Concurrent Queue - LCRQ
concurrent , parallel , queue
Intro
Concurrent queue는 locks, databases, load balancers / task schedulers, transaction logging, HFT, network packet processing 등에서 사용됩니다. 수십 개의 스레드가 동시에 enq/deq를 수행하면서 좋은 throughput을 유지하도록 조율하는 것은 쉽지 않습니다. 작년 기준으로 LCRQ는 가장 성능이 좋은 알고리즘으로 알려져 있습니다.
LCRQ가 어떻게 동작하는지 살펴보겠습니다.
Baseline & Simple approaches
Reminder & notations
큐를 위해서는 enqueue(x)와 dequeue() -> x를 지원해야 합니다. Array-based queue에서는 enq는 tail을, deq는 head를 1씩 증가시킵니다. CAS, FAA, linearizability, correctness, Cell 등의 개념을 사용합니다.
먼저 이전 포스트에서 다뤘던 concurrent linked list를 활용하고, CAS로 tail & head 포인터를 관리하는 단순한 접근을 생각할 수 있습니다.
- 이는 매우 느릴 것입니다. 모든 스레드가 tail/head에 write를 시도하다가 대부분 실패할 것이기 때문입니다.
- 또한 head/tail과 value cell을 한꺼번에 쓰는 것은 불가능합니다. 따라서 cell과 head/tail 사이의 불일치를 허용할 수 있는 방법을 찾아야 합니다.
만약 메모리가 무한하다면(infinite array) 다음과 같이 구현할 수 있습니다:
Head , Tail : Long // 64-bit counters
A: E[] // Infinite array for elements of type E
fun Enqueue (item : E) = while ( true ) {
t := Tail.FAA(1)
if (A[t].CAS(null, item)) return
}
fun Dequeue (): E = while ( true ) {
if (Head >= Tail) return null // empty ?
h := Head.FAA(1)
if (A[h] == null && A[h].CAS(null, ⊥)) continue
return A[h]
}
이 방식이 과해 보일 수 있지만, 모든 부분은 correctness 보장을 위해 필수적입니다. 몇 가지 관찰할 점들입니다:
- 각 연산은 ticket을 받고 대응하는 하나의 cell을 할당받아 작업합니다. 해당 셀에서 성공하거나 실패하면 연산 전체를 재시도합니다. 특정 셀에는 단 하나의 Enqueue와 단 하나의 Dequeue만 할당됩니다.
- 배열 A는 무한하며 각 셀의 lifetime은
null -> <item>또는null -> ⊥형태가 됩니다. 큐가 한 번 지나간 셀은 다시는 액세스되지 않습니다.- 또한 첫 번째 포인트 때문에
null -> <item>을 할 수 있는 Enq 스레드는 하나뿐이며,null -> ⊥를 할 수 있는 Deq 스레드도 하나뿐입니다.
- 또한 첫 번째 포인트 때문에
- Deq의 empty check는 atomic하지 않습니다. 즉 Head와 Tail을 읽는 시점이 다릅니다.
- 하지만 Head와 Tail은 증가만 하므로, Head를 읽고 그다음에 Tail을 읽었을 때
Head >= Tail이라면 그 시점에 큐가 실제로 비어 있었다고 확신할 수 있습니다. - ($Head_{t_1} \ge Head_{t_0}$ 이고 $Head_{t_0} \ge Tail_{t_1}$ 이면 $Head_{t_1} \ge Tail_{t_1}$).
- 결과적으로 실패한 Dequeue는 Tail을 읽은 시점을 기준으로 linearize됩니다.
- 하지만 Head와 Tail은 증가만 하므로, Head를 읽고 그다음에 Tail을 읽었을 때
- Head가 Tail을 앞지를 수도 있습니다. 여러 스레드가 동시에 empty check를 통과한 뒤
Head.FAA(1)를 수행하면 Head가 Tail보다 커질 수 있습니다. - 이 때문에 Deq는 기대했던 item 대신
null을 보는 케이스를 처리해야 합니다. 단순히 셀을⊥로 마킹하고 재시도합니다.- 이 셀을 담당하는 Deq는 하나뿐이므로 double write, ABA 등을 걱정할 필요가 없습니다.
- 할당된 Enq는 CAS에 실패하고 다음 셀로 넘어갑니다.
- 개념적으로 이 셀은 이제 skipped 상태이며 무한 배열의 hole이 됩니다.
- 이 문제는 Enq가 CAS에 늦거나, 많은 Deq가 Head를 지나쳐서 발생할 수 있습니다.
- 이는 모든 연산이 non-blocking임을 의미합니다. 일부 Enq 스레드가 멈춰 있더라도 Deq 스레드들은 셀을 dead로 마킹하고 계속 진행할 수 있습니다.
