Tree DP 문제 해결
목차
개요
이 포스트를 쓰며
알고리즘 공부를 하면서 오랫동안 다이나믹 프로그래밍을 그것도 트리에서 해결하는 문제를 꽤 안풀었음을 알았다. 그래서 오랜만에 다이나믹 프로그래밍 연습도 할겸 트리에서 해결하는 다이나믹 프로그래밍 문제를 몇가지 공유하고 같이 풀어보고자 한다. 이번 포스트를 통해 트리에서의 다이나믹 프로그래밍에 대한 문제를 재미있게 봐주었으면 한다.
간단한 원리
기본적으로 Top-down 방식으로 해결하며, 보통 leaf node 부터 값을 알아낸다. Top-down 방식의 DP에 익숙한 사람들은 문제를 해결하기 편할 것이다. 기본적으로 DFS 처럼 leaf node 까지 순회한 뒤, 값을 알아내서 그 다음 노드들의 값들을 알아내는 방식으로 해결한다. 따라서 재귀함수가 요긴하게 사용되며 이 포스트를 이해하기 위해서는 기본적인 재귀함수 지식과, DFS, DP 정도의 알고리즘 지식이 있어야 한다.
기본
일단 뼈대가 되는 pseudo code는 다음과 같다.
function dfs(u):
visit[u] = 1
for v in edge[u]:
if visit[v]:
continue
dfs(v)
dp[u] = dosomething(dp[v]);
일단 트리에서 이루어지며 보통 양방향 간선이므로 인접리스트 $edge$는 반드시 들어가게 된다. 그 다음, $u$를 방문했는지 체크해주고, $edge[u]$의 값을 iterative 하게 조사한다. 그것을 $v$라고 한다면 $v$를 이미 방문했다면(즉, $v$가 나의 부모라면) 무시해주고 아니라면 $dfs(v)$를 통하여 다음 자식으로 이동한다. 그리고 해당 함수가 마무리 지어졌다면 $dp[v]$에 있던 값들을 통해 $dp[u]$를 갱신해준다. 이것이 기본적인 Tree DP의 뼈대이다.
구현
구현을 보여주기 위하여 다음의 문제를 참고하였다. 이 문제는 트리의 지름을 구하는 문제로서, 트리의 지름이란 임의의 두점사이의 거리중 가장 긴 거리를 구하는 것을 의미한다. 이것을 다이나믹 프로그래밍을 활용하여 해결해보자.
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
vector<int> son[10010];
vector<int> sonval[10010];
int maxd[10010];
int dp[10010];
int dfs(int);
int main() {
int n, x, y, z;
scanf("%d",&n);
for(int i = 0;i<n-1;i++) {
scanf("%d %d %d",&x,&y,&z);
son[x].push_back(y);
sonval[x].push_back(z);
}
dfs(1);
printf("%d\n",dp[1]);
return 0;
}
먼저 인접 리스트를 만들어 준다. 이 문제의 경우 양방향을 고려할 필요 없이 부모의 정보를 바로 제공하므로 $visit$을 사용하지 않고 해결하였다. 연결된 간선과 간선의 cost를 각각, $son$과 $sonval$ 에 넣어주었다. 1번 노드가 항상 루트라고 문제에서 명시되어 있기 때문에 $dfs(1)$을 호출하였다.
