Learning-augmented Algorithm 소개
서론
전통적으로 알고리즘을 생각해보자. 근사 알고리즘의 경우에는 근사비(approximation ratio), 온라인 알고리즘의 경우에는 경쟁비(competitive ratio)가 성능 측정의 지표가 되며, 최악의 경우(worst-case)의 성능 및 평균적인 기대 성능(average-case, under distributional assumption)을 guarantee 하는 것을 목표했다.
기계학습 기술의 발전으로, 현실에서는 종종 문제와 관련한 예측 값을 얻을 수 있다. 이것은 기계학습 모델이 주는 것일 수도 있고, 과거 데이터 기반 통계량일 수도 있다. 그러나, 현실에서 얻을 수 있는 예측 값은 대개 “얼마나 정확한지”에 대해 아무것도 보장된 게 없다.
예측이 있는 상황에서의 worst-case safety 보장이라는 딜레마를 다루기 위해 최근 등장한 것이 바로 Learning-augmented framework이다. 이 framework은 문제의 입력과 함께 예측 값 또한 입력으로 받는 상황에서의 알고리즘을 논한다. 이 framework 하의 알고리즘의 목표는
- 예측이 올바른 경우 매우 성능이 좋기를 바라는 동시에,
- 예측이 실제 정답과 괴리가 있는 상황에서도 적당히 괜찮은 성능을 내는 것이다.
이 글에서는 learning-augmented algorithm이 무엇인지, 성능 측정 척도는 무엇이 있는지 알아본다. 그리고 간단한 예시를 살펴본다.
Learning-augmented 알고리즘의 성능 척도
Learning-augmented algorithm은 문제의 입력 $I$ 외에 prediction $\hat y$ (혹은 advice $p$)를 같이 받는다. 그리고 $(I, \hat y)$ 를 바탕으로 행동한다. 여기에서, prediction의 가능한 형태는 다음을 포함한다:
- optimal solution의 일부
- 앞으로 주어질 미래 요청의 통계량
- target location (facility location 부류의 문제의 경우)
Learning-augmented algorithm은 예측이 정확한 경우의 성능인 consistency와 예측이 아무리 틀려도 유지되는 성능(worst-case guarantee)인 robustness 라는 두 가지 성능 척도로 평가한다. prediction error를 직접 측정하는 방식도 있지만, 이 글에서는 다루지 않는다.
이 두 가지의 지표를 모두 살펴보는 이유는, consistency만 높은 알고리즘의 경우 예측이 틀린 경우에 guarantee 해줄 수 있는 게 없고, robustness만 높은 알고리즘의 경우 예측으로 부터 얻는 이점이 없어서, 전통적인 알고리즘과 딱히 다르지 않기 때문이다.
예제: 스키 대여 문제
온라인 알고리즘 분야의 클래식한 예제인 스키 대여 문제를 살펴보자.
여러분은 스키장에 가서 스키를 $T$일간 타려 하는데, $T$는 모르는 상황이다. 스키를 타기 위해 스키 장비를 빌려야 하는데,
- 장비를 하루 빌릴 때 마다 비용 $1$을 지불하거나,
- 장비를 구매하면 비용 $B$를 지불해야 한다.
여러분의 목표는 지불하는 비용을 최소화 하는 것이다.
예측이 없는 경우의 전략
만약, 이 정보를 모두 알고 있다면, 얼마를 지불해야 할까? 문제의 최적 비용 $OPT(T) = \min(T, B)$가 된다. 왜냐하면, $T < B$이면 계속 빌리고, $T \ge B$면 처음에 바로 사는게 최적이기 때문이다.
하지만, 여러분은 실제로 $T$일이 지나기 전까지 $T$에 대해 알지 못하고, 그것이 이 문제에 대해 어려운 점이다.
다음의 간단한 전략을 생각해볼 수 있다.
- 첫 $B$ 일 동안은 장비를 빌리고,
- $B+1$ 일 째에 장비를 산다.
이 전략을 사용할 때, 여러분이 지불하는 총 비용은
- $T \le B$인 경우 $T$ 만큼을 지불하고,
- $T > B$ 인 경우, $2B$ 만큼을 지불하게 된다.
따라서, $\sup_T \frac{ALG(T)}{OPT(T)} = \frac{2B}{B} = 2$ 가 되고, 이 알고리즘의 경쟁비는 2가 된다.
예측이 있는 경우
예측이 있는 버전에서는 $T$에 대한 예측 $\hat T$ 가 입력으로 함께 주어진다. 알고리즘은 이 예측을 고려해 언제 장비를 살지 결정한다.
간단한 예시로, 예측을 완전히 믿는 알고리즘을 살펴보자.
Algorithm 1. $A_{trust}(B, \hat T)$
- $\hat T < B$ 이면, 매일 장비를 빌린다.
- $\hat T \ge B$ 이면 첫날 바로 산다.
$A_{trust}$의 consistency와 robustness를 분석해보자.
-
Consistency
예측이 정확한$(\hat T = T)$ 경우의 경쟁비가 consistency가 된다.
