이진탐색의 확장 - 트리에서의 효율적인 탐색
서론
이진탐색은 정렬된 $N$개의 원소가 있을 때, 원하는 수의 위치를 $O(\log N)$ 시간에 찾는 테크닉이다. 이 글에서는 이진탐색을 트리로 확장할 것이다. 그리고 트리에서도 원하는 수의 위치를 $O(\log N)$시간에 찾을 수 있다는 증명과, 비교연산을 최소로 하는 방법을 설명할 것이다.
이진탐색
탐색이란 숨겨진 $a$ 이상 $b$이하의 정수 $x$에 대해, 이 $x$를 찾는 과정이다. 이진탐색에서는 다음과 같은 질문을 할 수 있다: “어떤 수 $y$ 에 대해, $y$와 $x$의 대소관계는 무엇인가?”
$y$가 $x$보다 크다는 답이 돌아오면, 우리는 $x$가 $y+1$ 이상 $b$ 이하라는 사실을 알 수 있고, $y$가 $x$보다 작다는 답이 돌아오면, $a$ 이상 $y-1$ 이하, $y$가 $x$와 같다면, 답이 $y$라는 사실을 알 수 있다. 여기서 $y$를 $\left\lfloor \dfrac{a+b}{2} \right\rfloor$로 설정 할 경우에, 구간의 크기인 $b-a+1$ 이 무조건 $\dfrac{b-a+1}{2}$이하로 줄어듦을 알 수 있다. 우리가 탐색해야 할 구간의 크기가 절반으로 줄어들었기 때문에, 이 과정을 $\left\lfloor \log_2 (b-a+1)) \right\rfloor$ 번 진행하면 답을 무조건 찾을수 있음이 알려져 있고 이가 이진탐색이다.
우리는 이 이진탐색이 제일 효율적이라는 것을 상대자 논증으로 증명할 수 있다. 수를 정해놓고 대답하는 것이 아니라, 작다나 크다라는 답 중에 범위가 더 긴 곳을 선택하면, 어떤 질문이 오더라도 질문의 횟수를 $\left\lfloor \log_2 (b-a+1)) \right\rfloor$번 이상으로 강제할 수 있다.
트리탐색
트리에서의 탐색은 어떤 노드 $x$를 찾는데 노드 $y$가 주어지면, $x$가 $y$인지 혹은, 어떤 subtree에 있는지 알려준다.
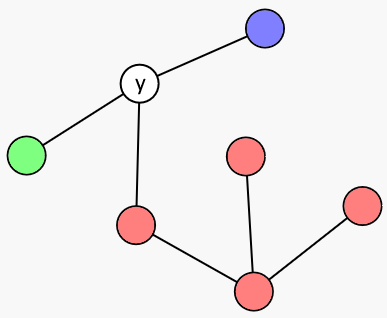
여기서 우리가 $y$ 를 주면 노드 $x$ 가 $y$ 인지, 파란색 노드 중 하나인지, 초록색 노드 중 하나인지, 혹은 빨간색 노드 중 하나인지를 알려준다. 이진탐색은 트리탐색의 특이한 케이스이다. 트리가 일직선인 경우에 트리탐색은 이진탐색이다. 우리는 트리 탐색에서도 노드의 수를 절반 혹은 그 이하로 줄일 수 있는 위치가 존재한다는 것을 증명할 것이다.
트리 $T$ 어떤 노드 $y$에서 탐색을 할 때, 노드의 수가 절반 초과인 서브트리 $S$가 존재하고, 그 서브트리에서 $y$에 가장 가까운 노드를 $z$ 라고 하면, $z$ 의 한 서브트리는, $(S \setminus T) \cup {y}$ 로, 노드의 수가 절반 이하이고, 다른 서브트리는 $S$ 보다 크기가 작으므로, 노드의 수가 절반 초과인 분할이 있으면, 노드의 위치를 옮기는것으로 더 최적의 분할을 찾을 수 있다.
그래서 최악의 경우에도 트리의 크기가 절반이하가 됨을 보장하고, 마찬가지로 $O(\log \mid T \mid)$ 번 진행하면 우리는 트리 탐색에서 원하는 노드를 찾을 수 있다.
최적의 트리탐색
항상 최대 서브트리 크기를 최소로 줄이는게 최적은 아니다.
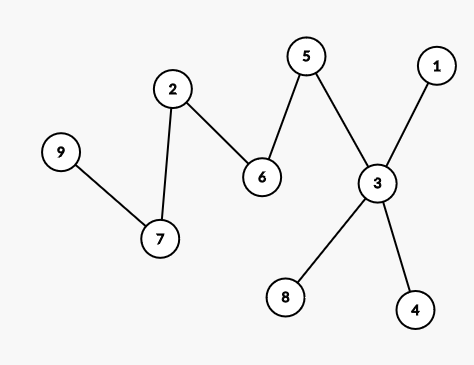
아래의 예제 같은 경우에는, 서브트리 크기를 최소로 줄이는 것은 5번 노드를 선택해서 양쪽 서브트리 크기를 5로 만드는 것이다. 하지만 이럴 경우에 [9, 2, 7, 6] 에서 원하는 노드를 찾는 것을 2번 더 물어봐야 한다. 하지만, 6을 고를 경우, [9, 2, 7] 과 [3, 5, 1, 8, 4] 에서 각각 2와 3을 물어보는 것으로 추가로 1번만 더 물어봐도 된다. 우리는 이렇기 때문에 최적의 트리 탐색은 $\lfloor \log \mid T \mid \rfloor$ 보다 작거나 같지만, 추가적으로 트리 구조에 대한 분석이 필요한 것을 알 수 있다.
