개요
이번 글에서는 지난 달 글에 이어서 조금 더 다양한 정렬 알고리즘을 소개해 보려고 합니다.
저번 글에서도 언급했지만 정렬의 종류는 엄청나게 다양하며, 이 글에서 소개하는 정렬 알고리즘들은 그들 중 극히 일부에 불과합니다. 개중에는 병렬 처리가 되거나 쓰기 연산이 극도로 비싼 등 매우 특수한 실행 환경에서만 이득이 되는 것들도 있고, 데이터가 거의 정렬된 상태에서 매우 효율적인 알고리즘, 또는 현실 세계의 데이터들에 적합하도록 고안된 알고리즘 등도 있었고, 마지막에 잠깐 언급한, 그저 재미를 위해서만 만들어낸, 비효율적이기만 한 알고리즘들도 있었습니다.
이번 글에서 소개하는 알고리즘들은 어떤 특징을 가지고 있을까요? 하나씩 소개해 보겠습니다.
Dual-Pivot Quicksort
퀵소트는 그 이름처럼 평균적으로 빠르다는 장점이 있습니다. 같은 $O(NlogN)$의 시간 복잡도를 가지는 heapsort 등에 비해, CPU와 메모리의 구조상 이득이 되는 경우가 많습니다. Dual-pivot quicksort는 그 장점을 더 극대화하여 평균적인 연산량을 더 줄여내도록 만든 퀵소트의 변형 중 하나입니다.
이름에서 드러나듯이 dual-pivot quicksort는 partitioning을 할 때 피벗을 하나가 아니라 두 개를 사용합니다. 사실 이렇게 피벗을 여러 개 사용한다는 개념은 1970년대부터 있었지만, 일반적인 퀵소트에 비해 나은 퍼포먼스를 그다지 보여주지 못했습니다. 그러다가 2009년에 Vladimir Yaroslavskiy에 의해 고안된 버전이 주목받게 되고, 이후 많은 실험을 거쳐 Java 7부터 primitive type 배열에 대한 Arrays.sort 메서드의 기본 정렬 알고리즘으로 채택되게 됩니다.
이 알고리즘의 기본적인 실행 흐름을 표현하면 다음과 같습니다.
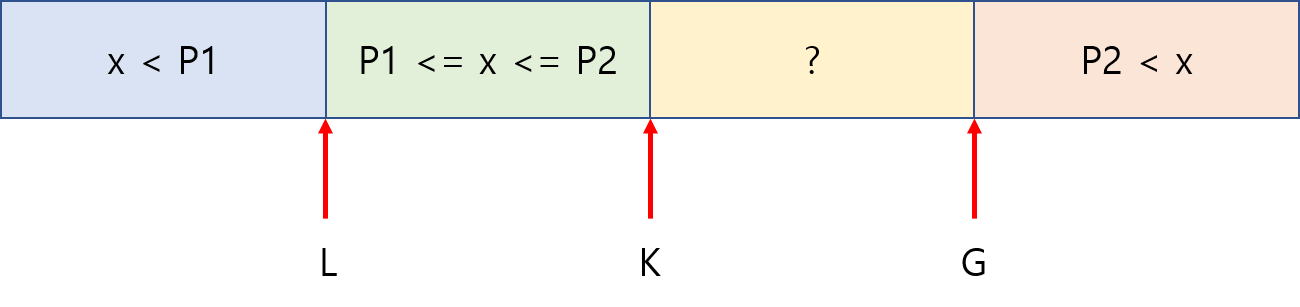
퀵소트와 비슷하게 partitioning을 하는데, 기본적인 퀵소트는 피벗을 하나를 정해서 두 개의 구간으로 분리하는 것에 반해, dual-pivot은 피벗을 두 개를 정해서 세 개의 구간으로 나누게 됩니다. 두 개의 피벗 P1과 P2를 잡고, P1보다 작은 원소들의 구간, P1 이상 P2 이하인 원소들의 구간, P2보다 큰 원소들의 구간입니다.
L(less)은 왼쪽 끝, G(great)는 오른쪽 끝에서 시작하며, K는 L에서 시작해서 G까지 옮겨가며 원소가 속하는 구간이 어디인지를 찾아 swap해주는 방식으로 동작합니다. 그림에서 물음표로 표시된 구간은 partitioning이 끝나면 사라지며, 나누어진 세 개의 구간 각각에 대해 다시 재귀적으로 dual-pivot quicksort를 하게 됩니다.