void dfs(int u) {
int d = 0, d2 = 0;
for(int i = 0; i < son[u].size(); i++) {
int v = son[u][i];
dfs(v);
if(d < maxd[v] + sonval[u][i]) {
d2 = d;
d = maxd[v] + sonval[u][i];
}
else if(d2 < maxd[v] + sonval[u][i]) {
d2 = maxd[v] + sonval[u][i];
}
if(dp[u] < d + d2) dp[u] = d + d2;
if(dp[u] < dp[v]) dp[u] = dp[v];
if(maxd[u] < d) maxd[u] = d;
}
}
이제 제시한 pseudo code를 이용한 코드를 봐보자. 우선 $visit$은 사용하지 않아도 되니 생략했으며, continue 부분 역시 생략했다. 이제 $dfs(v)$의 밑에 부분을 보자. 먼저 가장 큰 길이를 d라고 하고, 두번째로 큰 길이를 d2라고 하자. 이 두개를 구하는 과정은 매우 쉽다. 이제 그 $d$ 와 $d_{2}$를 더한값을 $dp[u]$와 비교해서 넣어준다. 이후, $dp[u]$에 $dp[v]$가 큰지 비교해보고 넣어준다. 이렇게 해주는 이유는 다른 노드에서 두개의 제일 긴 경로를 연결해주었을때, 그것이 최적이 될 수 있기 때문이다. 그 다음은 제일 긴 길이인 $d$를 $maxd[u]$ 에 넣어준다. 이런식으로 제일 큰 길이를 구하는 기법을 통하여 트리의 지름을 다이나믹 프로그래밍을 통하여 해결하였다.
이제 어느정도 익숙해 졌을테니 다른 문제를 해결해보록 하자.
문제풀이
트리의 가중치
이 링크를 통하여 문제를 확인해 볼 수 있다. 이 문제는 각 간선에 가중치가 배정이 되었을 때, 트리상의 모든 경로의 거리의 곱의 합을 구하는 문제이다. 즉, $\frac{n(n-1)}{2}$개의 경로들의 거리의 곱을 모두 구하는 문제이다. 이것만 봐서는 시간복잡도가 $O(n^{2})$으로 생각할 수 있다. 하지만 다이나믹 프로그래밍을 통하여 이를 개선할 수 있다.
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
const long long mod = 1000000007;
vector<int> edge[100010];
vector<long long> cost[100010];
int visit[100010];
long long dp[100010];
long long ans = 0;
void dfs(int);
int main() {
int n;
scanf("%d", &n);
for(int i = 1; i < n; i++) {
int x, y, z;
scanf("%d %d %d", &x, &y, &z);
edge[x].push_back(y);
cost[x].push_back(z);
edge[y].push_back(x);
cost[y].push_back(z);
}
dfs(1);
printf("%lld\n", ans);
return 0;
}
일단, 양방향 간선이기 때문에 다음과 같이 인접리스트를 구성해 주었다. 이후 $dp$ 배열과 전체 합을 구하기 위한 $ans$변수를 배치하였다. modulo 값이 $1000000007$ 이므로 상수값에 넣어주었다.
void dfs(int u) {
visit[u] = 1;
vector<long long> p;
for(int i = 0; i < edge[u].size(); i++) {
int v = edge[u][i];
long long c = cost[u][i];
if(visit[v]) continue;
dfs(edge[u][i]);
dp[u] += (dp[v] * c) % mod;
dp[u] %= mod;
p.push_back((dp[v] * c) % mod);
}
ans += dp[u];
ans %= mod;
long long sum = 0;
for(auto &v : p) {
sum += ((dp[u] - v + mod) % mod * v) % mod;
sum %= mod;
}
sum *= 500000004;
sum %= mod;
ans += sum;
ans %= mod;
dp[u]++;
dp[u] %= mod;
}
중요한 $dfs$ 함수이다. $dp[u]$ 함수가 의미하는 것은 노드 $u$를 루트로 삼는 부트리에서, 노드 $u$부터 다른 모든 노드 까지 가는 모든 경로들의 곱의 합을 의미한다. 이는 나중에 위에서 풀어보았던, 트리의 지름을 구하는 문제의 아이디어를 차용한 것이다. 한 노드를 공유하는 일직선 경로 두개를 합쳐서 모든 경로를 구해낼 수 있기 때문이다. 그런식으로 $dp[u]$를 $c \cdot dp[v]$들의 모든 합을 구한 것으로 하고, 그 각각의 값을 리스트 등에 따로 저장해 둔다. 이제 마무리는 간단하다. 리스트에 있던 값들을 iterative 하게 순회하면서 $(dp[u] - c \cdot dp[v]) \cdot c \ cdot dp[v]$ 을 모두 더해준 값을 구해준다. $(a + b + c)d$를 해준것과 같은 원리인데, 이것을 $a$, $b$, … 순으로 반복을 하는 것이다. 이렇게 하면 모든 경로들의 곱의 합을 구할 수 있다. 하지만, 중복이 두번 되므로 나누기 2를 해줘야 한다. 하지만 이 문제는 modulo를 사용하므로, $2$의 역원 $500000004$를 곱함으로서 나누기를 구현하였다. 이러한 방법으로 정답을 구할 수 있다. 시간복잡도는 $O(n)$ 이 된다.