우리는 트리 노드에 1 이상의 정수 rank를 하나씩 다음과 같은 규칙에 따라 붙여줄 것이다: “어떤 노드 $u$와 $v$가 같은 rank를 가지고 있으면, $u$와 $v$를 잇는 경로상에는 rank가 그 보다 큰 정수가 무조건 존재한다.”
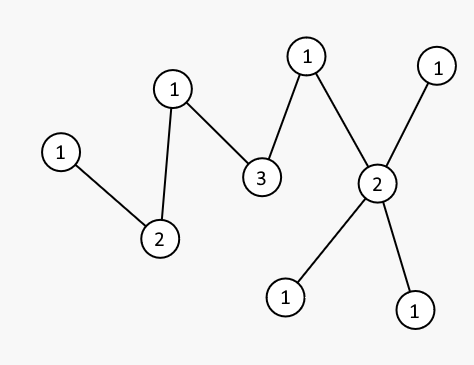
Rank는 여러가지 방법으로 붙일 수 있고, 이 규칙에 따라 rank를 붙이면, 트리 탐색을 다음과 같은 방법으로 할 수 있다:
- rank 가 가장 큰 노드를 고른다.
- 답으로 나온 서브트리에 대해서 1번을 반복한다.
어떤 트리에 대해서 rank가 가장 큰 노드는 유일하다. (둘 이상이면, rank가 큰 정수가 존재한다는 것에 대해 모순이다.) 그렇기 때문에, 서브트리에서 최대 랭크는 계속 1씩 줄어들며, 이 rank는 곧 트리탐색에서 어떤 순서로 물어볼지의 여부와 같다. 우리는 가능한 rank 중에서 rank의 최댓값이 제일 작은 것을 찾으려고 한다.
트리 위에서의 동적 계획법
우리는 임의의 루트를 잡고 이 노드 $v$ 에 대해서 rank $r$ 가 보인다는 것을 다음과 같이 정의할 것이다: “$v$의 rank가 $r$이거나, $v$에서 ($v$를 포함하여) rank $r$이하의 노드만 통해서 rank $r$인 노드로 이동할 수 있다.”
이럴 경우, 어떤 노드 $v$에 어떤 rank를 할당할 수 있는지는, 그 노드의 자식들에 대해서 어떤 rank들이 보이는 지로 쉽게 결정할 수 있다: “자식 중에 rank $r$이 보이는 노드가 둘 이상 있으면, 해당하는 노드에는 rank $r$ 이하를 붙일 수 없다.”
이는 만약에 rank $r$ 이하가 붙은 경우, 두 자식의 rank $r$ 인 두 노드의 경로가 모두 rank가 $r$ 이하가 되기 때문이다. 그렇기 때문에 이 조건을 만족하지 않는 최소의 rank를 노드에 붙여나갈 수 있고, 그 위의 rank도 붙일 수 있다. 우리는 그리디하게 최소의 rank를 붙여나간다. 이게 최소인 이유는 어떤 노드에서 rank $r_i$들이 보이면 충분히 큰 수 $M$ 에 대해 $M^{r_i}$의 합으로 표현한다고 하고, 이를 $DP(v)$ 라고 하면, $DP(v)$ 는 자식 $c_i$ 들의 $DP(c_i)$ 값의 합보다 무조건 크며 위처럼 그리디 하게 붙이는 방법은 큰 $DP(c_i)$ 를 붙이는 방법중에 최소로 붙인 방법이기 때문이다. 그래서 이 $DP$ 값의 최솟값을 계산하는 것은 rank의 최댓값이 제일 작은것과 동일 하며, 그리디하게 숫자를 붙이고 위와 같은 방법으로 트리 탐색을 하는 것이 가장 좋은 방법이다.
rank는 $O(\log N)$ 보다 작은게 보장되어있으므로 시간 복잡도 $O(N \log N)$ 에 이를 찾을 수 있다.
결론
이 트리 탐색은 일반적인 이진탐색을 트리구조에 대해서 확장하며, 주어진 트리에 대해서 가장 효율적인 이진탐색 방법을 찾는다. 이 방법은 쿼리가 굉장히 비싼 경우에 (어떤 방향에 노드가 존재하는지를 물어보는 연산이 비싼 경우) 잘 활용할 수 있는 방법이다. 또한 트리를 효율적으로 나눌 수 있는 구조에 대해서 설명 해 주기 때문에 트리를 부분부분 나눠서 분석해야 할 경우에 어느 부분에서 나누는게 좋은지에 대한 설명도 해 준다.