SAGE: Saliency-Guided Mixup with Optimal Rearrangements
SAGE: Saliency-Guided Mixup with Optimal Rearrangements
Mixed Sample Data Augmentation, MSDA는 vision task에서 사용하는 데이터를 증강하기 위해서 사용되는 기법입니다. 이를 위한 수많은 접근 방법이 나왔으며, Mixup을 필두로 해당 기법이 성능 개선에 큰 효과가 있다는 것이 알려지고, 최근에 왜 이러한 MSDA 방법론들이 실제 성능 향상에 영향을 주는지를 loss function perspective로 설명하는 A Unified Analysis of Mixed Sample Data Augmentation: A Loss Function Perspective이란 논문이 나오면서 더욱 다양한 관점과 방법론으로 연구되고 있습니다.
물론 아직 MSDA 방식이 정말로 효율적인 것인지에 대해 이야기되고 있기는 합니다. 여러가지 task 문제 상황에 따라서도 효과를 보지 못하는 경우도 있고, fine grained인지 coarse grained 인지에 따라서도 사용하는 기법의 종류가 달라지기도 하는 등, 검증과 방법론의 경우는 많은 연구가 더 필요한 상황입니다.
그럼에도 불구하고, 아직도 data augmentation의 경우 모델의 성능을 높이는 굉장히 쉬운 접근방법이며, 많은 경우에 효과를 보고있기 때문에 vision task을 연구하거나 실제 사용하는 사람들이라면 높은 관심을 가지고 있습니다.
이번에 소개할 논문 SAGE: Saliency-Guided Mixup with Optimal Rearrangements 는 BMVC 2022에 accept된 논문으로, 이전에 소개해드린 SalienyMix와 비슷하게 saliency를 base로 사용하는 mixup 기법입니다. 굉장히 단순한 아이디어를 사용하는데, 사람이 쉽게 눈으로 확인을 했을 때에도 어렵지 않게 성능의 개선이 있을 것이라는 점을 납득할 수 있다는 점과, 이러한 간단한 방법으로 Co-Mixup보다 더 좋은 성능을 내는 것과 동시에 더 빠르다는 장점을 가지고 있어서 소개하려합니다.
물론, 사람의 눈과 인지에서 make sense하다는 것이 곧바로 실제 모델에 적용했을 때에 항상 성능의 개선을 나타낸다는 뜻은 아니지만, 결과적으로도 성능의 향상이 있었고 특히 SOTA를 이야기할 때에 가장 많이 거론되는 Co-mixup에 견준다는 점이 확실히 한 번 봐도 좋을 논문이라고 생각합니다.
그러나 제가 전에 이야기했듯, 많은 종류의 논문들이 특정 환경설정과 몇 번의 시도들에서만 성능이 좋게 나오고, 다른 조건들에서도 같은 성능이 유지되리라는 보장이 없을 수 있습니다. 이에 따라서 실제로 SAGE를 사용해보시려면, 실제 task에서 이를 사용했을 때에 성능 개선이 있는지를 검증하시는 것이 필요할 것 같습니다.
Abstract
본 논문에서도 데이터 증강이 모델이 훈련하는 과정에서, 더 많은 종류의 train 이미지들을 제공함으로써 train 데이터에만 과적합하는 경우를 줄이고 일반화를 개선한다는 것을 명시하고 있습니다. 최근에는 데이터 증강을 구현하는 과정에서 기하적 변환 뿐만 아니라, 시각적 돌출성 등 다양한 정보나 방법들을 사용하여 새로운 데이터를 만드는 복잡한 방법들까지 제시되고 있습니다. 이러한 복잡한 데이터 증강 방법론들은 실제 더 좋은 train dataset을 만들어 모델의 성능을 개선하는 역할을 하지만, 이러한 data를 만들기 위해 더욱 많은 자원을 사용하여 비효율적이게 되는 것과 동시에, 몇몇 방법들은 특정 도메인에만 적용가능하여 일반화가 떨어진다는 점을 지적합니다. 이러한 문제점을 해결하기 위해, 단순하고 복잡도 상으로 효율적인, 일반화 가능하면서 높은 성능을 보이는 새로운 데이터 증강 기법이 필요하고 저자들이 SAGE를 개발하게 됩니다.