우유 생산팀 선발
이 링크를 통하여 문제를 확인할 수 있다. 이 문제는 각 소가 생산할 수 있는 우유의 양이 정해졌을때(생산할 우유가 망가지는 경우도 있다.), 우유를 생산할 소들을 정하는데, 소들의 가계도를 조사하여 부모-자식간의 관계가 최대한 많이 발생하면서 X이상의 우유를 생산하는 것이 목표인 문제이다. 이 문제는 매우 전형적인 다이나믹 문제지만 재미있는 트릭이 있으니 같이 보도록 하자.
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
int n;
vector<int> son[510];
int cost[510];
int dp[510][510][2];
int cnt[510];
void dfs(int);
int main() {
int X;
for(int i = 0; i < 510; i++) for(int j = 0; j < 510; j++) dp[i][j][0] = dp[i][j][1] = -987654321;
scanf("%d %d", &n, &X);
for(int i = 1; i <= n; i++) {
int x, y;
scanf("%d %d", &x, &y);
son[y].push_back(i);
cost[i] = x;
}
dfs(0);
for(int i = n; i >= 0; i--) {
if(dp[0][i][0] >= X) {
printf("%d\n", i);
return 0;
}
}
printf("-1\n");
return 0;
}
먼저 음수가 존재하므로 $dp$를 전부 음수로 초기화 해주는 것이 중요하다. 두번째로, 0번째 가상의 노드를 만들어 각각 떨어진 가계도를 하나로 뭉쳐주는 것이 중요하다. 이후 0번을 루트노드 삼아서 $dfs$를 실행한다.
void dfs(int u) {
int sub[510][2];
cnt[u] = 1;
dp[u][0][0] = 0;
dp[u][0][1] = cost[u];
for(int i = 0; i < son[u].size(); i++) {
int v = son[u][i];
dfs(v);
for(int j = 0; j <= cnt[u]; j++) {
sub[j][0] = dp[u][j][0];
sub[j][1] = dp[u][j][1];
}
for(int j = cnt[u]; j >= 0; j--) {
for(int k = cnt[v]; k >= 0; k--) {
dp[u][j+k][0] = max(dp[u][j+k][0], sub[j][0] + dp[v][k][0]);
dp[u][j+k][0] = max(dp[u][j+k][0], sub[j][0] + dp[v][k][1]);
dp[u][j+k][1] = max(dp[u][j+k][1], sub[j][1] + dp[v][k][0]);
dp[u][j+k+1][1] = max(dp[u][j+k+1][1], sub[j][1] + dp[v][k][1]);
}
}
cnt[u] += cnt[v];
}
}
