solving JIE-constant (acmicpc 22222)
문제 소개
지애 상수는 백준의 22222번째 문제를 기념하여 출제된 문제로, 문제에서 정의된 지애 상수라는 값을 소수점 222자리까지 구하는 문제입니다. 지애 상수의 정의는 아래와 같습니다.
Definition of 지애 상수
지애 상수는 좌표평면의 점 $A(0,0),B(1,0),C( {1 \over 2} , { \sqrt 3 \over 2})$로 정의된 정삼각형 $ABC$에서 시작하여 만든 시에르핀스키 삼각형에서 독립적으로 균등하게 잡은 점 두 개의 유클리디안 거리의 기댓값입니다.

균등하게 점 잡기?
지애 상수를 정의하기 위해서는 우선 시에르핀스키 삼각형에서 점을 균등하게 잡는 것을 수학적으로 정의할 수 있어야 합니다. 이는 시에르핀스키 삼각형의 재귀적 구조를 통해 해결할 수 있습니다.
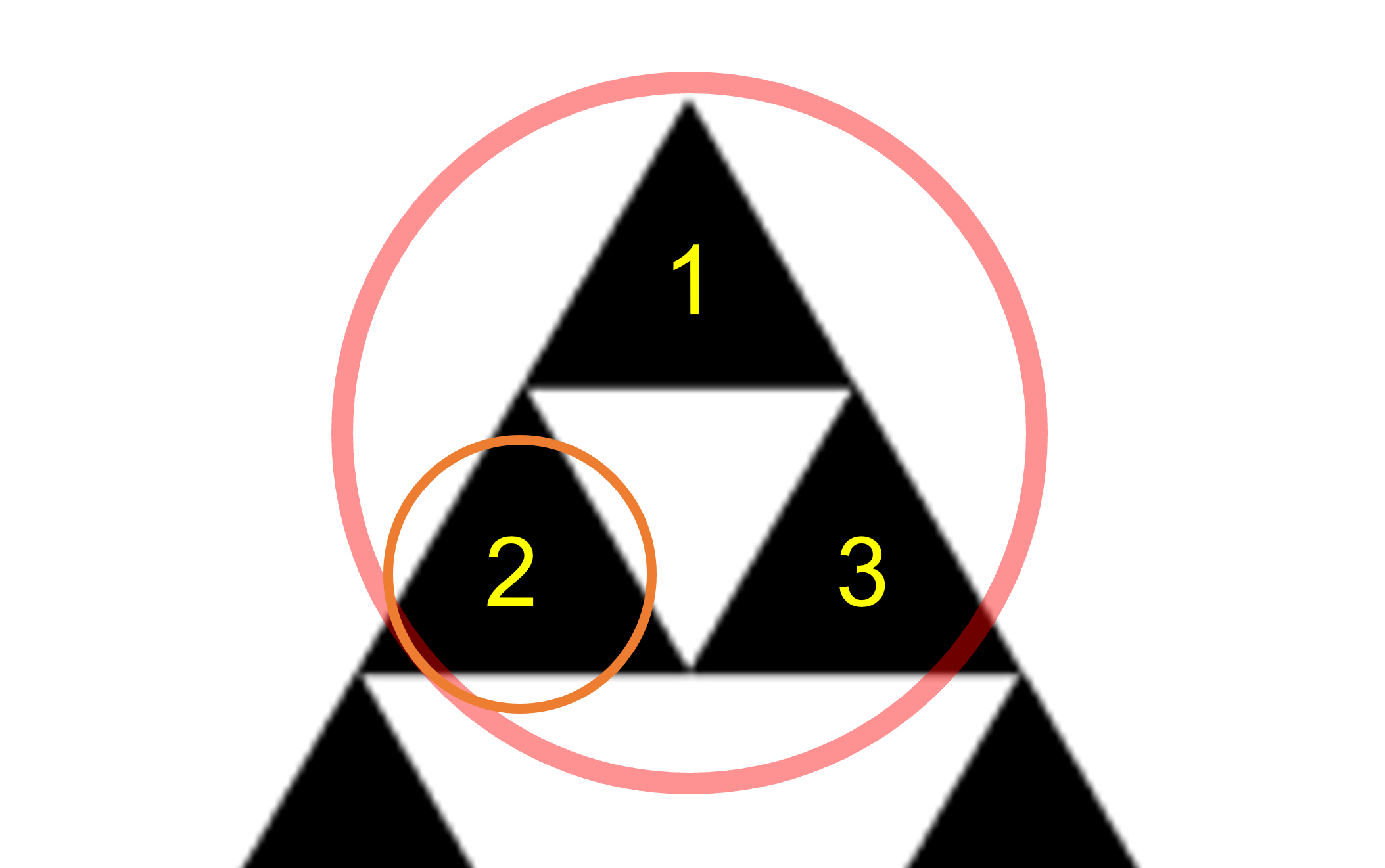
우선 아래 그림의 1단계 시에르핀스키 삼각형을 생각해봅시다. 점이 균등하게 선택되어야 하기에, 점은 각각 ${1\over 3}$ 확률로 삼각형 $1, 2, 3$ 중 한 곳에 선택되어야 합니다.

