문자열 해싱
hashing , string , rolling hash , rabin-karp
이번 글에선 해싱의 다양한 활용을 정리하고자 한다. 너무 기본적인 내용이나 필자도 모르는 너무 고급 기술은 다루지 않고, solved.ac 기준 다이아 중하위 수준까지의 문제를 해싱을 이용해 풀어보려는 사람들에게 적합하다. 해시값을 관리하는 몇가지 방법들을 소개하고, 마지막으로는 며칠 전에 출제된 따끈따끈한 문제인 ICPC 2023 Seoul Regional에 출제된 E번 문항을 해싱을 써서 해결하는 방법을 소개하며 글을 마무리한다.
해싱이란?
문자열 x[0] ~ x[l-1] 이 주어져있을 때, 소수 $p, M$을 사용하여 계산한 해시값 $(\sum_{i=0}^{l-1} x_ip^i) \text{ mod M}$ 을 비교하여 다른 문자열과 동일성을 판정하는 기법이다.
여기까지의 정의로는 $p$와 $M$이 꼭 소수일 필요는 없지만, 나중에 설명할 다양한 기법들까지 발전시키기 위해서라면, 그리고 저격데이터로 인해 틀릴 확률을 줄이기 위해서라면 $p$와 $M$이 소수여야만 한다.
해싱의 활용
문자열 매칭에 사용한다. 일일이 두 문자열의 동일성을 판정하려면 $O(l)$에 비례하는 시간복잡도가 필요하지만, 해시값이 미리 구해져 있다면 $O(1)$ 시간에 비교할 수 있다.
다들 알겠지만, 해싱도 치명적인 단점이 있다. 실제로는 다르지만 해시값이 같은 두 문자열을 저격 데이터로 만들 수 있고, 너무 흔한 $p$와 $M$쌍을 사용하면 저격당할 수 있다. 특히 코드 hack이 가능한 코포라면 당신이 쓴 $p, M$쌍에 알맞는 저격데이터를 생성할 수도 있으므로 더 위험하다. 하지만 미리 채점 데이터가 확정되어 있다면 $p, M$을 적당히 바꿔보고 더블 해싱까지 사용하면 웬만해서는 틀리기 힘들다. 해싱을 9중으로 해도 해킹 데이터를 만들 수 있음을 보이는 문제가 있지만, 이 문제는 모듈러 값인 $M$을 변경하지 않아서 가능한 것이다. $p, M$을 동시에 바꾼다면 더블 해싱만으로도 아주아주 안전할 것이다. 그래도 틀리면 $p, M$을 맞을때까지 수정하면 된다.
물론 대회에서 나온 문자열 문제에서 해싱이 정해인 경우는 거의 없다. 보통 사용되는 알고리즘으로는 kmp, 아호 코라식, suffix array 같은 좋은 방법들이 있지만, 고난이도의 문제라면 이 알고리즘들을 알고 있더라도 문제 풀이가 바로 나오지 않는 경우가 많다. 그리고 대회에선 이러한 고민에 시간을 쓰는 것 조차 큰 손해인 경우가 많고, 해싱을 쓰면 크게 머리를 쓰지 않고 문제가 풀리는 경우가 있다. 따라서 해싱을 적당히 알아두면 좋다.
해시값 관리
해싱으로 시간적인 이득을 보려면 주어진 문자열 s[0] ~ s[n-1]에서 s[l] ~ s[r] 의 해시값을 빠르게 구하는 것이 중요하다. 상황에 따라 다양한 전략이 가능하다.
해시값을 정의하는 방법은 크게 두 가지 방법이 있는데,
\[(\sum_{i=0}^{l-1} x_ip^i) \text{ mod M}\]이렇게 정방향 순서와,
\[(\sum_{i=0}^{l-1} x_ip^{l-1-i}) \text{ mod M}\]이렇게 역방향으로 계산하는 해싱이 있다 있다. 롤링 해싱을 [0] -> [l-1] 순서로 진행하는 경우엔 역순으로 하는 해싱이 모듈러 역원을 사용하지 않아서 조금 더 간단하지만, 큰 차이는 없다. 따라서 이번 글에서는 $(\sum_{i=0}^{l-1} x_ip^i) \text{ mod M}$ 이렇게 계산하는 정방향 해싱을 기준으로 설명하도록 하겠다.