- $\hat T = T < B$ 이면 계속 빌려서 비용 $T = OPT$ 이고,
- $\hat T = T \ge B$ 이면 처음에 바로 사서 비용 $B = OPT$ 이다.
따라서, consistency = 1 이다.
-
Robustness
예측이 엇나간 경우를 생각해보자. 최악의 입력에서 이 알고리즘이 가지는 경쟁비가 robustness가 된다.
예를 들어, $\hat T = 1$, $T = nB$ $(n > 1)$ 인 경우를 생각해보자.
그러면 $OPT = B$ 이지만, $A_{trust}$ 는 매번 빌리므로, $ALG = nB$ 가 된다. 따라서, $\frac{ALG}{OPT} = n$ 이다. 즉, 최악의 경우의 경쟁비가 bounded 되지 않으므로, robustness는 심지어 존재하지 않는다!
이 예시는 consistency에만 집중하는게 적절하지 못함을 보여준다. 반대로 앞서 살펴본 클래식한 알고리즘을 분석해보자.
Algorithm 2. $A_{classic} (B, \hat T)$
- 첫 $B$ 일 동안은 장비를 빌리고,
- $B+1$ 일 째에 장비를 산다.
이 알고리즘의 경우, 입력의 $\hat T$ 를 아예 무시한다. 앞서 살펴본 바와 같이 consistency = robustness = 2 가 될 것이다. 즉, robustness에만 집중하면 예측이 정확한 경우의 이점을 살리지 못함을 보여준다.
이제, 둘 사이를 섞는 알고리즘을 생각해보자.
Algorithm 3. $A_{\lambda}(B, \hat T)$ (여기에서 $\lambda$는 “어느 정도로” 예측을 믿는지를 조절하는 파라미터다. $\lambda \in (0, 1)$)
- 장비를 빌리거나 사는 “threshold” $X := \begin{cases} \lceil \lambda B \rceil & \hat T \ge B \ \lceil B/\lambda \rceil & \hat T < B \end{cases}$ 로 정의한다.
- 첫 $X$일 동안은 장비를 빌리고,
- $X+1$ 일 째에 장비를 산다.
이 알고리즘을 분석해보자.
-
Consistency.
$T=\hat T$ 와 $B$의 대소관계를 기준으로 따져보자.
-
$T, \hat T \ge B$ 인 경우:
Threshold $X = \lceil \lambda B \rceil \le B$ 이다. 따라서, 실제로 장비를 구매하게 된다고 볼 수 있다. 고로, $ALG = \lceil \lambda B \rceil + B$ 가 된다.
이 경우의 $OPT = B$ 이다. 따라서, 경쟁비는 $\frac{ALG}{OPT} = 1 + \frac{\lceil \lambda B \rceil}{B} \to 1 + \lambda$ 가 된다.
-
$T , \hat T < B$ 인 경우:
-
이 때는 $X = \lceil B / \lambda \rceil > B$ 이다. 실제로 구매가 일어나지 않는다. 고로, $ALG = T = OPT$ 가 되므로 경쟁비가 1이다.
따라서, $cons(A_{\lambda}) = \max(1 , 1 + \lambda) = 1 + \lambda$ 가 된다.
-
-
Robustness.
위에서 $T, \hat T $ 가 $B$를 기준으로 한 대소관계가 같은 경우, 경쟁비가 $1 + \lambda$ 가 됨을 확인하였다. 대소관계가 다른 나머지 두 가지 경우를 살펴보자.
-
$T \ge B > \hat T$ 인 경우:
이 경우, $OPT = B$ 이지만, 알고리즘은 최대 $\lceil B/\lambda \rceil + B$ 의 비용을 사용할 수 있다. 따라서, 경쟁비가 최악의 경우에 $1 + \frac{1}{\lambda}$ 가 된다.
-
$T < B \le \hat T$ 인 경우:
이 경우, 최악은 $T = X + 1$ 인 경우임을 알 수 있고, 이 때의 경쟁비는 $\frac{\lceil \lambda B\rceil + B }{\lceil \lambda B\rceil + 1} \approx 1 + \frac{1}{\lambda}$가 된다.
따라서, $rob(A \lambda) = 1 + \frac{1}{\lambda}$ 가 된다.
-
즉, 이 알고리즘은 $\lambda$를 통해 (consistency, robustness) 사이에 $(1 + \lambda, 1 + \frac{1}{\lambda})$ 의 tradeoff를 준다. 직관적으로 보자면, $\lambda$ 를 작게 하면 “큰 예측” 이 맞을 때 빨리 사서 consistency가 좋아지지만, “작은 예측”이 틀렸을 때 늦게 사게 되어 robustness가 낮아진다.
