때까지 기회를 열어두었던 노드들을 다시 순회하면서, 다른 스레드의 연산이 들어있으면 합치고, 노드를 다시 닫는다.
- Operation
- 만약 내가 루트까지 도달했다면 루트에 연산을 적용하고, 그렇지 않다면 도달했던 마지막 노드에서 결과값이 오기를 기다린다.
- Distribute
- 나의 결과값을 위에서 받았으면, 다시 아래로 내려가면서 기다리고 있던 스레드들에게 결과를 할당해준다. (
RESULT혹은IDLEstatus)
- 나의 결과값을 위에서 받았으면, 다시 아래로 내려가면서 기다리고 있던 스레드들에게 결과를 할당해준다. (
총 시간복잡도는 O(log N)인 것을 알 수 있다. 다만 나의 경로를 여러 번 순회하기 때문에, 상수는 조금 큰 편이다. 또한, 필연적으로 다른 스레드들을 기다리게 되기 때문에, lock free가 아니라 blocking한 알고리즘이다. 하지만 만약 한 메모리 위치를 store/load하는 것이 병목이었다면, 이러한 알고리즘으로 조금 더 높은 계산량을 부담하는 대신 그 병목을 해소할 수 있다.
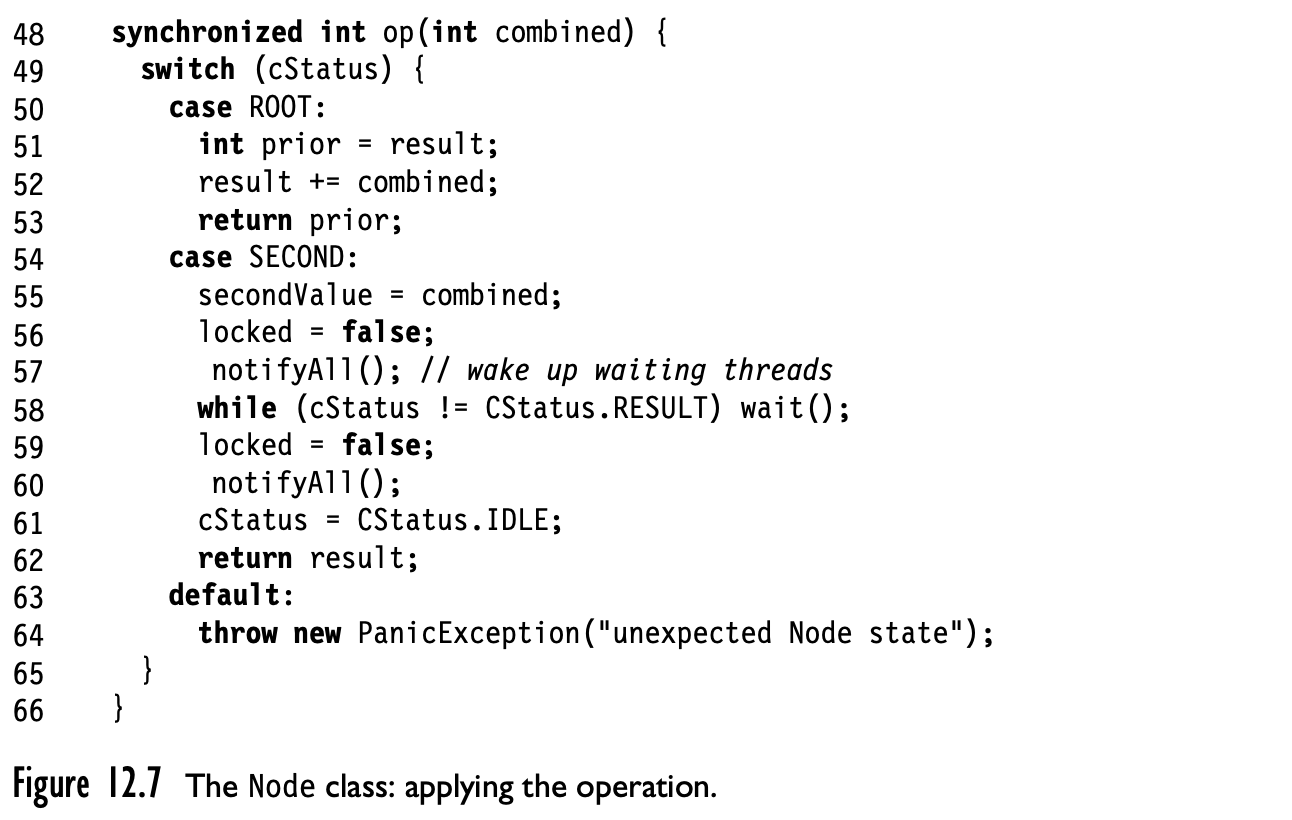
아래는 textbook에 나오는 JAVA 기준 pseudocode이다. C++ 구현은 https://github.com/Diuven/scadel 에 공개될 예정이다.