이렇게 동작하는 dual-pivot quicksort는 이론적, 실험적으로 랜덤 데이터에 대해 보통의 퀵소트보다 상당히 좋은 것으로 판명되었으나, 한 가지 문제는 존재합니다. 퀵소트가 가진 고질적인 문제, 여전히 최악의 경우 시간 복잡도는 $O(N^2)$임이 변한 것은 아닙니다. 그래서 Java에서 사용하고 있는 dual-pivot quicksort는 여기에 여러 복잡한 방법들을 사용하여 현실 세계의 데이터들에 대해 이 알고리즘이 $O(N^2)$에 동작할 일은 사실상 없을 수준오로 개선을 시켰기 때문에 실무에서 사용하는 데에는 무리가 없지만, 여전히 이 코드를 $O(N^2)$으로 만드는 데이터를 생성하는 것이 가능은 합니다. 1
Block Sort
Block (Merge) Sort는 $O(1)$2의 추가 메모리만을 사용하여, 즉 in-place로 병합 정렬을 수행하기 위한 알고리즘입니다. 일반적으로 병합 정렬은 최소한 merge하려는 구간의 반을 임시로 저장해둘 공간이 필요하기 때문에 $O(N)$의 추가 메모리를 사용해야 하지만 이를 단축시켜 한정된 추가 메모리로도 $O(NlogN)$의 병합 정렬을 수행해낼 수 있게 됩니다. 굉장히 복잡한 구조를 가지고 있기 때문에 자세한 설명은 생략하지만, 기본적으로는 bottom-up으로 크기를 늘려가면서 만들어지는 블록들을 merge시키는 구조를 가지고 있습니다. 여러 흥미로운 기법들이 사용되니, 관심이 있다면 공부해보는 것도 좋을 것입니다.
버블/삽입 정렬의 변형들
Cocktail Shaker Sort
Cocktail shaker sort는 버블 정렬의 변형의 일종으로, 한쪽 방향으로만 원소를 비교하여 나아가는 버블 정렬과는 달리, 한쪽 끝까지 한 방향으로 진행한 후에는 반대 방향으로 반대쪽 끝까지 진행하는 것을 반복하는 정렬입니다. 기본적인 버블 정렬에 비해서는 평균적으로 약간 나은 성능을 보이지만, 삽입 정렬에 비해서도 장점이 없고 평균 시간 복잡도 역시 $O(N^2)$이기 때문에 실용성은 그다지 없지만, 재미있는 성질을 하나 볼 수 있습니다.
왼쪽에서 오른쪽으로 진행하고, 어디까지 정렬된 상태인지를 기억하는 똑똑한 버블 정렬을 가정할 때, 아래와 같은 상황에서는 매우 안 좋은 과정을 거치게 됩니다.
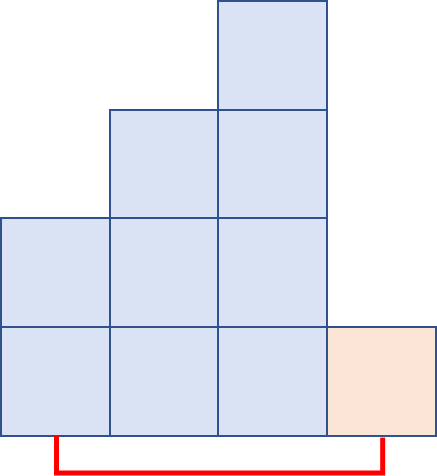
대부분 정렬이 되어있으나 가장 작은 빨간색 막대 하나가 오른쪽 끝에 놓여있습니다. 먼저 한 번 왼쪽 끝에서 오른쪽 끝까지 비교하고 교환을 수행하면, 아래와 같이 빨간색 막대가 한 칸 왼쪽으로 오게 됩니다.
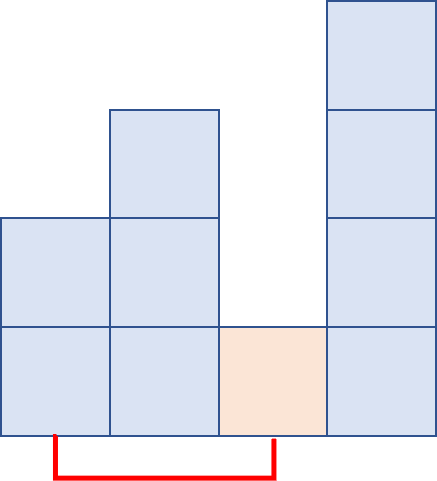
그러나 버블 정렬이 아직까지 확실하게 정렬되었다고 생각할 수 있는 건 가장 긴 막대 하나 뿐입니다. 결국 전체가 모두 정렬되기 위해서는 다시 왼쪽부터 시작해서 비교 / 교환해나가야 하고, 그 후에도 여전히 정렬이 안 끝났으므로 한 번 더 거쳐야 합니다.
