Zip Tree
서론
Zip Tree는 Robert Tarjan, Caleb Levy, Stephen Timmel이 제시한 랜덤 기반의 Binary Search Tree의 일종이다. 논문에서는 Rotate연산 대신 Zip과 Unzip연산을 통해 트리의 균형을 맞춘다고 소개되어 있지만, 이는 사실 기존에 Treap 자료구조에 대해 다룬 논문에 기재된 Split과 Join연산의 구현과 구조가 동일하다.
본 글에서는 그럼에도 Zip Tree가 널리 알려진 Treap의 형태와 어떤 차이점이 있는지 소개하고, 얻을 수 있는 기대효과를 분석해 보고자 한다.
Skip List vs Zip Tree
Zip Tree는 Skip List를 Balanced Binary Search Tree로 변환한 형태이다. 따라서 Skip List에 대한 간단한 설명을 먼저 기술한다. 여기서 Skip List란, 다음 연산을 모두 $O(\log n)$에 지원하는 연결 리스트를 이용하는 자료구조이다.
- 임의의 원소
x를 추가한다. - 임의의 원소
x를 삭제한다. x이상의 원소 중 가장 작은 것을 출력한다. Skip List의 구축에는 랜덤 알고리즘이 사용된다. Skip List에 원소를 삽입할 때, 해당 원소의 값과는 별개로 성공확률이 $0.5$인 베르누이 시행에 대해, 첫 번째 성공을 얻기까지 걸린 횟수를 해당 원소의 높이로 정의한다.
Skip List에서 탐색할 때는 최상단 높이에서 시작한다. 탐색 과정은 다음과 같이 진행된다.
- 찾고자 하는 원소를 발견하면 탐색을 종료한다.
- 찾고자 하는 원소보다 큰 원소를 만나면 높이를 $1$ 감소하고 탐색을 진행한다.
- 리스트의 끝에 도달했다면, 높이를 $1$ 감소하고 탐색을 진행한다.
Skip List의 각 원소의 높이를 성공 확률이 $0.5$인 기하분포를 따르도록 설정하였으므로, 직관적으로 위 탐색 방법이 $O(\log N)$의 시간복잡도가 걸릴 것으로 기대할 수 있고, 실제로도 그에 가까운 시간복잡도를 가진다.
이러한 Skip List의 탐색 과정을 Binary Search Tree에서의 탐색으로 모델링할 수 있다. rank가 가장 큰 원소 중 가장 작은 값을 기준으로, tail을 제외하고 이동할 수 있는 가장 먼 원소를 향해 계속 이동하는 것이 Binary Search Tree에서 오른쪽 자식으로 이동하는 것과 같다.