일반성을 잃지 않고 삼각형 $1$이 선택되었다고 합시다. 이제 2단계 시에르핀스키 삼각형으로 들어가면, 1단계의 $1$번 삼각형이 다시 3개의 삼각형으로 분할되고, 이중에서 새로운 삼각형이 각각 $1 \over 3$ 확률로 선택되게 될 것입니다. 이런 과정들을 계속 반복하다 보면 점은 결국 한 점으로 수렴함을 증명할 수 있고, 문제에서는 이 점을 시에르핀스키 삼각형에서 균등하게 고른 한 점이라고 정의합니다.
균등하게 선택한 점의 수식적 표현
점이 수렴하는 과정에서 선택된 각 단계의 정삼각형의 중심을 이어보면, 아래의 그림을 얻을 수 있게 됩니다.

이 화살표들을 관찰하면, 점이 수렴하는 과정을 수식으로 간단하게 표현할 수 있음을 알 수 있습니다. 편의상 0단계 시에르핀스키 삼각형의 중심을 $O(0,0)$이라고 정의하고, $i$번째 단계에서 고른 삼각형의 번호를 $a_i$라고 합시다. 이때, 선택된 점의 좌표는 아래와 같이 나타낼 수 있습니다. (편의상 복소평면 위에서 서술하겠습니다.)
$A = \sum_{i=1}^{\infty} {1 \over {2^i}} V_{a_i}$
$(a_i = 1,2,3), \ \ ( V_{1}, V_{2}, V_{3}) = ({1 \over {\sqrt 3}}i,\ {1 \over 2} -{1 \over {2\sqrt3}}i,\ -{1 \over 2} -{1 \over {2\sqrt3}}i )$
두 점 사이 거리의 수식적 표현
이때까지 점 1개를 고르는 과정을 수식으로 표현했습니다. 하지만 지애 상수를 구하기 위해서는 두 점 사이의 거리의 기댓값을 구해야 하고, 따라서 이를 수식으로 다시 나타내야 합니다.
각각 선택된 점을 $A = \sum_{i=1}^{\infty} {1 \over {2^i}} V_{a_i}$, $B = \sum_{i=1}^{\infty} {1 \over {2^i}} V_{b_i}$라고 합시다. (${a_i }, { b_i}$는 각각의 삼각형에서 $i$번째 삼각형 때 선택된 삼각형의 번호입니다) 두 점 사이의 거리 벡터를 계산하기 위해서는 $A-B$를 구해야 하며, 이때 $D=A-B = \sum_{i=1}^{\infty} {1 \over {2^i}} (V_{a_i} - V_{b_i})$가 됩니다. 이때 $V_{a_i} - V_{b_i}$를 직접 계산하기에는 꽤나 불편한 감이 있으니, 각각의 $A_i = (1,2,3), \ B_i = (1,2,3)$ 케이스마다 $V_{a_i} - V_{b_i} $의 값을 계산해서 새로운 확률 변수 $X_i = V_{a_i} - V_{b_i} $를 정의해 줍시다. 이때 $X_i$는 아래 그림처럼 표현됩니다.