1. $r-l$ 이 일정한 경우: rolling hashing
라빈 카프 알고리즘에서 사용하는 제일 기본적인 해싱 기법이 롤링 해싱이다. 길이 r-l인 문자열을 밀면서 해시값을 구한다.
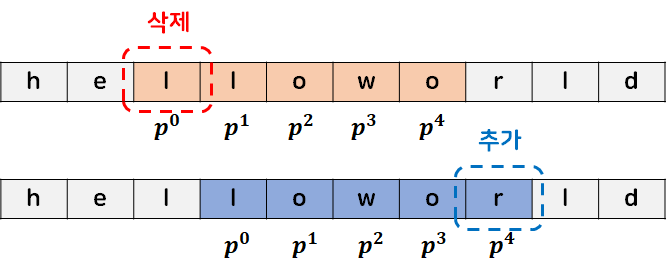
부분문자열의 길이 $k = r-l+1$로 정의하고, i를 0부터 n-1까지 밀면서 s[i-k+1] ~ s[i]의 해시값을 구하려는 상황을 가정하자. 이전의 해시값은 s[i-k] ~ s[i-1] 까지의 해시값을 담고 있을 것이다. 이 값을 A라고 하면, 새로운 해시값은
\[\frac{A-s_{i-k}}{p}+s_ip^{k-1}\]이 될 것이다. 물론 모든 값은 M으로 나눈 나머지 로 관리되므로, $p^{-1} = p^{M-2}$ 로 정의한 뒤,
\[A' = ((A-s_{i-k})p^{-1}+s_ip^{k-1})\text{ mod M}\]을 계산하여 갱신할 수 있다. 실제 코드에선 $A’$이 값이 음수가 되는 것을 방지하기 위해
A = (A - s[i-k]) * INVP % mod;
A = (A + s[i] * mypow(p, k-1)%mod)%mod
A = (A + mod)%mod // 이 부분 중요
위 코드처럼 $M$을 더한 다음 다시 $M$으로 나눈 나머지를 구해야만 한다. TLE를 피하려면 mypow함수는 아래와 같이 로그 시간에 작동하는 함수여야만 한다.
typedef long long ll;
ll mypow(ll a, ll b) {
ll ret = 1;
while(b) {
if(b&1) ret = ret*a%mod;
a = a*a%mod;
b>>=1;
}
return ret;
}
// 이걸 써서 ll INVP = mypow(p, mod-2)로 계산하자.
불필요한 시간 초과를 피하기 위해서 해시값을 계산하는 과정에서 매번 mypow를 호출하지 말고, 미리 배열에 $p$와 $p^{-1}$거듭제곱을 전부 구해놓고 꺼내 쓰는 방법을 강력하게 추천한다. 간단한 문제라면 상관 없지만, modular 연산은 아주아주 느리기 때문에 웬만하면 미리 구해놓아야만 한다.
여튼 이렇게 하면 $r-l$이 일정한 경우에 쓸 수 있는 롤링 해싱을 구현할 수 있다.