- 하지만 livelock이 발생할 가능성이 있습니다. Enq, Deq 쌍이
Enq.FAA, Deq.FAA, Deq.CAS, Enq.CAS, ...순서로 작동한다면 종료되지 않을 수도 있습니다.
- 하지만 livelock이 발생할 가능성이 있습니다. Enq, Deq 쌍이
- 일반적인 케이스에서 Enq와 Deq는 모두 CAS에 성공하고 즉시 반환됩니다.
- 스레드들을 각 셀로 분산시켰음에도 모든 스레드는 여전히 FAA로 Head와 Tail 값을 업데이트합니다.
Concurrent Ring Queue
무한 배열이 없으므로 위 알고리즘을 바탕으로 ring buffer를 사용하여 무한 배열을 흉내 낼 것입니다. 작동 방식의 개요는 다음과 같습니다:
- 하나의 유한한 버퍼만 가지되 Head와 Tail 인덱스는 무한 배열인 것처럼 유지합니다. 즉 Head와 Tail은 wrap around 없이 계속 증가하며, 스레드는
index = ticket % capacity,epoch = ticket / capacity를 통해 셀에 접근합니다.- 즉 무한 배열과 다르게 여러 Enq/Deq 스레드가 같은 셀에 접근할 수 있습니다. 하지만 동일한 ticket number(
index, epoch쌍)를 가진 Enq/Deq 스레드는 여전히 단 하나씩만 존재합니다.
- 즉 무한 배열과 다르게 여러 Enq/Deq 스레드가 같은 셀에 접근할 수 있습니다. 하지만 동일한 ticket number(
- 버퍼가 가득 차면 Enq는 실패하고 큐를
Closed상태로 간주합니다. - 무한 배열 시뮬레이션을 위해 각 셀에 epoch를 저장하여 스레드가 현재 셀이 자신이 처리해야 할 위치인지 판단하게 합니다.
- 셀은 두 개의 워드(8B * 2)를 가지며 하나는 item용, 하나는 epoch용입니다.
- 버퍼에서 인접한 셀들이라도 무한 배열 상에서는 연속적이지 않을 수 있습니다.
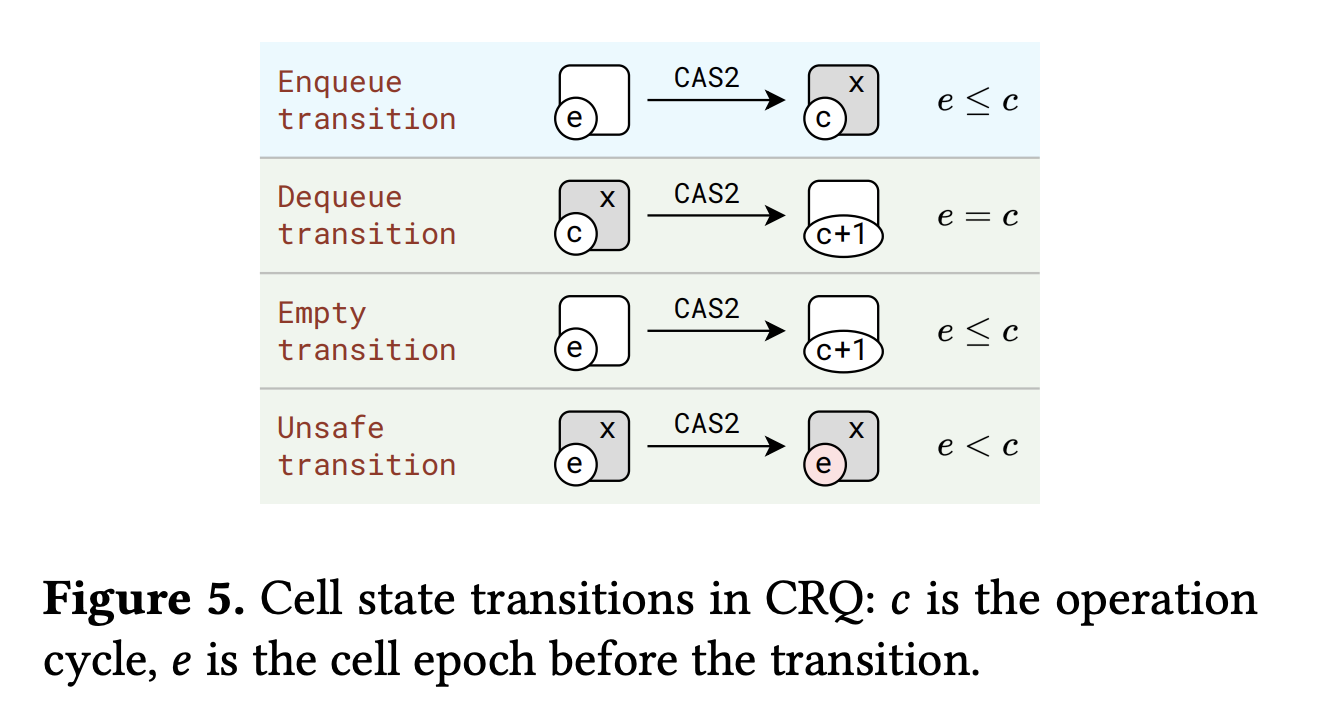
- Enqueue, Dequeue transition: 셀이 내 티켓에 해당한다면(
my ticket index == conceptual cell index) 로직은 이전과 같습니다. 성공한 Deq는 epoch를 1 증가시켜 나중에 올 Enq 스레드가 사용할 수 있게 합니다. - 내 티켓에 해당하지 않는 경우(뒤처지거나 앞서간 경우):
- 뒤처진 경우 (
my ticket index > conceptual cell index):- Enq는 셀이 비어있을 때만 사용할 수 있습니다. 비어있지 않다면 큐가 찼다는 의미일 수 있으므로 확인 후 재시도합니다.
