Pay Less Attention with Lightweight and Dynamic Convolutions 리뷰
self-attention , machine-learning , natural-language-processing
컨볼루션 그림은 이 글(https://qiita.com/koreyou/items/328fa92a1d3a7e680376)을 참고해서 만들었습니다.
소개
시퀀스-투-시퀀스(Sequence-to-sequence) 모델은 자연언어처리(Natural Language Processing) 분야의 다양한 테스크를 처리하기 위해 쓰이고 있습니다. 이중 수많은 SOTA 모델이 “Attention Is All You Need”에서 소개된 트랜스포머(Transformer)를 기반으로 설계되어있고 이 모델에서 사용하는 어텐션 기법인 셀프 어텐션(self attention)은 SOTA 성능을 달성하기 위해 꼭 필요한 구조로 여겨지곤 합니다.
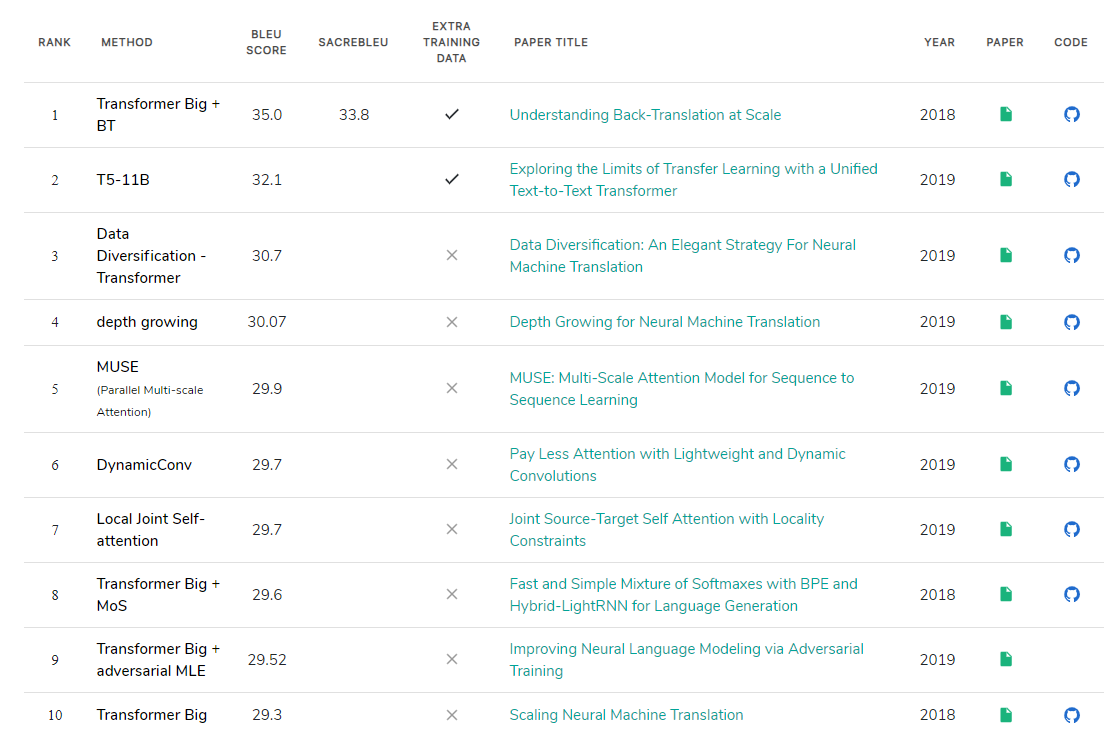
WMT2014 영어-독일어 데이터 셋에서 기계 번역 모델의 성능 순위 (2019.12.30)
“Pay Less Attention with Lightweight and Dynamic Convolutions”은 facebook AI research 팀의 논문으로 ICLR 2019에서 공개되었습니다. 이 논문에서는 셀프 어텐션의 단점으로 큰 연산 수를 지적하며 더 효율적인 어텐션인 lightweight 컨볼루션과 dynamic 컨볼루션을 제안합니다. 저자는 WMT’14 영어-독일어 데이터 셋에서 dynamic 컨볼루션을 사용하여 그 당시 SOTA 기록인 29.7 BLEU를 달성함으로써 셀프 어텐션 없이도 훌륭한 성능의 모델을 만들 수 있음을 보여줍니다.