2. $r-l$ 이 일정하지 않은 경우: prefix hashing
이제 더 나아가 $r-l$이 일정하지 않고 가변적인 길이의 부분문자열의 해시 값을 구해야 하는 경우를 살펴보자. 이전보다 오히려 간단하다고 느낄 수도 있다.
y[i] 에 s[0] ~ s[i] 까지의 해시값을 저장하자. 다음과 같은 형태일 것이다.
\[y_i = (\sum_{j=0}^{i}s_jp^j)\text{ mod M}\]이 값은 누적합의 개념을 사용해서
for (int i=0; i<n; i++)
y[i] = (y[i-1] + s[i]*mypow(p, i))%mod
이런식으로 구해놓을 수 있다. 그리고 s[l] ~ s[r] 까지의 해시값은 $(y[r]-y[l-1]) / p^{l-1}$ 로 쉽게 계산할 수 있다. 사실 아무리 생각해 봐도 이 방법이 롤링 해싱보다 훨씬 간단하고, 코딩 실수도 적어서 거의 상위호환인 방법인 것 같다. 여기서도 $p^{-1}$의 거듭제곱이 필요한데, 매번 거듭제곱 하지 말고 미리 배열에 넣어놓은 값을 사용하는 편이 좋다.
3. 문자열 s가 갱신되는 경우: segment tree
문자열 s의 원소를 바꾸는 쿼리와 s[l] ~ s[r]까지의 해시값을 구하는 쿼리를 온라인으로 쉽게 처리할 수 있는 방법이 있다. 문자열의 길이가 n이고, 쿼리의 개수가 q개라면 $O(qlogn)$에 가능하다. 핵심은 방법 2와 동일하게 $s_ip^i$의 합을 세그먼트 트리로 관리하면서 갱신하는 것이다. 세그먼트 트리를 사용하여 s[l]~s[r]구간의 합을 O(logn) 시간에 구하고, $p^{l-1}$로 나누어주면 된다. 갱신은 자명하므로 따로 설명하지 않겠다.
응용
이제 다양한 상황에서 해시값을 구할 수 있으므로 해싱을 응용해서 해결할 수 있는 다양한 문제들을 생각해 보자.
응용 1: 사전순 비교
가장 유명한 응용이다. 두 문자열 a[0]~a[n-1], b[0]~b[m-1]이 주어졌을 때, 해시함수 값만 주어져 있다면 $O(\min(\log n, \log m))$ 시간에 두 문자열을 사전순으로 비교할 수 있다. 이진 탐색으로 처음으로 해시값이 달라지는 지점을 찾고, 그 지점의 문자를 직접 비교해 주면 된다.
사전순 비교 (v2)
좀 더 나아가서 두 문자열의 임의 부분문자열 a[l]~a[r], b[L]~b[R]의 사전순 비교도 $O(\min(\log n, \log m))$ 시간에 구할 수 있다. 위에서 설명한 “방법 2: prefix sum”방식을 사용하면 해시값을 구하는 시작지점이 꼭 문자열의 시작부분일 필요가 없기 때문이다. 이번에도 해시값이 달라지는 최초의 지점을 이분탐색해서 비교하면 된다.
사전순 비교 (v3)
만약 두 문자열의 임이 부분문자열을 사전순 비교하는 쿼리, 문자열의 원소를 수정하는 쿼리를 온라인으로 처리해야 한다면 어떻게 해야 할까? 위에서 설명한 세그먼트 트리를 사용하여 해시값을 갱신해주면 이분탐색에 $O(\log n)$, 부분합 구하는게 $O(\log n)$이므로 $O(\log^2n)$시간에 쉽게 해결할 수 있다.
응용 2: cyclic shift의 해시값 구하기
먼저 문자열 s[0]~s[n-1]의 해시값을 구해놓은 경우를 가정하자. 이제 s[1]~s[n-1]은 왼쪽으로 한칸 이동하고, s[0]은 s[n-1]으로 이동하는 left cyclic shift를 고려해 보자. 이 문자열의 해시값은 O(1)에 새로 구할 수 있다.
아주 간단한 아이디어이므로 말로만 간략히 설명한다. 기존 문자열의 해시값이 H이며, 맨 앞 글자가 x라고 하자. 새로운 해시값은 다음과 같이 구해진다.
\[H' = (H-x)/p+xp^{n-1}\]위 식은 쉽게 계산 가능하다. 더 나아가, left cyclic shift를 m번(일반성을 잃지 않고, $1 \leq m \leq n-1$라 가정) 한 경우에도 O(1)에 계산할 수 있다. 미리 prefix sum기법으로 해시값 배열 P[0]~P[n-1]을 구해 놓았다고 가정할 때, 다음과 같이 해시함수를 갱신하면 된다.
\[H' = (H-P[m])/p^m+P[m]p^{n-m}\]여기서도 prefix sum hashing기법은 아주 유용하게 활용된다는 사실을 관찰할 수 있다.