아래 구현에는 locked 변수와 synchronized 블럭이 동시에 사용됨에 유의하자. locked 변수는 장기적으로 ‘기회가 열려 있음 / 닫혀 있음’ 을 표현하는 용도이고, synchronized 블럭은 단기적으로 노드에 atomic한 업데이트를 보장하기 위해 사용된다.





Combining Funnel
https://people.csail.mit.edu/shanir/publications/SZ-funnels.pdf Combining Funnels: A Dynamic Approach To Software Combining
Combining Funnel은 Combining Tree와 비슷하지만, 조금 더 유연하고 효율적인 구조를 가지고 있다.
두 가지 큰 차이점이라면, Combining Funnel에서는 각 스레드의 시작 위치 및 트리 구조를 dynamic하게 (runtime에도) 조절할 수 있고, Combining Tree와는 반대로, 나중에 시작한 연산이 기존에 올라가던 연산을 멈추고 올라갈 수 있다는 점이다.
간략히 설명하자면 다음과 같다.
- 각 연산은 자신의 연산 정보를 저장할 object를 하나 만든다.
- Funnel의 처음부터 시작해서, funnel의 각 레벨별로 랜덤하게 한 위치를 고른다.
- 그 위치에 누군가의 연산 정보가 있다면 그 연산을 먹어 합치고, 그 자리에 내 연산 정보를 둔다.
- 만약 내 연산 정보가 먹히지 않았다면, 루트까지 도달해 내 연선과 이때까지 먹은 연산들을 수행한다.
- 만약 내 연산 정보가 먹혔다면, 내 연산 정보에 내 결과가 할당될 때까지 기다린다.
- 내가 먹었던 연산들을 로컬 리스트에 저장해 두고, 내가 결과를 받게 되면 그 리스트를 돌면서 결과값들을 할당해준다.
여기서 유용한 점은 각 funnel 레벨에서 랜덤하게 위치를 고르기 때문에, 레벨 너비를 가변적으로 바꿀 수 있고, 레벨의 개수도 가변적으로 바꿀 수 있다는 점이다. 하드웨어 및 작업의 종류에 따라 성능이 다를 수 있기 때문에, 스레드 개수에만 의존하여 구조를 고정하는 것이 아니라, 실제로 일어나는 contention의 정도에 따라서 adaptive하게 조절할 수 있다는 점은 장점이다.
아래는 원문에 나와있던 C 기준 코드이다. 마찬가지로 C++ 구현은 https://github.com/Diuven/scadel 에 공개될 예정이다.

Closing
해당 논문들에서는 lock을 두고 하는 연산을 하는 것과 비교하고 있고, 해당 비교에서는 우위에 있다고 적혀 있다. 현대에는 CPU가 fetch-and-add 연산을 직접 지원하기 때문에 아주 많은 스레드가 있는 것이 아니라면 그것보다 빠르기 어렵다. 다만 이론상으로는 여전히 한 메모리 위치에 많은 스레드가 연산하는 것은 병목이고, 이 접근은 그것을 해소해 주기 때문에 고민해볼 가치가 있다.