즉, 다음 이미지와 같이 Skip List의 형태를 Binary Search Tree로 바꿀 수 있고, 이것이 Zip Tree의 형태이다.
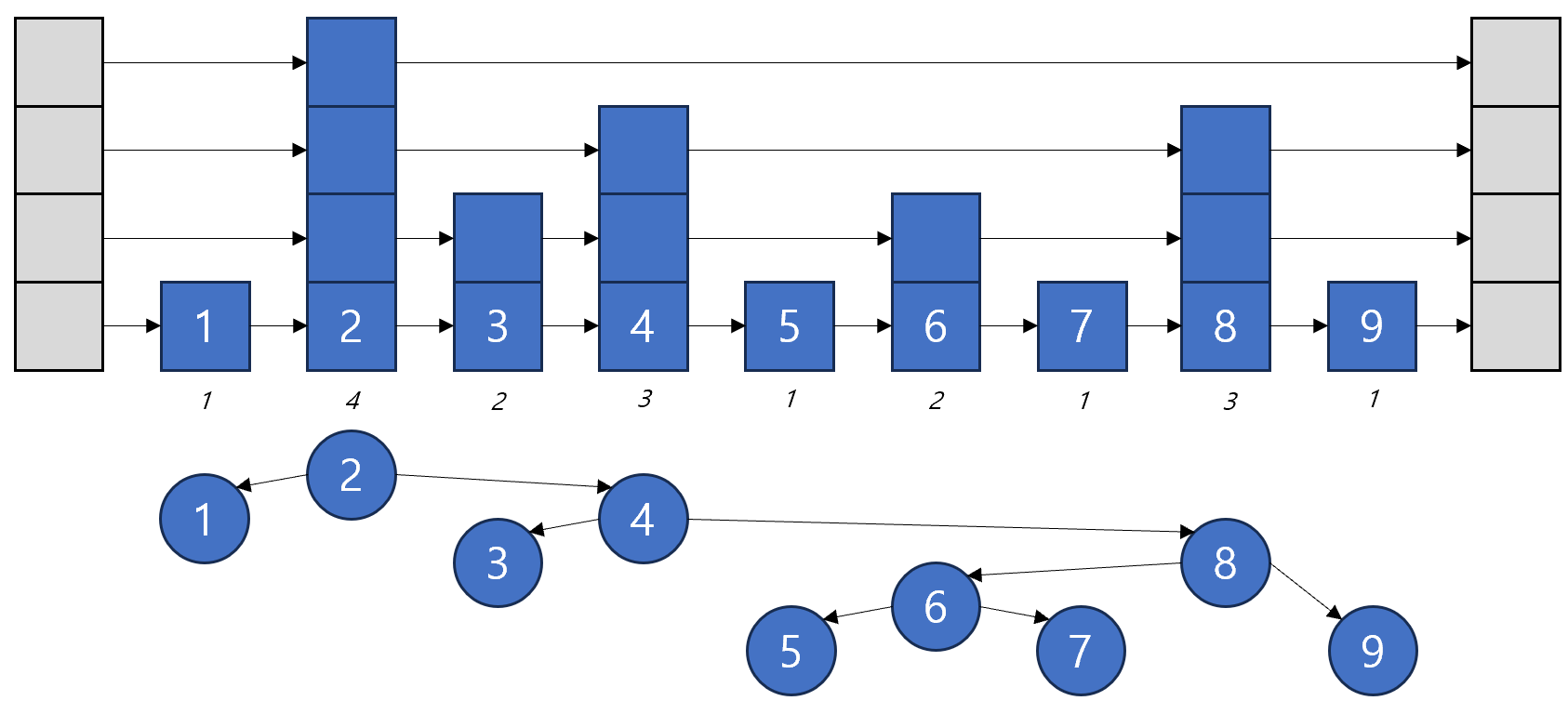
Treap vs Zip Tree
Zip Tree는 Skip List와 유사하게 동작한다. 먼저, 원소를 삽입할 때 동일하게 성공 확률이 $0.5$인 기하분포를 따르는 값을 rank로 부여한 뒤, 삽입 및 삭제 등의 연산은 Treap과 동일하게 동작한다.
여기서 흥미로운 사실은, Treap에서는 rank를 균등분포에서 추출하지만, Zip Tree는 기하분포에서 추출한다는 점이며, 이를 통해 Treap보다 약간의 메모리적 이점을 얻을 수 있다.
널리 사용되는 Treap의 경우, Binary Search Tree의 구조가 한쪽으로 치우치는 현상을 방지하기 위해서 입력 데이터에 무작위 순서를 부여하자는 발상이 들어간다. 하지만, 이 과정에서 원소들의 rank값의 충돌이 일어난다면 트리의 깊이가 늘어나고, 시간복잡도가 증가하게 된다. 따라서 구현할 경우 보통 Binary Search Tree에 삽입되는 원소의 개수 이상의 크기를 가지는 균등분포에서 rank를 추출하게 된다. 충돌을 최소화하기 위해서는 생일 문제 등을 이용하여 상당히 큰 범위에서 rank를 추출해야 한다.
일반적으로 Binary Search Tree를 사용하여 시간적인 이점을 얻기 위해서는 원소의 개수가 10만개 가량 되어야 한다. 아래 그래프는 무작위로 10만개의 원소를 Treap에 삽입한 뒤, 새로 주어지는 10만개의 원소들이 Treap에 속하는지 판단을 Online으로 해야 할 때, rank를 어떤 크기의 균등분포에서 추출하냐에 따라 달라지는 소요 시간을 로컬 환경에서 직접 측정한 것이다. (첨언하자면, 기하분포를 기반으로 rank를 정하는 Zip Tree의 경우 평균 196.7ms가 소요되었다)
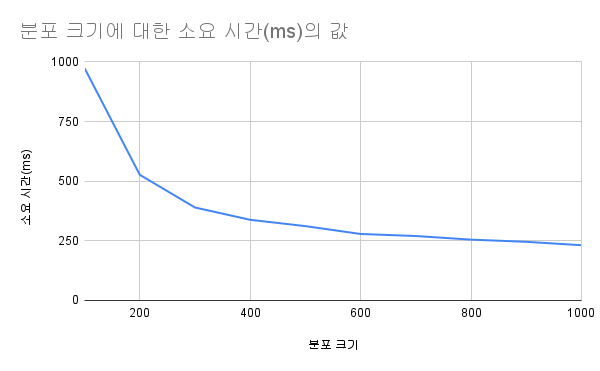
각 값은 100번의 랜덤 입력에 대한 평균 소요 시간을 나타내며, 코드별로 입력받은 데이터의 구조는 동일하다. 실험 환경에 따라 오차가 발생할 수 있겠지만, 균등분포의 범위를 늘려나감에 따라 확연히 시간이 줄어드는 것을 볼 수 있으며, 그 범위가 입력으로 주어지는 데이터 개수에 도달한 시점부터는 변화량이 작은 것을 알 수 있었다.