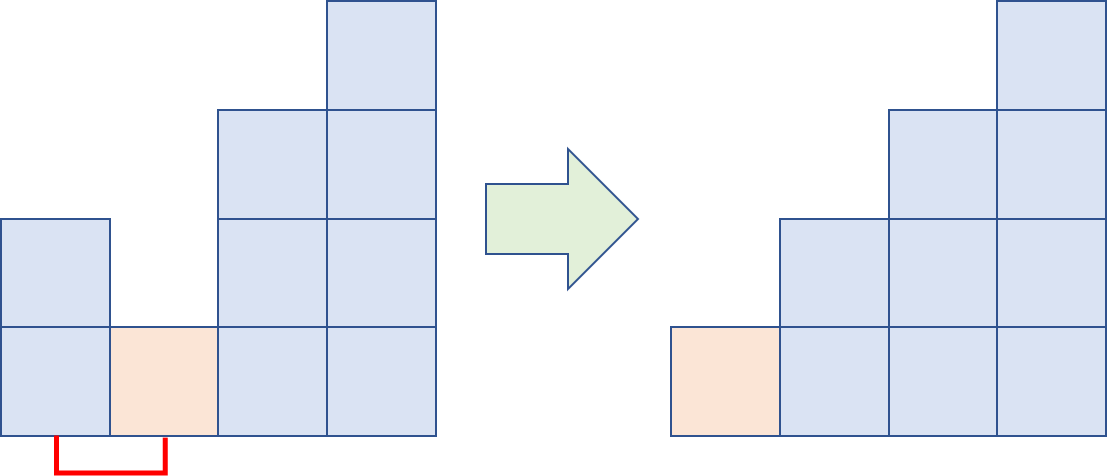
반면에 cocktail shaker sort는 한 번 오른쪽으로 진행한 후, 다시 왼쪽으로 오면서 반대로 비교하는 과정을 거칩니다. 그러면 두 번째 그림 다음은 이렇게 진행됩니다.
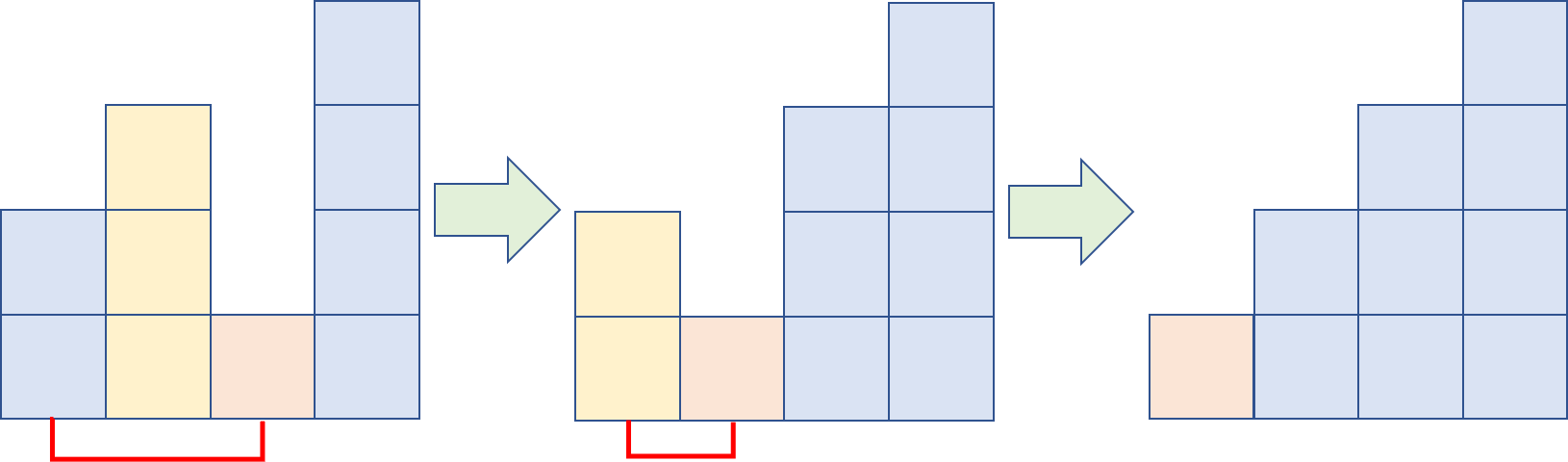
버블 정렬에 비해, 순회 과정을 여러 번 거치지 않고도 크게 벗어나 있는 어긋난 원소를 금방 가져올 수 있습니다. 이렇게 버블 정렬에서 오랜 시간이 지나도록 제 자리를 찾아오지 못하는, 즉, 진행 방향과 반대쪽으로 많이 이동해야 하는 원소를 turtle이라고 합니다(반대로 진행 방향으로 많이 이동해야 하는 원소는 금방 제 자리를 찾아갈 수 있기 때문에 rabbit이라고 합니다). Cocktail shaker sort는 이러한 turtle 문제를 해결해줄 수 있기 때문에 평균적으로는 버블 정렬보다 좋다고 할 수 있습니다.
