Intro
최근에 SIMD 연산을 활용해서 최적화를 해 볼 기회가 있었습니다. 그 과정에서 겪었던 어려운 점들과 흥미로운 점들, 그리고 유용한 점들을 모아 공유하고자 합니다.
확인해보니, 암호학 분야를 깊게 보시는 blisstoner께서 기존에 SIMD에 관한 소개글을 포스팅하신 것이 있습니다. Link 이 글에서는 좀더 다양한 연산들, 주의해야 할 점들, 그리고 어떻게 쉽게 개발할 수 있을지를 집중적으로 설명해봅니다.
간단하게 다시 짚고 넘어가자면, SIMD (Single Instruction Multiple Data) 연산은 다수의 데이터에 동일한 연산을 한꺼번에 적용하고자 하는 목표를 가집니다. 여러 개의 데이터를 병렬로 늘어놓고 처리한다는 면에서 벡터 연산 (vectorization)이라고 부르기도 하고, 여러 개의 워드를 한꺼번에 처리한다는 면에서 word parallelism이라고 부르기도 합니다.
이를 통해 하드웨어 레벨에서 병렬 처리를 구현할 수 있고, 결과적으로 싱글 코어만에서도 더 빠른 성능을 이룰 수 있습니다. 하드웨어 레벨에서 이러한 접근이 유효한 이유는, 현대 CPU에선 연산을 실제로 처리하는 부분 (ALU) 보다는 컨트롤을 제어하는 부분의 비율이 훨씬 크기 때문에, ALU를 여러 개 둔다고 해서 큰 공간/전력 손실이 아니기 때문입니다. 이러한 벡터 연산들을 잘 활용하기만 한다면 코드의 성능을 크게 향상시킬 수 있기 때문에, 현대 CPU들은 대부분 일정 수준의 벡터 연산들을 지원합니다.
Concepts
CPU마다 (보통 아키텍처마다) 지원하는 벡터 연산의 셋이 다릅니다. 여러 측면으로 나눌 수 있지만, 가장 주목할 만한 분류는 vectorization width 입니다.
앞서 설명된 대로, SIMD 연산은 여러 개의 데이터를 늘어놓고 한꺼번에 연산을 적용합니다. 여기서, 몇 개의 데이터를 늘어놓을 수 있는지에 대한 표현이 width입니다. 정확하게 표현하자면, 주로 데이터의 단위는 64bit로 생각하고 (long long or double), 그 64bit 데이터를 몇 개 처리할 수 있는지가 width입니다. 그러니 width=4인 경우에는 벡터 레지스터가 256bit인 것이고, width=8인 경우에는 512bit가 됩니다.