한편, Zip Tree의 경우, 10만개의 입력이 주어졌을 경우 rank의 값이 $32$ 이상이 될 확률은 $(0.5)^{32} \approx 2.33 \times 10^{-10}$밖에 되지 않는다. 즉, 어떠한 rank의 값을 이진수로 표현하기 위해서는 $\log N$개의 비트가 필요하므로, Treap의 경우 rank를 기록하기 위해 $\log N$의 메모리가 필요하지만, Zip Tree의 경우 $\log \log N$의 메모리로 표현이 가능하다는 것이다. 이를 통해 메모리의 이점을 챙길 수 있다.
이제 Zip Tree와 같이 기하분포를 통해 rank를 결정해도 Binary Search Tree의 균형을 유지할 수 있는지 확인해 보자. 이에 앞서, 균등 분포를 사용하는 Treap의 경우를 먼저 확인해 보자.
Treap의 깊이에 대한 분석
우선, 생일 문제를 고려하여 균등 분포의 크기를 적절히 크게 잡아 충돌이 일어날 확률이 $0$에 가깝다고 가정하자. 이제 각 원소 $x_i$에 무작위 rank값 $r_i$를 부여하면, Treap은 원소에 대해 inorder를 만족하고, rank값에 대해 heap을 만족하도록 유일하게 결정된다. 특정 원소 $x_k$가 포함된 노드의 깊이를 $depth(x_k)$라 하면, 우리는 $depth(x_k)$의 기댓값에 관심이 있다. 다음을 정의하자.
- 원소를 오름차순으로 정렬한 것을 $\;x_1,x_2,\dots,x_n\;$ 라 하자. 즉 $x_1$은 가장 작은 원소, $x_n$은 가장 큰 원소이다.
Pr(A)는 사건 $A$가 일어날 확률이다.E[Z]는 확률변수 $Z$의 기댓값이다. root의 깊이를 $0$이라고 하면, 다음의 식들이 만족한다.
$i<k$ (왼쪽에 있는 원소)일 때, $x_i$가 $x_k$의 조상 이려면 구간 ${x_i,x_{i+1},\dots,x_k}$ 안에서 우선순위가 가장 큰 원소가 정확히 $x_i$ 여야 한다.
WHY? BST+heap 성질로 인해 어떤 구간(원소들이 연속으로 모인 부분)의 루트는 그 구간 안에서 우선순위가 가장 큰 항목이다. $x_i$가 그 구간의 루트이면 그 구간의 모든 원소 위에 위치하므로 $x_i$는 $x_k$의 조상이 된다. 반대로 $x_i$가 조상이면 $x_i$는 그 구간에서 가장 큰 우선순위다.
모든 우선순위가 서로 대칭적으로 동일한 분포를 가지므로, 구간에 포함된 $m=k-i+1$개의 원소 중에서 특정 하나(여기서는 $x_i$)가 최댓값일 확률은 정확히 $\frac{1}{m}$이므로, 다음과 같은 식을 얻을 수 있다.
\[\Pr(x_i\text{ is ancestor of }x_k) = \frac{1}{k-i+1}\]유사하게 $i>k$ 인 경우에는 다음과 같다.
\[\Pr(x_i\text{ is ancestor of }x_k) = \frac{1}{i-k+1}\]따라서
\[\begin{aligned} \mathbb{E}[depth(x_k)] &= \sum_{i<k} \frac{1}{k-i+1} + \sum_{i>k} \frac{1}{i-k+1} \\ &= \sum_{j=1}^{k-1}\frac{1}{j+1} + \sum_{j=1}^{n-k}\frac{1}{j+1} \\ &= \big(H_k - 1\big) + \big(H_{n-k+1} - 1\big) \\ &= H_k + H_{n-k+1} - 2, \end{aligned}\]여기서 $H_m=\sum_{t=1}^m \frac{1}{t}$ 는 조화수(Harmonic number) 형태이다.