$dfs$ 부분은 이 문제에서 아이디어를 얻어서 시작한다. 100만은 너무 큰 숫자니, 가능한 부모자식 관계에서 가장 큰 우유 생산량을 담도록 하는 것이다. 이렇게 한다면, 위에 main 함수에서 보듯이 0번 노드에서 생산량이 X를 넘는 부모자식 관계가 제일 큰것을 구하게 하면 된다. 그러면 이번에 점화식을 살펴보자. 먼저 $sub$라는 toggle 배열을 만들어둔다. 이후 $dp[x][y][0]$은 $x$번 젖소를 사용하지 않는것을 의미하고 $dp[x][y][1]$은 $x$번 젓소를 사용하는것을 의미한다. 그리고 $y$는 부모자식간의 관계를 의미한다. 그러므로 부모자식 관계가 1 만큼 늘어나는 $dp[u][j+k+1][1]$ 은 $dp[u][j][1]$ 에 해당하는 $sub[j][1]$을 더해야하고 $dp[v][k][1]$ 더하면 부모자식 관계가 1 만큼 늘어난 $j+k+1$을 조사하게 될 수 있다. 그 이외의 경우엔 $j+k$로 하도록 한다. 이렇게 구하면 시간복잡도가 $O(n^{3})$ 이 되지만 여기엔 엄청난 트릭이 있다. 바로 $cnt[u]$ 와 $cnt[v]$ 인데, 이것은 서브트리의 전체 노드 개수를 의미한다. 즉, $dp[u]$와 $dp[v]$가 합쳐질 때, 노드의 개수도 점점 커지면서 계산하게 된다. for를 그 개수로 한정짓는 것이다. 이렇게 되면 시간복잡도는 $O(n^{2})$이 되는데 조금 생각해보면 사향트리, 혹은 n-tree의 경우를 생각해보면 $O(n^{2})$인 이유가 바로 나오며, 최악의 경우 완전 이진 트리 혹은 완전 삼진 트리 등의 다양한 경우를 생각해보아도 항상 시간복잡도는 $O(n^{2}$으로 같다.
두더지
이 링크를 통하여 문제를 확인할 수 있다. 이 문제는 트리가 주어지면, 간선 하나를 지우고 새로운 간선을 배치함으로서 트리의 지름을 최소화 하는 문제이다. 우선 이 링크를 통하여 트리의 지름을 구하는 다이나믹 프로그래밍을 사용하지 않는 간략한 알고리즘과 그 증명을 살펴보고 오자. 이 문제에 대한 아이디어는 다음과 같다. 먼저 한 간선을 제거했을때 나오는 두개의 서브트리들의 노드들을 전부 연결해 보는것이다. 즉, brute force 로 접근하는 것이다. 이 경우의 시간 복잡도는 $O(N^{4})$ 하지만, N크기가 30만이니 더 줄여야할 것이다. 그렇다면 이 아이디어를 개선해 보자. 우선 나누어진 두개의 부트리들의 지름중 제일 큰것이 새로 만들어질 트리의 지름의 후보가 될것은 자명하다. 문제는 두개의 부트리를 연결해서 생기는 새로운 경로의 길이를 가장 짧게 하는것이 우리의 목표가 될것이다. 그렇다면 두개의 부트리를 연결하는 과정에서 새로운 경로를 가장 짧게 하려면 어떻게 해야할까? 바로 각 지름의 중심부, 즉 길이를 $\frac{1}{2}$로 해주 는 지점을 찾아서 서로 연결해주면 $[\frac{l_{1} + 1}{2}] + [\frac{l_{2} + 1}{2}] + 1$의 길이만큼이 가능한한 적게 줄이는 것이 된다. 그 증명은 간단한 것이, 귀류법을 활용 하여, 만약 그 절반지점을 연결했을때, 더 긴 지점이 존재한다고 가정하자. 그렇다면 그 더 긴 지점이 자연스레 최초의 지름이라고 가정했던것 보다 더 길 수 밖에 없으므로 처음의 가정과 모순이다.