문제풀이
이제 해시를 사용하여 문제풀이에 응용하는 두 가지 예시를 살펴볼 것이다. 먼저, 간단한 예시인 반복 부분문자열(플레티넘 3), 가장 긴 문자열(플레티넘 3) 문제를 다룬다. 마지막으로 이 글을 쓴 계기를 제공하기도 한 따끈따끈한 문제인 ICPC 2023 Seoul Regional E번 문항을 해싱으로 풀어보자.
문제풀이 1: 가장 긴 반복되는 부분문자열 구하기
반복 부분문자열(플레티넘 3), 가장 긴 문자열(플레티넘 3) 모두 같은 문제이다. 겹침을 허용했을 때, 문자열에서 두번 이상 등장하는 가장 긴 부분문자열을 구하는 문제이다.
길이 l인 반복 문자열이 있다면, 길이 l이하인 반복 문자열은 전부 있으므로 l을 기준으로 이분탐색을 수행하면 된다. 길이 l인 부분 문자열이 두번 이상 등장하는지 확인할 때는 롤링 해싱 기법을 사용하거나, prefix sum을 사용하면 된다. 대부분의 경우에 prefix sum을 사용하는 것이 훨씬 깔끔하고 시간상으로도 빠르다. 주의할 점은, 저격데이터 때문에 더블 해싱을 사용해야 한다. 더블 해싱을 할 때는 p값도 당연히 바꿔야 하지만, modular값도 바꿔야 한다는 점에 유의하자. 아래 코드는 풀이의 일부이다. 실제 풀이에서는 double hashing을 사용했으므로 같은 줄이 하나씩 더 있다고 생각하면 된다.
// 전처리 코드
/* p의 모듈러 역원을 구한다 */
invp1 = mypow(p1, mod1-2, mod1);
/* 미리 p와 역원의 거듭제곱을 구해 놓는다 */
pp1[0] = ip1[0] = pp2[0] = ip2[0] = 1;
for(int i=1; i<=n; i++) {
pp1[i] = pp1[i-1]*p1%mod1;
ip1[i] = ip1[i-1]*invp1%mod1;
}
/* prefix sum으로 해시값을 저장한다 */
for(int i=1; i<=n; i++) {
sum1[i] = (sum1[i-1] + (ll)(s[i-1]-'a'+1)*pp1[i])%mod1;
}
구간 [i-l+1]~[i]의 해시값은 아래 코드로 구해진다.
for(int i=l; i<=n; i++) {
ll h1 = (sum1[i] - sum1[i-l])%mod1;
h1 = ((h1* ip1[i-l+1])%mod1 + mod1)%mod1;
}
prefix sum으로 전처리를 해놓으니, 아주 쉽게 해시값을 구할 수 있음을 확인할 수 있다.
문제풀이 2: ICPC 2023 E번
마지막으로, 이번 글을 작성한 목적이기도 한 ICPC Seoul Regional E번 문항의 풀이를 정리한다. 정해는 아호 코라식을 잘 응용하면 풀리는 것 같은데, 아마 대부분의 사람들에게는 1. 대회시간 내에 이 풀이를 떠올리고 2. 수정된 아호 코라식을 실수 없이 구현하는것 보단 해싱으로 문제를 해결하는게 편하리라 생각한다. 필자는 이 방식을 써서 E번문항을 해결하였고, 이 문항을 푼 4팀들 중 최소한 3팀은 해싱으로 문제를 해결하였다.