SAGE는 고전적인(물론, 현재를 기준으로) Saliency를 base로 사용하여 이미지 쌍을 혼합하는 과정에서, foreground에 해당하는 object들 위주로 잘 사용하여 train 과정에서 사용할 새로운 이미지를 만들어냅니다. 그리고 이러한 SAGE가 여러가지 MSDA들보다 benchmark 데이터 세트에서 더욱 정확하고, 꽤나 빠르게 동작한다는 것이 SAGE의 contribution으로 두고 있습니다.
결국, MSDA를 위한 접근 방법 자체는 제가 기존에 다루었던 Saliency-based MSDA와 크게 다르지 않습니다. 그러나 어떠한 디테일이 기존 방법론들과 SAGE의 차이를 두었는지 살펴보도록 하겠습니다.
Method
Comparision of DA methods

일단 SAGE가 어떻게 동작하는지 확인하기에 앞서, 위 Figure 1을 보면서 다른 논문들이 어떤 식으로 MSDA를 진행하는지, 그리고 어떤 차이점들이 존재하는지 이야기해보도록 하겠습니다.
위에 다음과 같이 3개의 batch image들이 주어져있다고 생각해보겠습니다.
이 때, Mixup의 경우에는 두 개의 이미지들을 모두 pixel-wise하게 특정값 lambda의 비율로 섞어주게 됩니다. 이 때에 해당하는 lambda는 gamma function을 통해 정해지게 되며, 이러한 비율로 두 이미지를 섞어서 두 이미지의 형태가 모두 흐릿하게 남아있게 됩니다. 그러나 이 과정에서 두 이미지 모두의 object가 blur해진다는 단점이 있었습니다.
CutMix의 경우, 두 이미지의 random한 영역을 선택하여, 해당 영역은 A로, 다른 영역은 B로 채우는 식으로 두 이미지를 섞게 됩니다. 그리고 나서 두 이미지의 label은 영역의 크기에 비례하여 두 이미지가 나눠 갖게 됩니다. 이 과정에서 두 이미지 모두 blur하지 않은 상태로 이미지 mixing이 이루어진다는 장점이 있습니다. 그러나 여기에서 영역을 선택하는 과정이 random이기 때문에, 실제로 object가 존재하지 않은 영역도 mixing되는 경우가 발생할 수도 있습니다.
SaliencyMix의 경우, CutMix에서 object가 존재하지 않는 영역이 mixing되는 경우를 방지하기 위해, target image에서 saliency map을 통해 가장 큰 값을 가지는 위치에서 image cutting을 진행합니다. 이는 saliency map에서 가장 큰 값을 가지는 곳은 object일 것이라는 가정이 들어가게 됩니다. 이를 통해 합성된 이미지에서 두 이미지의 object가 모두 존재하게 만들려는 시도를 합니다.
PuzzleMix에서는 Saliency를 사용하여 object를 살리는 것과 동시에, map을 기존처럼 사각형으로 자르는 것 뿐만 아니라, 다양하게 나누어 필요없는 영역은 skip하고, 필요한 영역은 mixing하는 방식으로 진행됩니다. 두 이미지를 섞는 과정에서, source image에 덮어씌우는 영역이 해당 이미지에서 중요한 영역이라면, 정보의 손실이 일어나기 때문에, object를 살리기 위해서 target 이미지를 다른 곳으로 옮기거나 mixing 방법에 따라서 작은 픽셀 단위로도 섞고 saliency를 살리는 더 복잡한 방식으로 동작합니다.
위에 설명한 논문들의 경우, 모두 2개의 이미지에 대해서만 섞는 것이 가능했으나, Co-Mixup의 경우 3개 이상의 이미지 또한 섞는 것이 가능합니다. 동작 원리는 PuzzleMix와 비슷하게, 최대한 섞는 이미지들의 object 영역을 살리는 것이 목적이며, 이를 위해서 Saliency Map을 사용하여 생성된 이미지의 전체 saliency measure를 maximize하는 방법을 목표로 하여 섞게 됩니다.
여기까지, SAGE를 보기 이전에 위 방법론들에 대해 먼저 이야기하고 가보겠습니다. SaliencyMix까지는 기존의 방법들을 개선하는 것이지만, 실제 이미지로 확인했을 때에도, 그리고 기법 자체로 볼 때에도 확실히 생성된 이미지가 어색하거나 reasonable하지 않을 수 있다는 것을 알 수 있습니다. 그러나 이러한 방법론들은 단순히 saliency map을 만드는 과정 + target mask를 사용하여 섞는 방법이기 때문에 굉장히 빠르게 동작합니다.