셀프 어텐션
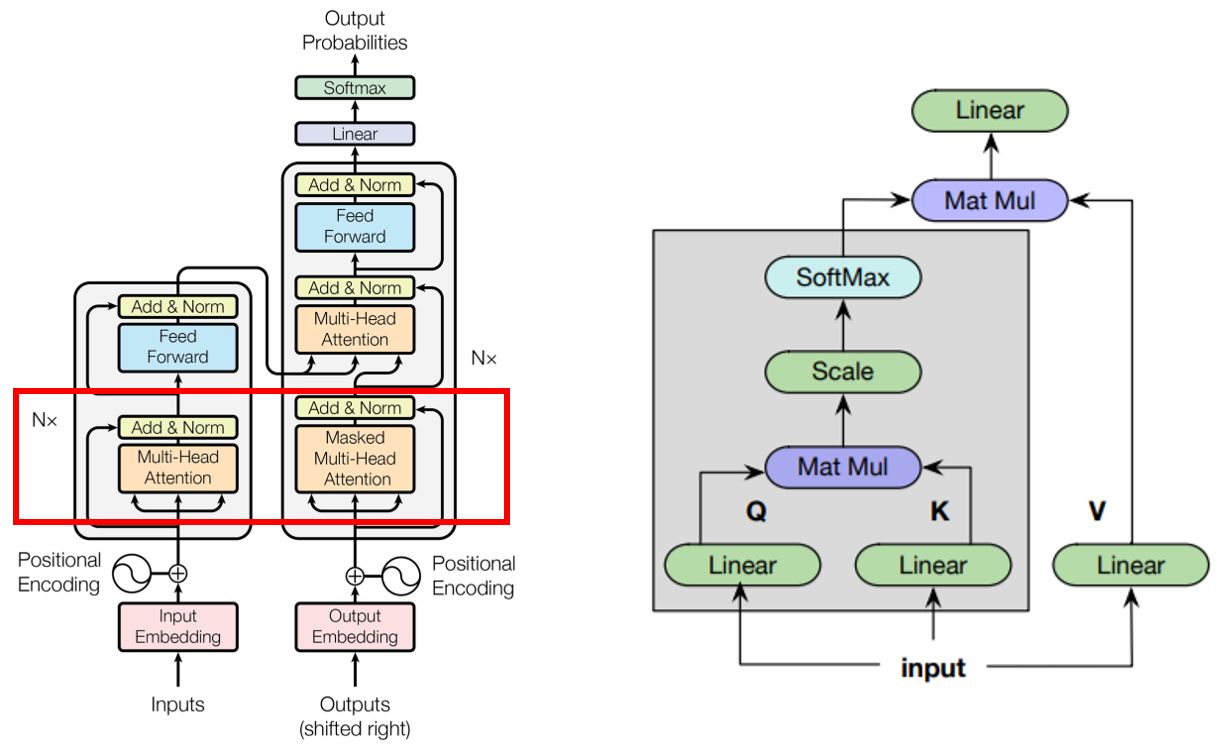
트랜스포머(왼쪽)와 셀프 어텐션(오른쪽) 구조
트랜스포머에서 인코더(encoder)와 디코더(encoder) 각각의 첫 번째 서브레이어에서 셀프 어텐션을 사용하고 있습니다. 기존의 소스-타켓 어텐션(source-target attention)이 타겟 시퀀스를 형성하기 위해 다른 소스 시퀀스의 정보를 요약하는 반면, 셀프 어텐션은 한 시퀀스 내에서 각 단어 벡터쌍에 대한 정보를 요약합니다. 셀프 어텐션은 시퀀스가 입력으로 들어오면 이를 선형 모듈을 통해 쿼리(query), 키(key), 벨류(value) 표현 벡터를 얻고, 쿼리 벡터와 키 벡터간의 내적을 구한 뒤, 안정적인 학습을 위해 스케일링을 합니다. 이 값을 softmax 함수를 통해 normalize를 하고, 벨류 벡터들과 같이 가중치 합을 구한 뒤, 선형 모듈을 통해 최종적인 결과를 얻습니다.
논문에서는 셀프 어텐션이 다음과 같은 문제점을 가지고 있음을 지적합니다.
- 장기 의존성을 모델링하는 능력이 확실하지 않다.
- 필요한 연산 수가 시퀀스 길이의 제곱에 비례하기 때문에 컨텍스트 사이즈가 큰 경우에 사용하기 어렵다.
- 실제로 긴 길이의 시퀀스에 대해서는 계층 구조를 적용해야 한다.
저자는 이러한 문제점을 해결하기 위해 연산 수가 시퀀스 길이에 비례하지만 성능은 셀프 어텐션과 비슷하거나 나은 lightweight 컨볼루션, dynamic 컨볼루션을 제시합니다. 두 컨볼루션은 depthwise 컨볼루션을 기반으로 설계되었기 때문에 depthwise 컨볼루션에 대해 먼저 설명하고 저자가 제시한 두 컨볼루션에 대해서 살펴보겠습니다.
일반적인 1D 컨볼루션
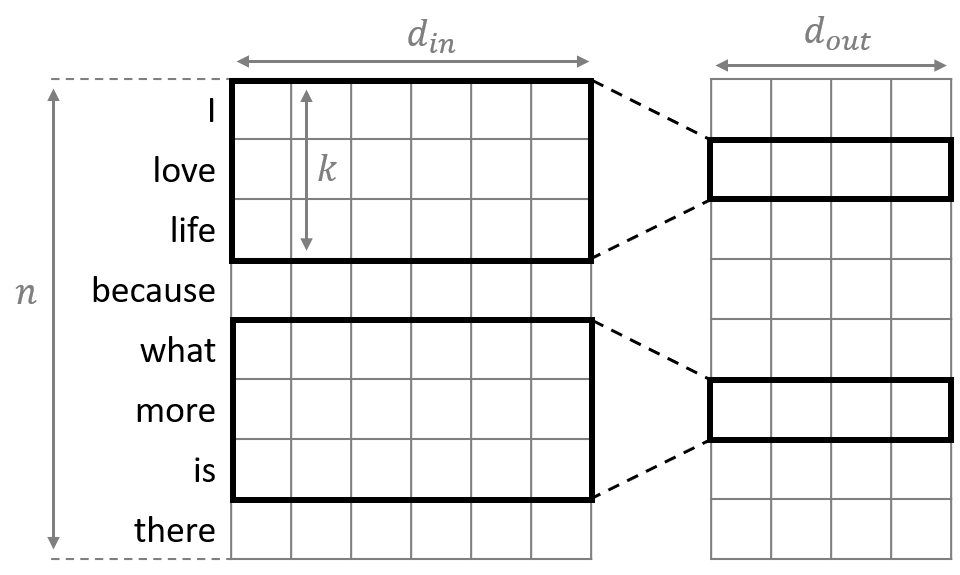
Standard one-dimensional convolution
“Convolutional Neural Networks for Sentence Classification”에서 콘볼루션 뉴럴 네트워크를 워드 벡터들에 적용하는 방법을 소개하고 있습니다. 일반적인 컨볼루션은 입력 벡터와 출력 벡터의 채널 수가 각각 $d_{in}$, $d_{out}$이고 커널의 너비가 $k$일 때, 총 $d_{in} \times d_{out} \times k$개의 파라매터가 필요합니다. 입력 시퀀스 $X \in \mathbb{R}^{n \times d_{in}}$와 커널의 가중치 $W \in \mathbb{R}^{d_{in} \times d_{out} \times k}$, bias 항 $b\in\mathbb{R}$가 주어졌을 때 컨볼루션 연산 결과 $Y \in \mathbb{R}^{n \times d_{out}}$는 다음과 같이 정의됩니다.