문제 설명
간단하게 문제를 설명하자면,
길이 N(< 백만)인 중복 없는 수열이 주어진다. 그리고 길이 K(< 10000)인 패턴 M(< 1000)개가 주어지는데, 이 턴은 상대적인 수들의 순서를 나타내며, 1과 K사이 수들로 이루어진 permutation이다. 패턴들은 모두 다르다. 이 때, 처음에 주어진 길이 N인 수열을 앞에서부터 볼 때, 최초로 상대적인 수들의 크기 순서가 패턴과 가장 먼저 일치하는 패턴을 찾자.
예를 들어, 수가 10, 50, 20, 30, 40 이고, 첫 패턴은 3, 1, 2. 두 번째 패턴은 1, 2, 3 이라고 하자. 이 경우 답은 3, 1, 2 이다. 수열에서 두번째 원소부터 시작하는 [50 20 30] 부분이 패턴과 일치하기 때문이다. 패턴 1, 2, 3은 맨 마지막 [20 30 40]에서 등장하므로 등장 순서 상에서 밀렸다.
해싱을 사용한 풀이
우리의 목표는 수들의 상대적인 크기를 해싱하는 것이다. 예를 들어 10, 50, 30 이라면 1, 3, 2를 해싱하는 것이다. 상대적인 크기를 해싱해야 하므로 값을 바로 해시함수에 넣을 수가 없다. 또한 수들 사이의 상대적인 크기는 [l, r]구간을 다르게 잡으면 달라지기 때문에 prefix sum방식이나 segment tree방식도 어렵다. 따라서 롤링 해싱 기법으로 해시값을 관리하는것을 목표로 해보자. 롤링 해싱의 기본은 수를 추가하거나 뺄 때 전체 해시값이 어떻게 변하는지를 관찰하는 것이다. 한번 관찰해 보자.
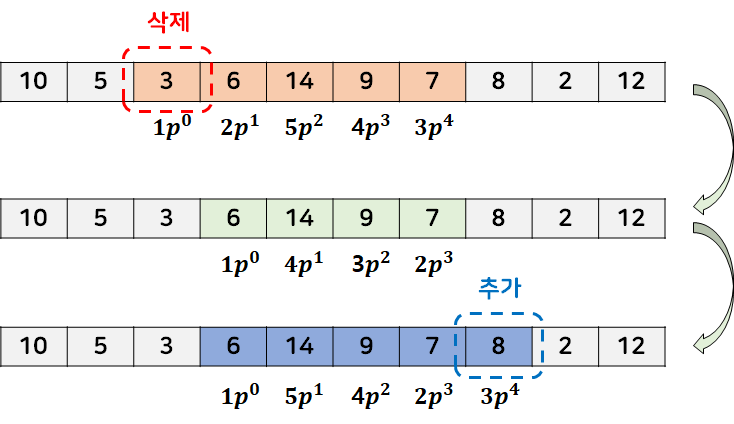
해시값이 관심있는 색칠된 영역을 관심 구간이라고 하자. 관심 구간의 맨 앞 원소를 삭제하고, 관심 구간의 맨 뒤 원소를 추가한다면 우 그림 2와 같은 변화가 생길 것이다. 위 과정에서 관심 구간의 해시값의 변화량을 빠르게 계산한다면 문제를 해결할 수 있다. 우선 현재 빼거나 넣으려는 값이 관심 구간에서 몇 번째 순서인지를 알아야 한다. 이는 펜윅트리를 사용해서 그 수의 위치에 1을 더하거나 빼고, 앞에서부터의 누적합을 구하는 쿼리로 아주 쉽게 구현 가능하다. 따라서 삭제하려는 값은 그 수의 순서를 그냥 빼면 되고, 추가하려는 값은 그 수의 순서 x $p^{k-1}$을 더하면 된다.
하지만 수를 삭제/추가 하는 과정에서 기존에 관심 구간에 있던 값들의 상대적인 순서가 바뀐다! 사실 이게 이 문제를 해싱으로 해결하는데 가장 큰 난관이다. 다음과 같은 관찰을 해보자.