그러나 puzzlemix나 co-mixup의 경우, saliency based method를 쓰기는 하지만, 그 이후에 어떻게 섞을 것이냐에도 굉장한 중점을 두어, 실제 동작 과정에서 시간 소요가 훨씬 걸리는 편입니다. 이러한 일장일단이 있기 때문에 어떠한 기법이 훨씬 나은 방법이라고 논하기는 어려운 부분이 있습니다. (정확도, 시간)
이 때에, SAGE를 보도록 하겠습니다.
SAGE의 경우 해당 method를 써서 하고자하는 목적은 결국 두 이미지의 mixing을 하는 과정에서 object가 모두 살아있도록 하면서 섞는 방법이 없을지에 대해 고려한 결과임을 알아볼 수 있습니다. 생성된 이미지의 경우, 두 강아지 객체가 모두 한 이미지 내에 잘 섞여있고, 그 과정에서 mixup보다 적은 blurry를 가지면서 다른 이미지들보다 더 많은 saliency area들을 가지고 있음을 쉽게 확인할 수 있습니다.
실제 SAGE의 방법론을 보게 되면, 위와 같은 형태의 이미지를 얻기 위해서 우리가 어떠한 방향의 생각을 해보아야하는지에 대한 과정을 명확하게 이해할 수 있습니다.
Approach

위 figure 2에서 볼 수 있듯, SAGE는 3가지 독립적인 컴포넌트로 구성되어 있습니다.
첫 번째로는 주어진 original input image에서 saliency map을 추출합니다. 이 과정은 기존의 여러가지 saliency based MSDA들에서 사용했던 것들과 마찬가지로, pretrained된 neural network를 사용하여 추출하게 됩니다. pretrained model을 사용하여 추출한 saliency map의 경우, classification에 유용한 foreground object에 초점을 맞춘다는 것이 알려져 있습니다. SaliencyMix나 Puzzle, Co-mixup과 같이, 이러한 saliency map을 사용하여 foreground object의 saliency area를 최대화하려는 노력을 SAGE도 합니다.
두 번째로는 이러한 Saliency Map을 사용하여 Saliency-guided Mixup을 진행합니다. 기존에도 이를 사용한 mixup 기법들은 굉장히 많았습니다. Mixup의 경우, 두 이미지를 선형으로 섞는 방식을 사용하였고, SaliencyMix는 maximum point를 통해 cutmix를 진행했습니다. 그러나 이러한 방식들에는 앞서 이야기했듯, 제대로 동작하지 않을 수 있는 명백한 약점들이 존재합니다. 그래서 SAGE에서는 이러한 방식들의 단점을 극복할 수 있는, 새로운 Saliency-guided Mixup을 제안합니다. 그 방법은 다음과 같습니다.
SAGE에서는 모든 이미지들의 모든 픽셀들의 mixing ratio가 Saliency Map에 다르게 책정됩니다.
예를 들어, 두 이미지가 x1, x2가 주어지고, 각 이미지의 saliency map을 s1, s2라고 하겠습니다. 이 때, 우리가 새롭게 두 이미지의 mixing mask M을 만든다고 하면, M은 다음과 같은 식을 통해서 만들어지게 됩니다.

즉, 두 이미지의 saliency map을 사용하는데, 이 과정에서 두 이미지의 saliency map들에 gaussian smoothed가 적용된 새로운 mask를 기반으로 두 이미지가 섞이게 됩니다. 결과적으로 이렇게 만들어지는 이미지는 결국, 어떠한 픽셀에 대해서, 해당 이미지의 saliency score가 적으면 그에 비례해서 만들어지는 이미지에도 해당 픽셀의 값은 적게 반영이 되고, 만약 해당 픽셀의 saliency score가 높으면 그만큼 더 높은 비율로 해당 pixel의 비율이 책정되는 식으로 pixel-wise하게 새롭게 mask가 생성된다는 것을 알 수 있습니다.