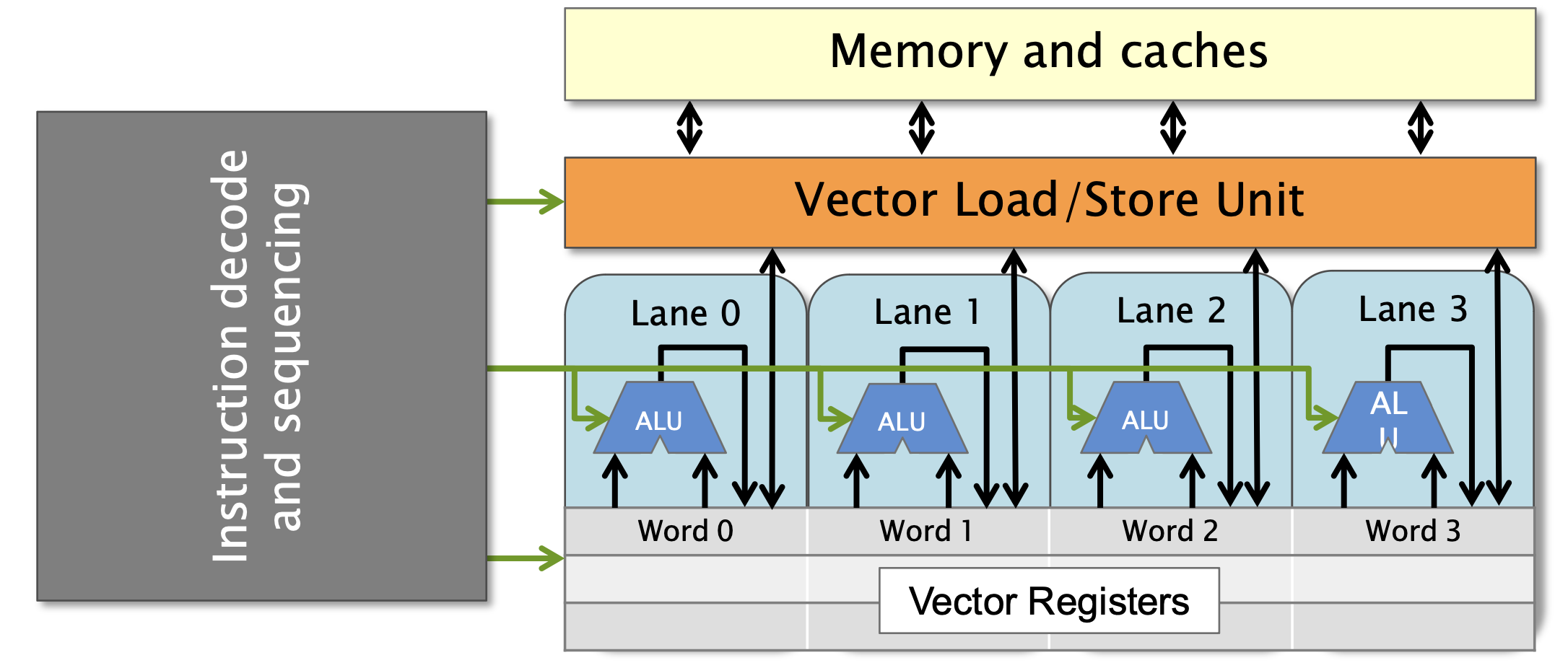
데이터의 단위가 64bit인 이유는, 대부분의 기존 instruction들이 64bit를 기준으로 (혹은, 최대 64bit) 작동하기 때문입니다. CPU의 역사를 되짚어보기엔 내용이 너무 복잡하지만, 제가 이해하기로는 CPU의 워드 단위가 8bit, 16bit, 32bit, 64bit로 증가한 가장 큰 이유는 메모리의 크기, 곧 포인터의 표현 범위의 제한 때문인 것으로 알고 있습니다. (2^32~=4GiB -> 2^64 >1e19B) 포인터에는 다양한 연산들이 필요하기 때문에, 이 과정에서는 복잡한 재설계와 ISA 하위 호환성 문제를 감수하면서도 레지스터 크기를 늘리고 (eax -> rax, etc) 64bit 데이터를 처리할 수 있는 연산들을 추가한 것으로 알고 있습니다. (addd -> addq, etc) 하지만 메모리 주소는 이제 더 이상 병목이 아니니, 복잡한 재설계 과정을 감수하면서 레지스터 크기를 늘릴 요인은 없습니다. 하지만 여전히 동시에 처리하는 데이터의 양을 늘려 성능 향상을 얻을 필요는 있었기 때문에, 기존의 레지스터 크기를 키우고 ISA를 전부 확장하는 것이 아니라 별도 레지스터를 만들고 일부 연산만 지원하는 식으로 구현한 것으로 이해하고 있습니다.
당연히, 초기의 벡터 연산은 두개의 워드 (128bit)만을 지원했습니다. 많은 최신 CPU들은 8개 워드 (512bit)를 지원합니다. 그리고 아키텍처에 따라 지원하는 연산의 종류도 차이가 있습니다. 이러한 CPU 스펙들은 lscpu 커맨드에서 확인할 수 있는데, 나오는 정보들 중 flag에서 avx512f, avx512bw 등 avx가 붙은 플래그들이 지원하는 벡터 연산의 스펙을 나타낸다고 보면 됩니다. 벡터 width는 2, 4, 8이 있고, 그 중간의 값 (6 등)만큼의 워드를 따로 지원하지는 않습니다. 그러니 6개 워드를 벡터화할 바에는 8개를 모아서 하거나, 4개만 하고 2개는 각각 돌리던가 하는게 나을 수 있습니다.