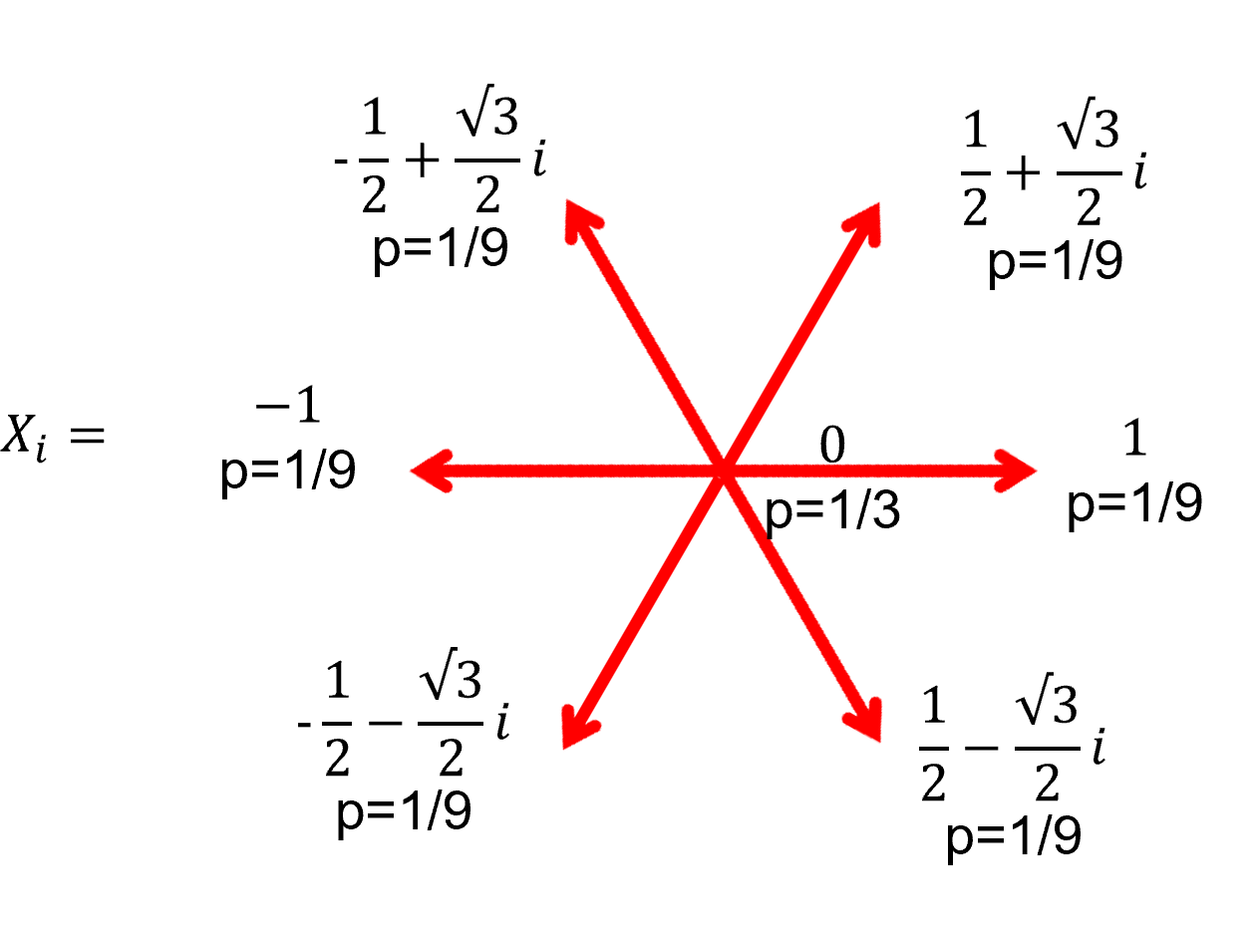
위 확률 변수 $X_i$에 대해, 균등하게 선택된 두 점 사이의 벡터는 $D=\sum_{i=1}^{\infty} {1 \over 2^i} X_i$가 되겠습니다.
이제 실제 유클리디안 거리는 $\vert D\vert =\sqrt{DD^{\ast}}$으로 표현할 수 있고, 지애 상수는 확률 변수 $X_1, X_2, …$에 대해 결정되는 $\sqrt{DD^{\ast}}$의 값의 기댓값이라고 할 수 있습니다.
How to get $\vert D\vert $?
드디어 문제 정의를 마쳤습니다. 이제 이렇게 정의된 $\vert D\vert =\sqrt{DD^{\ast}}$의 기댓값 $E[\sqrt{DD^{\ast}}]$을 어떻게 정리해서 구할 지 알아봅시다.