이렇게 만들어지는 mask를 쓰는 경우, 기존의 mixup처럼 섞이는 결과가 발생하기는 하나, saliency score를 기반으로 하기 때문에 두 이미지가 선형으로 섞이는 것이 아닌, 중요한 object가 살아있는 영역은 더 많이 남기게 되어 결국 blurry가 더 사라지는 결과를 낳을 수 있게 됩니다.
그러나 여기까지만의 approach에는 약간의 문제가 있을 수 있습니다. 예를 들어, 만약 두 object모두 saliency score가 굉장히 높다면 어떻게 될까요? 이러한 경우, 둘 다 반반씩 섞인 pixel 결과가 나오게 될 것입니다. 그러나 이러한 섞는 결과는 둘 모두 약할 때에도 거의 비슷하게 섞이게 될 수도 있습니다. 또한 어떠한 경우에는, 둘다 saliency score가 낮지만, 한 쪽이 유의미하게 비율적으로 더 크다면 해당 영역이 더 반영되는 등, 실제 saliency score를 제대로 반영하냐는 질문에 명확한 답을 하기 어려울 수 있습니다.
SAGE의 저자들은, 이러한 문제점을 해결하기 위해서 마지막 단계의 방법을 이야기합니다.
마지막으로는, 이렇게해서 새롭게 만들어지는 saliency-guided mask에서 실제 saliency 영역을 maximize하기 위해 optimal rearrangement를 찾는 것입니다.
앞선 두 번째 방법의 saliency-guided mixup의 경우, 실제 두 이미지의 pixel location은 그대로 유지한 상태로 섞는 방식이었습니다. 이러한 방식을 사용할 때의 단점은, 만약 두 이미지에서 object가 왼쪽에 몰려있다면, 왼쪽에 존재하는 두 object가 섞인 형태의 새 이미지가 생성된다는 것입니다. 그러나 만약 이렇게 object가 한 쪽에 몰려있는 경우라면, 우리가 잘 조정하여 두 object가 서로 다른 곳에 놓여있도록 만들어줄 수 있습니다.
SAGE는 이러한 점을 고려하여 새롭게 rearrangement를 진행합니다. 이를 위해서 결과적으로 생성되는 이미지에서, 최종 saliency score가 maximize하기 위한 shift process를 진행합니다. 그 과정은 다음과 같습니다.
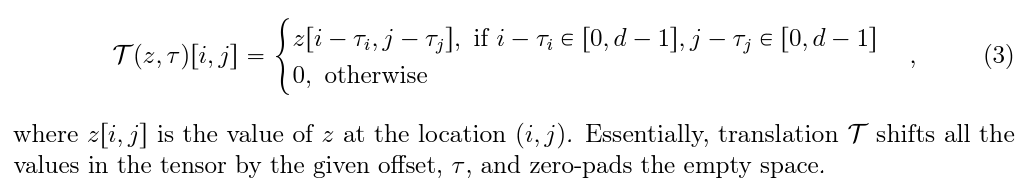
쉽게 이야기하자면, 결국 우리가 원하는 특정 tau에 대해서 모든 좌표들을 shift한 새로운 map을 return해주는 함수를 이야기합니다. 이러한 함수를 고려하여 앞선 saliency-guided mixup을 적용하면 다음과 같이 됩니다.
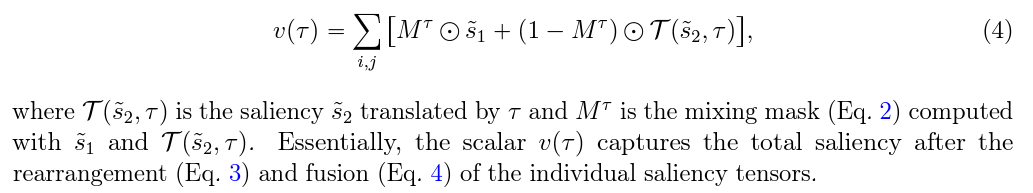
이렇게 새로 생긴 v의 경우, 특정 tau마다 얻게되는 saliency score의 합이 됩니다. 이러한 방식으로 섞는 결과는 figure 2에서 확인할 수 있는 이미지와 비슷하게 되며, 우리는 모든 가능한 shift들에 대해서 이러한 score가 maximize되는 tau를 찾아서 실제 이미지를 shift해주고 mixing한 output을 만들어내면 SAGE는 모두 끝나게 됩니다.