\[Y_{r,c}=\sum_{i=1}^{d_{in}} \sum_{j=1}^k {W_{i,c,j} \cdot X_{r+j-{\lceil { {k+1}\over 2}\rceil},c}} + b\]Depthwise 컨볼루션
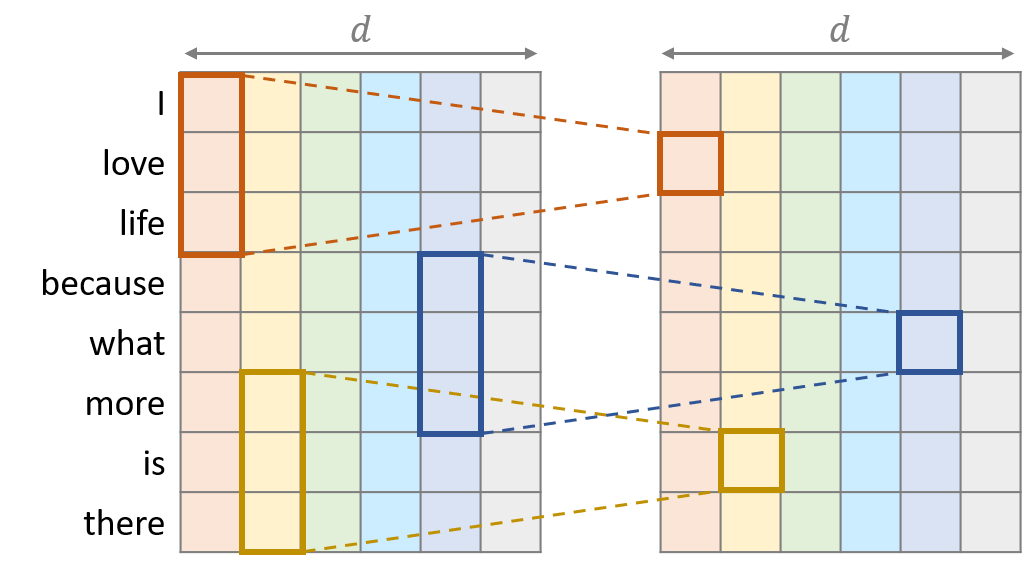
Depthwise convolution
Depthwise 컨볼루션은 “Xception: Deep Learning with Depthwise Separable Convolutions”에서 연산량을 줄이기 위해 소개된 컨볼루션으로 각 채널마다 일반 컨볼루션을 독립적으로 적용합니다. 컨볼루션이 같은 채널 내에서만 계산되어야 하므로 입력 시퀀스의 채널 수와 출력 시퀀스의 채널 수는 $d$로 일치하게 됩니다. 같은 입출력 시퀀스에 대해 일반 컨볼루션을 적용하기 위해서 $d^2k$개의 파라매터가 필요한 반면 Depthwise 컨볼루션은 더 적은 $dk$개의 파라매터를 사용합니다. 모든 커널의 가중치를 $W\in \mathbb{R}^{d\times k}$라고 할 때 컨볼루션 연산 결과 $O\in\mathbb{R}^{n \times d}$는 다음과 같이 정의됩니다.
\[O_{i,c}=\text{DepthwiseConv}(X,W_{c,:},i,c)=\sum_{j=1}^k {W_{c,j} \cdot X_{(i+j)-\lceil { {k+1}\over 2}\rceil,c}}\]Lightweight 컨볼루션
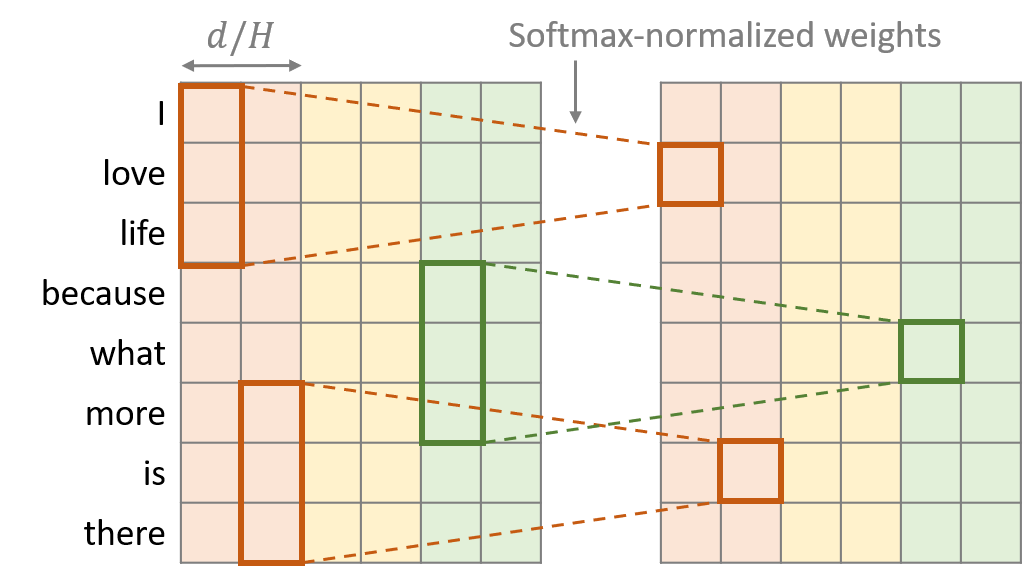
Lightweight convolution
Lightweight 컨볼루션은 depthwise 컨볼루션과 비슷한 구조를 가졌지만 두 가지의 특징이 추가되었습니다. 첫 번째는 연속된 $d/H$개의 채널마다 커널의 가중치를 공유했다는 점입니다. 가중치 공유를 통해 필요한 파라매터 수는 $dk$개에서 $dH$개로 줄어듭니다. 그림에서는 d=6, H=3이기 때문에 (1,2), (3,4), (5,6) 각각의 채널 쌍에 대해 컨볼루션의 가중치가 서로 공유됩니다. 두 번째는 가중치를 타임 스탭방향으로 softmax-normalization을 했다는 점입니다. 가중치 $W\in\mathbb{R}^{H\times k}$가 주어졌을 때, Softmax-normalization과 lightweight 컨볼루션은 다음과 같이 정의됩니다.