현재 기댓값을 구하는 데 있어 가장 큰 걸림돌은 식에 씌워진 루트라고 할 수 있겠습니다. 실제로 루트를 제거한 $E(DD^{\ast})$의 경우 $2/9$로 깔끔한 값을 가집니다. 그럼 어떻게 수식에서 루트를 떼어낼 수 있을까요?
이는 테일러 전개에서 힌트를 얻을 수 있습니다. 테일러 전개에 의하면, $\sqrt{1+X}$는 아래와 같이 나타낼 수 있습니다.
$\sqrt{1+X} = 1 + {1\over 2}X - {1\over8}X^2 + {1\over 16}X^3 - \cdots$
즉, $\sqrt{F}$ 꼴의 식을 $F$의 polynomial한 식으로 바꿔서 전개를 할 수 있게 됩니다. 이 문제의 경우 $E[D^p {D^{\ast q}} ]$의 값을 꽤 쉽게 구할 수 있기 때문에(후술됩니다), 이런 식의 전개가 매우 유효한 접근이라고 할 수 있겠습니다.
$E[D^p {D^{\ast q}}]$ 구하기
전개된 테일러 식으로 지애 상수를 구하기 위해서는, 전개된 각 $E[D^p{D^{\ast q}} ]$의 값들을 알 수 있어야 합니다. 이를 구하기 위해 다음 4개의 property가 사용됩니다.
(0) $E[D^0{D^{\ast 0}}]=1$입니다.
proof) 자명합니다.
(1) $6 \nmid p-q$면, $E[D^p {D^{\ast q}} ] = 0$이 성립합니다.
proof) $D$에서 각각의 확률 변수 $X_i$는 60도 대칭임을 관찰하면, $E[f(D)] = E[f(e^{\frac{\pi i}{3}} D)]$임을 관찰할 수 있습니다. 따라서
$E[D^p {D^{\ast q}} ] = E[(e^{\frac{\pi i}{3}} D)^p {(e^{\frac{\pi i}{3}} D)^{\ast q}} ] = E[D^p {D^{\ast q}} ] e^{\frac{(p-q)\pi i }{3}}$
이 성립하며, 가정에 의해 $e^{\frac{(p-q)\pi i }{3}} \neq 1$이므로 $E[D^p {D^{\ast q}} ] = 0$입니다.
(2) $6 \mid p - q$면, $b = ae^{\frac{\pi i}{3}}$에 대해 $E[(a+D)^p({a^{\ast}} + D^{\ast})^q] = E[(b+D)^p({b^{\ast}} + D^{\ast})^q]$가 성립합니다.
proof) (1)의 증명과 유사하게, $E[f(D)] = E[f(e^{\frac{\pi i }{3}} D)]$가 성립하므로
$E[(b+D)^p({b^{\ast}} + D^{\ast})^q] = E[(ae^{\frac{\pi i}{3}}+De^{\frac{\pi i}{3}})^p({a^{\ast}}e^{-{\frac{\pi i}{3}}} + D^{\ast}e^{-{\frac{\pi i}{3}}} )^q]$
$= e^{\frac{(p-q)\pi i}{3}}E[(a+D)^p({a^{\ast}} + D^{\ast})^q] = E[(a+D)^p({a^{\ast}} + D^{\ast})^q]$
이 성립합니다.
(3) $E[F(D)] = \sum_{x_i\in X_1} p(x=x_i)E[F({x_i \over 2} + {D \over 2})]$가 성립합니다.
proof) $D$의 구조를 보면 $D = \sum_{i=1}^\infty {1\over2^i}X_i = {X_1 \over 2} + {1\over 2}\sum_{i=1}^\infty {1\over2^i}X_{i+1} = {X_1 \over 2} + {1 \over 2} D’$ 꼴임을 알 수 있고, 따라서 위 식이 성립합니다.
위 property들로 $E[ D^p{D^{\ast q}} ]$의 값의 점화식을 유도해봅시다. property (2), (3)을 사용하면, $6 \mid p-q$일 때, $E[D^p {D^{\ast q}}]$는 아래와 같이 표현됩니다.