실제로 이러한 optimal rearrangement가 결과게 미치는 영향은 위 사진으로 쉽게 확인할 수 있습니다. 위 그림처럼, object 위치가 결과에 영향을 줄 수 있는 상황에서, rearrange shift를 사용하게 되면 최종적으로 만들어지는 saliency score mask의 sum이 훨씬더 커지는 것과 동시에, 결과적으로 생성되는 이미지에서 object가 굉장히 선명하게 잘 남아있다는 것을 알 수 있습니다.
Experiment
이제 실제 SAGE가 얼마나 효율적이고 좋은 성능을 보이는지 실험한 결과에 대해 이야기하겠습니다.
SAGE는 MSDA를 적용할 수 있는 task에 domain independent하게 모두 적용할 수 있습니다.
Image Classification
가장 먼저, benchmark dataset인 CIFAR-10과 CIFAR-100에서의 기본 성능을 확인할 수 있습니다. PreActResNet18과 WRNet16, ResNext29 모델을 사용하여 실험한 SAGE의 성능은 다음과 같습니다.
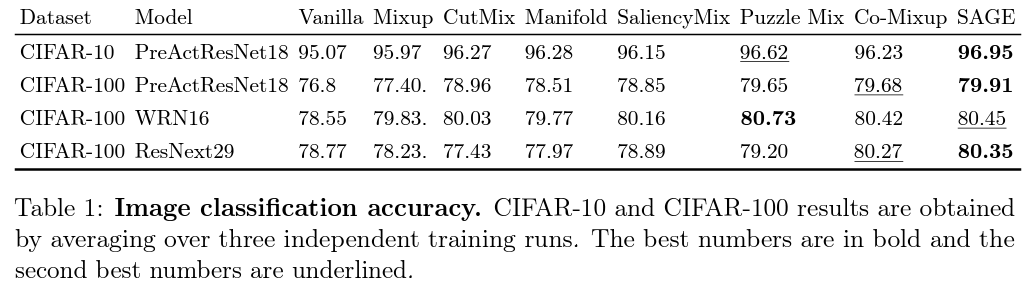
여기에서 확인할 수 있듯, 많은 경우에서 SAGE는 다른 MSDA 방법들과 비교해서 더 좋은 성능을 보인다는 것을 확인할 수 있습니다. 3번째 케이스의 경우, PuzzleMix에게 밀리는 결과를 보여주기는 했으나, PuzzleMix를 제외한 모든 방법들보다 더 나은 성능을 보이는 것을 확인할 수 있습니다.
Out-of-distribution Generalization and Few-shot Adaptation & Runtime Analysis
해당 task의 경우, 해당 기법이 얼마나 OOD에 일반화 성능을 갖는지와, 퓨샷 task에도 도움을 줄 수 있는지 실험합니다.
이를 확인하기 위해, 먼저 가우시안 노이즈와 adversarial perturbation이 적용된 test data에 대한 accuracy를 실험합니다. 또한, mini-Imagenet dataset에 대한 new categories few-shot adaptation을 적용한 결과에 성능을 체크합니다.
그리고 마지막으로, SAGE가 기존 MSDA에 비해 runtime적으로 얼마나 이득을 갖는지에 대해서도 분석합니다. 만약 실행 시간이 오래걸린다면 정확도가 높은 것은 큰 이점이 아닐수도 있습니다. 그러나 만약 정확도와 시간 모두 이점을 갖는다면 그것은 굉장히 큰 메리트를 갖게 됩니다.
자세한 세팅들은 모두 실제 논문에서 확인할 수 있으므로, 여기에서는 간단한 세팅에 대해 이야기하고 결과를 공유하겠습니다.
OOD task에 대해서는 CIFAR-100의 OOD benchmark case의 경우에서, 기존의 test accuracy와의 비교를 plot하였습니다. Few shot adaptation을 위해서는 새로운 categories를 위해 mini-ImageNet dataset을 사용합니다. Runtime을 위해서는 모든 기법을 single NVIDIA Tesla T4에서 학습시켜서 학습까지 걸리는 시간을 책정합니다.
그 비교 결과는 다음과 같습니다.