-
어떤 수를 삭제하거나 추가할 때, 그 수보다 작은 수는 상대적인 순서에 영향을 받지 않는다. 오직 그 수보다 큰 수만 영향을 받는다.
-
어떤 수를 삭제할 때 그 수보다 큰 수들의 상대적인 순서는 1 만큼만 감소하고, 어떤 수를 추가할때 그 수보다 큰 수들의 상대적인 순서는 1 만큼만 증가한다. 따라서 해시값의 차이는 p의 거듭제곱들의 합이 될 것이다. 위 그림 2에서 수 3을 삭제할 때는 관심구간의 모든 수가 3보다 크기 때문에 [2, 5, 4, 3]이 [1, 4, 3, 2]로 감소했다. 이 과정에서 생기는 해시값의 차이는 $p^1+p^2+p^3+p^4$일 것이다. 반대로, 숫자 8을 추가할 때는 숫자 6, 9만이 영향을 받았으며 증가한 해시값은 $p^1 + p^2$이다.
앞에서 수의 순서를 구하는 문제에서 수 x를 추가할 때는 펜윅의 [x] 인덱스의 값을 1 더했다. 그럼 이제 배열의 i번째 값이 x라고 할 때, 펜윅의 [x]인덱스에 $p^i$를 더해보자. 그럼 x보다 큰 인덱스의 합을 구한다면 그 수보다 큰 (순서의 변동이 생길) 값들의 $\sum p^i$를 계산할 수 있다. 그리고 시작 위치만큼 $p^j$로 적당히 나눠주면 값을 맞춰줄 수 있다. 이 방식은 한참 위에서 설명했던 prefix sum, segment tree기법에서도 사용한 방법이다.
이제 해시값을 관리할 수 있다!! 다음과 같은 프로세스로 해시값이 바뀐다. 관심 구간의 길이를 $k$라고 하자. [i-k] ~ [i-1] 구간의 해시값이 X일 때, [i-k+1]~[i]구간의 해시값은 다음과 같이 바뀐다. 주어진 배열은 a배열이라고 하자. 펜윅트리 두개를 사용한다. 수들의 상대적인 순서를 관리하는 펜윅 트리를 순서 펜윅이라고 하고, $p^i$를 더해놓는 펜윅 트리를 위치 펜윅이라고 하자.
- 순서 펜윅으로부터 a[i-k-1]의 상대적인 순서를 구한 다음 X에서 뺀다.
- 위치 펜윅으로부터 a[i-k-1]보다 큰 범위의 합을 구하고, $p^{i-k-1}$로 나눠주고 X에서 뺀다.
- a[i-k-1]을 관심 구간에서 제거하기 위해 순서 펜윅, 위치 펜윅을 갱신한다.
- X에 $p^{-1}$을 곱하여 한칸 밀어준다.
- 순서 펜윅으로부터 a[i]의 상대적인 순서를 구한 다음 $p^{k-1}$을 곱해 X에 더한다.
- 위치 펜윅으로부터 a[i]보다 큰 범위의 합을 구하고 $p^{i-l}$로 나눈 뒤 X에 더한다.
- a[i]을 관심 구간에 추가하기 위해 순서 펜윅, 위치 펜윅을 갱신한다.
이렇게 하면 해시값을 적절히 관리할 수 있고, O(NlogN) 시간에 문제를 해결할 수 있다. 정답 후보들도 미리 해싱해놓고 비교해야 하므로 O(NlogN+NlogM)이 좀 더 정확하겠지만, M은 아주 작은 값이므로 별 상관 없다.
또한, 저격데이터를 피하기 위해 더블 해싱을 사용해야 한다. 그리고 항상 강조하지만, 시간초과를 피하기 위해 $p$와 $p^{-1}$들의 거듭제곱을 N까지는 미리 구해놓고 재활용하는 것을 추천한다. 이상으로 풀이를 마친다.