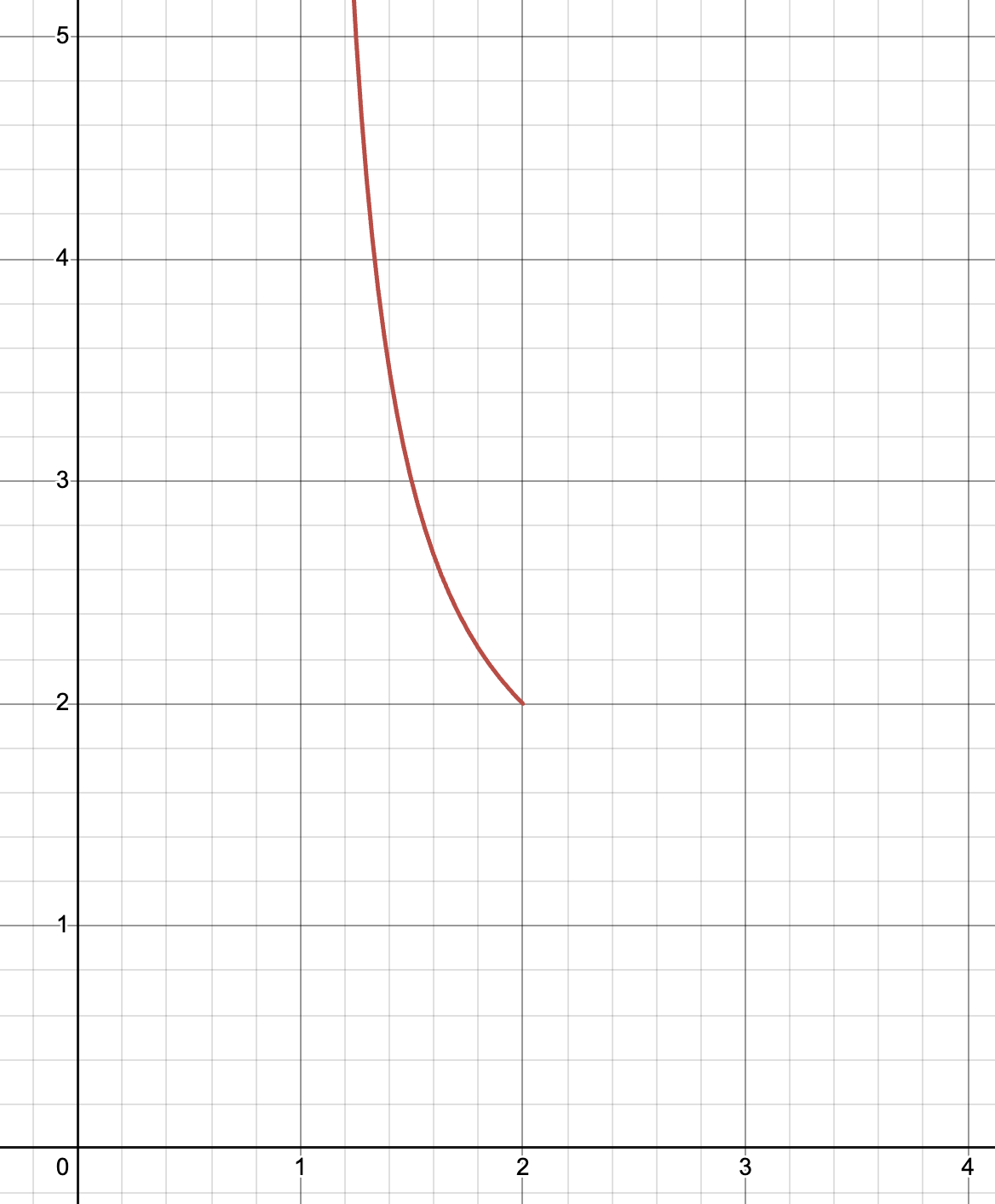
위 이미지의 $x$축은 consistency, $y$ 축은 robustness 이다. 앞서 살펴본 $A_{trust}$ 와 $A_{classic}$ 은 각각 $(1, \infty)$, $(2, 2)$ 에 위치해있고, 그 사이의 붉은 곡선이 $A_{\lambda}$ 에 의해 tradeoff를 줄 수 있는 영역이다.
Learning-augmented algorithm의 연구 방향
앞선 문단에서 consistency-robustness tradeoff curve를 살펴보았다. Learning-augmented algorithm을 연구하는 사람들은
- 더 나은 tradeoff curve를 가지는 알고리즘을 찾기 위해 노력하는 동시에,
- curve가 “어느 선” 아래로 갈 수 없다는 결과 (일종의 hardness result) 에도 관심을 가지고 연구한다.
NeurIPS, ICML, ICLR, AAAI 등의 기계학습 학회나 ITCS, SODA 등의 이론 컴퓨터 과학 학회에서 관련한 연구들이 주로 다루어진다. 관심 있는 사람들은 다음 사이트를 참고해보면 좋다: https://algorithms-with-predictions.github.io/
결론
Learning-augmented algorithm은 예측을 활용해 전통적 알고리즘보다 더 좋은 성능을 노리되, 예측이 틀려도 worst-case guarantee를 유지하려는 알고리즘 설계 패러다임이다. 이와 관련한 예시로 스키 대여 문제를 살펴보았다.
Reference
- https://algorithms-with-predictions.github.io/
- Ravi Kumar, Manish Purohit, Zoya Svitkina, Improving Online Algorithms via ML Predictions