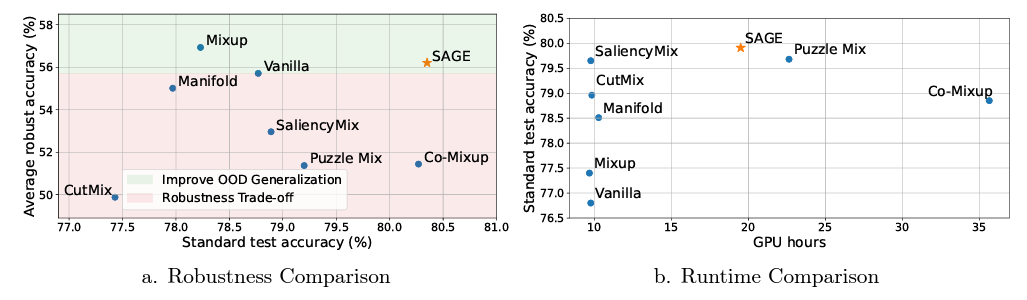
여기에서 확인할 수 있듯, SAGE의 경우, few-shot adaptation에서도 다른 기법들에 비해 높은 성능을 보이는 것을 확인할 수 있습니다. 또한, OOD task에 대해서도, SAGE는 mixup에 비해서는 낮은 robustness를 보이지만, 다른 기법들에 비해서는 robustness와 standard accuracy 모두 성능이 향상된다는 것을 알 수 있습니다.
그리고 runtime perspective에서도 saliency map만 단순히 사용하는 기법들에 비해서는 시간이 오래 걸리지만, 이후의 다른 방법론들이 들어가는 puzzlemix, co-mixup에 비해서는 SAGE의 runtime이 더 적다는 것을 확인할 수 있어서 빠르게 동작한다는 것을 알 수 있습니다.
그러나 여기에서 주의해야할 점이 있습니다.
제가 앞서 말씀드렸듯, 논문들은 다양한 상황과 조건에 따라서 그 결과가 바뀔 수 있습니다. 여기에서 우리가 한 번 짚고 넘어가야할 것은 바로 SAGE 논문에서 실험한 robustness comparision입니다. 많은 경우에, data augmentation의 높은 기여 중 하나로 robustness가 향상되어 adversarial attack등에 더욱 강력하다는 점을 강조하고 있습니다(e.g. SmoothMix). 허나, 해당 논문의 지표에서, 다양한 accuracy 비교에서 vanilla보다 robustness가 떨어진다는 점, cutmix의 경우 standard test acc도 떨어진다는 점에서 우리는 기존에 알고있던 내용과 상반되는 점들이 꽤나 있다는 것을 알 수 있습니다. 그렇기에, 해당 결과의 무조건적인 신뢰를 하기는 어렵습니다. 이것이 왜 제가 SAGE를 적용할 때에는 실제로 성능의 향상이 있는지 검증해야한다는 점과 연관이 있습니다. 사람이 생각할 때에는 굉장히 make sense하지만, 온전히 그것이 결과로 이어지지 않을 수 있으니까요.
이에 대해서는 확실한 검증이 필요하고, 논문을 읽어보시면서도 올바른지에 대해 꼭 검증할 필요가 있고 생각해봐야하는 부분이기에 이를 짚고 넘어가겠습니다.
그러나 일단 결론적으로는, SAGE는 해당 논문이 발표되기까지의 SOTA에 가까운 성능(다른 기법들을 모두 알고 있지 않아서, SOTA인지 확신은 어렵습니다)을 보이고, 쉽게 이해가 되고 접근 방법이 쉽다는 점에서 긍정적입니다.
Conclusion
결과적으로 우리는 Saliency-guided MSDA인 SAGE에 대해서 알아보았습니다. 기존의 mixup의 linear mixup에서, pixel-wise saliency-guided mixup을 하는 것을 통해서 object의 saliency area를 살리고, rearrangement optimization을 통해서 object 영역을 최대화하는 방법으로 꽤나 납득될만한 기법을 적용하여 좋은 성과를 보였다는 것에서 해당 논문을 한 번 즈음 읽어보고 적용해볼법하다고 생각합니다.
앞서 말씀드린 것처럼, 본인이 적용하고 싶어하는 task 상황에 맞추어 실험을 하여, 검증하는 단계가 끝나고 난다면 한 번 즈음 시도해봐도 좋을 것 같습니다.