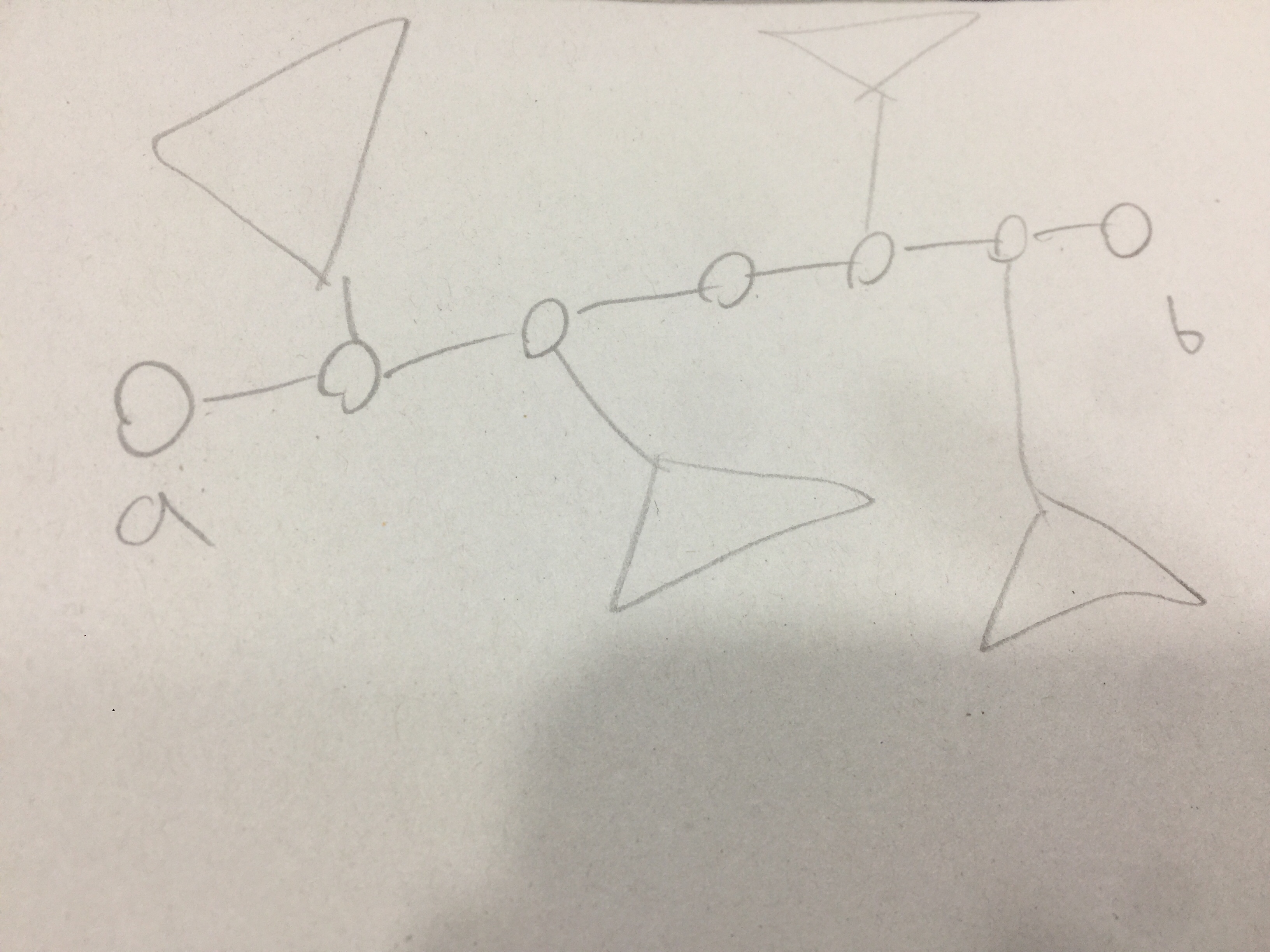
즉, 지름의 절반되는 지점끼리 연결해주면 되므로 모든 노드들을 연결해볼 필요가 없게 된다. 이 경우에 시간 복잡도는 $O(n^{2})$이 된다. 하지만 여전히 N이 30만 이므로, 시간초과는 피할 수 없다. 이 문제를 해결하기 위해, 우리는 이제 다이나믹 프로그래밍을 도입해야한다. 그것은 바로 각 부트리의 가장 긴 지름을 알아내는 것이다. 먼저 1을 루트로 한 트리에서의 각 노드들을 루트 로 취급하는 부트리는, 구하기 매우 쉽다. 바로 이 포스트의 처음에서 설명한 방법으로 구하면 된다. 하지만 잘라지고 난 다음에 생기는 다른 부트리는 어떻게 구해야 할까? 그것은 의외로 간단하다. 우리가 구한 $dp$배열을 역 이용해서 새로운 $dp2$배열을 만들어서 활용하면 되기 때문이다. 내려가는 과정에서 sibling 들의 $dp$값과 부모의 $dp2$값을 활용하는 기법을 사용하면 또 다른 서브트리의 값을 구하는건 매우 쉽다.