\[\text{LightConv}(X,W_{\lceil {cH\over d} \rceil,:},i,c)=\text{DepthwiseConv}(X,\text{softmax}(W_{\lceil {cH\over d} \rceil,:}),i,c)\]where \(\text{softmax}(W)_{h,j}={\exp W_{h,j} \over {\sum_{j'=1}^k \exp W_{h,j'}}}\)
Dynamic 컨볼루션
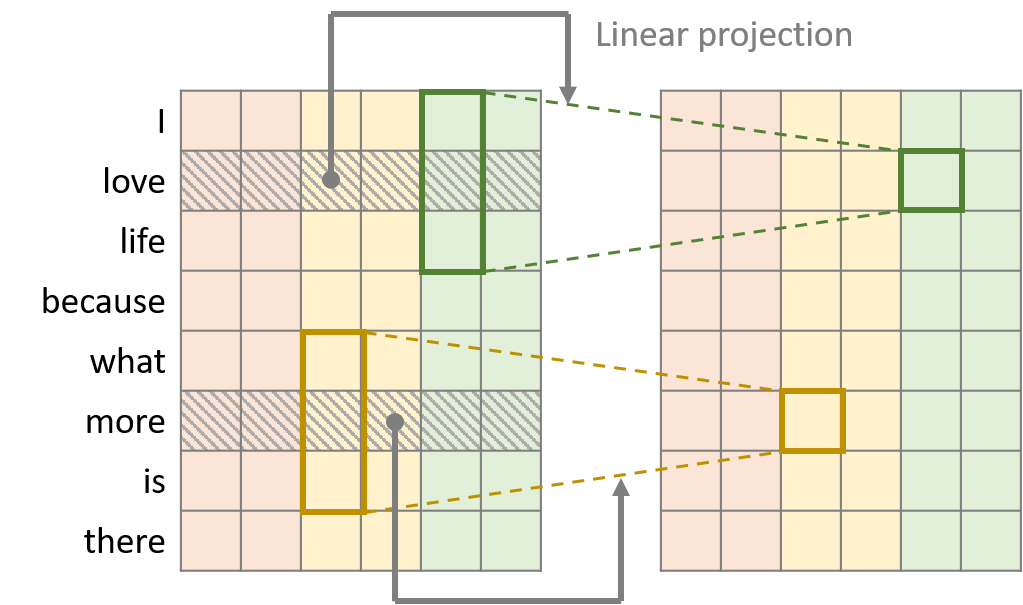
Dynamic convolution
Dynamic 컨볼루션은 Lightweight 컨볼루션에서 커널을 타임 스탭에 의존하게 만든 컨볼루션입니다. 이 때, 커널 중앙에 위치한 워드 벡터를 선형 모듈을 통해 커널의 가중치를 형성합니다. 예를 들어, 그림에서는 초록색 커널의 중앙에 love라는 단어가 위치해 있기 때문에 love의 워드 벡터를 가지고 커널의 가중치를 생성한 뒤, lightweight 컨볼루션과 같은 연산을 수행하게 됩니다. 선형 모듈의 가중치가 $W^Q \in \mathbb{R}^{H \times k \times d}$일 때, Dynamic 컨볼루션은 다음과 같이 정의됩니다.
\[\text{DynamicConv}(X,i,c)=\text{LightConv}(X,f(X_i)_{h,:},i,c)\]where $f(X_i)=\sum_{c=1}^d W^Q_{h,j,c}X_{i,c}$
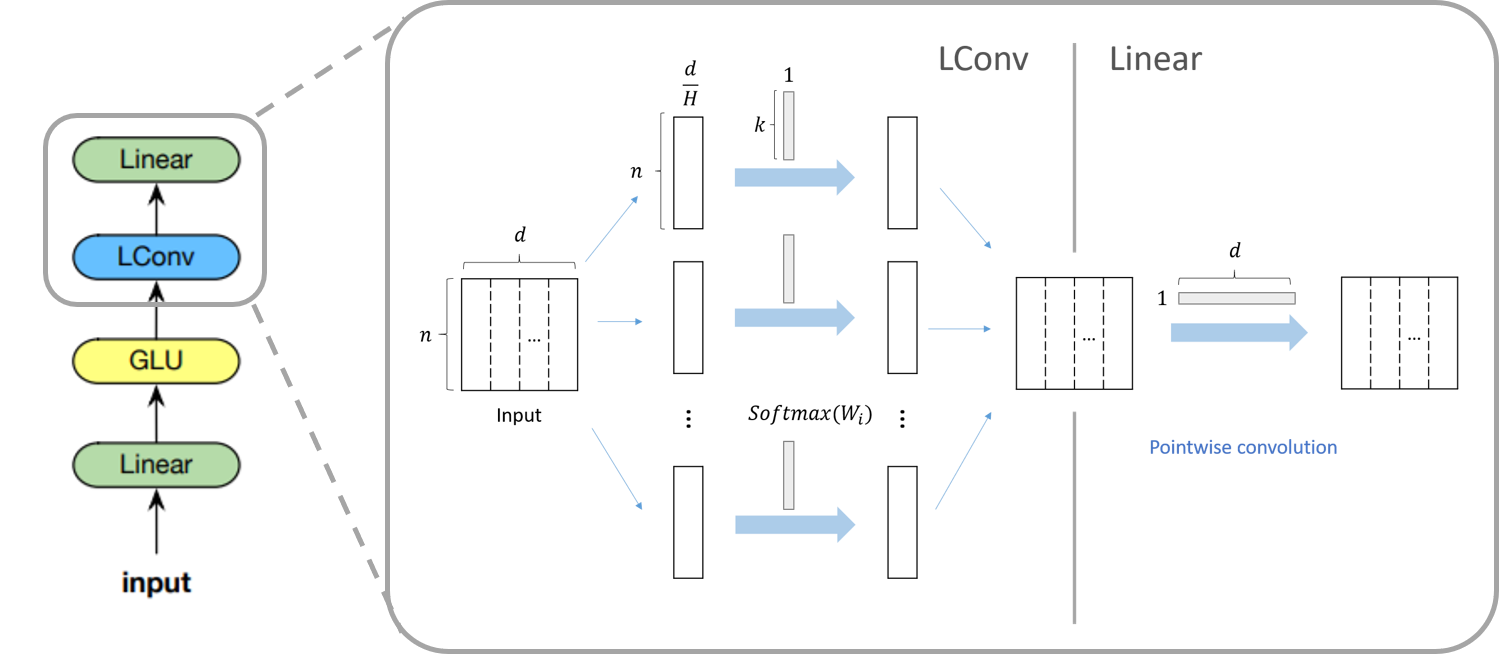