Gnome Sort
Gnome Sort는 삽입 정렬과 매우 유사하며, 똑같은 swap 과정을 거치지만 더 간단하고 비효율적인 알고리즘입니다. 물론 시간 복잡도는 $O(N^2)$이며, 다음과 같은 의사 코드로 표현할 수 있습니다. 3
procedure gnomeSort(a[]):
pos := 0
while pos < length(a):
if (pos == 0 or a[pos] >= a[pos-1]):
pos := pos + 1
else:
swap a[pos] and a[pos-1]
pos := pos - 1
이중 루프조차 필요하지 않으며, pos라는 하나의 포인터를 가지고 좌우로 왔다갔다만 합니다. 현재 위치보다 왼쪽 위치의 원소가 더 크면 둘을 스왑하고 pos를 왼쪽으로 옮기며, 아니면 pos를 오른쪽으로 옮기는 게 전부입니다. 사실 생각해보면 한 원소가 제 자리를 찾았다면 그 원소가 출발했던 위치까지는 다 정렬되어있는 상태일 것이므로 바로 돌아가면 될 것을 굳이 한 칸씩 옮겨가기 때문에 삽입 정렬에 비해 전혀 나을 것은 전혀 없습니다.
Odd-Even Sort
Odd-even sort는 버블 정렬과 많은 특징을 공유하지만, 진행 방식이 독특합니다. 다음과 같은 과정을 모든 원소가 정렬될 때까지 반복합니다.
1. 모든 홀수 x에 대해 (x,x+1)의 인덱스끼리 비교하여 대소 관계가 역전되어 있으면 swap한다.
2. 모든 짝수 y에 대해 (y,y+1)의 인덱스끼리 비교하여 대소 관계가 역전되어 있으면 swap한다.
이 알고리즘이 이 과정을 거치는 것을 N번 이하로 반복하여 완전히 정렬시킬 수 있다는 것이 증명되어 있으므로, 총 시간 복잡도는 $O(N^2)$입니다. 그 자체로는 그다지 득이 되는 것이 없지만, 이 알고리즘을 주목할 수 있는 이유 중 하나는 이 기법을 활용한 병렬 정렬 알고리즘을 사용할 수 있기 때문입니다.
병렬로 odd-even sort를 수행하도록 만든 알고리즘을 Batcher’s odd-even mergesort라고 하며, 저번 글에서 설명한 bitonic sort와 비슷하게 무수히 많은 프로세서가 있다면 $O(log^2N)$에 동작하게 됩니다. 이론적으로 $O(logN)$ 시간에 병렬로 정렬하는 것이 가능은 하지만, 병렬 처리라는 것은 퍼포먼스에 중대한 영향을 미치는 외부적인 요소(동기화 처리 등)가 많고, 이런 면에서 현실에서는 오히려 Batcher’s odd-even sort가 병렬 정렬에 더 효율적이라고 합니다.4
느린 정렬들
지금부터 소개할 알고리즘들은 효율성과는 무관하게, 단순한 재미나 연구 목적으로 만들어진 것들입니다. 저번 글에서 간략하게 소개한 것들도 일부 있습니다.
Slowsort
Slowsort는 이름에서 유추되듯이, Quicksort의 반댓말입니다. 이름 그대로 매우 느린 퍼포먼스를 자랑하는데, 내세우는 원칙은 multiply and surrender(곱하고 항복)으로 이 역시 퀵소트를 비롯한 알고리즘들의 divide and conquer(나누고 지배)를 패러디한 것이며, 이 알고리즘을 게재한 논문의 제목은 Pessimal Algorithms and Simplexity Analysis(최저 효율의 알고리즘들과 단순도 분석)입니다.