#include <cstdio>
#include <algorithm>
#include <queue>
#include <vector>
#include <set>
using namespace std;
int dp[300010];
int dp2[300010];
int maxd[300010];
int maxd2[300010];
int visit[300010];
int visit2[300010];
vector<int> edge[300010];
int ans = 300001, a, b;
void dfs(int);
void dfs2(int);
int bfs(int);
int main() {
int n;
scanf("%d", &n);
for(int i = 0; i < n - 1; i++) {
int x, y;
scanf("%d %d", &x, &y);
edge[x].push_back(y);
edge[y].push_back(x);
}
dfs(1);
dfs2(1);
printf("%d\n%d %d\n", ans, a, b);
int na = bfs(a);
int nb = bfs(b);
for(int i = 1; i <= n; i++) dist[i] = trace[i] = 0;
int la = bfs(na);
int lb = bfs(nb);
int aa = la;
for(int i = 0; i < dist[la] / 2; i++) aa = trace[aa];
int ab = lb;
for(int i = 0; i < dist[lb] / 2; i++) ab = trace[ab];
printf("%d %d\n", aa, ab);
}
먼저 main부를 살펴보자, 인접 리스트를 만들고 $dfs$, $dfs2$를 두번 실행시킴으로서 정답을 알아낸다. 그 다음, 알아낸 정답을 통하여 각 부트리의 지름과 각 지름의 끝점 좌표들을 추출한 뒤, 지름의 중심 좌표를 알아낸 뒤, 출력한다.
void dfs(int u) {
visit[u] = 1;
int d = -1;
int subd = -1;
for(int i = 0; i < edge[u].size(); i++) {
int v = edge[u][i];
if(visit[v]) continue;
dfs(v);
if(maxd[v] > d) {
subd = d;
d = maxd[v];
}
else if(maxd[v] > subd) subd = maxd[v];
dp[u] = max(dp[u], dp[v]);
}
maxd[u] = d + 1;
dp[u] = max(dp[u], subd + d + 2);
}
그 다음 지름의 길이를 구하는 $dfs$이다. 이 코드는 익숙할 테니 설명은 생략한다.
void dfs2(int u) {
visit2[u] = 1;
multiset<int> mds, ds;
for(int i = 0; i < edge[u].size(); i++) {
int v = edge[u][i];
if(visit2[v]) continue;
mds.insert(maxd[v]);
ds.insert(dp[v]);
}
for(int i = 0; i < edge[u].size(); i++) {
int v = edge[u][i];
if(visit2[v]) continue;
mds.erase(mds.find(maxd[v]));
ds.erase(ds.find(dp[v]));
dp2[v] = dp2[u];
maxd2[v] = maxd2[u] + 1;
int maxlen = max(dp2[u], maxd2[u]);
if(ds.size()) {
int k = *(--ds.end());
if(k > dp2[v]) dp2[v] = k;
if(maxlen < k) maxlen = k;
}
if(mds.size()) {
int k = *(--mds.end());
int k2 = -1;
if(mds.size() > 1) k2 = *(--(--mds.end()));
if(k + 2 > maxd2[v]) maxd2[v] = k + 2;
if(k + k2 + 2 > dp2[v]) dp2[v] = k + k2 + 2;
if(k + 2 > dp2[v]) dp2[v] = k + 2;
if(k + 1 + maxd2[u] > dp2[v]) dp2[v] = k + 1 + maxd2[u];
if(maxlen < k + k2 + 2) maxlen = k + k2 + 2;
if(maxlen < k + 1) maxlen = k + 1;
if(maxlen < k + 1 + maxd2[u]) maxlen = k + 1 + maxd2[u];
}
dfs2(v);
mds.insert(maxd[v]);
ds.insert(dp[v]);
int subans = max({dp[v], maxlen, (dp[v] + 1) / 2 + (maxlen + 1) / 2 + 1});
if(ans > subans) {
ans = subans;
a = u;
b = v;
}
}
}
하이라이트인 dfs2이다. 원래 가장 최대값 세개를 추출하여 돌려 써가면 $O(n)$에 해결할 수 있지만, 코드의 복잡성이 높아지므로 multiset을 사용하여 $O(n log n)$에 해결하였다. 원래 구했던 $dp$와 $maxd$, 그리고 그것들을 사용하여 $dp2$와 $maxd2$를 새로 구해준다. 이를 통하여 $u$를 포함하는 부트리를 구할 수 있게 된다.