Lightweight, dynamic 모듈
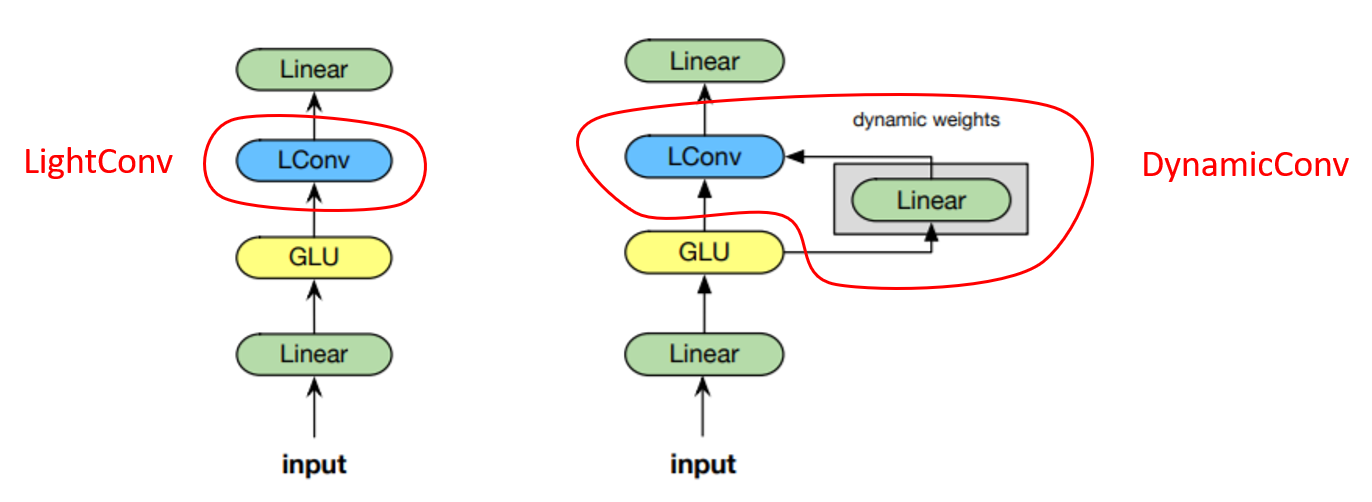
lightweight 컨볼루션 모듈(왼쪽)과 dynamic 컨볼루션 모듈(오른쪽)
저자는 셀프 어텐션을 대체하기 위해 앞에서 설명한 Lightweight 컨볼루션 혹은 Dynamic 컨볼루션을 포함하여 모듈을 구성하였습니다. 왼쪽 그림은 lightweight 컨볼루션을 포함한 모듈의 구조를 나타냅니다. 먼저, 입력 시퀀스가 들어오면 선형 모듈로 차원을 $d$에서 $2d$로 늘려준 뒤, GLU 활성 함수, LightConv와 선형 모듈을 차례대로 적용합니다. 오른쪽 그림은 dynamic 컨볼루션을 포함한 모듈의 구조를 나타냅니다. 오른쪽 모듈은 왼쪽 모듈에서 LightConv 대신 DynamicConv를 사용했다는 점 이외에는 모두 동일한 구조를 갖고 있습니다.
GLU 활성 함수
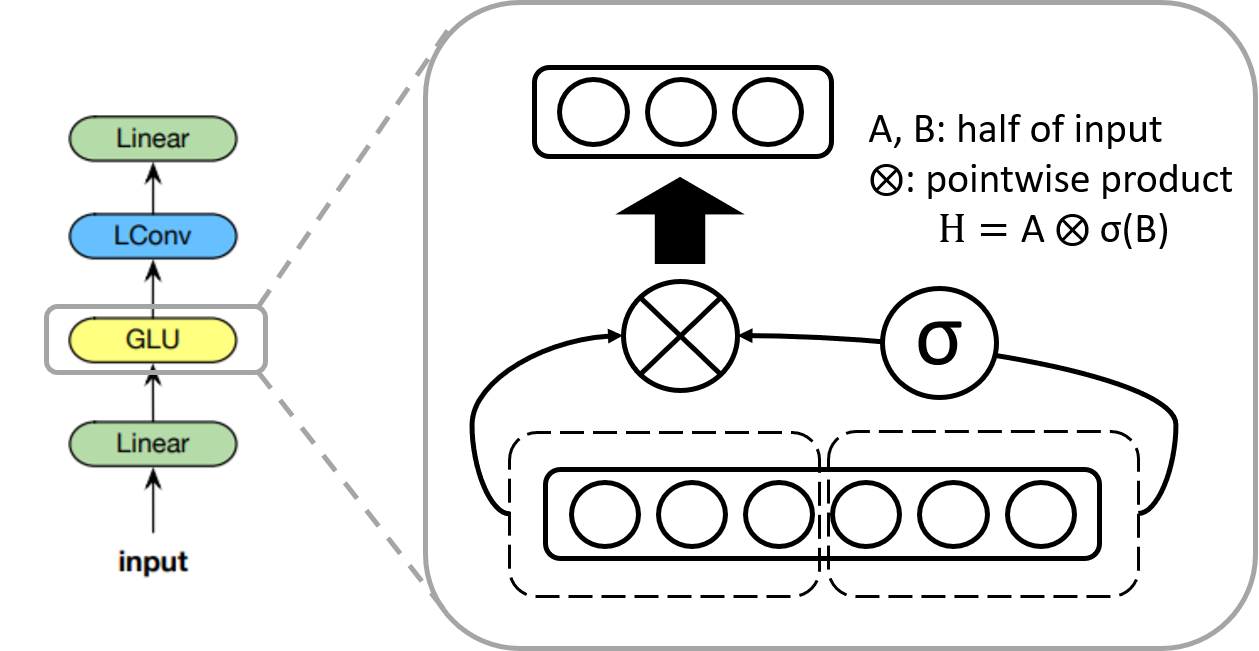
GLU activation
GLU(gated linear unit) 활성 함수는 “Language Modeling with Gated Convolutional Networks”에서 소개된 활성 함수입니다. 이 함수는 입력의 절반에 시그모이드 함수를 취한 것과 나머지 입력의 절반을 가지고 pointwise 곱을 계산합니다. 따라서 출력 값의 차원은 입력 값의 차원의 절반이 됩니다. GLU는 비선형 기능을 유지하면서 선형 연산을 통해 vanishing gradient 문제를 완화합니다.