위에서 언급한 데이터의 크기가 상당히 중요한데, 많은 경우에 벡터 연산은 lane 사이의 정보 교환이 크게 제한됩니다. 물론 SIMD의 원래 목적대로라면 서로 다른 데이터 사이에 정보 전달이 왜 필요하겠냐 싶겠지만, 일부 연산을 제한적이지만 cross-lane operation들을 지원하고, 또 상황에 따라 매우 유용하게 쓰이는 경우들이 있습니다. (예를 들어, 256bit integer 혹은 bitmask를 사용하고 싶은 경우) 데이터의 단위에 따라서 연산을 사용할 수 있는 패턴이 달라지기 때문에, 연산 이름에 보통 연산 단위가 명시되어 있습니다.
앞선 포스팅에서도 언급된 점이지만, 연산에 따라 latency, bandwidth 등의 스펙이 다를 수 있습니다. 아키텍쳐에 따라서도, 또 세부 argument에 따라서도 스펙이 달라질 수 있기 때문에, 정확한 확인을 하고 사용해야 합니다.
How to use
벡터 연산을 사용하기 가장 쉬운 방법은, 컴파일러에게 맡기는 겁니다. 컴파일 할 시점에 ‘이 CPU는 이러이러한 벡터 연산이 가능하니, 인지하고 알아서 잘 컴파일해라’ 라고 플래그를 넣어주면, 몇몇 패턴들을 알아서 인식해서 벡터 연산으로 치환해줍니다. 물론, 컴파일러가 인식할 수 있는 범위에는 한계가 있기 때문에, 해당 플래그를 넣어준다고 해도 컴파일러가 치환하기 편하게 코드를 잘 만져주는 것이 중요합니다.
예를 들어, -mavx512 와 -ftree-vectorize 플래그를 넣어준다면 (세부 플래그 값은 해당 머신의 lscpu 플래그에 따라 달라집니다), 컴파일러가 최대 512bit 벡터 연산을 염두에 두고 컴파일합니다. 이렇게 컴파일된 어셈블리를 뜯어보면, vpaddq 등의 연산들을 볼 수 있습니다. 주로 vp prefix가 붙고, 뒤에 i64x2,q,d,w (64bit int x2, quad, double, word) 등 unit data type을 나타내는 suffix가 붙습니다.
컴파일러에 직접적인 접근이 어렵다면, (대부분의 competitive programming의 경우) #pragma GCC target() directive를 이용해서 컴파일러 옵션을 코드에 넣을 수도 있고, clang의 경우에는 #pragma clang loop vectorize(), interleave() 등의 힌트를 통해 강제할 수도 있습니다. ARM 머신에서는 테스트하기 어렵다는 점에 주의합시다.
컴파일 결과를 실제 환경에서 테스트해보는 것이 가장 이상적이지만, 상황이 여의치 않다면 https://www.godbolt.org/ 등의 도구들을 이용해서 어셈블리를 확인할 수도 있습니다. 그리고 컴파일러의 비위를 맞춰주기 싫거나 믿음직스럽지 않다면, 직접 벡터 연산을 사용해 구현할 수도 있습니다. 인텔에서 제공하는 몇몇 헤더들이 있는데, 필요한 대부분은 immintrin.h헤더에 포함되어 있습니다.
기존 포스팅에서 소개한 대로, __m512i 등의 타입을 이용해서 데이터를 적재하고, _mm512_add_epi64등의 함수를 불러 연산을 사용할 수 있습니다. 단, 벡터 레지스터는 일반 레지스터와 별개의 존재이기 때문에, load와 store에 시간이 걸린다는 점에 유의합시다. 예를 들어, 64bit int 네개를 __m256i에 넣고 연산을 하고 싶다고 해서 _mm256_set_epi64x같은 연산을 써버리면, 이는 단순히 네번의 instruction으로 벡터 레지스터에 값을 적재하기 때문에, 벡터 연산을 안 쓰는 것보다 더 느린 결과를 얻을 수 있습니다. 데이터를 빼오는 것도 마찬가지이고, 이를 유의해서 연속적인 데이터에만 적용하거나 (_mm512_load_epi64) 하나의 값을 네 레인에 모두 쓰거나 (_mm512_set1_epi64) 하는 등의 준비 과정이 중요합니다.