조화수의 표준 근사는 다음과 같으므로,
\[H_m = \ln m + \gamma + O(1)\]($\gamma$는 오일러–마스케로니 상수)
$k$가 중앙 원소일 때
\[\mathbb{E}[depth(x_k)] \approx 2\ln n + O(1).\]가 되어, $2\ln n = (2\ln 2)\log n \approx 1.3863 \log n$ 라는 깊이의 기댓값을 구해낼 수 있다.
Zip Tree의 깊이에 대한 분석
Zip Tree의 각 원소의 rank는 독립적인 기하분포에서 샘플린된다. 또한 입력으로 들어오는 원소의 순서와 관계없이, 트리 구조가 원소에 대해 inorder를 만족하고, rank값에 대해 heap을 만족하도록 유일하게 결정된다.
우선, 루트의 rank의 기댓값은 $O(\log n)$이다. 이는 루트의 rank가 $n$개의 기하표본 중 최댓값이므로, 직관적으로 알 수 있다.
이제 Zip tree의 검색 경로에서 low ancestors와 high ancestors로 나눠서 분석을 진행할 수 있다. 어떤 원소 $x$의 low ancestors란, 원소가 $x$보다 작아서 $x$의 검색 경로에서 만나는 왼쪽의 조상을 말하며, high ancestors는 검색 경로에서 만나는 나머지 원소들을 말한다. 어떠한 원소가 $x$의 조상이 되려면, 그 원소의 rank가 현재까지의 경계 rank 이상이어야 한다.
이때 경계 rank란, 현재까지 x의 low ancestor(또는 high ancestor)로 선택된 노드들 중 가장 최근에 선택된 노드의 rank이다.
경계 rank를 기준으로, 그다음에 나오는 기하분포의 독립시행 결과에 따라 다음 원소들이 경계보다 큰지 작은지 결정되며, 이러한 값들을 통해 기댓값을 계산해 볼 수 있다.
임의의 상수 $k$에 대해, $\mathbb{E}[\ell]$을 low ancestors의 갯수의 기댓값, $\mathbb{E}[h]$을 high ancestors의 갯수의 기댓값이라고 할 때, 값들은 다음과 같이 계산된다.
\[\mathbb{E}[\ell] \le k+1,\qquad \Pr\big(\ell > (1+\delta)k+1\big)\le \exp\Big(-\frac{\delta^2 k}{2+\delta}\Big).\] \[\mathbb{E}[h] \le \frac{k}{2},\qquad \Pr\big(h > (1+\delta)\tfrac{k}{2}\big)\le \exp\Big(-\frac{\delta^2 k}{2(2+\delta)}\Big).\]따라서 위 두 결과를 결합하면, 한 노드 $x$의 기대 조상 수는
\[\mathbb{E}[\ell+h] \le (k+1) + \frac{k}{2} = \frac{3}{2}k + 1 = \frac{3}{2}\log n + O(1).\]와 같이 계산된다. 더욱 자세한 설명은 논문에 잘 나와 있지만, 직관적으로 low와 high의 값이 $2$배가 차이 나는 것은 현재 rank를 결정하는 기하분포 시행에서 경계를 넘는지를 결정하는 부분인지 아닌지가 나뉘기 때문이다.
결론
Zip Tree는 Skip List의 확률적 구조를 BST로 옮겨 온 구현 관점의 변형으로 볼 수 있다. Treap과 동일한 탐색 성능(평균 $O(\log N)$)을 보장하면서도 rank를 기하분포에서 샘플링하는 것으로 rank의 저장에 필요한 메모리가 줄어든다는 이점을 제공한다. 원소의 rank를 기하분포를 기반으로 구해도 트리의 깊이가 아주 낮도록 유지할 수 있음을 보였으며, Zip Tree도 효율적인 랜덤 기반의 Binary Search Tree구조임을 알 수 있었다.
다만 실제 적용을 통해 메모리를 절약하기 위해서는 압축된 rank의 값들을 인덱스 방식 기반으로 구현하며 메모리를 적절히 할당하는 등의 복잡한 구현을 추가로 요구하며, 이를 통해 개선되는 메모리의 크기가 전체 메모리 사용량에 비해 매우 크진 않다는 한계가 있다.
참고 자료
[1] Tarjan, Robert E.; Levy, Caleb C.; Timmel, Stephen (2021-10-31). “Zip Trees”
[2] Seidel, R., Aragon, C.R.: Randomized search trees. Algorithmica 16(4-5), 464–497 (1996)