Depthwise separable 구조
Depthwise separable 구조
저자는 lightweight 컨볼루션이 depthwise separable하다고 언급했습니다. Depthwise separable 컨볼루션은 depthwise 컨볼루션과 pointwise 컨볼루션을 같이 사용하는 연산을 가리킵니다. Xception에서는 기존의 컨볼루션을 이렇게 두 연산으로 나누면 더 적은 연산과 파라매터를 사용함에도 불구하고 좋은 성능을 낼 수 있음을 보였습니다. Payless attention 논문에서는 어떤 부분이 depthwise separable한지 명확히 나오지 않았지만 모듈의 마지막 두 층의 구조를 가리킨 것으로 보입니다. 실제로 LConv에 해당하는 부분은 depthwise 컨볼루션과 유사한 형태를 띄고 있고 그 뒤에 따라오는 선형 모듈은 pointwise 컨볼루션으로 생각할 수 있습니다. 결과적으로 이 구조는 효율적으로 컨볼루션 연산을 수행할 수 있게 합니다.
모델 아키텍쳐
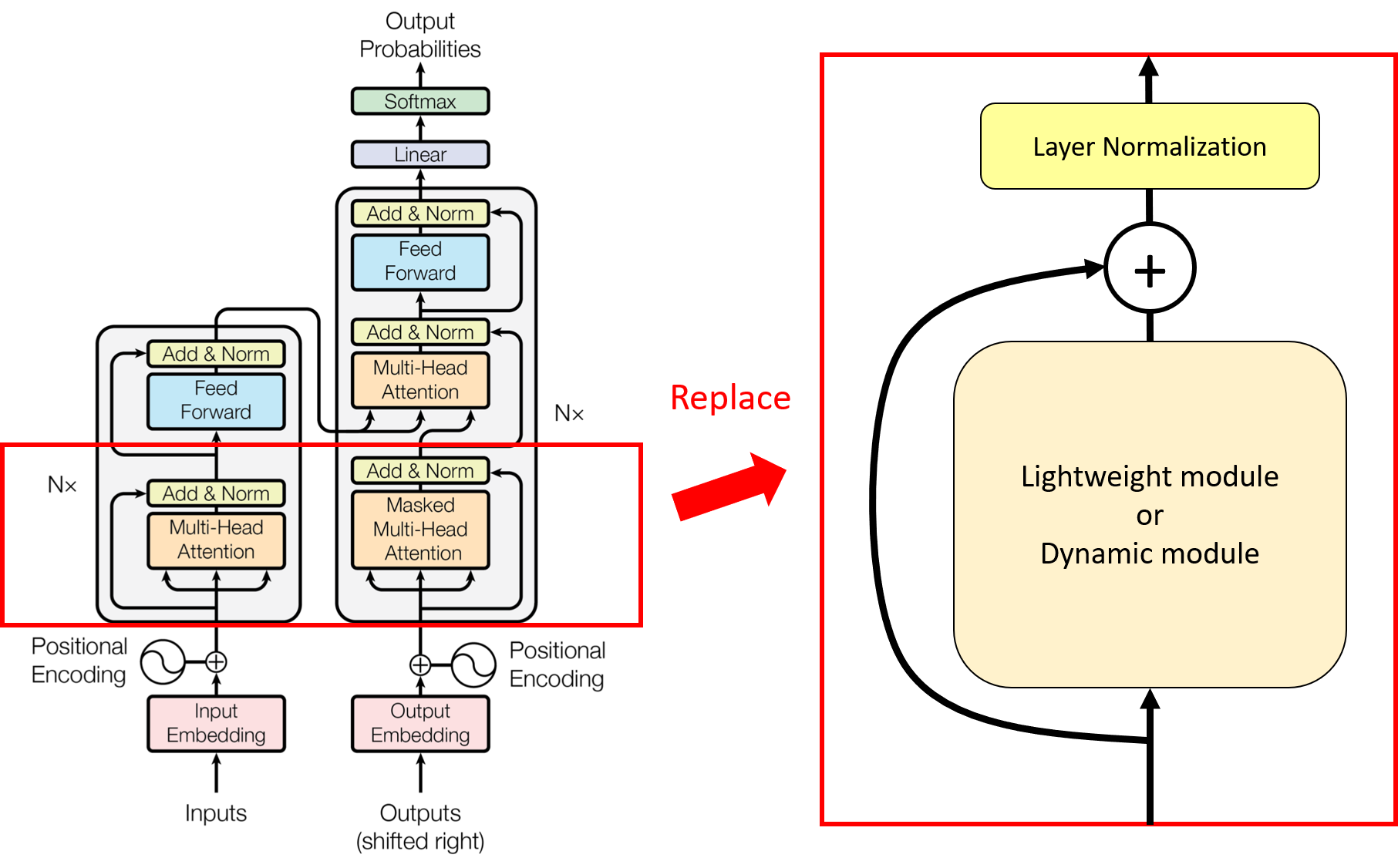
제시된 인코더-디코더 모델
저자는 트랜스포머 아키텍쳐와 유사한 형태로 자신의 모델 아키텍쳐를 구현하였습니다. 셀프 어텐션 베이스라인으로 fairseq에서 재구현한 트랜스포머 아키텍쳐를 사용하고 셀프 어텐션 부분을 lightweight, dynamic 모듈로 바꿔서 제시한 모듈 성능을 테스트하였습니다.