int dist[300010];
int trace[300010];
int bfs(int start) {
queue<int> q;
q.push(start);
dist[start] = 1;
int maxlen = 1, ed = start;
while(q.size()) {
int u = q.front();
q.pop();
if(maxlen < dist[u]) {
maxlen = dist[u];
ed = u;
}
for(int i = 0; i < edge[u].size(); i++) {
int v = edge[u][i];
if(u == a && v == b) continue;
if(u == b && v == a) continue;
if(dist[v]) continue;
dist[v] = dist[u] + 1;
trace[v] = u;
q.push(v);
}
}
return ed;
}
마지막은 $bfs$인데 이 과정에 대한 설명은 처음 트리의 지름을 쉽게 구하는 위 링크로 대체한다.
이러한 과정을 통하여 $O(n^{2})$풀이를 $O(n log n)$ 으로 줄일 수 있게 된다. 물론 위에서 언급한 최대값을 세개만 들고다니며, 그때마다 갱신하는 방법을 사용하면 $O(n)$ 까지 줄일 수 있다. 이는 참고만 하도록 하자.
나무수송
이 링크를 통하여 문제를 확인할 수 있다. 이 문제는 각 강(간선)의 길이와, 각 마을(노드)에서 생산되는 나무의 양이 주어졌을 때, 목공소를 지어서 나무를 운반하는 비용을 줄이는 문제이다. 이 문제는 목공소를 설치한다에 집중하면 쉽게 풀린다. 일단 3차원 배열을 잡을것인데, 각각의 상태공간을 다음과 같이 생각한다. $dp(u, l, t)$ 가 있다고 하자. 이때 $u$는 현재 마을위치, 즉, 노드를 의미한다. $l$은 목공소가 마지막으로 생성된 지점이다. $t$는 앞으로 지을 수 있는 목공소의 개수를 의미한다. 이렇게 상태공간을 정의하는 순간 점화식은 매우 간단하게 나온다. 나보다 상류에 있는 마을, 즉, 자식 노드를 $v_{i}$라고 하자. 이때, 내가 $u$ 마을에 목공소를 짓는 경우, 즉, $t > 0$ 인 경우 $dp(v_i, u, j)$ 들 중, $j$들의 합이 $t - 1$이 되는 것 중 최소값을 찾으면 된다. 이것은 단순 다이나믹 프로그래밍로 쉽게 구해줄 수 있다. 두번째로는 목공소를 설치하지 않고 그대로 넘기는 경우, $dp(v_i, l, j)$ 들 중, $j$들의 합이 $t$가 되는 것중 최소값을 찾으면 된다. 이것 역시 단순 다이나믹 프로그래밍으로 해결할 수 있다. 이 경우엔 목공소를 설치하지 않으므로 현재 위치에서 생산된 나무는 반드시 l노드까지 올려보내져야 하고, 그 과정에서 발생하는 비용인 $length_{ul} \cdot cost$를 더해주어야 한다. 여기서 cost는 u에서 생산된 나무의 개수를 의미한다. 그렇게 하여 구한 두개의 최소값중 작은걸 선택하면 된다. Top-down 테크닉을 활용하면 보다 직관적으로 짤 수 있다.