필요한 연산이 있다면, Intel Intrinsics Guide 혹은 Intel Developer Guide에서 찾아볼 수 있습니다. 정확한 작동 방식, 자신의 환경에 맞는 스펙, 필요한 플래그 등을 정확하게 확인해보고 사용합시다.
Notable Instructions
간단히 생각할 수 있는 단순 산수 (add, sub, mul, div, and, or, xor, min, max, abs, float 역수, sqrt, round, exp 등)은 당연히 잘 지원합니다. 또한, 많은 경우에 constant mask를 사용해서 특정 데이터에만 적용하거나, 특정 부분만 0으로 만들거나 하는 기능을 추가적으로 지원합니다. 이 글에선 흥미로운 몇몇 연산들을 짚어봅니다.
먼저, 대중적으로 많이 사용되는 고급 함수들이 있습니다. SHA512, Pseudo-random functions 등 암호학 관련, sin/cos 등의 삼각함수들, 그리고 128bit packed string compare 등이 있습니다. 직접 사용해보진 않았지만, 일정 조건 하에 유용하게 쓸 수 있을 것으로 보입니다.
앞서 언급한 대로, SIMD의 초기 가정을 어기고 서로 다른 데이터간의 연산을 지원하는 연산들도 있습니다. 예를 들어 _mm512_permutex2var_epi64 함수는 512bit의 a, b, idx를 인자로 받아, 64비트 단위로 idx의 값에 따라 a 혹은 b의 워드 중 하나를 선택합니다. 비슷하게, _mm512_shuffle_epi8 함수는 512bit의 a,b를 인자로 받아, 8비트 단위로 b가 나타내는 위치의 a의 값을 선택합니다. 이러한 연산들을 통해 엔디안 변환, 자릿수 변환 등을 할 수 있겠습니다.
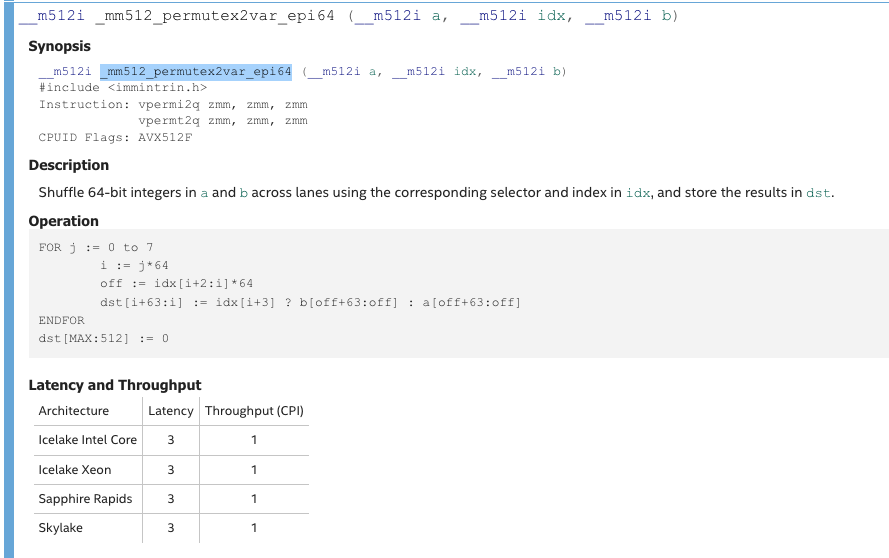
한편, 벡터 연산들중에는 비트 단위의 연산이 많지 않은데, 대부분의 비트 단위 연산은 vpternlog 연산으로 구현할 수 있습니다. 512bit a,b,c,를 받고 연산 종류를 나타내는 imm8을 인자로 받아, 가능한 truth table중 하나를 골라 bitwise operation을 계산합니다.
imm8을 설정하는 로직은 확실하지 않은데, 여기에 논리식을 imm8으로 바꿔주는 도구가 있습니다.