이 알고리즘의 의사 코드는 다음과 같습니다.5
procedure slowsort(A,i,j) // sorts Array A[i],...,A[j]
if i >= j then return
m := ⌊(i+j)/2⌋
slowsort(A,i,m) // (1.1)
slowsort(A,m+1,j) // (1.2)
if A[j] < A[m] then swap A[j] and A[m] // (1.3)
slowsort(A,i,j-1)
전체적인 구조는 병합 정렬을 비슷하게 따라갑니다…만, 여기서 병합을 하는 과정이 없습니다. 대신에 정렬된 양쪽 끝 중 더 큰 쪽을 구간의 가장 끝에 놓고, 나머지 부분에 대해 다시 slowsort를 재귀 호출하는 구조를 가집니다.
이 알고리즘의 시간 복잡도는 아예 다항식이 아닙니다. 지수 복잡도를 가지는데, 정확하게 표현하면 $Ω\Big(N^{\text{(\frac {\log_2N} {2+ε})}}\Big)$이 됩니다. 어느 정도인지 감이 잡히지 않는다면, C++로 실험해보았을 때 N=200에서는 약 0.5초가, N=300에서는 약 8초가 소요되었습니다.
이 알고리즘의 재미있는 점은, 알고리즘 수행 과정에 어떠한 불필요하거나, 역으로 답에서 멀어져가게 만들 수 있는 코드를 삽입하지 않고도 정말 나쁜 시간 복잡도로 정렬을 수행하게 만들었다는 것입니다.
Stooge Sort
Stooge sort도 병합 정렬과 유사하지만, 훨씬 더 단순하면서도 느린 방법으로 정렬을 수행하는 알고리즘입니다. 알고리즘의 의사 코드는 다음과 같습니다.6
function stoogesort(array L, i = 0, j = length(L)-1){
if L[i] > L[j] then
L[i] ↔ L[j]
if (j - i + 1) > 2 then
t = (j - i + 1) / 3
stoogesort(L, i , j-t)
stoogesort(L, i+t, j )
stoogesort(L, i , j-t)
return L
}
간단히 설명하면 먼저 구간의 양끝의 대소 관계를 맞춰놓고, 구간을 1/3씩으로 쪼갠 뒤,
- 앞 2/3를 정렬
- 뒤 2/3를 정렬
- 앞 2/3를 정렬
하여 전체를 정렬하는 방법입니다. 전체 구간에서 가장 큰 1/3개의 원소는 1번에서 뒤 2/3에 모두 속하게 되므로 2번에서 완전하게 정렬되고, 전체 구간에서 가장 작은 1/3개의 원소는 2번에서 앞 2/3에 모두 속하게 되므로 3번에서 완전하게 정렬할 수 있기 때문에 정렬이 성립합니다.
매우 간단해 보이지만 시간 복잡도는 $O(N^{log3/log1.5})$ ~= $O(N^{2.7095…})$ 정도로 버블 정렬 등에 비해 매우 안 좋습니다. 겉보기만 정말 깔끔하고 독특한 알고리즘입니다.
마치며
이번 글에서도 많은 종류의 정렬에 대해 소개한 것 같지만, 더 쓰고 싶은 정렬들은 아직도 많습니다. 알고리즘마다 각기 특색이 있고, 각 알고리즘의 평균 / 최악 복잡도 분석과 어떤 경우에 어떤 알고리즘이 빠르게 / 느리게 동작하는지를 생각해보는 것은 정말 재미있습니다.
또한 지금까지 배운 여러 알고리즘이나 정렬 기법 등을 하이브리드로 사용해서 특수한 경우에 유용한 adaptive 정렬 알고리즘을 만들 수 있을지도 모릅니다. 앞으로 정렬 분야에서 어떤 흥미로운 점을 또 발견할 수 있을지 기대가 됩니다.
-
엄밀하게는 N이 무한히 커질 경우 블록 크기를 저장하기 위해서라면 $O(logN)$의 메모리가 필요하겠지만, 기본적으로 컴퓨터 알고리즘에서 사용하는 모델은 저장하는 수의 크기에 따라 필요한 메모리의 양은 변하지 않는다고 가정합니다. 현실적으로도, 64비트 정수형을 사용할 때 이 정수형 내에 들어가지 않을 크기를 저장하려면 원소가 2^64개가 넘어야 하는데, 그럴 일은 사실상 존재하지 않습니다. ↩
-
https://en.wikipedia.org/wiki/Gnome_sort ↩
-
https://en.wikipedia.org/wiki/Batcher_odd%E2%80%93even_mergesort ↩
-
https://en.wikipedia.org/wiki/Slowsort ↩
-
https://en.wikipedia.org/wiki/Stooge_sort ↩