실험 및 결과
저자는 기계 번역(machine translation), 언어 모델링(language modeling), 요약(summarization) 테스크를 수행했습니다. lightweight 컨볼루션과 dynamic 컨볼루션은 다양한 테스크에서 셀프 어텐션 베이스라인보다 좋은 성능을 보여주었습니다. 특히, Dynamic 컨볼루션의 WMT’14 영어-독일어 데이터 셋에서 기계 번역 모델 점수는 29.7 BLEU로 높은 성능을 보여주었습니다. 비록 현재 이 성능은 SOTA가 아니지만 지금까지도 많은 모델이 트랜스포머 모델 기반으로 구현되는 것을 보면 저자의 접근이 흥미로운 면이 있습니다.
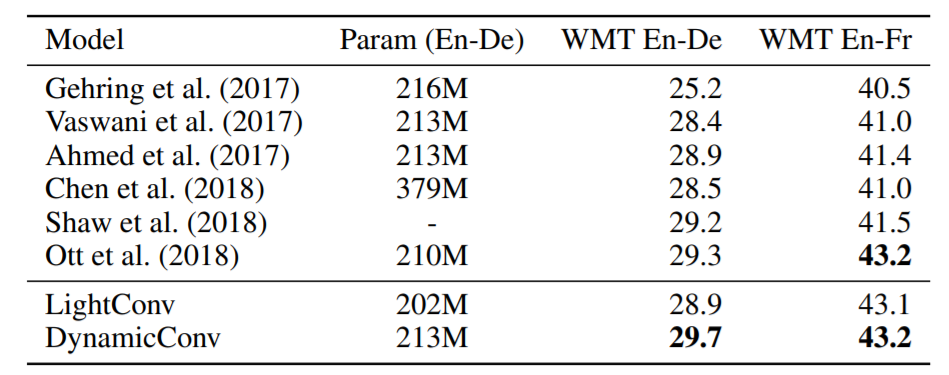
Machine translation accuracy in terms of BLEU for WMT En-De and WMT En-Fr on newstest2014.

Language modeling results on the Google Billion Word test set.
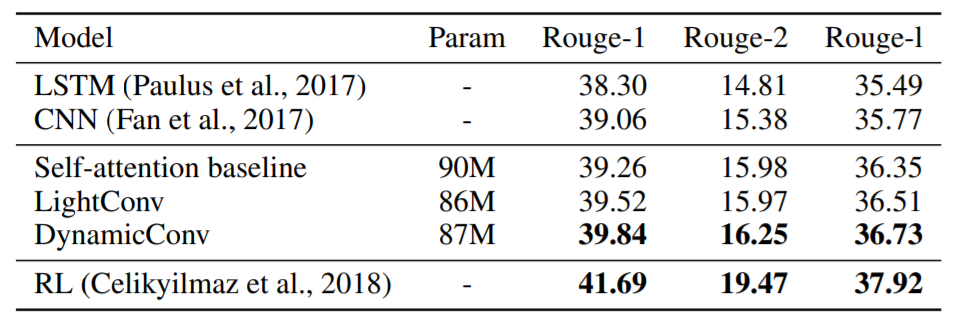
Results on CNN-DailyMail summarization. We compare to likelihood trained approaches except for Celikyilmaz et al. (2018).
개인적인 실험
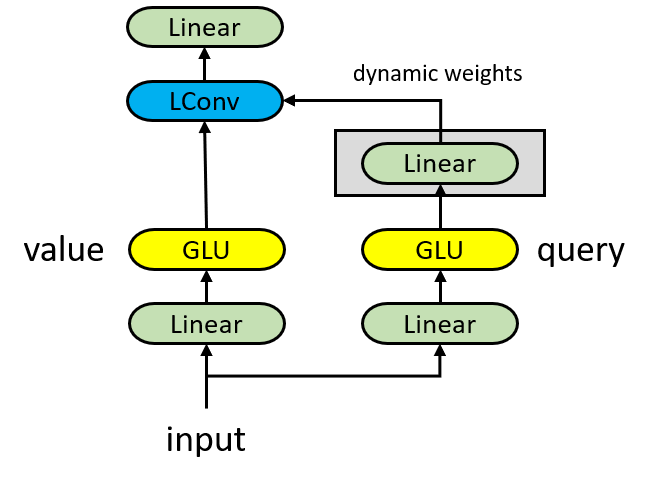
수정한 Dynamic 모듈
Dynamic 컨볼루션은 lightweight 컨볼루션에 비해 커널에 필요한 파라매터 수가 입력 벡터의 차원배수 만큼 더 많이 필요합니다. Dynamic 컨볼루션의 커널이 타입 스탭에 의존하게 만들기 위해 너무 많은 파라매터를 쓰는 것 같아서 이를 조절할 수 있도록 위 그림과 같이 value, query 벡터 프로젝션을 나눠보는 실험을 해보았습니다. 이렇게 나누면 입력 벡터를 커널의 가중치로 바로 프로젝션하기 전에 차원을 줄일 수 있습니다. query 벡터의 차원을 1에 가깝게 줄이면 lightweight 컨볼루션과 비슷하게 되고 늘려서 value 벡터의 차원에 도달하면 dynamic 컨볼루션과 비슷하게 될 것으로 예상합니다.