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
int node[110];
int length[110];
int v[110];
long long dp[110][110][110];
vector<int> edge[110], cost[110];
vector<int> trace;
long long dfs(int, int, int);
void init(int u, int len) {
length[u] = len;
node[u]++;
trace.push_back(u);
for(int i = 0; i < edge[u].size(); i++) {
init(edge[u][i], len + cost[u][i]);
node[u] += node[edge[u][i]];
}
for(int i = 0; i < trace.size(); i++) dp[u][trace[i]][node[u]] = 0;
}
int main() {
int n, k;
scanf("%d %d", &n, &k);
for(int i = 0; i < 110; i++) for(int j = 0; j < 110; j++) for(int k = 0; k < 110; k++) dp[i][j][k] = -1;
init(0, 0);
for(int i = 1; i <= n; i++) {
int x, y, z;
scanf("%d %d %d", &x, &y, &z);
edge[y].push_back(i);
cost[y].push_back(z);
v[i] = x;
}
init(0, 0);
printf("%lld\n", dfs(0, 0, k));
return 0;
}
main함수 내부는 늘 보듯이 edge추가와 cost추가가 있다. 이때 init 함수가 추가되는데, 바로 현재 노드에 해당하는 부트리에 모든 노드의 개수가 t와 같다면 비용은 항상 0 이라는 점을 넣어주기 위함이다. 그 뿐만 아니라 두 노드간의 length를 구해주기 위한 초기화 작업이기도 하다.
long long dfs(int u, int l, int t) {
if(dp[u][l][t] != -1) return dp[u][l][t];
long long ans1[110], ans2[110], tmp1[110], tmp2[110];
for(int i = 0; i < 110; i++) ans1[i] = ans2[i] = tmp1[i] = tmp2[i] = 1ll << 50;
ans1[0] = 0;
ans2[0] = 0;
for(int i = 0; i < edge[u].size(); i++) {
int v = edge[u][i];
for(int j = 0; j <= t; j++) {
tmp1[j] = ans1[j];
ans1[j] = 1ll << 50;
tmp2[j] = ans2[j];
ans2[j] = 1ll << 50;
}
for(int nt = 0; nt <= t; nt++) {
if(nt > node[v]) break;
long long x = dfs(v, l, nt);
for(int j = t; j >= 0; j--) {
if(j + nt > t) continue;
ans1[j + nt] = min(ans1[j + nt], tmp1[j] + x);
}
if(nt < t) {
long long x = dfs(v, u, nt);
for(int j = t - 1; j >= 0; j--) {
if(j + nt >= t) continue;
ans2[j + nt] = min(ans2[j + nt], tmp2[j] + x);
}
}
}
}
if(t == 0) return dp[u][l][t] = ans1[t] + v[u] * (length[u] - length[l]);
else return dp[u][l][t] = min(ans1[t] + v[u] * (length[u] - length[l]), ans2[t - 1]);
}
$dfs$함수는 위에서 설명한 그대로이다. 단순 다이나믹 프로그래밍으로 위에서 설명한 점화식으로 최솟값을 구하고, 그 중에서 제일 작은 최솟값을 고르는 과정이다. 이 경우에 시간복잡도는 $O(n^{2}k^{2})$이 된다.
마무리
이 포스트를 통해 Tree에서의 다이나믹 프로그래밍을 하는 것에 대해 좀 더 흥미를 가졌으면 좋겠고, 문제풀이에 도움이 되었으면 한다. 트리에 관련된 문제는 어려우면서도 좋은 문제가 많다. 다 같이 즐거운 Tree DP 문제를 풀어보는 것이 어떨까?
참고자료
- blog.myungwoo.kr; 트리의 지름 구하기. 전명우
- oi.edu.pl; IOI 2006 Task and Solutions. ioi2005