$E[D^p {D^{\ast q}}] = \sum_{x_i\in X_1} p(x=x_i)E[(x_i + {1 \over 2}D)^p (x_i^{\ast} + {1 \over 2}D^{\ast})^q ]$
$= {1\over3}E [ (0 + {1\over 2}D)^p(0 + {1 \over 2}D^{\ast} )^q ] + {2 \over 3}E [ ({1\over2} + {1\over 2}D)^p({1\over2} + {1 \over 2}D^{\ast} )^q ]$
이를 통해 $E[D^i{D^{\ast j}}]$의 점화식을 구할 수 있습니다.
$E[D^p {D^{\ast q}}] = I_6(p, q) \times {2\over3} {1\over {2^{p+q}-1}} \sum_{i=0}^p \sum_{j=0}^q d_{p,q}(i,j) \times {_pC_i} {_qC_j} E[D^i {D^{\ast j}}]$
(이때 $d_{p,q}(i, j) = 0 \ \text{if} \ (i,j)=(p,q),\ 1 \ \text{otherwise}$, 그리고 $I_{6}(p, q) = 1 \ \text{if} \ 6 \mid p - q, \ 0 \ \text{otherwise}$)
이를 이용해 이전에 언급한 $E(DD^{\ast})$의 값을 구해보면,
$E[D^1 {D^{\ast 1}}] = {2\over3} {1\over {2^{2}-1}} \sum_{i=0}^p \sum_{j=0}^q d_{p,q}(i,j) = {2\over9}(E[D^0{D^{\ast 0}}]+ E[D^0{D^{\ast 1}}] + E[D^1{D^{\ast 0}}]) = {2 \over 9}$
임을 확인할 수 있습니다.
저 점화식의 꼴을 그대로 사용하면 $E[D^n{D^{\ast n}}]$를 구하기 위해 $O(n^2)$의 공간복잡도와 $O(n^4)$의 시간복잡도가 필요하며, 간단한 DP 최적화를 거치면 시간복잡도 $O(n^3)$에 이를 구할 수 있게 됩니다. 지애 상수의 222자리까지 구하기 위해서는 대략 $n=1000$까지의 $E[D^n {D^{\ast n}}]$이 필요하며(로직 및 구현 방식에 따라 차이가 있을 수 있습니다), 두 버전 모두 충분히 빠른 시간 내에 이들을 구할 수 있습니다.
Calculating $E[ \vert D\vert ]$ - First try
이제 다시 본 문제를 생각해봅시다.
위 단계에서 각각의 $E[D^p {D^{\ast q}}]$를 구하기는 했으나, 당장 $E[ \sqrt{DD^{\ast}} ]$을 가지고 테일러 전개를 하는 것은 쉽지 않습니다. 단순히 $DD^{\ast} = 1 + (DD^{\ast} - 1) = 1+x$로 넣고 계산을 시도해보면, 테일러 급수의 초기 100개의 항을 더하면 $10^{90}$이라는 놀라운 값으로 날뛰는 걸 확인해볼 수 있습니다. 상식적으로 지애 상수가 저 값으로 수렴할 리는 없습니다. 어디서 문제가 발생한 걸까요?
이는 $x=\sqrt{DD^{\ast}}-1$의 값이 $[-1,0]$ 사이의 값을 가지고, 따라서 $\sqrt{1+x}$의 수렴반경 $(-1, 1)$을 벗어났기 때문입니다. 물론, $x=-1$이 되는 경우는 $D=0$인 경우 뿐이므로 배제를 할 수 있습니다. 하지만 실질적인 문제는 $\vert D\vert $의 값이 매우 작을 때 발생합니다.
먼저 다음 Lemma가 성립합니다. 계산 과정은 생략하겠습니다.
Lemma) $\sqrt{1+x}$의 테일러 급수의 $k$번째 항까지 계산한 후 남은 오차 $R_k(x)$는 $O(\vert x\vert ^{k+1})$이다.