기존 Dynamic 모듈을 사용한 베이스 모델은 IWSLT’14 German-English(De-En) 기계 번역 모델로 잡았습니다. (https://github.com/pytorch/fairseq/blob/master/examples/pay_less_attention_paper/README.md)
수정한 dynamic 모듈을 사용한 모델은 베이스 모델에서 value 벡터의 차원을 512, query 벡터의 차원을 256으로 놓은 것을 제외하고 모두 같은 값의 하이퍼파라매터로 구성하였습니다. 저자가 IWSLT14 De-En 데이터 셋에서 실험할 때 모델에 GLU 활성 함수를 사용하지 않았기 때문에 수정한 모델에서도 GLU 활성 함수를 사용하지 않았습니다. (수정한 모듈 - https://github.com/choyi0521/fairseq/tree/dev6)
수정한 모델의 학습 및 평가 설정(IPython)
# Training
!mkdir -p "{SAVE}"
!CUDA_VISIBLE_DEVICES=0 $(which fairseq-train) data-bin/iwslt14.tokenized.de-en \
--encoder-conv-type ddynamic --decoder-conv-type ddynamic \
--clip-norm 0 --optimizer adam --lr 0.0005 \
--source-lang de --target-lang en --max-tokens 4000 --no-progress-bar \
--log-interval 100 --min-lr '1e-09' --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--lr-scheduler inverse_sqrt \
--ddp-backend=no_c10d \
--max-update 80000 --warmup-updates 4000 --warmup-init-lr '1e-07' \
--adam-betas '(0.9, 0.98)' \
-a lightconv_iwslt_de_en --save-dir "{SAVE}" \
--dropout 0.3 --attention-dropout 0.1 --weight-dropout 0.1 \
--encoder-glu 0 --decoder-glu 0 \
--encoder-gau 0 --decoder-gau 0 \
--conv-mixed 0 \
--encoder-conv-dim 512 --decoder-conv-dim 512 \
--encoder-query-dim 256 --decoder-query-dim 256 \
--encoder-attention-heads 4 --decoder-attention-heads 4 \
--encoder-attention-query-heads 1 --decoder-attention-query-heads 1 \
2>&1 | tee "{SAVE}/train.log"
# Evaluation
!CUDA_VISIBLE_DEVICES=0 fairseq-generate data-bin/iwslt14.tokenized.de-en --path "{SAVE}/checkpoint_last10_avg.pt" --batch-size 128 --beam 4 --remove-bpe --lenpen 1 --gen-subset test --quiet
수정한 모델 성능
Namespace(beam=4, bpe=None, cpu=False, criterion='cross_entropy', data='data-bin/iwslt14.tokenized.de-en', dataset_impl=None, decoding_format=None, diverse_beam_groups=-1, diverse_beam_strength=0.5, empty_cache_freq=0, force_anneal=None, fp16=False, fp16_init_scale=128, fp16_scale_tolerance=0.0, fp16_scale_window=None, gen_subset='test', iter_decode_eos_penalty=0.0, iter_decode_force_max_iter=False, iter_decode_max_iter=10, lazy_load=False, left_pad_source='True', left_pad_target='False', lenpen=1.0, load_alignments=False, log_format=None, log_interval=1000, lr_scheduler='fixed', lr_shrink=0.1, match_source_len=False, max_len_a=0, max_len_b=200, max_sentences=128, max_source_positions=1024, max_target_positions=1024, max_tokens=None, memory_efficient_fp16=False, min_len=1, min_loss_scale=0.0001, model_overrides='{}', momentum=0.99, nbest=1, no_beamable_mm=False, no_early_stop=False, no_progress_bar=False, no_repeat_ngram_size=0, num_shards=1, num_workers=1, optimizer='nag', path='/content/gdrive/My Drive/colab/payless/save_base/dynamic_conv_iwslt/checkpoint_last10_avg.pt', prefix_size=0, print_alignment=False, print_step=False, quiet=True, raw_text=False, remove_bpe='@@ ', replace_unk=None, required_batch_size_multiple=8, results_path=None, sacrebleu=False, sampling=False, sampling_topk=-1, sampling_topp=-1.0, score_reference=False, seed=1, shard_id=0, skip_invalid_size_inputs_valid_test=False, source_lang=None, target_lang=None, task='translation', tbmf_wrapper=False, temperature=1.0, tensorboard_logdir='', threshold_loss_scale=None, tokenizer=None, unkpen=0, unnormalized=False, upsample_primary=1, user_dir=None, warmup_updates=0, weight_decay=0.0)
| [de] dictionary: 8848 types
| [en] dictionary: 6632 types
| loaded 6750 examples from: data-bin/iwslt14.tokenized.de-en/test.de-en.de
| loaded 6750 examples from: data-bin/iwslt14.tokenized.de-en/test.de-en.en
| data-bin/iwslt14.tokenized.de-en test de-en 6750 examples
| loading model(s) from /content/gdrive/My Drive/colab/payless/save_base/dynamic_conv_iwslt/checkpoint_last10_avg.pt
| Translated 6750 sentences (149022 tokens) in 74.4s (90.73 sentences/s, 2002.97 tokens/s)
| Generate test with beam=4: BLEU4 = 35.44, 69.4/43.9/29.8/20.7 (BP=0.958, ratio=0.958, syslen=125712, reflen=131161)
IWSLT14 De-En 데이터 셋에서 수정한 모델이 저자의 Dynamic 콘볼루션 모델 성능인 35.2 BLEU보다 높은 35.44 BLEU를 받았습니다. Query 벡터로 프로젝션하기 위해 추가적인 파라매터가 필요하고 약간의 하이퍼파라매터 튜닝을 요구하지만 성능차이를 고려하면 의미있는 수정으로 보입니다.
참고문헌
- Yoon Kim. 2014. Convolutional Neural Networks for Sentence Classification. EMNLP 2014.
- François Chollet. 2017. Xception: Deep Learning with Depthwise Separable Convolutions. CVPR 2017.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N, Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. NIPS 2017.
- Felix Wu, Angela Fan, Alexei Baevski, Yann Dauphin, and Michael Auli. 2019. Pay less attention with lightweight and dynamic convolutions. ICLR 2019.
- https://qiita.com/koreyou/items/328fa92a1d3a7e680376
- https://paperswithcode.com/sota/machine-translation-on-wmt2014-english-german