- Empty transition: Dequeue는 비어있는 셀의 epoch를 업데이트하여 hole을 만들고 넘어갈 수 있습니다. (
null -> ⊥케이스와 동일) - Unsafe transition: 셀이 비어있지 않다면 아직 비워지지 않은 셀을 추월한 것입니다.
- 그냥 건너뛸 수도 있겠지만, 나중에 올 Enq(나와 티켓 인덱스가 같은 엔큐)가 빈 셀을 보고 값을 써버릴 수 있습니다. 이 값을 수거할 Deq가 없게 되므로 문제입니다.
- 이를 방지하기 위해 셀에
unsafe비트를 마킹합니다. Enq는 이 비트를 확인하고(자신의 짝꿍 Deq가 아직 시작하지 않았음을 확실히 알 때만 쓰고) 아니면 건너뜁니다. - 이
safe비트는 epoch 워드 안에 저장됩니다.
- 앞서간 경우 (
my ticket index < conceptual cell index): 내가 너무 오래 잠들어 있었던 것이므로 재시도합니다.
- 뒤처진 경우 (

Ring buffer 크기를 충분히 키우면 대부분의 스레드는 티켓을 받고 셀을 한두 번 읽고 쓰는 것만으로 연산을 마칩니다.
참고로 닫힘(closing) 조건이 전체 closing 연산 내내 유지되지는 않을 수 있지만, 무한 큐에서 언급했듯이 연산 중에 그러한 상태가 반드시 존재했어야 합니다.
캐시 라인 공유로 인한 false sharing 문제를 방지하기 위해 인접한 셀들이 서로 다른 cache line에 위치하도록 배치하는 최적화를 적용합니다. Linearization point는 성공한 Enq/Deq의 경우 마지막 FAA입니다.
LCRQ
LCRQ는 단순히 CRQ들을 CAS를 이용한 linked list로 관리합니다. 큐가 커져서 새로운 CRQ가 필요하면 리스트의 tail에 새 CRQ를 추가합니다. CAS로 교체되므로 CRQ 체인은 단 하나만 존재하게 됩니다.
Closed된 큐는 다시 열리지 않습니다. 실제 구현에서는 memory reclamation 기법을 사용하여 객체들을 재사용하므로 오버헤드는 미미합니다.

Limitations, Future works
LCRQ는 두 개의 FAA 객체를 사용하여 경합을 완화하지만 극심한 경합 상황에서는 여전히 이 두 객체가 병목이 됩니다. 이는 Aggregating Funnels 논문에서 보여준 것처럼 더 빠른 FAA로 개선될 수 있습니다.
또한 오리지널 LCRQ는 epoch와 value를 함께 관리하기 위해 double-width CAS를 사용합니다. 이를 피하기 위해 표준 single-width CAS만 사용하는 LPRQ와 같은 변형 알고리즘도 존재합니다.
References
-
(LCRQ) Fast Concurrent Queues for x86 Processors https://dl.acm.org/doi/10.1145/2442516.2442527
-
(LPRQ) The State-of-the-Art LCRQ Concurrent Queue Algorithm Does NOT Require CAS2 https://dl.acm.org/doi/10.1145/3572848.3577485
-
(YMC Queue) A wait-free queue as fast as fetch-and-add https://dl.acm.org/doi/abs/10.1145/2851141.2851168
-
(Aggregating Funnels) Aggregating Funnels for Faster Fetch&Add and Queues https://dl.acm.org/doi/10.1145/3710848.3710873