이제 적당히 작은 실수 $h>0$에 대해, $\vert D\vert <h$인 케이스를 생각해봅시다. $D$가 이런 값을 가질 확률을 $p_h$라 할 때, $p_h > 0$임을 쉽게 관찰할 수 있습니다($D$의 초기 $r$개의 $X_i$ 값이 $0$이 되는 케이스를 생각해보면 됩니다). 이러한 $D$에 대해 $x = \sqrt{DD^{\ast}}-1 < -(1-h)$이며, lemma에 의해 테일러 급수의 앞 $k$개의 항을 계산했을 때 실제 지애 상수 값과의 오차는 $O((1-h)^k)$임을 알 수 있습니다. 만약 $h={1\over k}$로 잡으면 위 오차는 대략 $1/e$의 스케일이 될 것이고, 이는 $k$개의 급수 연산으로는 오차가 충분히 좁혀지지 않음을 의미합니다. 정리하자면, 아무리 큰 $k$를 잡고, $x=DD^{\ast}-1$로 계산한 테일러 급수 중 앞 $k$개를 계산한다고 해도, $h={1\over k}$에 대해 $p_h$ 확률로 등장하는 $D$의 원소들은 충분히 수렴하지 못하기에 이 방법으로는 원하는 수렴값을 얻을 수 없습니다.
Calculating $E[ \vert D\vert ]$ - Second try
위 실패를 통해 저희는 중요한 교훈을 얻었습니다. $\sqrt{1+X}$의 테일러 급수를 사용하려면 $\vert X\vert $의 크기가 충분히 작아야 합니다. 엄밀하게는 $\vert X\vert $의 upper bound가 strictly하게 1보다 작아야 하며, 한정된 컴퓨터 자원으로 충분히 빠른 수렴 속도를 보장하려면 그래도 $\vert X\vert < 0.8$ 정도는 되어야 살아생전 지애 상수를 볼 수 있을 듯 합니다. 어떻게 하면 저런 꼴의 식을 얻을 수 있을까요?
이는 아래의 식정리를 통해 해결할 수 있습니다. (property 2, 3이 사용됩니다.)
$E[\vert D\vert ] = {1\over 3} (E[ {\vert 0 + {1\over2}D}\vert ]) + {2\over 3} (E[ {\vert {1\over2} + {1\over2}D}\vert ])$
$E[\vert D\vert ] = {2 \over 5}E[\vert 1 + D\vert ] $
$E[\vert 1+D\vert ] = \sum_{x_i\in X, \ x_i \neq -1} p(x=x_i)(E[\vert 1+{1\over2}x_i + {1\over2}D \vert ]) + {1\over9}(E[ \vert 1-{1\over2}+{1\over2}D \vert ]) $
$E[\vert 1+D\vert ] = {18 \over 17} \sum_{x_i\in X, \ x_i \neq -1} p(x=x_i)(E[ \vert 1+{1\over2}x_i + {1\over2}D \vert ]) $
$E[\vert D\vert ] = {36 \over 85} \sum_{x_i\in X, \ x_i \neq -1} p(x=x_i)(E[ \vert 1+{1\over2}x_i + {1\over2}D \vert ])$
마지막 식에서 $\vert 1+{1\over2}x_i\vert $의 값들은 모두 $\vert {3 \over 4} + {\sqrt{3} \over 4}i\vert \approx 0.866 $보다 크며, 각 $x_i$마다 식정리를 하면 $E[\vert 1+UD\vert ] = E[\sqrt{(1+UD)(1+U^{\ast}D^{\ast})} ]$, $\vert UD\vert < 0.7$ 꼴의 식이 나오게 됩니다. 따라서 각 $\sqrt{1+UD}$, $\sqrt{1+U^{\ast}D^{\ast}}$의 테일러 급수는 빠르게 수렴함이 보장되고, 각 식을 펼치면 나오는
$E[\sqrt{1+UD} \sqrt{1+U^{\ast}D^{\ast}} ] = E[(1 + \frac{1}{2}UD - \frac{1}{8} (UD)^2 + \cdots)(1 + \frac{1}{2}U^{\ast}D^{\ast} - \frac{1}{8} (U^{\ast}D^{\ast})^2 + \cdots) ]$
$= E[1] + {1\over 2}UE[D] + {1\over 2}U^{\ast}E[D^{\ast}] + {1\over4}UU^{\ast}E[DD^{\ast}] + \cdots$
를 적절한 $k$번째 항까지 계산하면 됩니다.
계산한 각각의 값을 더하면, 최종적으로 지애 상수 $E[ \vert D\vert ]$의 수렴값을 구할 수 있게 됩니다!
구현
solver의 코드가 꽤 길어서, github link로 대체합니다. 참조해서 직접 구현해보는 것을 권장합니다.
MAX_N의 값을 1000 정도로 세팅하면, 약 1시간 정도의 계산 후에 답을 구할 수 있습니다.